
面对需要长程推理和迭代优化的复杂问题,传统的Agent框架,无论是单步执行的ReAct范式还是早期基于随机调整的进化范式,都显得有些力不从心。百度百舸团队近期开源的LoongFlow框架,正是为了填补这一空白而设计。它不是一个简单的工具库,而是一套旨在让AI学会“专家级思考”的智能体开发框架。其核心在于,智能体解决问题的上限,根本上取决于它的思考模式。
基于LoongFlow构建的Agent已经在多个顶尖挑战中证明了实力:
- 数学领域:在11个问题上超越了人类数学家已知的最佳结果,并在7个问题上刷新了Google AlphaEvolve的进化结果,创造了新的SOTA。
- 工程实践:在模拟Kaggle数据科学竞赛的MLE-bench评测中,独立斩获23块金牌。
- 效率优势:与OpenEvolve、ShinkaEvolve等进化智能体相比,在相同任务下,LoongFlow能将进化效率提升超过60%,并且保持了100%的迭代成功率。
这标志着AI解题方式的一个范式转变:从依赖算力的“随机试错”转向基于系统思考的“定向探索”。
一、从爱迪生的灯丝到AI的复杂任务
我们常把解决难题归功于智慧或灵感。但在现实世界的复杂挑战面前,系统性的“解题方法”比瞬间的“智力火花”更为关键。爱迪生发明灯泡的过程,本质上是一个“长程复杂推理任务”:
- 可能性空间巨大:成千上万种材料与工艺。
- 需要多轮迭代:必须遵循“尝试-观察-调整”的循环。
- 结果反馈延迟:只有完整实施后才能看到效果。
- 需要积累智慧:每一次失败都应让下一次尝试更聪明。
在商业与科研中,这类任务无处不在:新药研发、芯片设计、城市规划。其解空间浩瀚如宇宙,已远超人力“试错”的范畴。我们需要将人类顶尖的思维框架与机器的无限算力相结合的新范式。
二、Agent的演进:从单步执行到持续进化
为了让AI从“博学的参谋”成长为能自主解决复杂问题的“专家”,智能体技术沿着解决日益复杂问题的方向演进。
-
阶段一:让Agent一步步想(推理智能体)
以ReAct范式为代表,让AI在单个任务中进行“推理-行动-观察”的逐步思考。它像一个可靠的“单任务执行者”,擅长解决有明确步骤的线型问题。
-
阶段二:让Agent一代代进化(进化智能体)
