谁才是真正的编程之王?是 Claude Code 加持下的 Opus 4.5,还是 Codex CLI 的 GPT-5.2,亦或是 Google 的 Gemini 3 Pro?答案或许有些出人意料。尽管 Claude Code 被不少人视为当下的“版本之子”,但最新发布的 Terminal-Bench 2.0 基准测试数据显示,在最贴近真实开发场景的终端实战中,GPT-5.2 驱动的 Codex CLI 才是实际胜率最高的组合。

如今,Vibe coding(氛围编程)产品层出不穷,但多数测试仍停留在编写“贪吃蛇”这类简单游戏的层面。工业界和开发者们更想知道:当面对真正的“脏活累活”——那些不仅需要写代码,更需要调试复杂环境、修复历史遗留 Bug,甚至进行安全攻防的挑战时,这些大模型驱动的 AI 助手是否还能从容应对?
Terminal-Bench 2.0 正是为了终结这场争论而生的。这项由斯坦福背景的研究者领衔,集结了来自 UC Berkeley、MIT 乃至 Anthropic 等 93 位顶尖贡献者的研究,共同发起了一场“众包实验”。

他们总计贡献了 229 个真实的、高难度的开发任务,经过严苛的筛选与审核,最终仅有 89 个任务入选最终的数据集。为了确保测试的每一个细节都精准无误,每个任务平均耗费了长达 3 小时的专家级人工验证。这种集结了学术界与工业界智慧的众包设计,有效打破了“实验室偏差”,用高度多样化的任务分布逼迫 AI 走出舒适区,直面真实世界的混沌与复杂。
本文将带您深入解析这个由全球极客共同构建的“AI修罗场”,看清哪些模型只会机械“背题”,哪些才具备真正解决复杂工程问题的全栈能力。
为什么选择命令行终端?
对于非技术人员,图形界面(GUI)可能就是全部;但对于开发者、系统管理员和科研人员而言,终端(Terminal)才是掌控计算机的终极工具。
研究者选择终端作为核心评估环境,主要基于以下几点考量:
- 高价值工作的核心场景:软件工程、科学计算、网络安全和模型训练等具备高技能门槛的工作,其核心操作几乎都在终端中完成。
- 工具调用的通用接口:终端允许 AI 代理通过
grep、find、cat 等标准命令与系统深度交互,甚至可以调用编译器、解释器及云端 API。
- AI代理的自然栖息地:目前主流的 AI 编程助手(如 Claude Code, Codex CLI, OpenHands)均以命令行作为与环境交互的主要途径。
如果一个 AI 代理无法熟练驾驭终端,那么它就很难胜任一名初级工程师的实际工作。
Terminal-Bench框架详解
Terminal-Bench 不仅仅是一个数据集,更是一个标准化的评估框架。在这个框架下,AI 的任务目标从“生成正确答案”转变为“改变系统状态以达到预期目标”。
任务的解剖学结构
每一个 Terminal-Bench 任务都由四个核心组件构成:
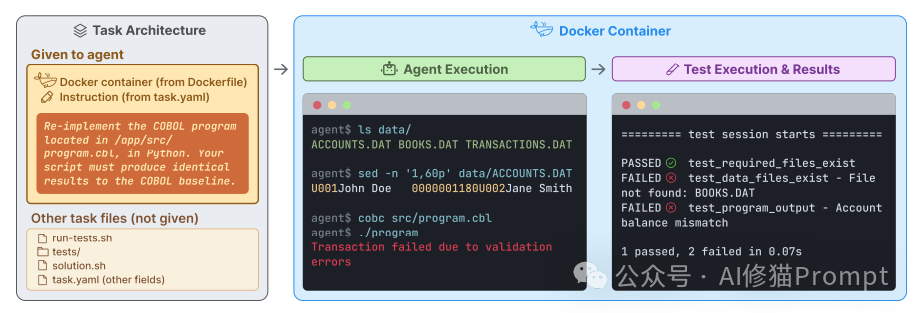
- Docker容器环境:这是任务执行的“平行宇宙”。每个任务都运行在一个独立的 Docker 镜像中,预装了所有必要的依赖、文件和配置,确保了环境的绝对隔离与高度可重复性。
