2026 年 1 月 26 日,微软正式发布其首款专为 AI 推理定制的自研芯片——Maia 200。这不仅是微软在定制硅领域的重大突破,更标志着云计算巨头正将性能优化推向一个全新维度:从通用硬件到场景专属,从追求峰值算力到极致能效比。

这款基于 TSMC 3nm 工艺打造的 AI 加速器,号称能提供比当前 Azure 舰队中最新一代硬件高出 30% 的“性能每美元”表现。
它并非训练芯片,而是精准瞄向了正在爆发的 AI 推理 市场——那些运行着的 ChatGPT 对话、文档总结、代码生成和智能助手。想了解更多前沿技术动态和深度解析,欢迎访问云栈社区。
一、为什么是“推理专用芯片”?
AI 工作负载正日益分化。训练任务如同“建造大脑”,需要海量数据和算力进行一次性、长时间的高强度计算;而推理任务则是“运用大脑”,需要低延迟、高吞吐、持续稳定地处理无数用户的实时请求。
微软在官方博客中指出:“AI 推理正日益由一个‘效率前沿’所定义——这是一条衡量在给定成本、延迟和能量水平下,能交付多少实际能力和准确性的曲线。”
不同的应用场景坐落在这条曲线的不同位置:
- 交互式 Copilot(如微软 365 Copilot):优先考虑低延迟响应。
- 批量摘要与搜索:强调在给定成本下的高吞吐量。
- 高级推理工作负载:需要在长上下文和多步执行下保持持续高性能。
企业级的 AI 部署不再是“一刀切”,它需要一种组合方案,以规模化提供最高性能、最低成本的基础设施。Maia 200 正是这一理念的产物——它不是万能的,而是在自己最擅长的推理战场上做到了极致。
二、Maia 200 架构揭秘:为效率而生的全栈创新
Maia 200 的成功并非单点突破,而是软件、硅芯片、系统、数据中心跨栈协同创新的结果。其架构设计充满了对 AI 推理工作负载的深刻理解。
1. 峰值规格:定义行业新标杆
根据技术文档中提供的峰值规格表,Maia 200 的关键指标令人瞩目:
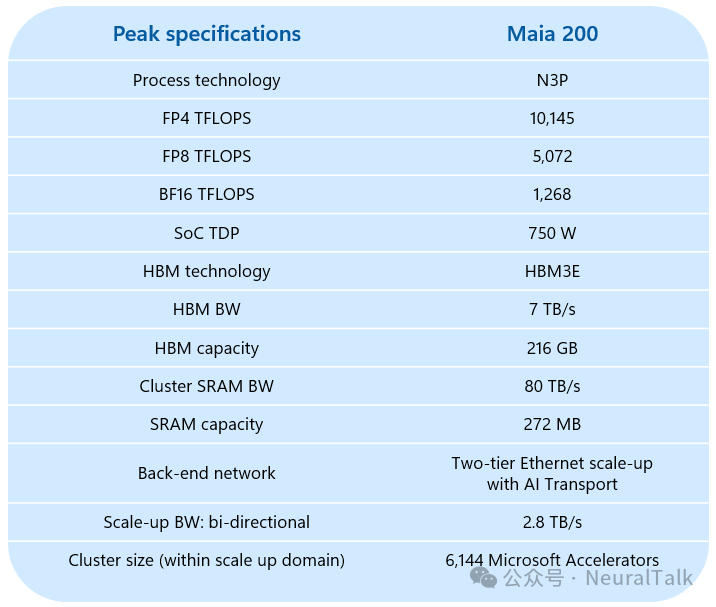
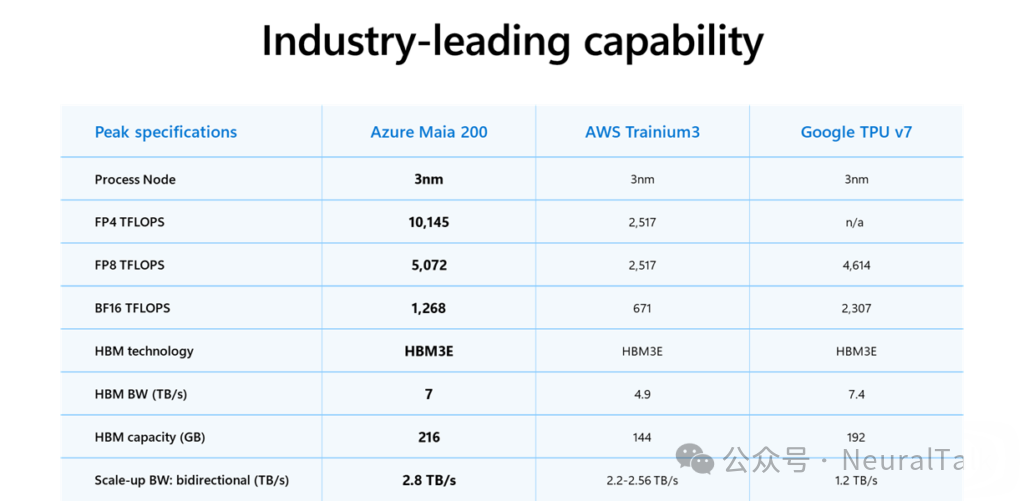
这些数字背后是清晰的战略:拥抱窄精度计算,最大化内存带宽,构建可扩展的互联。其 FP4 算力号称是第三代 Amazon Trainium 的 3 倍,FP8 性能也超越 Google 第七代 TPU。