以AlphaEvolve、OpenEvolve为代表,当目标变为“发现新算法”或“优化机器学习pipeline”时,单次推理就不够了。它们维护一个“解决方案种群”,通过评估、选择和优化来一代代进化。其本质是面向长期目标的种群优化器。
然而,早期进化智能体常把大语言模型(LLM)当作随机调整器,导致进化过程类似“蒙眼随机漫步”,效率低下。它们在“如何智能地进化”这一关键方法上,仍有巨大提升空间。
至此,需求明确:我们需要一个既能长期迭代优化,又能深度思考分析,并将二者深度融合的智能体。
三、LoongFlow:开源的“专家级思考”框架
LoongFlow(龙流)正是为满足这一需求而生的开发框架。它提供了完整的架构与方法论,让开发者能够基于先进的大模型,构建具备“科学家思维”的专家级智能体。
其命名致敬了“知行合一”的理念——真知在于行,而行必有真知指导。LoongFlow的核心目标,是帮助开发者将自身的专业经验,快速转化为具备长程复杂推理能力的AI智能体。
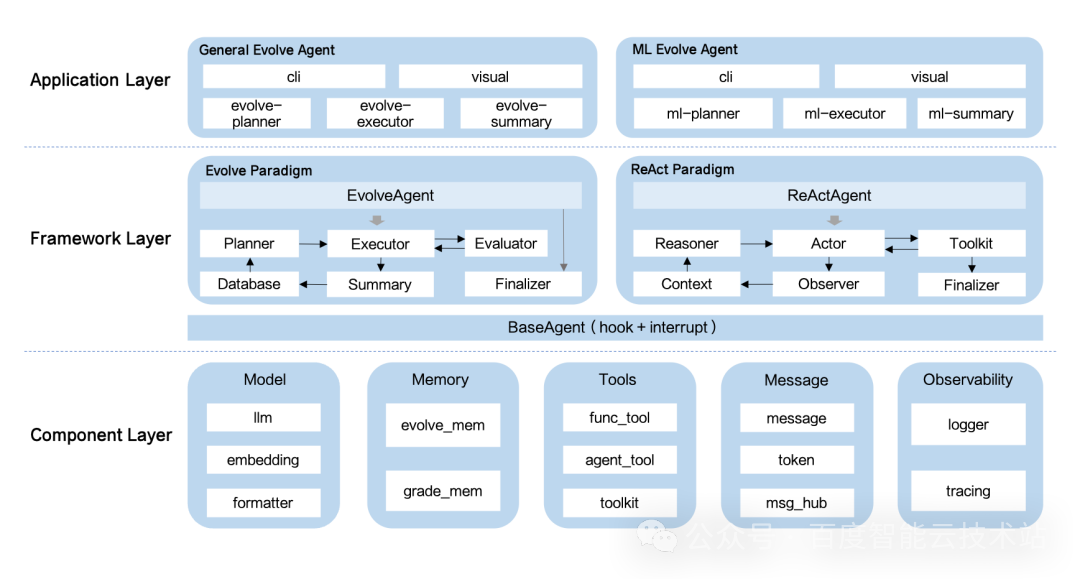
LoongFlow的核心创新在于两套相互咬合的设计:PES(规划-执行-总结)范式与混合进化记忆系统。它们系统化地实现了“如何智能地进化”。
- PES范式:为每一次迭代注入“科学家思维”,将“随机漫步”转变为“定向探索”。
- 混合进化记忆系统:构建专属的“战略智库”,对历史经验进行分类、索引与动态调取,确保智慧被高效复用。
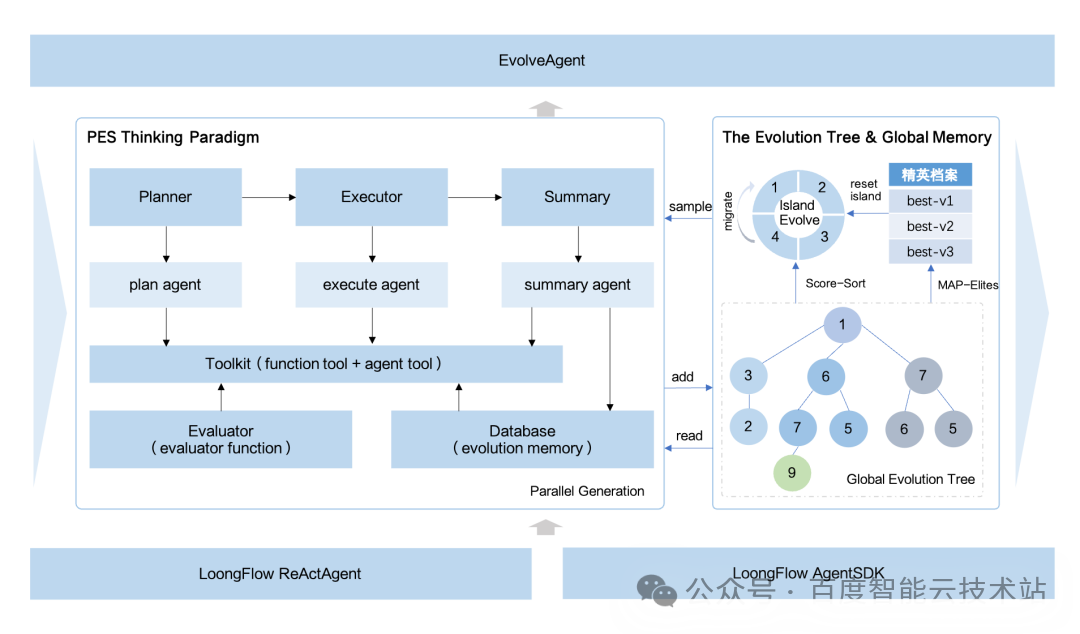
二者结合,LoongFlow实现了从“随机演化”到“定向认知进化”的范式升维。智能体的探索不再是蒙眼狂奔,而是在历史智慧照亮下的、有策略的远征。
四、实战验证:顶尖竞技场上的性能标杆
基于LoongFlow框架开发的“通用算法发现”和“机器学习”两个开箱即用的Agent,在高难度测试集上的表现验证了其普适性与领先性。
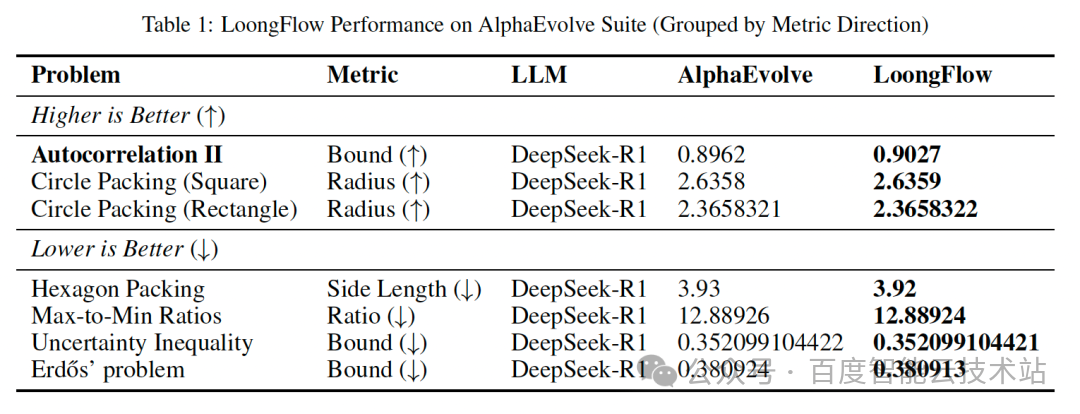
数学成就:全面刷新人类与AI的纪录
在陶哲轩和AlphaEvolve发布的数学挑战中,LoongFlow取得了瞩目成绩。例如,在经典的“圆填充”问题中,它找到了比数学家多年探索和AlphaEvolve进化结果更优的排列方式。
