最近在深入研究 Verl 的架构。虽然我之前接触过强化学习(RL)的算法,但对 RL 的系统架构了解不多。
初看 Verl 的论文时,觉得其“单控制流、多计算流”的核心思想可以理解,但一旦深入细节就容易一头雾水。经过一段时间的学习,终于有了一些头绪,感觉能把 Verl 的设计思路串联起来了。
背景知识:Ray 框架
我们先简单了解一下 Ray 这个分布式计算框架。它能帮助解决分布式环境下的状态同步、数据传输和资源管理问题。
假设有这样一个场景:5个节点代表不同的计算任务,每个节点消耗特定资源(CPU/GPU),节点间的有向边代表了计算或数据流。
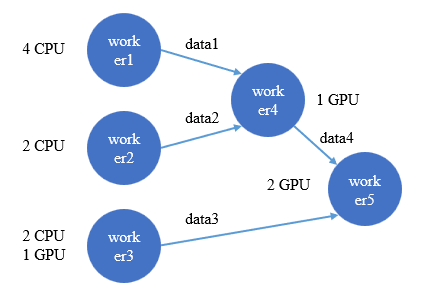
数据流示意图
在这个场景中,Ray 是如何发挥作用的呢?
- 状态同步管理:Ray 将每个任务包装成非阻塞的异步任务,执行后会立即得到一个代表未来结果的对象(Future)。例如,worker1 执行后,会立即得到一个代表 data1 的 futures 对象。当 worker4 需要 data1 时,只需调用
ray.get() 获取这个 futures 的真实值。这种方式避免了手动控制 worker4 等待 worker1 和 worker2 执行完毕的繁琐状态同步。
- 数据传输管理:不同 worker 可能位于不同的机器上。Ray 通过引入一个额外的 driver 节点来管理数据传输和整体调度。worker4 需要 data1 时,无需知道 data1 在哪台机器,只需通知 driver 节点,由 driver 根据计算图自动管理数据从 worker1 到 worker4 的传输。
- 资源管理:我们只需声明每个 worker 所需的资源(如 CPU/GPU),Ray 便可自动进行资源分配和管理。
朴素的 RL 框架实现
说完背景知识,我们来看看如何实现一个最朴素的 RL 框架。
典型的 RL 流程如下:
- Generator(即 Actor)推理生成样本。
- 然后,将样本输入 Actor 计算
old_log_prob,输入 Critic 计算 value,输入 Ref Model 计算 ref_log_prob,输入 Reward Model 计算 reward。
- 接着基于上述值计算优势(adv)和损失(loss),更新 Actor 和 Critic 模型。重复此过程直到达到预定步数。
朴素的实现就是严格按照上述流程串行执行。但这会带来两个问题:
- 计算
old_log_prob、value、ref_log_prob、reward 之间没有数据依赖,本可以并行,串行执行效率低。
- 默认所有模型都在同一个计算集群中,这会引入复杂的并行设置问题,增加通信开销。
Verl 的改进方案
3.1 单控制流,多计算流
针对第一个效率问题,最自然的想法是将这些计算并行化:用不同进程管理不同角色,同时执行。
并行化确实能缓解效率问题,但引入了复杂的状态同步难题,尤其是在涉及多 GPU 或多机时,手动管理极易出错,代码复杂,难以优化。
Verl 的解决方案是引入 Ray 框架。如前所述,Ray 通过异步操作解决了分布式节点间的状态同步问题。因此,RL 框架的使用者只需关注算法整体流程,具体的分布式计算和节点间通信由 Ray 管理。
串行实现是单控制流,简单的并行实现是多控制流。它们的数据流对比如下图所示:

三种 RL 框架实现方式数据流对比
- 单控制流:需要顺序执行,Reference Model 计算完后 Critic 才能计算 Value。
- 多控制流:可以并行执行,但状态同步难以管理,现有框架的通信逻辑与算法代码耦合严重,难以修改。
- Verl 的数据流:大致如图 (c) 所示。表面上仍是“串行”调用,但从 Ref 到 Critic,再到 RM 的调用是异步的,不会阻塞,实际上三者是并行执行的。从而兼具了代码的简洁性和执行的高效性。
3.2 资源管理:模型放置策略
第二个问题是,所有模型角色放在同一个集群会导致:
- 通信开销增加:多个大模型共处一集群,显存压力剧增,不得不提高模型并行度(如张量并行 TP),而这本身就会增大通信开销。
- 分布式策略受限:不同角色对并行策略的需求矛盾。例如,Generator 为追求推理速度,希望 TP 较小;而 Actor/Critic 训练为节省显存,希望 TP 较大。
因此,Verl 提出将不同角色放置在不同的集群中。同时注意到,第一阶段(Generator 推理样本)和最后阶段(Actor 训练)使用相同的模型权重,因此可以将这两个角色放置在同一个集群中,即 Colocate(共置)策略。
- Actor 和 Generator 共置一个集群。
- Critic 的推理和训练共置一个集群。
- 其他角色(如 Ref Model, Reward Model)放在其他集群。
实现这种细粒度的资源管理和共置策略,依然依赖 Ray,但 Verl 在其基础上进行了优化(如构建 RayResearchPool 以支持更细粒度的资源表示)。
3.2.1 HybridEngine:共置优化
Actor 和 Generator 共置有什么特别之处?它们共享同一套权重,是否意味着训练更新后,推理可以直接使用,省去参数同步?