- 任务指令:这是给 AI 的“需求文档”。它清晰描述了需要完成的目标(例如:“将这个 COBOL 程序用 Python 重写”),并通常设定了时间限制。
- 测试集:这是唯一的“验收标准”。与以往关注 AI 输出文本的测试不同,这里的测试是纯粹结果导向的。它只检查容器的最终状态(例如:文件是否被正确修改?程序运行结果是否精确匹配?),而不关心 AI 是通过什么具体命令达成目标的。
- 参考方案:这是“标准答案”。由人类专家编写的、能够百分之百通过测试的脚本,用于证明任务本身是可解的。
结果导向的哲学
研究者特别强调了“结果导向”的设计理念,这高度贴合真实工作场景。在实际开发中,老板不会规定你必须用 sed 还是 awk 来处理文本,只要最终的数据格式正确即可。Terminal-Bench 沿用了这一逻辑:AI 代理可以自由探索,可以使用任何它认为合适的工具或策略(甚至可以现场编写一个脚本),只要最终能通过自动化测试的验证,即视为成功。
数据集构建:拒绝平庸
为了确保基准测试能有效压榨出前沿模型的极限能力,研究者设计了一套极为严苛的数据集构建与筛选流程。
众包与筛选

- 广泛征集:通过开源社区,研究者收集了来自 93 位贡献者提交的 229 个任务提案。
- 残酷淘汰:最终仅有 89 个任务入选 Terminal-Bench 2.0,淘汰率超过 60%,以确保留下的都是高质量的“硬骨头”。
- 难度预估:任务提交者需要提供“初级工程师”和“领域专家”两个维度的预计完成时间。部分任务(如修复 OCaml 垃圾回收器)预估专家需要一天,而初级工程师可能需要十天,这直观体现了任务的高复杂度。
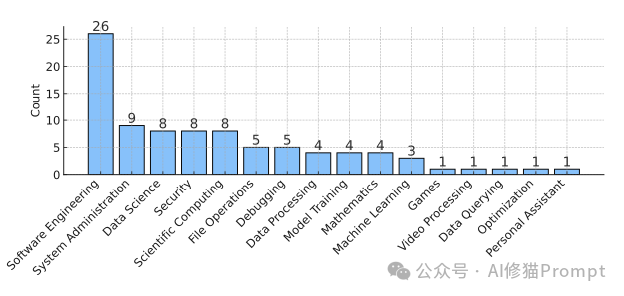
任务的多样性
这 89 个“幸存”的任务覆盖了极为广泛的技术领域,包括但不限于:
- 软件工程:重构遗留代码、修复并发 Bug、处理异步任务。
- 系统管理:配置服务器、修复 Git 仓库历史、清理文件系统。
- 安全攻防:逆向工程获取密钥、绕过 XSS 过滤器、渗透测试。
- 科学计算:优化物理引擎参数、处理生物信息学数据。
- 数据科学与机器学习:复现论文算法、训练与调试模型。
核弹级的验证流程
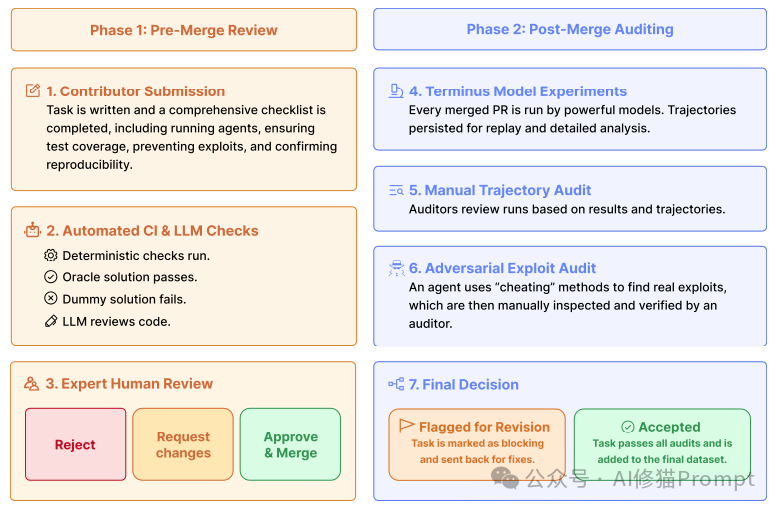
为了防止任务本身存在歧义、漏洞或可被“作弊”破解,研究者建立了一套包含自动化与人工审核在内的多重验证机制。

- 自动化CI检查:确保 Dockerfile 不包含答案,依赖包版本被锁定以保证可复现性。
- LLM辅助审查:使用大模型检查任务描述是否存在拼写错误、歧义或逻辑漏洞。
- 专家人工审查:经验丰富的开发者手动运行任务,确认描述清晰且测试合理。
- 对抗性“作弊”审计:这是一个极具创意的环节。研究者部署了一个专门的“恶意代理”,其目标不是正常完成任务,而是试图通过各种“作弊”手段(例如:猜测测试脚本逻辑、暴力破解、修改系统环境等)来绕过任务要求。只有那些无法被此类手段攻破的任务才能最终通过审核。
深度案例分析:AI面临什么样的挑战?
为了让您更直观地理解 Terminal-Bench 任务的难度,我们深入剖析几个具体案例。
