本文将以 bert-base-chinese 模型为例,深入探讨自然语言处理中的核心组件——Tokenizer。我们将从它的基本作用、内部机制一直讲到主流的分词类型,帮助你由浅入深地理解模型是如何“读懂”文本的。
一、BERT-base-chinese 模型简介
bert-base-chinese 是 Google 在 2018 年发布的原始 BERT 模型之一,专门针对中文文本进行预训练。它使用中文维基百科和通用文本语料,通过掩码语言建模(MLM)任务和下一句预测(NSP)任务训练而成。
选择这个模型为例有三个原因:
- 它的 tokenizer 设计相对直观,便于理解核心概念。
- 模型本身带有中文优化,能很好地体现中英文处理的差异。
- 其他 NLP 模型的 tokenizer 在实现和附加功能上可能有所不同,但主要目的是一致的,正所谓“换汤不换药”。
预训练任务
该模型主要包含两个预训练任务:
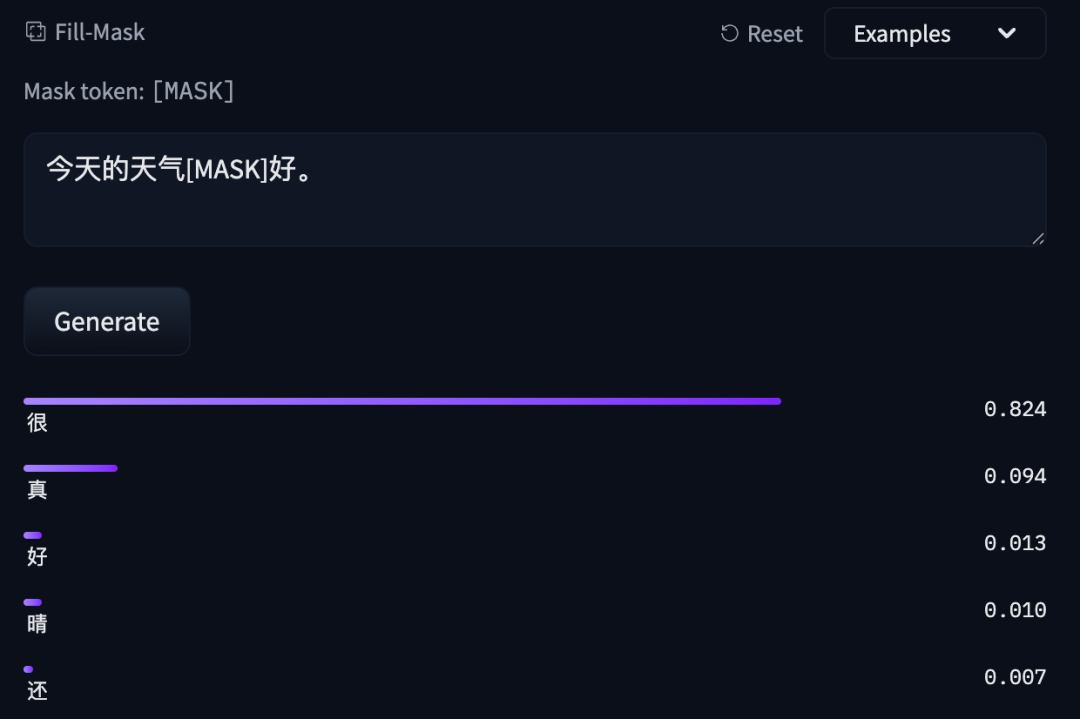
- MLM(掩码语言建模)任务:输入一句带有掩码的句子,模型输出掩码位置可能字符的概率。
-
NSP(下一句预测)任务:输入A、B两句话,判断B是否是A的下一句,本质上是一个二分类(是/不是)任务。
tokenizer = BertTokenizer.from_pretrained(model_path)
model = BertForNextSentencePrediction.from_pretrained(model_path)
text_A = "今天天气很好"
text_B = "我们一起去公园玩"
encoding = tokenizer(text_A, text_B, return_tensors='pt')
outputs = model(**encoding)
probs = torch.softmax(outputs.logits, dim=-1)
if torch.argmax(probs) == 0:
print("B是A的下一句")
else:
print("B不是A的下一句")
>> B是A的下一句
支持的下游任务
除了预训练任务,它还支持多种下游任务:
- SC(序列分类):如文本分类、情感分析、自然语言推理(NLI)。
- TC(Token分类):如命名实体识别(NER)、词性标注(POS)。
- QA(问答):如抽取式问答(SQuAD)。
- MC(多项选择):从多个候选答案中选择一个正确答案。
二、为什么需要 Tokenizer?