并不完全如此。因为推理和训练的并行策略(流水线并行 PP、张量并行 TP)通常设置不同。例如,推理为追求效率,PP 常设为 1,TP 尽量小;训练则 PP 和 TP 可能都较大。这导致权重在不同卡上的分布不同(如下图 (a) 所示)。因此,在训练转推理或推理转训练时,仍需聚合权重并重新分配,通信开销无法避免。
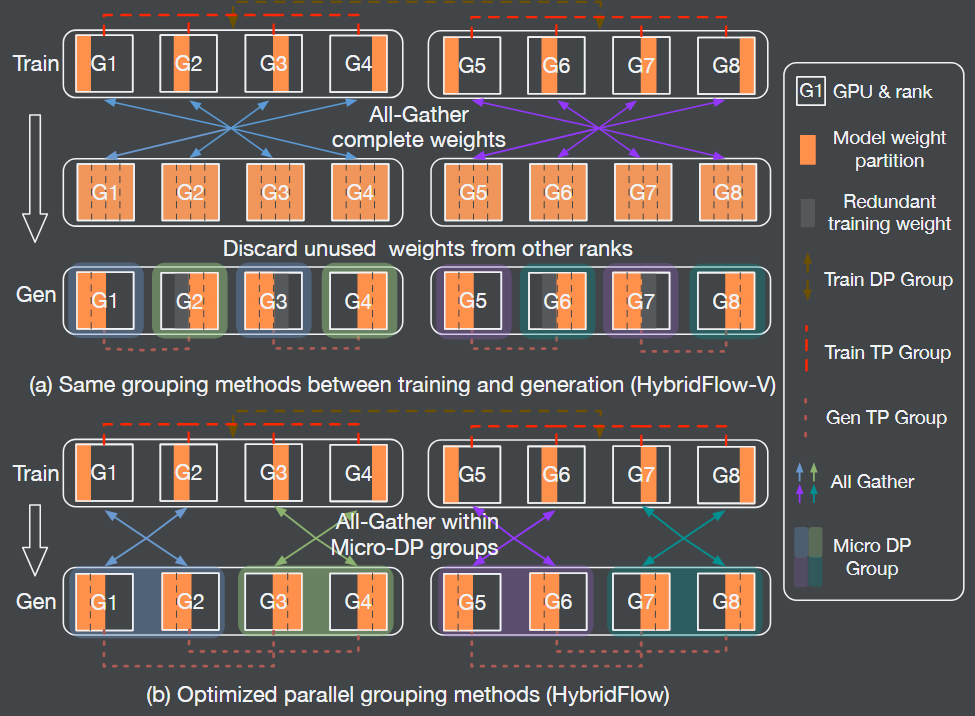
Verl 论文中 HybridEngine 示意图
Verl 提出了 HybridEngine,通过改变推理并行组的设置来避免通信开销并降低冗余内存压力。即调整每张卡上张量并行切分权重的存储顺序,如上图 (b) 所示。
传统推理并行组的排列优先级是 TP > DP(数据并行),Verl 将其改为 DP > TP,即先按 DP 数排列,再按 TP 数排列。
