英文名:Conditional Memory via Scalable Lookup: A New Axis of Sparsity for Large Language Models
中文名:基于可扩展查找的条件记忆:大语言模型稀疏性的新维度
发布日期:2026-01-12
论文地址:https://arxiv.org/abs/2601.07372 (正文约20页,核心在第3-6页)
相关代码:https://github.com/deepseek-ai/Engram
机构:北京大学,DeepSeek-AI
1 核心突破:知识与推理的解耦
这篇论文最引人注目的地方,在于它成功实现了 知识与推理的深度解耦。
传统的大型语言模型(LLM)将海量知识以隐式、分散的方式编码在网络的所有参数中。而 Engram 则不同,它构建了一个 相对显式且结构化的“N-gram 记忆表” ,你可以把它想象成一个模型自带的、经过训练的“知识库”。这一设计从根本上改变了语义的存储方式:从 Embedding 空间中难以捉摸的“模糊分布”,转向了类似知识图谱的“精确索引”。
这种架构转变带来了两大显著优势:
- 可解释性增强:我们能够更清晰地追踪模型“回忆”了哪些知识。
- 局部更新可能:为未来不重新训练整个模型、仅修正特定错误知识的“局部更新”提供了理论路径。
需要特别指出的是,这个记忆表并非人工导入的外部数据,而是 通过与 LLM 主干协同训练得到的。它在训练过程中不断吸收知识,在推理时则扮演一个静态的“外部知识库”供模型即时调用,兼具了检索增强模型的准确性和原生模型的响应速度。
2 摘要概述
- 目标:解决 Transformer 架构缺乏高效知识检索原语的问题,使模型在稀疏计算的约束下,既能处理复杂推理,又能高效存储和调用知识。
- 方法:提出 Engram 模块。它利用现代哈希技术,实现了基于 N-gram 的 O(1) 复杂度快速知识查找。论文系统性地探索并利用了计算(由 MoE 负责)与静态记忆(由 Engram 负责)之间的最优分配定律,该定律呈现 U 型曲线。
- 效果:在总参数量和计算量(FLOPs)保持不变的前提下,显著提升了模型在知识、推理、代码及数学等综合性任务上的性能。得益于其确定性寻址特性,Engram 在系统层面也实现了高效部署,为下一代稀疏大模型奠定了基础。
3 架构详解
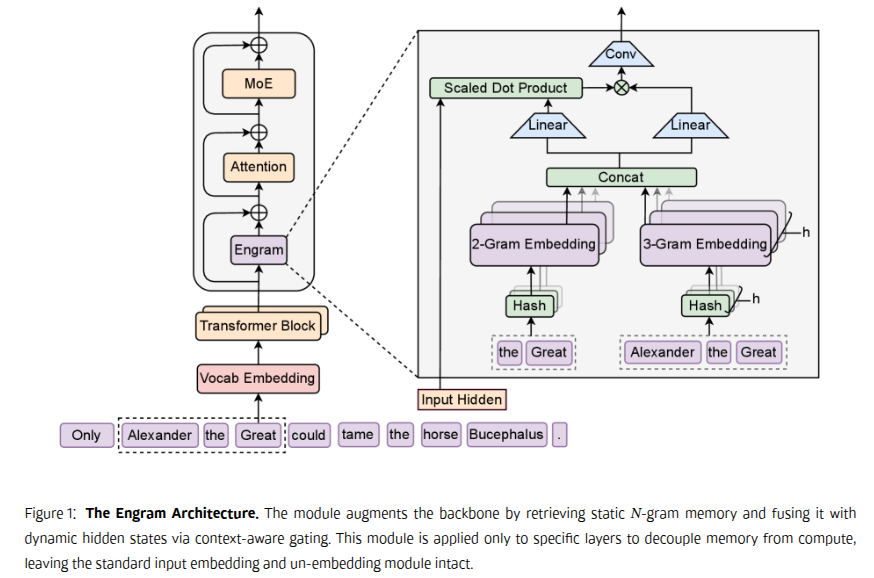
3.1 核心思想
Engram 是一个条件内存模块,其核心设计理念是 在结构上将静态的模式存储与动态的计算过程分离,以此增强 Transformer 骨干网络。该模块在每个位置 t 的处理分为两个阶段:检索 与 融合。
3.2 通过哈希 N-gram 进行稀疏检索
第一阶段的任务,是将局部上下文映射到静态内存条目中。这主要涉及两个步骤:分词器压缩和基于确定性哈希的嵌入检索。
3.2.1 分词器压缩
在常规处理中,为了无损表示,分词器常将语义相近但形式不同的 token 分配不同的 ID(例如 “Apple” 和 “␣apple”)。为了最大化语义密度,Engram 实现了一个词汇投射层 X->X‘,将原始 token ID 压缩为基于规范化文本的“典范标识符”。这一操作实现了约 23% 的有效词汇量减少。
3.2.2 多头哈希
这里用更通俗的方式解释一下关键概念:
- N-gram:把输入序列切成连续的 N 元组。例如序列“1234”,2-gram 是“12”,“23”,“34”;3-gram 是“123”,“234”。
- 哈希:一个将任意长度的“词条”(字符串)通过数学函数快速转换为固定长度数字(哈希值)的过程。这个值可以直接作为内存地址,用于定位该词条对应的信息,无需遍历整个知识库。
- 哈希冲突:两个不同的 N-gram 可能被哈希到同一个地址。为解决此问题,Engram 使用了
K 种不同的哈希函数(多头)。只要有一个函数未发生冲突,就能成功定位。这好比用多个搜索引擎同时查询一个词条。
