论文链接:https://arxiv.org/pdf/2601.11144

背景:GraphRAG 面临的“三难”困境
在传统的检索增强生成(RAG)系统中,向量召回是主流方案。然而,当遇到需要“跨知识点推理”的复杂查询时,这种方法的局限性就显现出来,效果不佳。为了解决这一问题,业界引入了图检索增强生成(GraphRAG),它将知识图谱的结构化信息融入检索过程,但也带来了新的挑战,可以概括为“三难”困境:
- 全局视角(Global)够全但粗粒度:能够覆盖全局信息,但检索结果过于概括,导致关键细节被摘要信息所淹没。
- 局部视角(Local)够细却跳不远:能够获取特定实体的详细信息,但在处理需要“多跳”推理、跨越多个知识单元的问题时,检索路径容易中断。
- 检索路径爆炸,延迟扛不住:图结构的复杂性可能导致候选检索路径呈指数级增长,严重影响了系统的响应速度和处理效率。
Deep GraphRAG 的核心设计
由蚂蚁集团和浙江大学联合提出的 Deep GraphRAG 框架,旨在通过一套系统性方案来破解上述困境,在检索的全面性与效率之间取得平衡。其核心设计围绕三个模块展开:
| 模块 |
一句话总结 |
| ① 层次化全局→局部检索 |
先定位顶层社区,再深入子社区,最后聚焦实体,实现层层递进的剪枝式检索。 |
| ② 基于 Beam-Search 的动态重排 |
在检索的每一步仅保留 Top-k 候选,从而显著降低计算量和延迟。 |
| ③ 动态权重 GRPO(DW-GRPO)强化学习 |
引入基于奖励增速的动态权重调整,让小模型(如 1.5B)也能逼近大模型(如 70B)的知识整合能力。 |
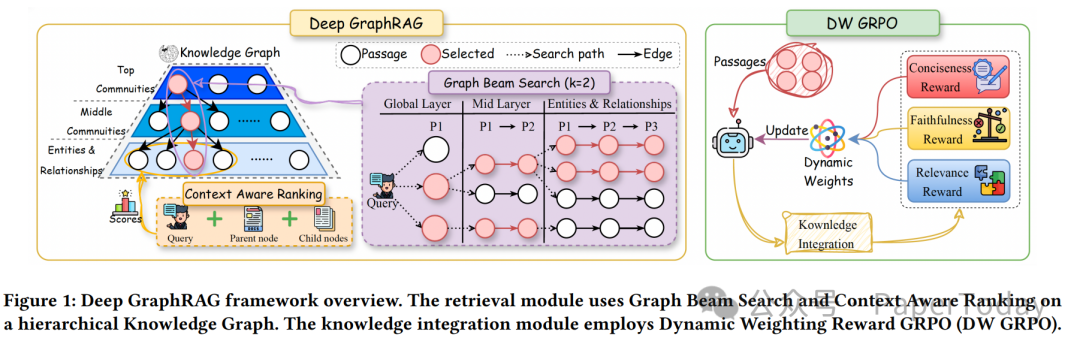
技术细节拆解
图构建流水线(Graph Construction)
模型的基石是一个精心构建的层次化知识图谱。其构建流程包含以下关键步骤:
- 文本切块:采用 600 个 Token 的滑动窗口进行文本分块,并设置 100 个 Token 的重叠区域,以保证上下文连贯性。
- 实体与关系抽取:使用 Qwen2.5-72B-Instruct 模型进行抽取,并设置温度参数为零,以确保结果的确定性。
- 实体消歧:首先使用 bge-m3 模型计算实体相似度,当相似度大于 0.95 时,再交由大语言模型进行二次确认和消歧。