不过,当模型极大,需要同时使用 PP 和 TP(即两者均大于1)时,个人推导认为可能仍无法完全避免通信开销和内存冗余。
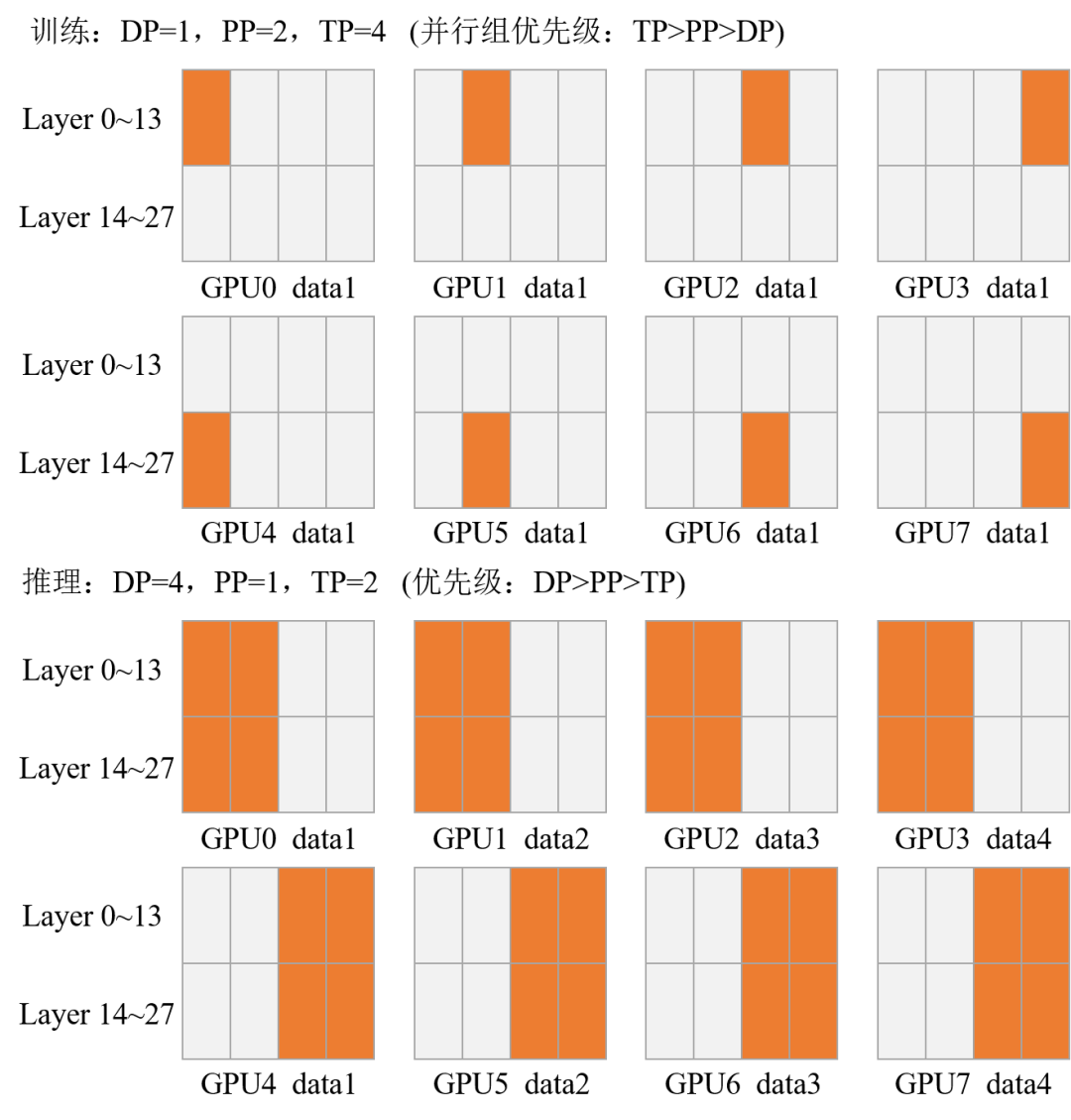
PP 和 TP 同时大于 1 时的权重分布思考
总结与深入探讨
总结一下,Verl 的核心改进在于:
- 使用 Ray 框架,通过异步并行执行解决状态同步问题,通过 Driver 进程管理解决数据传输问题。
- 采用半共置(Semi-Colocate)模型放置策略与修改权重切分顺序(HybridEngine),优化资源利用与通信。
接下来,我们深入探讨两个具体问题:
- Verl 的具体设计思路是什么?
- 单控制流和多控制流在代码中是如何体现的?