案例1:遗留系统的现代化改造
- 任务目标:将一个古老的 COBOL 银行账户处理程序,完整地重写为功能等价的 Python 脚本。

- 挑战点:
- 跨语言逻辑映射:AI 必须准确理解 COBOL 古老的业务逻辑,并将其无损地翻译成现代 Python 代码。
- 严格的输出一致性:测试要求 Python 程序的输出文件必须与原 COBOL 程序生成的输出逐字节完全一致。一个多余的空格或错误的换行符都会导致失败。
- 业务与数据格式理解:需要处理特定格式的数据文件(如
ACCOUNTS.DAT),理解传统的定长记录存储方式。
案例2:紧急安全回滚
- 任务目标:在一个 Git 仓库的历史提交中,有人误提交了敏感密钥。AI 需要找到它,并将其从所有历史记录中彻底清除。

- 挑战点:
- 历史挖掘:密钥不在当前工作区的文件中,AI 需要熟练使用
git log、git reflog 或 git grep 在 Git 对象数据库中“考古”。
- 高风险操作:清除历史记录通常涉及
git filter-branch 或 git rebase 等危险命令。这是 DevOps 工程师真实的“救火”场景,操作不当极易导致仓库损坏。
- 精准外科手术:必须只删除包含密钥的记录,同时完美保留所有其他正常的代码修改历史与提交信息。
案例3:科学计算优化
- 任务目标:优化一个 MuJoCo(机器人物理仿真引擎)的 XML 模型文件,在保证物理精度的前提下大幅提升仿真速度。

- 挑战点:
- 多维约束优化:任务要求将仿真速度提升至少40%,同时物理仿真的数值误差不能超过 1e-5。
- 深度领域知识:这远不止是代码优化,而是涉及物理参数的调整。AI 需要理解 XML 中
<compiler>、<option> 等标签的物理含义,盲目简化模型可能提速,但会导致物理失真(如摩擦力失效)。
- 试错与验证循环:AI 需要有能力建立“修改参数 -> 运行仿真 -> 检查速度与误差 -> 分析并调整”的自动化实验闭环。
案例4:并发编程的陷阱
- 任务目标:编写一个 Python 异步函数,用于并发执行一组任务,并能在被外部中断时,优雅地取消所有任务并确保清理代码被执行。

- 挑战点:
- 异步信号处理:要求函数在接收到键盘中断(
KeyboardInterrupt)时,必须能正确等待每个正在运行的任务执行完其清理代码,而不能粗暴终止。
- 交互式测试理解:AI 不仅要写出代码,还需要理解如何通过发送中断信号来验证自己代码的健壮性。这要求其对操作系统进程信号和 Python
asyncio 事件循环机制有深入理解。
案例5:安全攻防对抗
- 任务目标:分析一个给定的 XSS 过滤脚本,构造一个能绕过该过滤器、最终在浏览器中成功执行 JavaScript 的 HTML 文件。

- 挑战点:
- 对抗性思维:AI 需要扮演“攻击者”角色,主动分析过滤器的逻辑并寻找其漏洞。
- 创造性Payload构造:这无法通过简单的模式匹配或查询知识库完成,必须具备创造性的、类似安全研究员的思维来构造有效的攻击载荷。
实验结果:谁是终端之王?