NLP模型在训练和推理时,真正“喂进去”的都是数字——即 token ids。当然,模型可能还需要其他输入特征,例如在BERT中:
token type idsattention maskposition index
Tokenizer 的核心职责,就是决定如何将原始文本转换成这些 token ids 及其他输入特征。 所有模型都需要 token ids,但生成它们的方式却可以多种多样。
三、Tokenizer 做了什么?
可以把 Tokenizer 的工作拆解为以下几个核心作用:
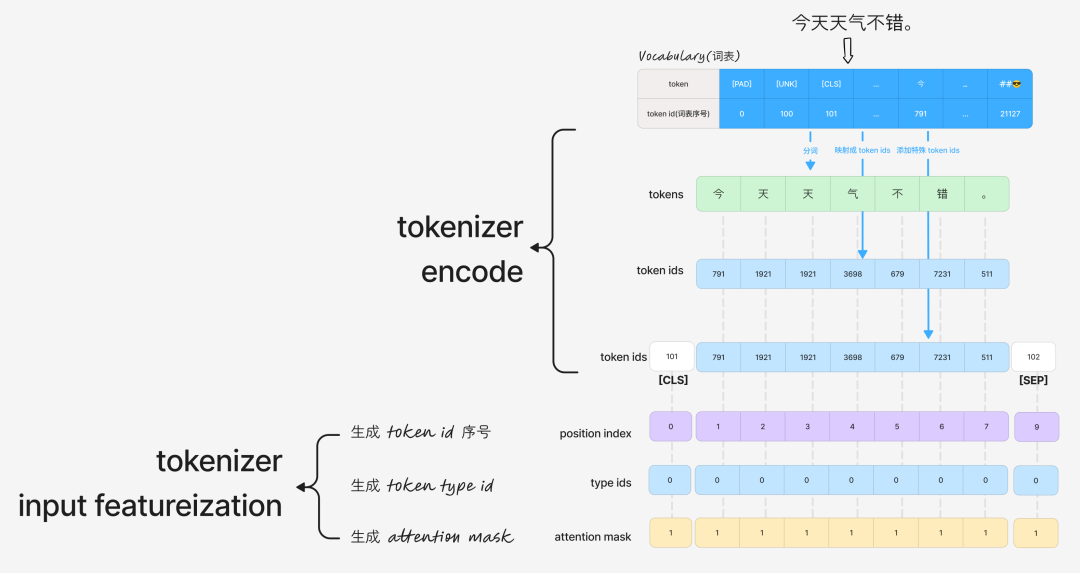
作用 1:分词 (Tokenization)
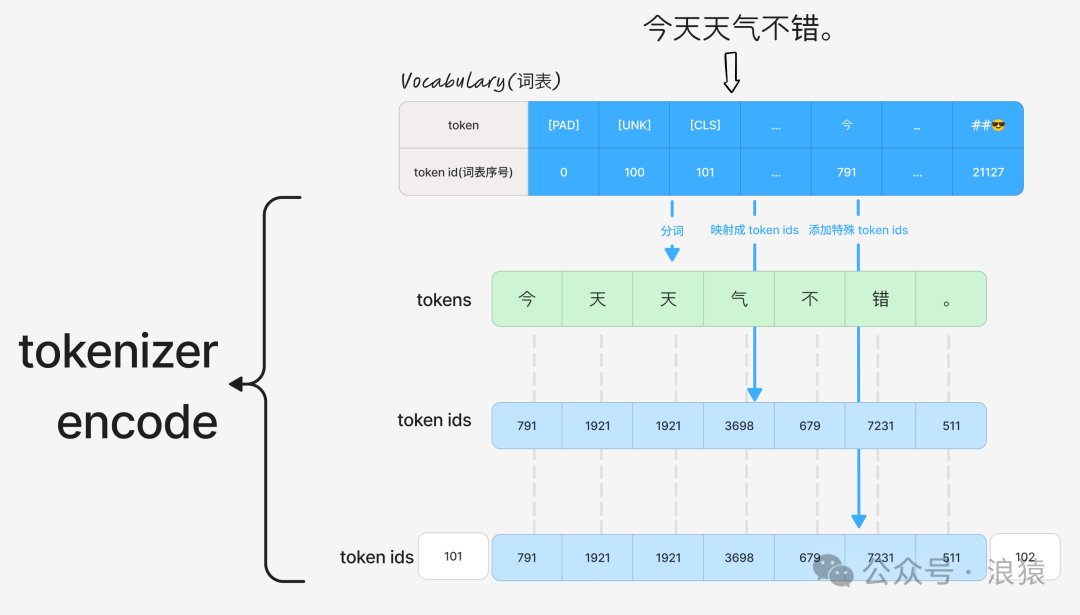
Tokenizer 的第一步是通过词表 (Vocabulary) 把自然语言文本切分成最小的语义单元,即 token。词表是一个包含了所有已知 token 及其对应 ID 的映射表。
这个过程很像人类学习语言:从单字到词语,再到句子和篇章。因此,把文本合理地分成 token 至关重要。
让我们用代码实验一下:
# 生成一个 bert-base-chinese 的 tokenizer
tokenizer = AutoTokenizer.from_pretrained("./bert-base-chinese/")
# 测试中文
text = " 今天天气不错。 "
tokens = tokenizer.tokenize(text)
print(tokens)
>> ['今', '天', '天', '气', '不', '错', '。']
# 测试英文
text = "today is cloudy."
tokens = tokenizer.tokenize(text)
print(tokens)
>> ['today', 'is', 'cloud', '##y', '.']
可以看到,中文被分成了7个「单字」和「标点」。而英文单词“cloudy”被拆分成了 “cloud” 和 “##y”,这里的 “##” 表示该子词是某个单词的一部分。
提示:分词前通常会有预处理,例如实验中文本首尾的空格就被去掉了。
作用 2:Tokens 映射成 Token IDs
Tokenizer 通过查询词表,将上一步得到的 tokens 映射成对应的 token ids。这是最核心的一步。
tokenizer = AutoTokenizer.from_pretrained("./bert-base-chinese/")
ids = tokenizer.encode("今天天气不错。", add_special_tokens=False)
print(ids)
>> [791, 1921, 1921, 3698, 679, 7231, 511]
提示:这个 token id 就是 token 在词表中的序号。
作用 3:特殊 Token 组装
映射成基础 token ids 后,还需要加入一些具有特殊功能的 token ids。
tokenizer = AutoTokenizer.from_pretrained("./bert-base-chinese/")
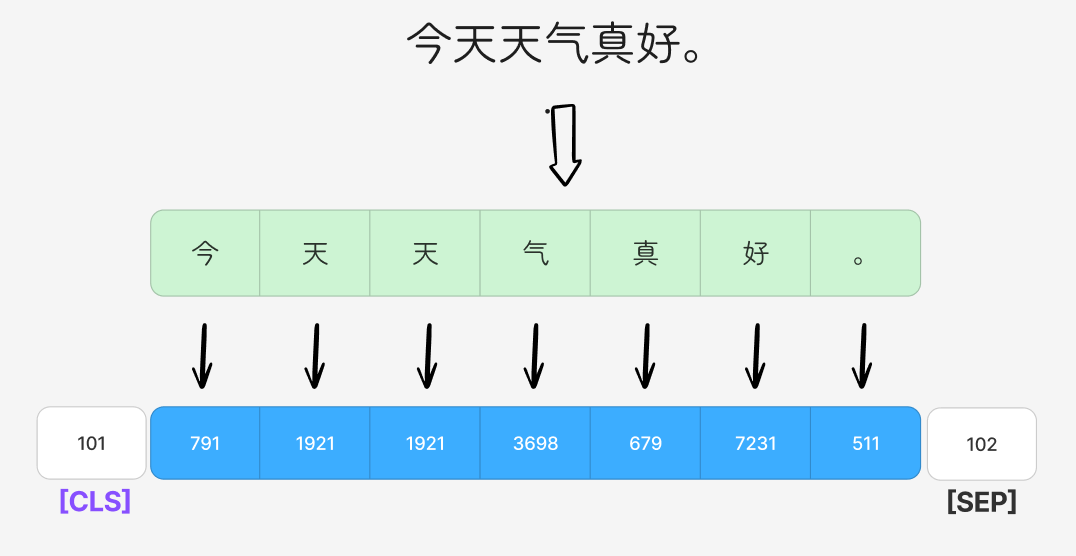
ids = tokenizer.encode("今天天气不错。", add_special_tokens=True)
print(ids)
>> [101, 791, 1921, 1921, 3698, 679, 7231, 511, 102]