1. 核心概念定义
1.1 单控制流 vs 多控制流
- 单控制流:一个控制器管理整个运算逻辑。在 RL 中,即 Rollout、生成经验、训练等步骤都由一个中心控制器调度。
- 多控制流:多个控制器分别管理一组计算单元,彼此通过消息传递或共享内存通信。
1.2 SPMD vs MPMD
- SPMD(单程序多数据):各进程运行相同程序,处理不同数据。通过
barrier、all_gather、all_reduce 等原语进行同步通信。
- MPMD(多程序多数据):各进程运行的程序和数据都不同,需要额外调度器管理逻辑与数据。
2. Verl 的设计思想
Verl 的设计是 上层控制层采用单控制流,下层运算层采用多控制流。
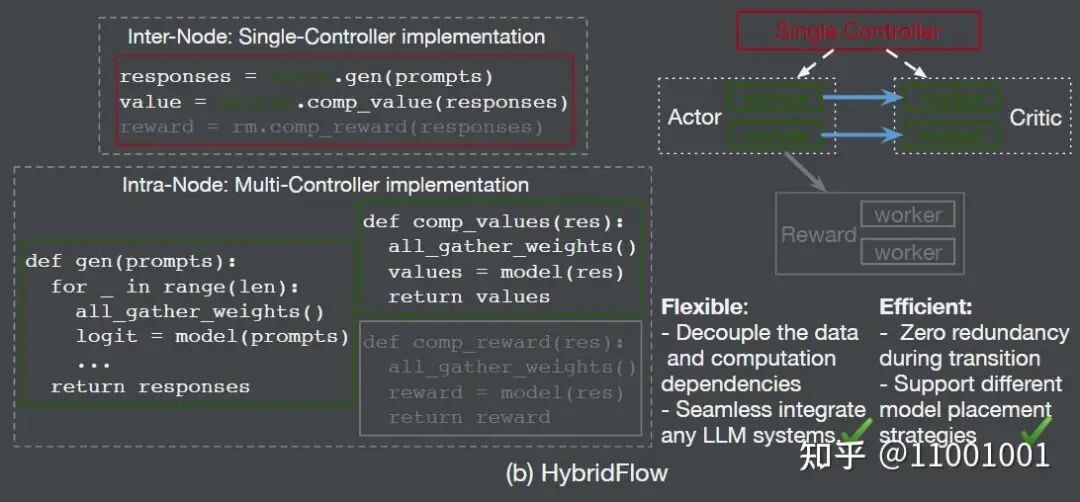
Verl 设计示意图:(a)上层单控制流,(b)下层多控制流
- 控制层(单控制流):
RayPPOTrainer 作为总入口,管理所有 Workers 和 Worker Groups,协调完成整个 RL 流程。它向各个 Worker Group 调用如 generate_sequences 等接口,逻辑清晰简洁。
- 运算层(多控制流):每个进程(每张卡)上都有一个 Worker 实例,负责具体的计算逻辑(如模型前向、反向)。这些 Worker 内部以 SPMD 范式运行,通过集合通信原语协作。
2.1 设计原因
- 分层设计:控制层目标在于逻辑简洁、易修改;运算层目标在于高效执行固定计算模式,并适配各种并行策略与引擎。
- 流式选择:
- 控制层用单控制流,将算法逻辑与底层计算解耦,直观且易于改动。
- 运算层用多控制流,因其操作相对固定,且现代深度学习框架(如 PyTorch)的训练和推理引擎(如 FSDP, Megatron, vLLM, SGLang)本就遵循 SPMD 范式,天然适合多控制流。若在运算层也用单控制流,会使对应节点通信压力过大。
3. 代码层面的具体实现
3.1 控制层:单控制流实现
3.1.1 管理入口
单控制流由 RayPPOTrainer 类管理。在程序入口 main.ppo 的 TaskRunner.run 函数中创建:
trainer = RayPPOTrainer(
config=config,
tokenizer=tokenizer,
processor=processor,
role_worker_mapping=role_worker_mapping,
resource_pool_manager=resource_pool_manager,
ray_worker_group_cls=ray_worker_group_cls,
reward_fn=reward_fn,
val_reward_fn=val_reward_fn,
train_dataset=train_dataset,
val_dataset=val_dataset,
collate_fn=collate_fn,
train_sampler=train_sampler,
)
# Initialize the workers of the trainer.
trainer.init_workers()
# Start the training process.
trainer.fit()
3.1.2 与运算层交互
通过 Worker Group 进行交互。在 init_workers 中,为每个资源池创建对应的 Worker 类,并用 Ray 装饰,然后基于这些类创建 Worker Group。
for resource_pool, class_dict in self.resource_pool_to_cls.items():
worker_dict_cls = create_colocated_worker_cls(class_dict=class_dict)
wg_dict = self.ray_worker_group_cls(
resource_pool=resource_pool,
ray_cls_with_init=worker_dict_cls,
**wg_kwargs,
)
spawn_wg = wg_dict.spawn(prefix_set=class_dict.keys())
all_wg.update(spawn_wg)
...