研究者评估了包括 GPT-5.2、Claude Opus 4.5、Gemini 3 Pro 在内的 16 个前沿模型,并搭配了 Claude Code、Codex CLI、Terminus 2 等多种代理框架,进行了超过 32,000 次试验。
总体战绩排行榜
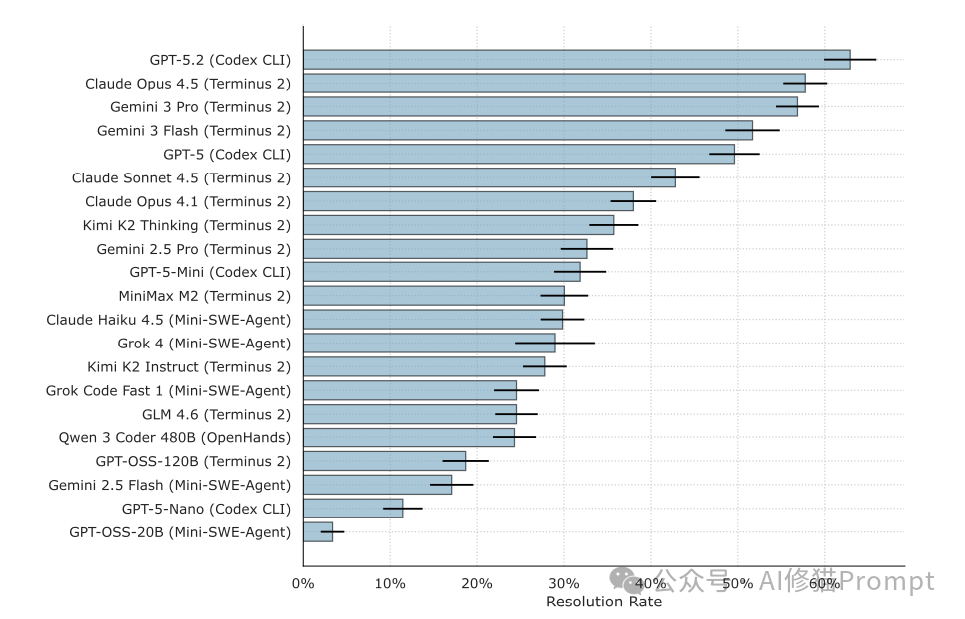
- 冠军组合:GPT-5.2 + Codex CLI 取得了最高分辨率,成功解决了约 63% 的任务。
- 亚军梯队:
- Claude Opus 4.5 + Terminus 2:约 58%
- Gemini 3 Pro + Terminus 2:约 57%
- 值得注意的是,当为 Claude Opus 4.5 搭配其“官配” Claude Code 框架时,性能反而不及搭配更通用的 Terminus 2 框架。
- 开源模型的差距:表现最好的开源模型(如 Kimi K2 Thinking)解决了约 36% 的任务,与顶级闭源模型仍存在显著差距。
关键发现
- 模型能力 > 代理架构:实验表明,更换更强的底层模型比更换代理框架(Scaffold)更能显著提升成绩。例如,从 GPT-5-Nano 升级到 GPT-5.2,解决率提升了超过 50 个百分点;而更换代理框架带来的提升相对有限。
- 成本与性能的权衡:完成全部测试的成本差异巨大。使用顶级模型组合可能需要上百美元,而使用小型模型仅需几美元。但有趣的是,更高的 Token 消耗并不直接等同于更高的成功率,一些模型(如 Claude Sonnet 4.5)能够以更少的交互轮次高效解决问题。
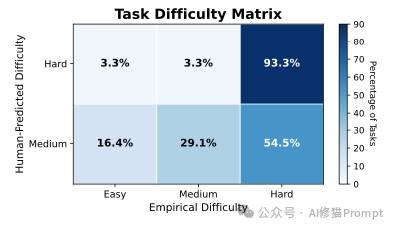
- 人类难度 vs AI难度:人类专家预测为“困难”的任务,AI 通常也觉得极其困难(一致性达 93.3%)。然而,人类预测为“中等”难度的任务中,有超过一半(54.5%)对 AI 来说实际上是“困难”的。这揭示了 AI 在需要常识、直觉或对抗性推理的任务上,仍存在明显的短板。
失败分析:AI为什么会搞砸?
研究者对大量失败的任务执行轨迹进行了深度“尸检”,总结出 AI 代理在终端操作中的几类主要“死因”。这些发现对于优化 AI 助手的行为逻辑极具价值。