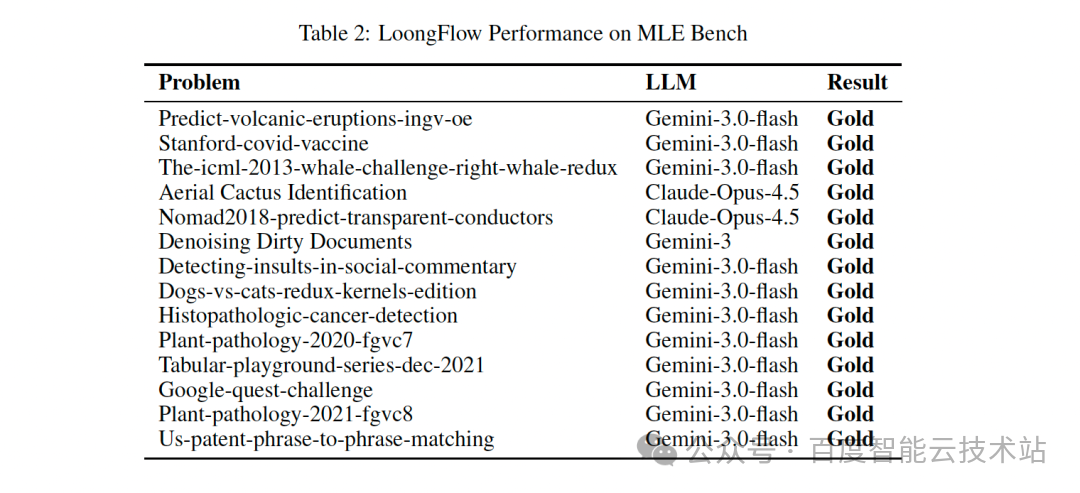
工程成就:在23项真实挑战中夺得金牌
在OpenAI发布的模拟Kaggle数据科学竞赛的MLE-bench评测中,由LoongFlow驱动的智能体已独立斩获23枚金牌,任务涵盖从“病理切片癌症检测”到“预测火山喷发”等高度专业的现实场景。
效率成就:以显著优势稳定胜出
在相同任务下,与主流进化智能体框架对比,LoongFlow展现出压倒性的效率优势。
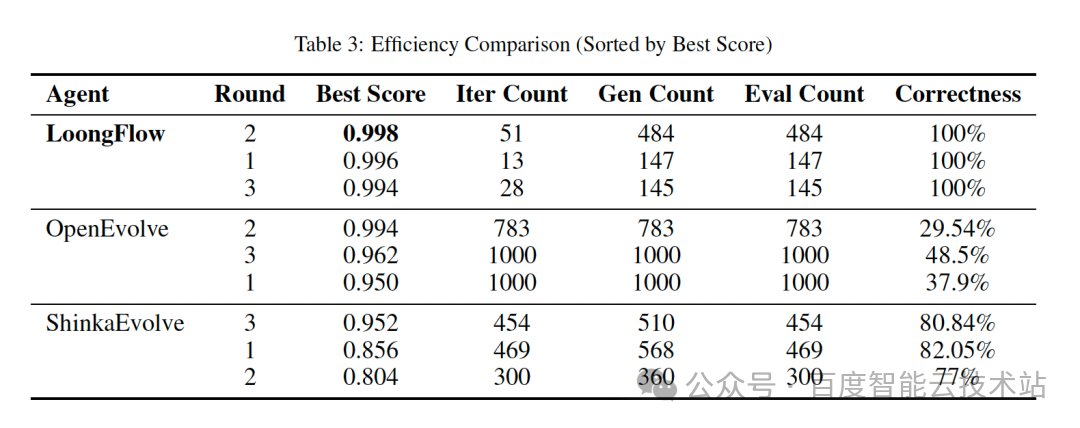
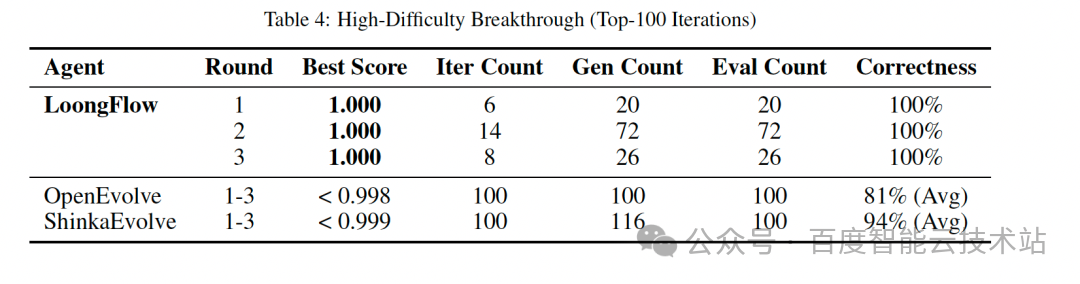
这意味着,使用LoongFlow能以显著更低的计算与时间成本,获得更可靠、更优质的解决方案。
五、机制解构:智慧如何从系统中涌现
LoongFlow的高效源于其精妙的架构设计,通过微观的认知循环与宏观的经验管理紧密协同。
PES范式:高质量的定向认知循环
这是驱动每一次迭代的核心引擎,确保进化过程中的每一步都深思熟虑。
- Plan(规划):扮演“战略分析师”,分析当前方案,检索历史经验与教训,制定目标清晰、规避陷阱的“进化蓝图”,杜绝盲目尝试。
- Execute(执行):如同配备全系专业工具包的“智能施工队”,具备“因题施策”的动态适配能力,并结合“快速本地验证”机制,从源头确保高质量输出。
- Summarize(总结):承担“复盘官”职责,深入剖析规划与结果的差距,提炼因果洞察,转化为下一代规划时可检索的宝贵知识。
混合进化记忆系统:体系化的经验治理
如果说PES是单次探索的“优质生产线”,那么混合进化记忆系统就是确保整个探索事业可持续发展的“智慧管理体系”。
- 多岛模型:建立多个独立的“探索特区”,维持探索的多样性,避免思维过早趋同。
- MAP-Elites:如同多维的“杰出方案陈列馆”,不仅按成绩,更按行为特征对方案归档,为跨界创新保留火种。
- 自适应玻尔兹曼选择:作为智能的“资源调度官”,根据种群状态动态调节策略,智能地在“全局开拓”与“局部深耕”间切换。
系统的协同魔力