self.actor_rollout_wg = all_wg["actor_rollout"]
self.actor_rollout_wg.init_model()
Worker 对象在 Worker Group 的初始化过程中被实例化。_init_with_resource_pool 方法会为 local_world_size 的每张卡创建一个 Worker。
rank = -1
local_world_size = resource_pool.store[0]
for pg_idx, pg in enumerate(sort_placement_group_by_node_ip(pgs)):
assert local_world_size <= pg.bundle_count, f"when generating for {self.name_prefix}, for the "
for local_rank in range(local_world_size):
rank += 1
...
# create a worker
worker = ray_cls_with_init(
placement_group=pg,
placement_group_bundle_idx=local_rank,
use_gpu=use_gpu,
num_gpus=num_gpus,
device_name=self.device_name,
)
self._workers.append(worker)
self._worker_names.append(name)
3.1.3 单控制流运算过程
在 fit 方法中,通过调用各个 Worker Group 暴露的接口,清晰直观地完成了 RL 流程:
# rollout阶段
gen_batch_output = self.actor_rollout_wg.generate_sequences(gen_batch)
# 计算reward
reward_tensor, reward_extra_infos_dict = compute_reward(batch, self.reward_fn)
# 计算old_log_prob
old_log_prob = self.actor_rollout_wg.compute_log_prob(batch)
# 计算ref_log_prob(可选)
if not self.ref_in_actor:
ref_log_prob = self.ref_policy_wg.compute_ref_log_prob(batch)
else:
ref_log_prob = self.actor_rollout_wg.compute_ref_log_prob(batch)
# 计算value(可选)
values = self.critic_wg.compute_values(batch)
# 更新critic模型(可选)
critic_output = self.critic_wg.update_critic(batch)
# 更新actor模型
actor_output = self.actor_rollout_wg.update_actor(batch)
3.2 运算层:多控制流实现
3.2.1 多控制流管理
由每张卡上的 Worker 实例负责。如上述代码所示,每个 Worker 管理本卡的计算引擎。RL 框架本质上是联结训练引擎和推理引擎。根据角色不同,Worker 内部可能包含:
- 训练引擎(如 FSDP, Megatron)
- 推理引擎(如 vLLM, SGLang)
- 或两者皆有(共置情况)
例如,FSDP Worker 初始化模型时会用 FSDP 包装:
actor_module_fsdp = FSDP(
actor_module,
cpu_offload=cpu_offload,
param_init_fn=init_fn,
auto_wrap_policy=auto_wrap_policy,
device_id=get_device_id(),
sharding_strategy=sharding_strategy, # zero3
...
)
而使用 vLLM 作为推理引擎时,会在 _build_rollout 方法中实例化 vLLMRollout,每张卡都会创建一个 LLM 对象作为 inference_engine:
self.inference_engine = LLM(
model=model_path,
enable_sleep_mode=config.free_cache_engine,
tensor_parallel_size=tensor_parallel_size,
...
)
对于 SGLang,其实现略有不同,采用了“Mock SPMD”模式,仅在推理 TP 组的 rank0 卡上创建真实的 AsyncEngine,其他卡上为 None。
3.2.2 多控制流运算逻辑
计算以 SPMD 范式进行。数据传入时被切分到各卡,各卡上的 Worker 调用本地引擎进行计算,最后结果被聚合返回给控制层。
例如,generate_sequences 方法会被一个负责数据分发与结果聚合的装饰器(如 DP_COMPUTE_PROTO)包装:
@register(dispatch_mode=Dispatch.DP_COMPUTE_PROTO)
def generate_sequences(self, prompts: DataProto):
...
output = self.rollout.generate_sequences(prompts=prompts)
内部的 rollout.generate_sequences 会调用如 vLLM 引擎的 generate 方法。
参考资料
作者:11001001,已获作者授权发布。
原文链接:https://zhuanlan.zhihu.com/p/1926030684704704490
希望这篇对 Verl 架构的解析,能帮助你理解这个高效 强化学习 框架的设计精髓。如果你对分布式机器学习系统感兴趣,欢迎在 云栈社区 交流讨论。
 发表于 2026-1-23 01:32:01
|
查看: 338|
回复: 0
发表于 2026-1-23 01:32:01
|
查看: 338|
回复: 0