- 结果融合:多个“头”(哈希路径)各自找到一组候选记忆条目,系统会汇总整合这些结果,最终形成一个与当前输入最相关的“条件记忆”向量。
3.2.3 检索阶段总结
你可以认为模型内部固化了一个知识库(在训练后固定),存储着海量 N-gram 及其对应的知识向量。当模型遇到一个词(如“苹果”)时,它会直接从这个知识库中检索该词常见的关联信息(例如,是水果还是手机品牌)。
这个过程是快速且独立于当前具体语境的,检索出的信息 e_t 可能是粗粒度的、多义的,甚至包含噪声。例如,处理“我要吃苹果”时,通过 2-gram 和 3-gram 可以检索到“苹果”和“吃苹果”的相关向量。
3.3 上下文感知门控
检索到的信息需要与当前语境融合。上下文感知门控包含两部分:门控 与 卷积。
3.3.1 门控
门控的逻辑是:让当前的上下文来决定,采纳多少检索到的“知识”。其设计借鉴了注意力机制中的 QKV 模式:
-
利用检索到的静态知识向量 e_t,通过两个可学习的投影矩阵 W_K 和 W_V,分别计算出用于匹配的“特征” k_t 和要注入的“知识内容” v_t。
k_t = W_K e_t, v_t = W_V e_t
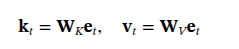
-
引入代表当前全局上下文的动态隐藏状态 h_t 作为 Query。
-
计算匹配度:对 h_t 和 k_t 进行 RMSNorm 标准化,然后计算点积,再通过 Sigmoid 函数得到一个介于 0 到 1 之间的标量门控值 α_t。这个值就代表了当前语境对检索知识的“信任程度”。
α_t = σ( (RMSNorm(h_t)^T RMSNorm(k_t)) / √d )
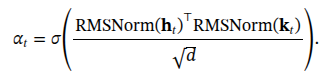
-
最终,用门控值对知识内容加权,得到与上下文对齐的知识向量:$𝐯̃_t = α_t · 𝐯_t$。
3.3.2 卷积
门控为每个位置输出了独立的知识向量,卷积的作用是 对这些知识序列进行局部平滑与融合,防止知识“碎片化”,使其在相邻 token 间更连贯。
操作上,使用一个很小的因果卷积核(论文中 kernel size=4)在序列 𝐯̃_t 上滑动,混合窗口内的几个知识向量,生成一个更连贯的新表示。最后通过一个带有 SiLU 激活的残差连接将处理后的知识注入回主干网络。
Y = SiLU( Conv1D(RMSNorm(Ṽ)) ) + Ṽ
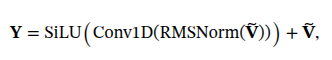
简单总结:门控决定 “每个词该注入什么知识” ,卷积则确保 “这些知识在连续的几个词之间连贯自然” 。
3.4 与多分支架构的集成
当模型主干采用多分支架构(如并行处理的 FFN 分支)时,Engram 可以优雅地集成。每个分支可以拥有自己独立的门控/键投影权重,但 共享同一份静态的嵌入查找表(Engram 的值投影矩阵 Wᵥ),这提高了参数效率。
3.5 系统效率:计算与内存的解耦
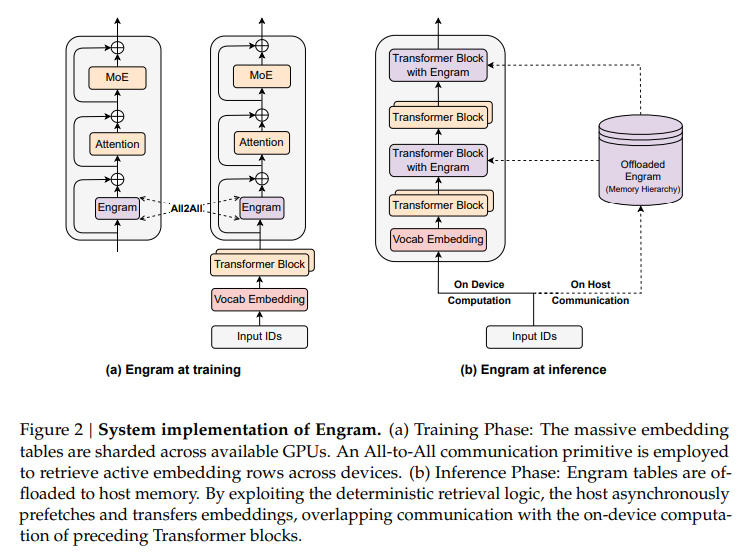
Engram 在系统层面的设计充分考虑了训练和推理的效率:
- 训练阶段:Engram 记忆表作为模型参数的一部分,与 Transformer 主干一起进行端到端训练。由于表规模巨大,它被切分并分布在多张 GPU 上,通过 All-to-All 通信原语进行同步更新。
- 推理阶段:此时 Engram 的参数已冻结,且其访问索引仅依赖于确定的输入 token。因此,巨大的记忆表无需常驻 GPU 显存,可以卸载到主机内存甚至更慢的存储层次中。系统利用其确定性检索逻辑,异步预取所需的嵌入向量,从而将通信开销与设备上前一个 Transformer 块的计算重叠起来,在显著降低显存占用的同时不损失性能。
4 MoE 与 Engram 的最佳分配比例
在一个固定的总参数和计算预算下,一个关键问题是:如何在 MoE 专家和 Engram 记忆模块之间分配稀疏参数预算,才能使模型性能最优?
