想象一下,你请来一位学识渊博的大学教授,他上知天文下知地理,能和你就哲学艺术侃侃而谈。但当你需要他处理一份复杂的财务报表,或者解读一张医学影像时,他可能就需要一些“专项培训”了。这,正是大模型微调(Fine-tuning)的核心价值所在——将一个万能的“通才”模型,塑造成精通特定领域的“专才”。
当前的主流大语言模型(如GPT、Llama等)经过海量数据的预训练,拥有了广泛的知识基础和强大的语言理解能力。但这种通用性是一把双刃剑:在面对一些专业化任务时,它们给出的回答可能不够精确,格式不符合特定要求,或者缺乏关键的领域知识。这时,微调就成了我们手中的“精修工具”。
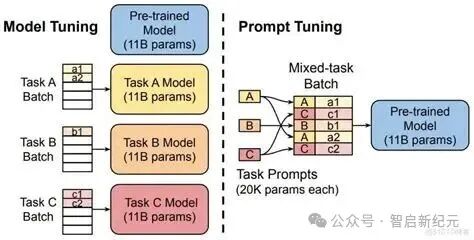
微调究竟是什么?
简单来说,微调是在预训练大模型的基础上,使用特定领域或任务的数据集进行额外训练的过程。这个过程会轻微调整模型的内部参数,使其在保留原有通用智能的同时,更擅长处理你交给它的那类具体工作。
关键概念辨析:预训练 vs. 微调 vs. 提示工程
为了不混淆,我们快速理清这三个核心概念:
- 预训练 (Pre-training):模型从零开始学习,使用TB级别的海量无标注数据,耗时数周甚至数月,计算成本极高。这是打造模型“通才”基础的过程。
- 微调 (Fine-tuning):在预训练好的模型基础上,使用GB级别、规模较小的专业数据进行针对性调整,通常只需几小时到几天。这是将“通才”培养成“专才”的过程。
- 提示工程 (Prompt Engineering):不改变模型本身的任何参数,仅仅通过设计和优化输入给模型的“提示词”(指令)来引导其输出。这是零训练成本,但能力提升有限的方法。
主流微调方法详解
当你决定微调后,方法的选择至关重要。主要有两大类:
1. 全参数微调 (Full Fine-tuning)
顾名思义,这种方法会更新模型所有的参数。效果通常最好,相当于给模型进行一次“全面进修”。但它的代价也很高:需要巨大的计算资源和大量数据,并且可能导致“灾难性遗忘”——模型学会了新技能,却把原来的通用知识给忘了。
2. 高效微调技术 (Parameter-Efficient Fine-tuning, PEFT)
这是目前的主流选择,核心思想是只微调一小部分参数,从而大幅节省资源。以下是几种流行的方法:
何时需要考虑微调?
不是所有问题都需要上微调。先问问自己,你是否面临以下情况?
你应该考虑微调的场景:
- 领域专业化需求:比如法律条文分析、医疗报告生成、金融风险评估。
- 风格一致性要求:如品牌文案撰写、特定的学术论文或技术文档写作风格。
- 任务特殊格式化:需要模型严格按某种结构化格式(如JSON、特定API调用模板)输出。
- 知识更新需求:需要将最新的行业知识或公司的私有数据融入模型。
- 长期成本控制:对于高频使用的场景,训练一个专用小模型可能比持续调用大模型的API更经济。
你可能不需要微调(先试试提示工程):
- 任务简单:仅仅是普通的问答或摘要,优化提示词或许就能解决。
- 任务多变:需要处理的任务没有固定模式,保持模型的通用性反而更好。
- 数据极度匮乏:只有几十条甚至更少的样本,微调很可能效果不佳甚至有害。
微调实战:五步标准化流程
如果你确定了要微调,可以遵循以下步骤:
第一步:明确目标与评估基准
想清楚你到底要改善什么?是回答的准确率、格式的符合度,还是风格的匹配度?建立一个包含各种案例的测试集,用于量化评估微调前后的效果。
第二步:精心准备数据
- 数据量:通常需要几百到几万条高质量样本,并非越多越好,质量是关键。
- 数据质量:标注要准确、一致,尽可能覆盖任务的各种场景,避免偏见。