2. 核心架构:层次化微架构与高效执行引擎
Maia 加速器围绕一个层次化微架构构建。最基础的单元是Tile(计算块),这是最小的自主计算和本地存储单元。
每个 Tile 包含两个互补的执行引擎:
- Tile Tensor Unit:用于高吞吐量的矩阵乘法和卷积运算。
- Tile Vector Processor:作为高度可编程的 SIMD 引擎,支持 BF16、FP16、FP32 等更高精度计算。
这些引擎由多存储体的 Tile SRAM 和一个 Tile 级 DMA 子系统提供数据,确保数据移动不阻塞计算流水线。一个轻量级的 Tile 控制处理器负责协调工作。
多个 Tile 组成一个Cluster,共享一个更大的 Cluster SRAM。整个 SoC 则由多个 Cluster 实例化而成。这种设计不仅追求峰值性能,还通过内置的 Tile 和 SRAM 冗余方案提高了芯片的可制造性和良率。
3. 内存子系统革命:用巨大的片上缓存“喂饱”算力
AI 计算的瓶颈往往不在算力,而在“喂数据”的速度。Maia 200 一个标志性特征是它重新设计的内存层次结构。
它集成了高达272MB 的片上 SRAM,并分区为集群级和 Tile 级 SRAM。这片巨大的片上资源使得一系列低延迟、高带宽的数据管理策略成为可能。
软件可以确定性地放置和固定数据,实现精准的局部性控制。例如:
- GEMM 核:可将中间矩阵块保留在 Tile SRAM 中,避免访问 HBM 甚至集群 SRAM,显著提升计算强度。
- 注意力核:可尽可能将 Q/O、K/V 张量及部分 Q-K 乘积固定在 Tile SRAM 中,最小化注意力机制中的数据移动开销。
- 集体通信核:可在集群 SRAM 中缓冲完整负载,同时在 Tile SRAM 中进行累加,减轻 HBM 压力。
这种软件管理的、巨大的片上缓存,是 Maia 实现高计算效率和确定性性能的关键,即使模型架构和序列长度越来越复杂。
4. 数据移动架构:专用 DMA 与定制片上网络
为了在计算块、SRAM、HBM 和 I/O 之间高效、可预测地移动数据,Maia 200 设计了一个定制化的片上网络和分层 DMA 引擎子系统。