明明只有7个 tokens,却输出了9个 ids。让我们转回 tokens 看看:
# 再使用 convert_ids_to_tokens 转回 token 看下
tokens = tokenizer.convert_ids_to_tokens(ids)
print(tokens)
>> ['[CLS]', '今', '天', '天', '气', '不', '错', '。', '[SEP]']
原来前后各多了一个 [CLS] 和 [SEP],这就是特殊 token。在 BERT 模型中,常见的特殊 token 包括:
-
[MASK]:用于预训练的掩码占位符。推理时也可使用,例如输入“今天的天气[MASK]好。”,模型会预测[MASK]位置最可能的字。
-
[CLS]:分类标记。通常位于序列开头,其最终的隐藏状态被用作整个序列的聚合表示,供下游分类任务使用。
-
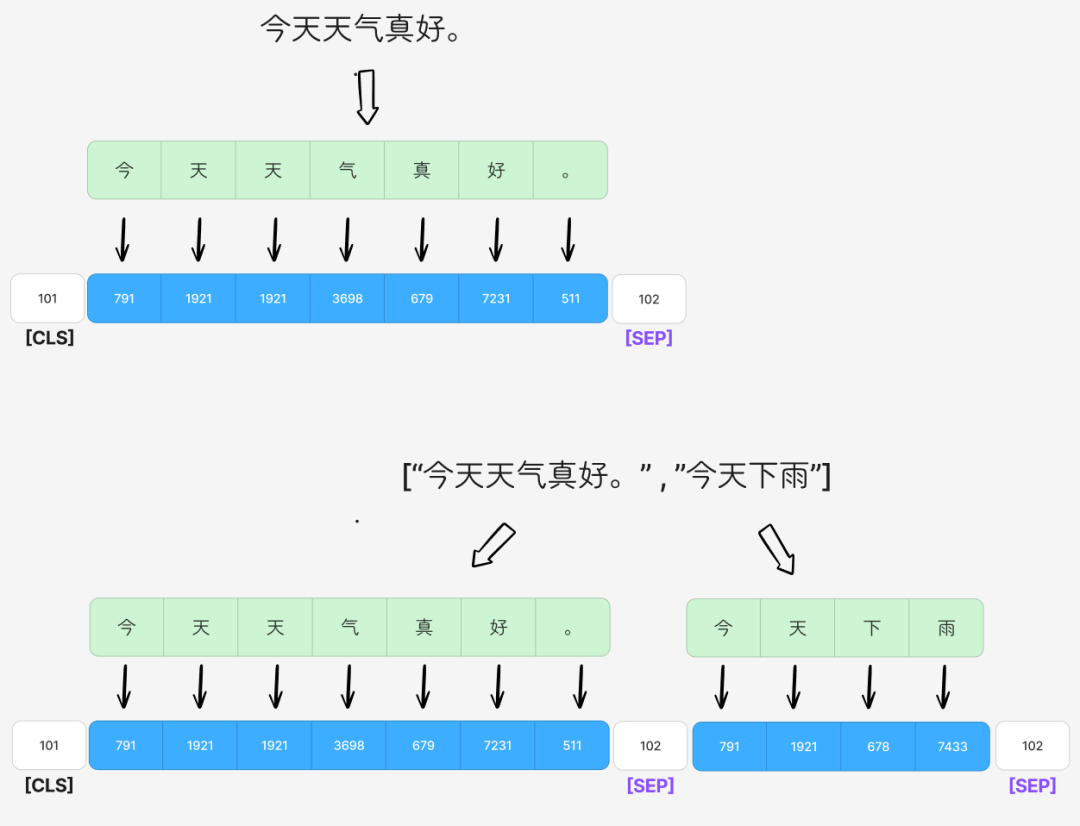
[SEP]:分隔符。用于区分句子对中的不同句子,例如在NSP或NLI任务中。
-
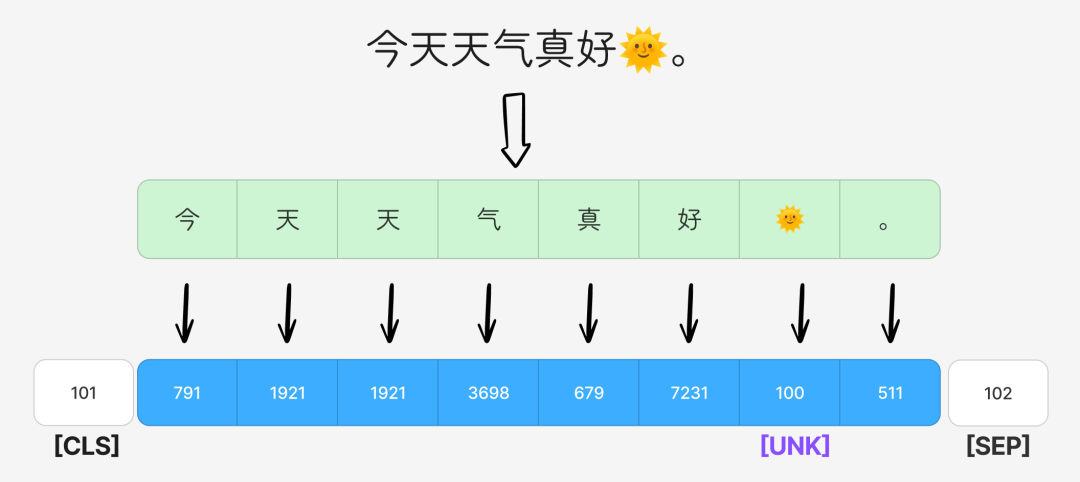
[UNK]:未知词标记。当遇到词表中不存在的词(OOV, Out-of-Vocabulary)时使用。