- 层次社区化:采用加权 Louvain 算法进行递归聚类,设置分辨率参数 γ=1.0,最终得到 L0(顶层社区)、L1(中层社区)、L2(实体与关系层)的三层树状结构。
三层检索流程
Deep GraphRAG 的核心检索过程通过一个分层的 Beam Search 算法实现,具体流程如下表所示:
| 阶段 |
Beam 宽度 |
输入 |
输出 |
相似度函数 |
| ① Top 社区层检索 |
k=3 |
查询 q + 社区嵌入 |
Top-3 社区 |
cos(q, D(c)) |
| ② Mid 社区层检索 |
k=3 |
展开上一步得到的子社区 |
Top-3 子社区 |
cos(q, D(c')) |
| ③ 实体层检索 |
m=10 |
展开上一步得到的子社区至实体 |
Top-10 实体 |
cos(q, D(v)) |
整个检索过程主要依赖小规模的矩阵乘法,与 Drift Search 等方法相比,其 GPU 内存占用可降低至约 1/6。

DW-GRPO:动态权重的奖励机制
传统的多目标强化学习方法通常为不同奖励分配固定权重,容易导致优化过程中的“跷跷板效应”——提升一个目标可能以牺牲另一个目标为代价。DW-GRPO 创新性地将权重本身视为可优化的策略参数,在训练过程中根据各奖励函数的“改进速度”动态调整其权重。
α:代表过去 20 个训练步骤中,某一奖励得分的归一化改进斜率。T=0.1:温度参数,用于保证权重更新的平滑性。
动态权重 w_j(t) 通过带有温度参数 T 的 softmax 函数计算得出,其中 W 用于保持权重总和不变:
w_j(t) = W exp(-1 · α_j(t-1)/T) / Σ_j exp(-1 · α_j(t-1)/T) (7)
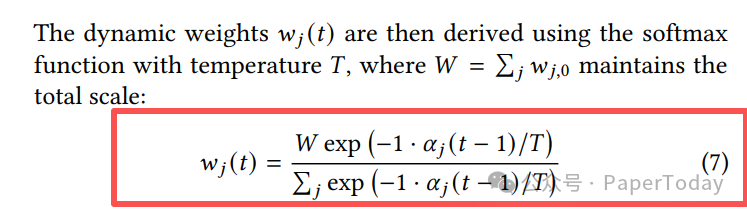
该方法整合了三种关键奖励:
| 奖励 |
实现方式 |
目的 |
| 相关性奖励 (r_rel) |
交叉编码器 (cross-encoder) |
惩罚与查询无关的回答 |
| 忠实度奖励 (r_faith) |
BERTScore-F1 |
惩罚生成内容中的事实性错误或“幻觉” |
| 简洁性奖励 (r_conc) |
1 - len(回答)/len(知识) |
惩罚冗长、啰嗦的表述 |
这种动态调整机制带来了显著效果:在 NQ 数据集上,一个仅 1.5B 参数的模型通过 DW-GRPO 训练后,其知识整合性能达到了 72B 大模型的 94%,同时延迟降低了 20 倍。