片上网络是一个覆盖所有集群、Tile、内存控制器和 I/O 单元的网状网络,被划分为多个逻辑平面,包括用于大数据传输的高带宽数据平面和用于控制信号的专用控制平面。这种分离确保了关键的延迟敏感型控制流量永远不会被批量数据传输阻塞。
其创新包括:
- 高效的 HBM 到集群广播:数据从 HBM 读取一次,即可扇出到多个集群 SRAM,避免重复读取。
- 本地化高带宽集群流量: hottest 的数据移动被限制在集群内部完成。
- Tile 间 SRAM 直接访问:允许直接读写对等 Tile 的 SRAM,实现高效广播、规约和状态更新。
分层 DMA 引擎则包括负责细粒度传输的 Tile DMA、在集群 SRAM 和 HBM 间穿梭的 Cluster DMA,以及管理片外链路的 Network DMA。它们协同工作,确保计算单元在各种负载下都能“吃饱”。
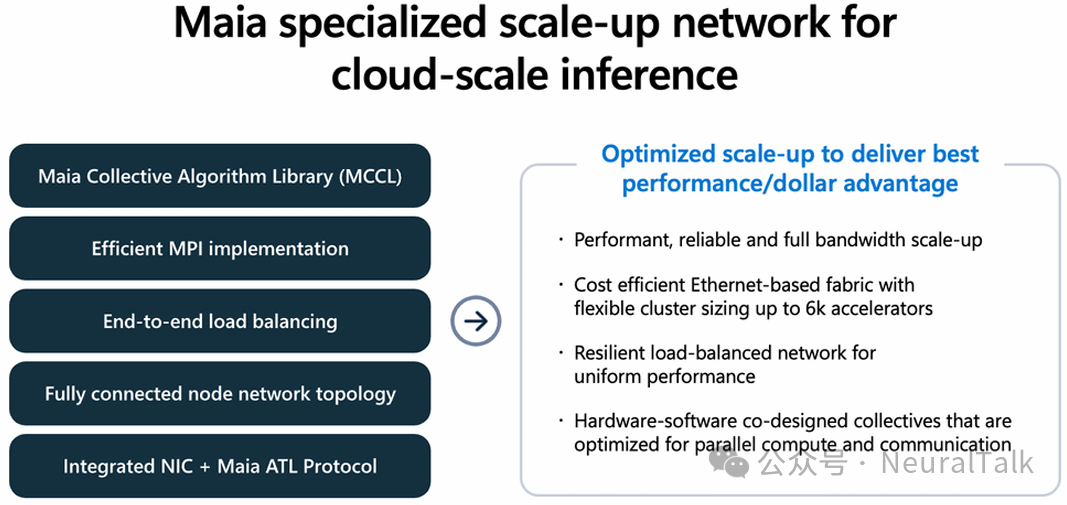
5. 扩展互联:基于以太网的创新二层架构
Maia 200 摒弃了昂贵且封闭的专有互联方案,选择基于标准以太网,构建了一个高性能、可靠的二层扩展互联。
其核心是集成在芯片上的网络接口控制器和专为 AI 优化的AI 传输层协议。片上 NIC 提供了 1.4 TB/s 单向带宽,消除了外置 NIC 的功耗和成本开销。
其网络拓扑分为两层:
- 全连接象限:四个加速器通过直接的、非交换的链路完全连接,保持高带宽通信本地化。
- 交换层:将连接扩展到最多 6,144 个加速器,支持大型模型跨节点分片。
这种设计带来了三大优势:
- 带宽优化与开销降低:高强度的张量并行流量被限制在 FCQ 组内。
- 大规模推理无需训练级成本:避免了扩展网络带来的功耗和复杂性负担。
- 与工作负载匹配的网络行为:满足了推理所需的适度同步,而非训练所需的极端全对全压力。
顶层的微软集体通信库(MCCL)与硬件协同设计,通过计算-I/O 重叠、分层集体操作、动态算法选择等技术,进一步优化了大规模并行通信的性能。
三、系统与软件:云原生的深度集成
Maia 200 不仅仅是一颗芯片,更是一个深度集成到 Azure 的云原生系统。
1. 硬件系统:标准化与可部署性
在硬件层,Maia 200 与 Azure 的第三方 GPU 系统协同设计,遵循标准化的机架、电源和机械架构。这使得它能够轻松部署在微软最大的 AI 和 GPU 舰队所在的同一云计算基础设施中,无需定制化基础设施。