- 数据格式:对话格式(指令-输入-输出)是目前最通用和有效的格式。
第三步:选择方法与工具链
- 初学者/研究者:推荐使用HuggingFace的Transformers库搭配PEFT库,生态完善,教程丰富。
- 企业级应用:可以考虑MosaicML、Modal等提供完整训练管道的平台服务。
- 云端训练:Google Colab Pro(有GPU)、AWS SageMaker、Azure ML等都是不错的选择。
第四步:启动训练与密切监控
- 超参数设置:学习率通常要设得很小(例如5e-5),防止破坏预训练好的知识。
- 防止过拟合:务必使用验证集,并监控其在训练过程中的表现。
- 监控指标:时刻关注损失函数和你的评估指标的变化曲线。
第五步:全面评估与部署上线
- 最终测试:在一个从未参与过训练或验证的独立测试集上进行最终评估。
- A/B测试:在真实场景中,与原始的通用模型进行对比测试。
- 部署:将微调好的模型打包,部署为REST API服务,或直接集成到你的应用程序中。
微调的实际挑战与应对策略
微调路上也有不少“坑”,需要提前了解:
常见陷阱:
- 数据泄漏:训练数据和测试数据没有严格分开,导致评估结果虚高,模型实际泛化能力差。
- 过拟合:模型过分“死记硬背”训练数据中的细节和噪声,对新数据表现糟糕。
- 偏见放大:如果训练数据本身存在偏见(如性别、种族),微调后的模型可能会将其放大。
应对策略:
- 严格划分数据集:确保训练集、验证集、测试集完全独立,无重叠。
- 使用早停法:当验证集上的性能不再提升时,果断停止训练,这是防止过拟合的有效手段。
- 数据审查与清洗:在数据准备阶段就注重多样性和公平性,进行必要的偏见检测。
未来展望:微调技术将走向何方?
随着技术的发展,微调领域也在快速演进:
- 效率更高:会出现参数效率更高的新方法,用更少的资源达到更好的效果。
- 流程自动化:自动化机器学习(AutoML)理念将融入微调,自动选择最佳方法和超参数。
- 走向多模态:微调对象不再局限于文本模型,图文、语音等多模态模型的统一微调将成为趋势。
- 实现持续学习:模型能够在不遗忘旧知识的前提下,持续、增量地学习新知识。
给不同角色的行动建议
- 业务决策者:首先聚焦微调能否带来可量化的业务价值(如提升客服效率、生成营销内容)。建议从小范围、高价值的试点项目开始。
- 开发者:从LoRA等高效微调入手上手最快。充分利用HuggingFace等开源社区和工具,能极大降低门槛。
- 研究者:可以关注适配器组合、模块化微调等更前沿的方向,探索微调的极限。
- 数据准备者:记住,质量永远重于数量。10条标注完美、覆盖核心难点的数据,其价值可能远胜100条质量平平的数据。
结语
大模型微调正在推动AI技术的民主化——它让更多的企业和开发者能够以可承受的成本,打造出真正贴合自身需求的智能解决方案。这就像为一台动力澎湃的通用发动机,装上适合你车型的精准方向盘和传动系统。
微调并非点石成金的魔法,而是一项需要清晰目标、高质量数据和持续迭代的精密工程实践。当被正确应用时,它能释放出巨大的潜力,让大模型从一个“什么都懂一点”的旁观者,转变为你业务中“真正懂行”的智能伙伴。
无论是构建一个能理解行业黑话的智能客服,还是打造一个能写出你品牌专属调性的内容助手,微调都为我们提供了将通用人工智能转化为专属能力的钥匙。在这个大模型日益普及的时代,深入理解微调,或许就是掌握定制化AI未来的关键一步。在云栈社区,你可以找到更多关于AI实践的开源项目与深度讨论,与广大开发者共同探索技术的边界。 |  发表于 2026-1-27 13:00:58
|
查看: 270|
回复: 0
发表于 2026-1-27 13:00:58
|
查看: 270|
回复: 0