实验结果与分析
主要性能指标
在 Natural Questions (NQ) 和 HotpotQA 两个权威数据集上的实验表明,Deep GraphRAG 在多项指标上超越了现有方法。
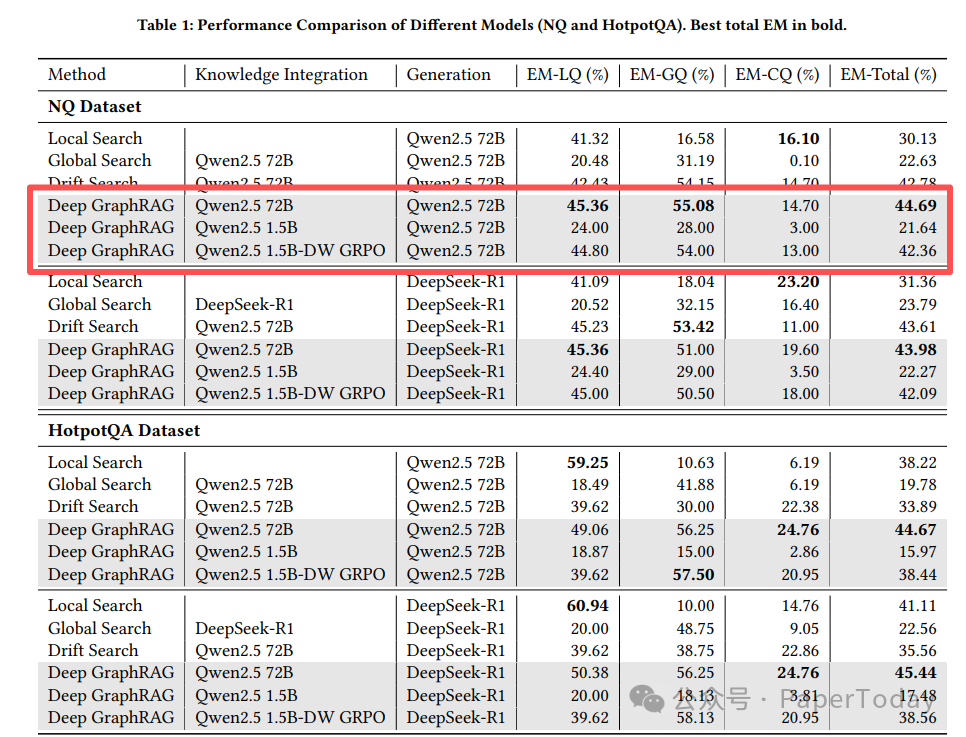
这里重点对比需要复杂推理的 GQ(全局性问题) 表现和整体性能:
| 数据集 |
问题类型 |
Deep GraphRAG |
Drift Search (基线) |
性能提升 |
| HotpotQA |
GQ |
56.25% |
38.75% |
+17.5 个百分点 |
| NQ |
整体 (Total) |
44.69% |
38.05% |
+6.6 个百分点 |
GQ 类问题通常需要跨越至少 2 个社区的知识进行推理,Deep GraphRAG 凭借其层次化检索和动态集成能力,在该类问题上取得了显著优势。
系统延迟对比
效率是 Deep GraphRAG 设计的另一大重点。实验结果显示,其在显著提升效果的同时,大幅降低了系统处理延迟。
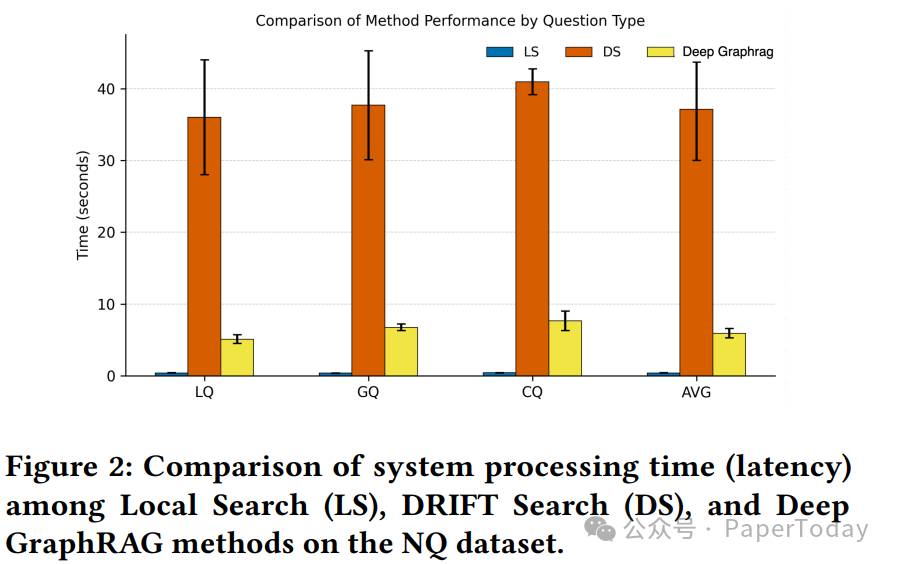
将 Drift Search 的延迟归一化为 1.00 倍作为基准,Deep GraphRAG 的表现如下:
| 场景 |
Drift Search 延迟 |
Deep GraphRAG 延迟 |
延迟降低幅度 |
| NQ-Local 问题 |
1.00× |
0.14× |
-86% |
| NQ-Global 问题 |
1.00× |
0.18× |
-81.6% |
总结
Deep GraphRAG 通过层次化的知识图谱检索、高效的 Beam Search 剪枝策略以及创新的 DW-GRPO 动态权重强化学习方法,系统性地解决了 GraphRAG 在全面性、准确性和效率之间的权衡难题。它不仅在图结构检索(GraphRAG)的全面性上表现优异,更在需要多跳推理的复杂问题上实现了性能突破,同时将系统延迟降低了一个数量级。这项研究为构建下一代高效、可靠的知识密集型应用提供了新的思路和强大的技术文档参考。对图神经网络和检索增强生成技术感兴趣的朋友,可以在云栈社区找到更多相关的深度讨论与实践资源。 |  发表于 2026-1-26 03:22:24
|
查看: 159|
回复: 0
发表于 2026-1-26 03:22:24
|
查看: 159|
回复: 0