-
[PAD]:填充标记。在批量处理时,用于将不同长度的句子填充到同一长度,以便组成张量。
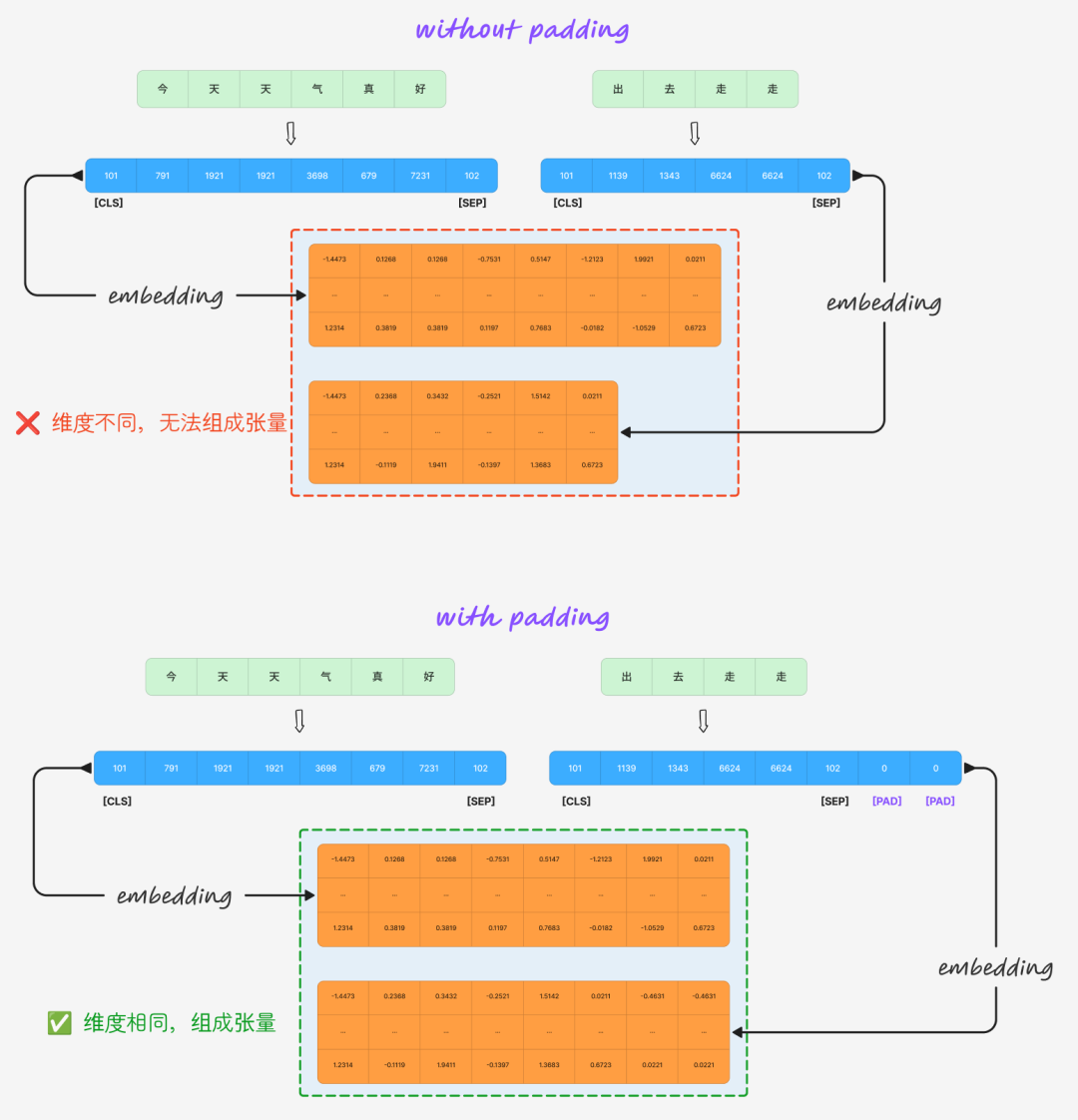
提示:分词、Tokens映射到Token IDs、特殊Token组装,这三步一起被称为 Tokenizer 的 编码(Encode) 过程,它们都依赖于词表(Vocabulary)。
作用 4:生成注意力遮罩 (Attention Mask)
你可能会问,如果句子中本身就有 [PAD] 这个词怎么办?attention mask 就是用来解决这个问题的。它告诉模型在计算注意力时应该忽略哪些位置(通常是填充的位置)。
例如,对于句子“[PAD]是特殊的”:
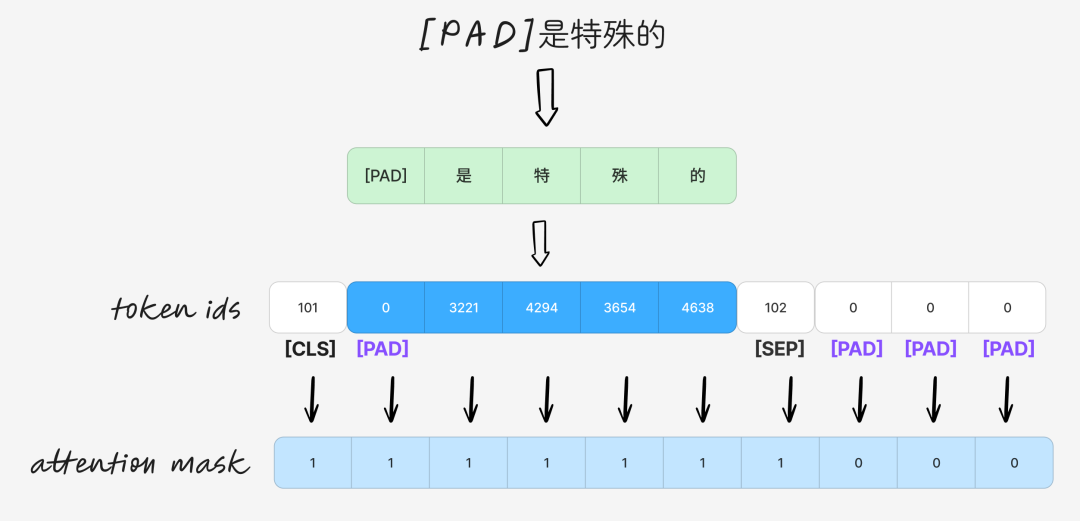
在 Self-Attention 计算中,通过 attention mask 对被屏蔽位置(mask值为0)加上一个极小的负值,使得经过 Softmax 后这些位置的注意力权重趋近于0,从而阻止模型关注它们。如果你了解 Decoder-Only 模型,会发现因果掩码(Causal Mask)的原理与此类似。