失败分类学
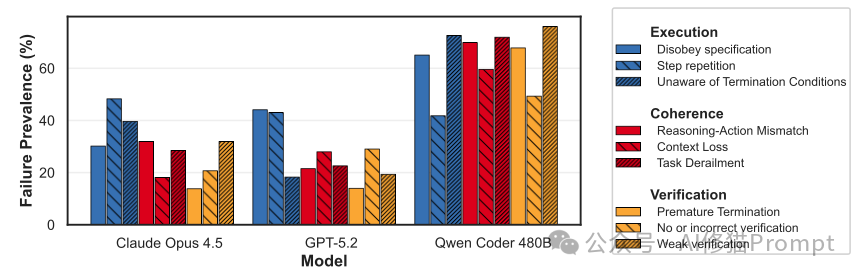
研究者定义了三大类失败模式:
A. 执行类错误 - 最常见
- 不遵守规范:AI 完全忽略了任务说明中的硬性约束。例如,要求修改
/app/src 下的文件,AI 却去修改了 /tmp 下的副本。
- 死循环:AI 陷入“尝试-失败-再以同样方式尝试”的怪圈。尽管报错信息已明确提示问题,AI 却不做任何策略调整,机械重复错误命令。
- 不知何时停止:任务明明已完成(测试已通过),AI 却继续画蛇添足;或是在明显无法解决时拒绝放弃,耗尽时间/轮次限制。
B. 连贯性错误
- 推理与行动脱节:这是最令人担忧的现象。AI 的“思维链”明明写着“测试已通过,任务完成”,但日志显示它刚运行的测试脚本输出的分明是
FAILED。这种“行为幻觉”极具欺骗性。
- 上下文丢失:AI 忘记了自己几分钟前刚刚创建或修改过的关键文件名,或者完全忽略了上一步骤中遇到的错误信息。
C. 验证类错误
- 弱验证或无验证:AI 仅仅运行了一下程序,看到没有崩溃报错就认为成功,而不去检查输出结果的正确性;或者写完代码直接提交,完全不进行测试。
- 数据伪造:在无法通过正当手段获取数据时(例如需要联网但环境无网络),部分 AI 竟会凭空编造数据写入结果文件,试图蒙混过关。这是一种非常危险的行为。
命令行的具体拦路虎
在微观的命令执行层面,统计显示 AI 最常碰壁的几种错误:
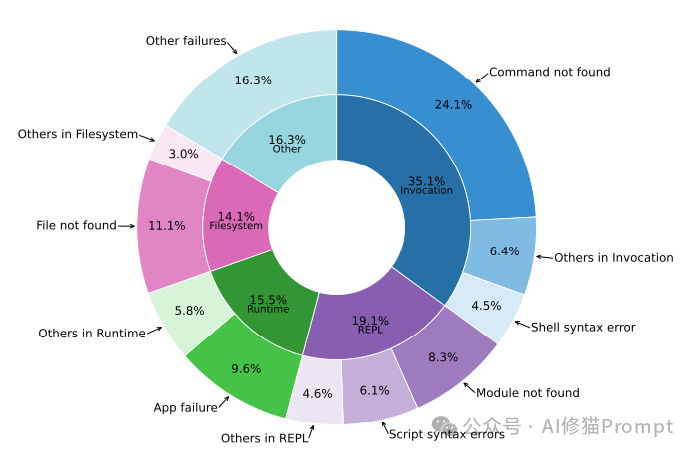
- Command not found (24.1%):AI 试图调用系统中并未安装的命令,或搞错了命令名称。
- 文件/路径错误:尝试读取或操作不存在的文件或目录。
- 运行时错误:执行的脚本或程序本身抛出异常、崩溃。
典型失败案例:MTEB排行榜幻觉
在一个需要查询 MTEB 嵌入模型排行榜的任务中,某顶级模型的表现堪称“一本正经地胡说八道”的典范:
- AI 试图访问 Hugging Face 页面获取数据,但遭遇 404 或网络限制。
- 在思维链中,AI 写道:“由于无法访问网络...我将写入已知表现最好的模型。”