实验发现,验证损失与分配比例 ρ(分配给 Engram 的参数比例)之间呈现出 明显的 U 形曲线关系。
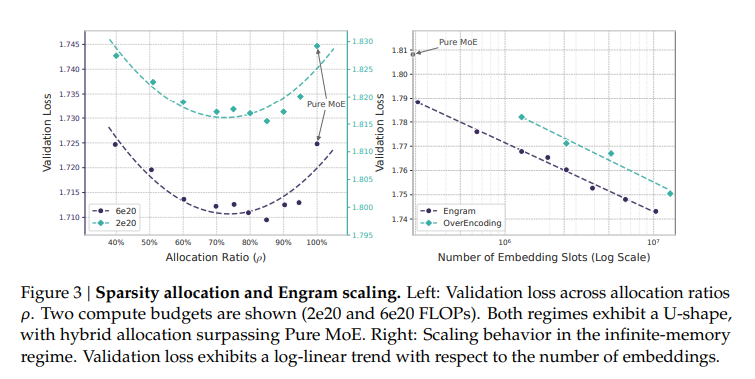
最优点大约在 ρ ≈ 20% – 25%,即把大约 20%–25% 的稀疏参数分配给 Engram,剩下的 75%–80% 留给 MoE。此时模型的验证损失最低,综合表现最佳。后续的大规模实验模型也采用了这一配比。
5 实验结果
论文进行了全面的实验,对比了 Dense 模型、纯 MoE 模型以及加入 Engram 的混合模型。在总激活参数量(计算量)严格对齐的前提下,Engram 模型在知识、推理、代码数学等多个维度上均表现出显著优势。
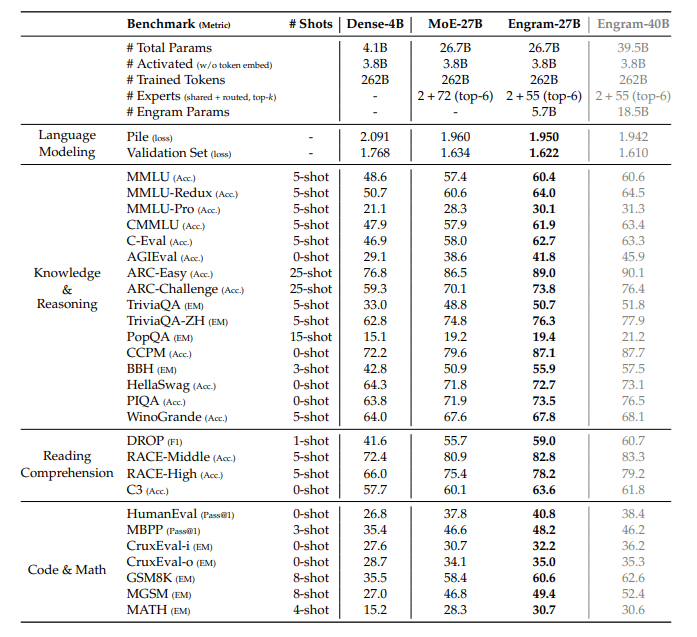
上表显示,在同等计算量(激活参数量 ~3.8B)下,Engram-27B 模型在 MMLU、C-Eval、GSM8K、MATH 等核心评测上,性能全面超越参数量相近的 MoE-27B 模型,甚至逼近或超越计算量更大的 Dense 模型。这验证了“计算与记忆解耦”这一新稀疏维度的有效性。
这项研究为 Deep Learning 模型架构探索开辟了新的方向,将静态记忆作为与动态计算并列的核心设计要素。对于从事大模型研究与系统优化的开发者而言,深入理解 Engram 的设计思想,无疑能拓宽对下一代模型设计的认知。更多前沿的技术解读与深度讨论,欢迎在 云栈社区 的 计算机科学 板块交流探索。
 发表于 2026-1-27 13:04:14
|
查看: 206|
回复: 0
发表于 2026-1-27 13:04:14
|
查看: 206|
回复: 0