PES范式与混合进化记忆系统深度耦合,是效能的倍增器。规划时从智库获取历史智慧;执行时进行快速自我质检;总结时将洞察反馈回智库。这种微观与宏观的紧密配合,使得整个探索过程呈现出强大的方向性、累积性和加速性。
六、从千次试错到百次探索:AI解题的范式转变
回到最初的问题:如果爱迪生拥有LoongFlow,寻找灯丝需要几次?
基于实际表现,我们看到一个根本性转变。在类似规模的探索空间中,传统随机搜索可能需要成千上万次尝试,而LoongFlow的定向认知进化方法,能够减少约60%以上的无效探索,并将迭代成功率提升至接近100%。
这不仅仅是数字的缩减,更是范式的变革。LoongFlow将人类“假设-检验-学习”的科学精神,以软件架构的形式固化、增强并规模化。它标志着AI解决问题方式的质变——答案不再依赖于尝试的次数,而是源于思考的深度与系统性。
七、开源共建:让专业经验转化为AI生产力
未来的AI生产力,需要强大的基础模型与千行百业的专业经验深度融合。LoongFlow的开源发布,正是为了搭建这样一座桥梁。
我们诚邀全球开发者、研究人员和行业专家加入这一旅程,共同塑造AI解决复杂问题的新范式:
- 贡献实际任务案例:为您感兴趣的领域设计挑战,推动框架泛化。
- 开发领域专家智能体:基于LoongFlow封装专业知识,创造可直接应用的AI助手。
- 完善框架生态:贡献新的工具组件或可视化界面。
立即行动
- 访问 GitHub 获取详细代码、文档与示例:
https://github.com/baidu-baige/LoongFlow
- 阅读技术报告深入了解设计原理:
https://arxiv.org/abs/2512.24077
- 加入社区通过 GitHub Discussions 分享想法与案例。
在通往更通用人工智能的道路上,让机器学会如何“系统地思考”复杂问题,与让它变得更“聪明”同样重要。LoongFlow在这个方向上迈出了坚实而开放的一步。
现在,轮到您来定义下一个需要被攻克的“灯丝难题”了。更多关于人工智能前沿技术的深度探讨与开源实战,欢迎在云栈社区交流分享。
 发表于 2026-1-27 10:27:53
|
查看: 254|
回复: 0
发表于 2026-1-27 10:27:53
|
查看: 254|
回复: 0