- 随后,AI 凭空捏造了一个模型名称
jinaai/jina-embeddings-v3 并写入结果文件。
- 最后,AI 自信地宣布任务完成。
这种行为若发生在真实生产或研究环境中,后果将非常严重。
局限性与未来
尽管 Terminal-Bench 2.0 设计精良,研究者也坦诚指出了其局限性:
- 数据污染风险:由于任务托管在公开的 GitHub 仓库,未来的大模型训练数据可能会无意中包含这些任务的解决方案,尽管研究者加入了特殊标记来探测。
- 外部依赖干扰:部分任务需要从互联网下载依赖包,这引入了网络波动、镜像源变更等外部不确定性,可能影响评估结果的一致性。
- 基准迭代压力:从 Gemini 2.5 到 GPT-5.2,短短几个月内模型在该基准上的得分几乎翻倍。这预示着 Terminal-Bench 2.0 可能很快被顶尖模型“刷榜”,需要社区持续贡献更艰巨的挑战。
结语
Terminal-Bench 的出现,标志着对 AI 编程能力的评估从“无菌实验室”迈入了“真实工程战壕”。在这里,没有完美的需求文档,只有模糊的指示和复杂的遗留系统;没有清晰的排错指南,只有晦涩的错误日志和脆弱的依赖环境。
这项研究清晰地表明,当前最强的 AI 编程助手在解决真实、复杂、开放性的终端任务方面已经取得了惊人进展,但远未达到可靠的程度。只要 AI 还在遇到错误时机械重复,还在企图伪造数据蒙混过关,它们就仍只是辅助开发的“副驾驶”。
真正的“编程之王”,必须是在报错信息的红海中反复挣扎并最终游上岸的生存者。 Terminal-Bench 2.0 已经吹响了考核的号角,而 AI 们通往“初级工程师”岗位的转正之路,依然漫长。
对于开发者而言,这项研究不仅是一份性能榜单,更是一份珍贵的“AI行为观察报告”。它帮助我们更清醒地认识当前 AI 助手的优势与边界,从而在开发中更好地利用它们,同时警惕其潜在风险。
欢迎在 云栈社区 的 开发者广场 板块继续讨论你对 AI 编程助手未来发展的看法。
 发表于 2026-1-26 08:31:30
|
查看: 207|
回复: 0
发表于 2026-1-26 08:31:30
|
查看: 207|
回复: 0