其散热设计支持风冷和液冷数据中心,包括为高密度机架设计的第二代液冷侧挂方案,确保了在现有和下一代数据中心中的广泛部署能力和一致性性能。
2. 软件栈:面向开发者的全链路工具
Maia 的软件栈旨在让云开发者无缝采用。其软件开发套件为在 Maia 硬件上构建、优化和部署开源及专有模型提供了全面的工具链。
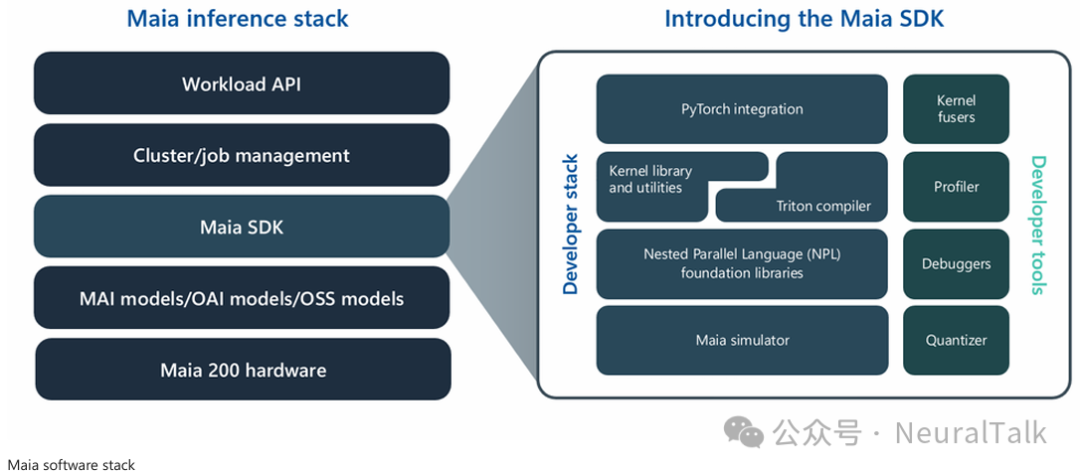
工作流程从 PyTorch 开始,开发者可以根据需要选择抽象层级:
- Maia Triton 编译器:用于快速生成内核。
- 高度优化的内核库:针对 Maia 的 Tile 和集群架构进行了调优。
- 微软嵌套并行语言:用于显式控制数据移动、SRAM 放置和并行执行,以实现接近峰值的利用率。
SDK 还包括全系统模拟器、编译器流水线、性能剖析器、调试器以及强大的量化和验证套件,使团队能够在流片前对模型进行原型设计。
四、意义与展望:定义 AI 基础设施的未来
Maia 200 的发布,是微软“从模型到软件,从硅到数据中心”全栈优化能力的集中展示。它证明了在 AI 时代,基础设施的领导力来自于跨整个技术栈的统一系统与工作负载优化。
- 对于行业而言,Maia 200 标志着云计算巨头正将竞争从单纯的算力规模,推向更深层次的能效比、总拥有成本和经济性。推理专用芯片的崛起,将加速 AI 从训练到大规模应用的落地。
- 对于开发者与客户而言,这意味着更经济、更高效、更可靠的 AI 服务。Maia 200 将服务于包括 OpenAI 最新 GPT-5.2 在内的多种模型,为 Microsoft Foundry 和 Microsoft 365 Copilot 等产品带来直接的成本与性能优势。
正如微软执行副总裁斯科特·格思里所言:“大规模 AI 时代刚刚开始,基础设施将定义什么是可能的。” Maia 200 是这一多代计划的第一步,它不仅仅是一颗芯片,更是微软构建世界上能力最强、效率最高、最可扩展的云平台的基石,为 AI 的未来奠定了坚实的地基。
 发表于 2026-1-28 06:11:29
|
查看: 173|
回复: 0
发表于 2026-1-28 06:11:29
|
查看: 173|
回复: 0
