在安防IPC、人脸闸机、车载DVR等领域,工程师们对瑞芯微(Rockchip)在2020至2021年推出的RV1109与RV1126芯片组合一定不陌生。这对高低搭配、Pin-to-Pin兼容的智慧视觉解决方案,凭借其稳定的供货和成熟的SDK,迅速成为了市场主流标杆。
由于上游产业链产能紧张及市场需求旺盛,相关芯片在2024至2025年间经历了价格波动与供应紧张。为此,瑞芯微在2025年5月正式发布了RV1126的升级版——RV1126B。这款芯片采用四核64位ARM Cortex-A53 CPU,集成3.0 TOPS算力的NPU,并首次引入了独立的AI-ISP硬件,旨在服务中高端的工业与车载视觉应用,而RV1109/RV1126则继续聚焦于存量市场。
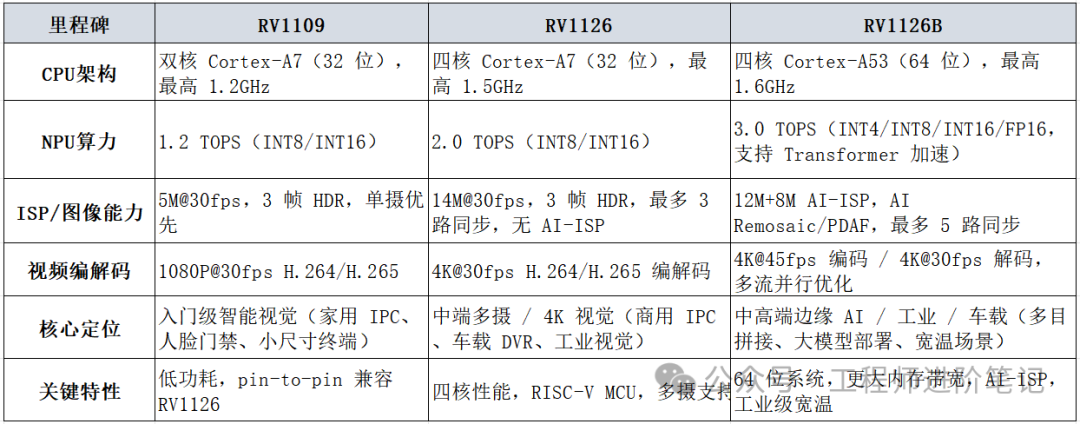
图:RV1109、RV1126、RV1126B三款芯片核心参数对比
为了深入评估RV1126B的实际表现,我们以飞凌嵌入式(FORLINX)的OK1126B-S开发平台作为测试载体。

该开发板的核心板型号为FET1126B-S,采用10层沉金PCB与邮票孔+LGA封装,共引出237个引脚,并已集成电源、复位及存储电路。测试平台配备了4GB内存与64GB eMMC存储。

在连接性方面,开发板设计了两路RJ45网口(百兆与千兆各一),但RV1126B主控仅内置一个以太网控制器,因此需通过U-Boot菜单切换使用。此外,板载的RTL8821CS模组提供了Wi-Fi与蓝牙功能。作为面向机器视觉的解决方案,开发板支持两路4-lane MIPI-CSI摄像头输入,以及一路4-lane MIPI-DSI或LCD屏幕输出(二者择一使用)。为了方便开发者验证,底板还预留了兼容树莓派的40Pin GPIO接口,并配备了ESD防护。

其他外设包括1路扬声器与麦克风、7路SAR-ADC、1路USB 2.0、1路USB 3.0以及1个可用于系统烧录的TF卡槽。整体来看,硬件设计务实,为开发者预留了充足的定制空间。
软件层面,OK1126B-S开发板运行Linux 6.1.118内核,文件系统基于Buildroot定制,提供了常用的Qt与命令行测试工具,用于验证基础外设功能。
当然,RV1126B的核心升级并非这些常规接口,而在于其NPU算力提升至3.0 TOPS,以及革命性的独立AI-ISP。与前代RV1126依赖NPU与ISP协同处理图像不同,RV1126B通过专用AI-ISP硬件执行图像增强算法,完全不占用NPU算力。这种设计在降低整体功耗的同时,能显著提升在低照度等复杂环境下的图像画质。
以下是通过AI-ISP实现的几种图像处理效果对比:

HDR(高动态范围)处理

鱼眼矫正

3DNR(三维降噪)

去雾增强
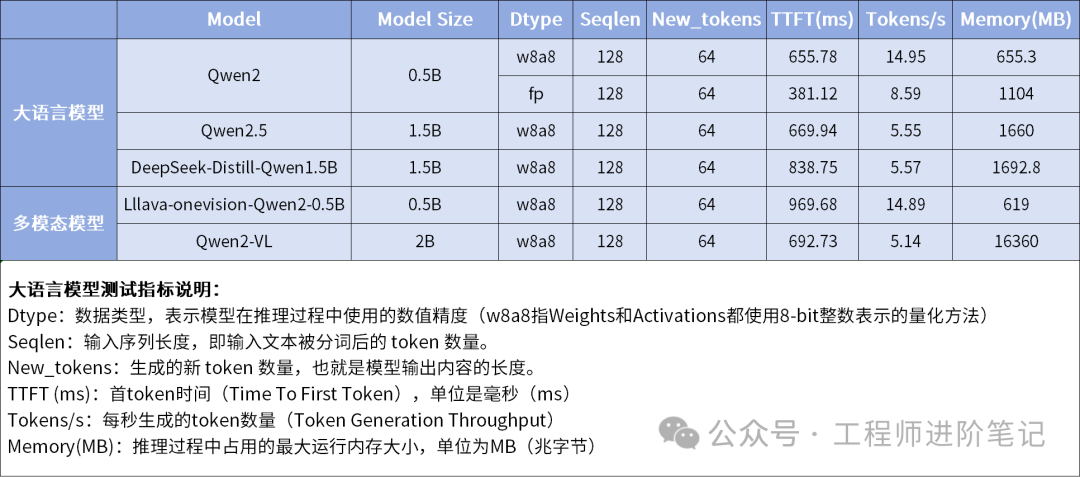
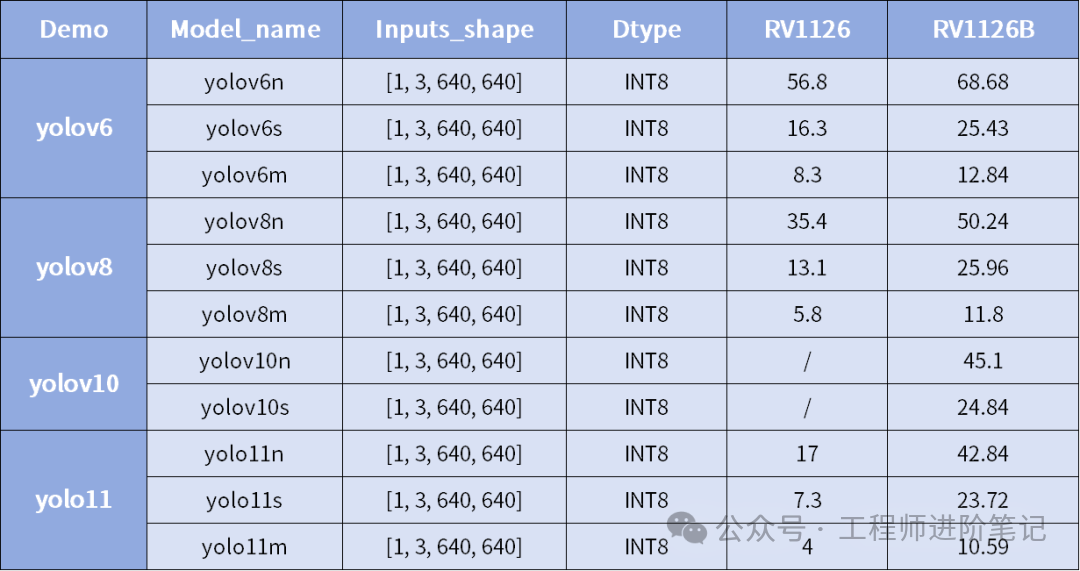
NPU算力的显著提升,使得在RV1126B设备端运行更复杂的AI模型成为可能,为多模态数据分析提供了硬件基础。以下是基于飞凌嵌入式提供数据的部分模型性能实测(单位:FPS)。
大语言模型(LLM)与多模态模型性能
YOLO系列目标检测模型性能
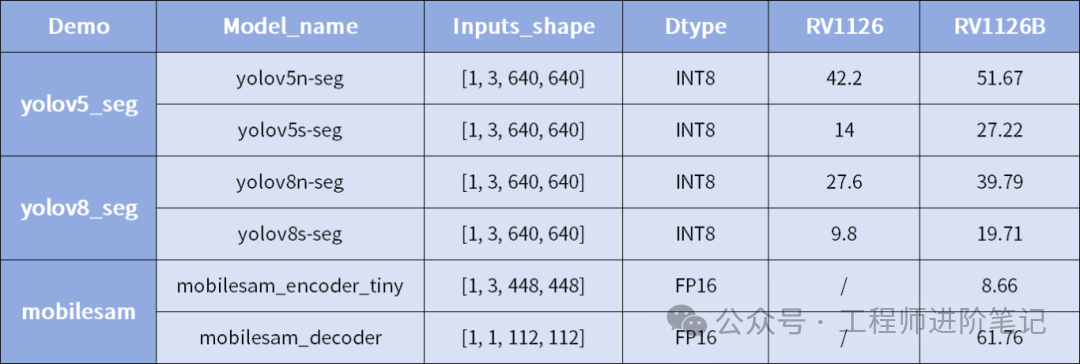
图像分割模型性能
人体姿态与人脸检测模型性能
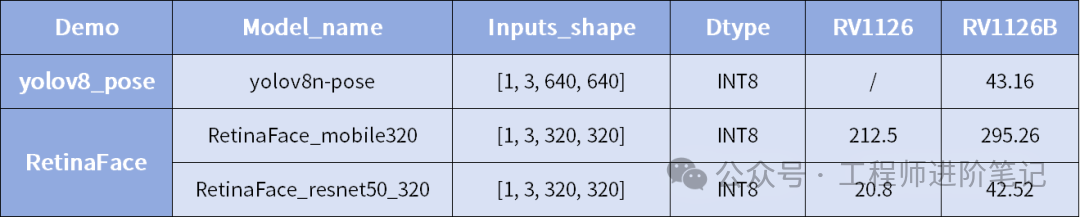
从对比数据可以看出,RV1126B相较于RV1126,在各种AI推理任务上均有显著的帧率提升,这得益于其更强的NPU算力与优化的内存架构(64位CPU带来更佳带宽)。这种从32位到64位计算机体系结构的升级,对于处理现代AI工作负载至关重要。
总结而言,瑞芯微RV1126B通过“独立AI-ISP + 更强NPU + 64位CPU”的组合拳,完成了对前代产品的一次有力迭代。它不仅解决了前代在复杂图像处理时NPU算力被占用的问题,还大幅提升了端侧AI推理的性能边界,非常适合对画质和AI算力有更高要求的工业视觉、高端安防、智能车载等应用场景。对于开发者而言,理解此类芯片的操作系统与底层硬件协同,是发挥其最大效能的关键。
本文部分性能数据及图片素材由飞凌嵌入式提供。更多关于嵌入式系统开发与硬件选型的技术讨论,欢迎访问云栈社区进行交流。 |  发表于 2026-1-17 06:09:44
|
查看: 308|
回复: 0
发表于 2026-1-17 06:09:44
|
查看: 308|
回复: 0