作用 5:生成 Token 位置序号 (Position Index)
Self-Attention 机制本身不具备位置感知能力。因此,需要将位置向量(Position Embedding) 加到每个 token 的向量上。而 token position index 就是用来查找(Look Up)对应位置向量的索引。
作用 6:生成 Token Type ID
对于需要输入句子对的任务(如NSP),token type id 用来区分当前 token 属于第一个句子还是第二个句子。它用于查找分段向量(Segment Embedding),该向量也会被加到 token 的向量上。
第一句的所有 token 的 token type id 为 0,第二句的所有 token 为 1。
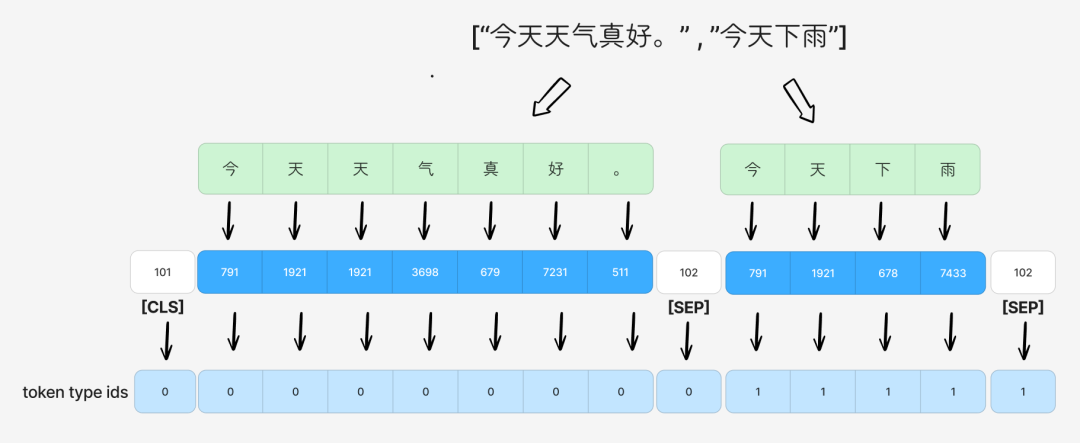
提示:生成 Token ID 序号(Position Index)、生成 Token Type IDs、生成 Attention Mask,这三步一起被称为 Tokenizer 的 输入特征化(Input Featureization)。
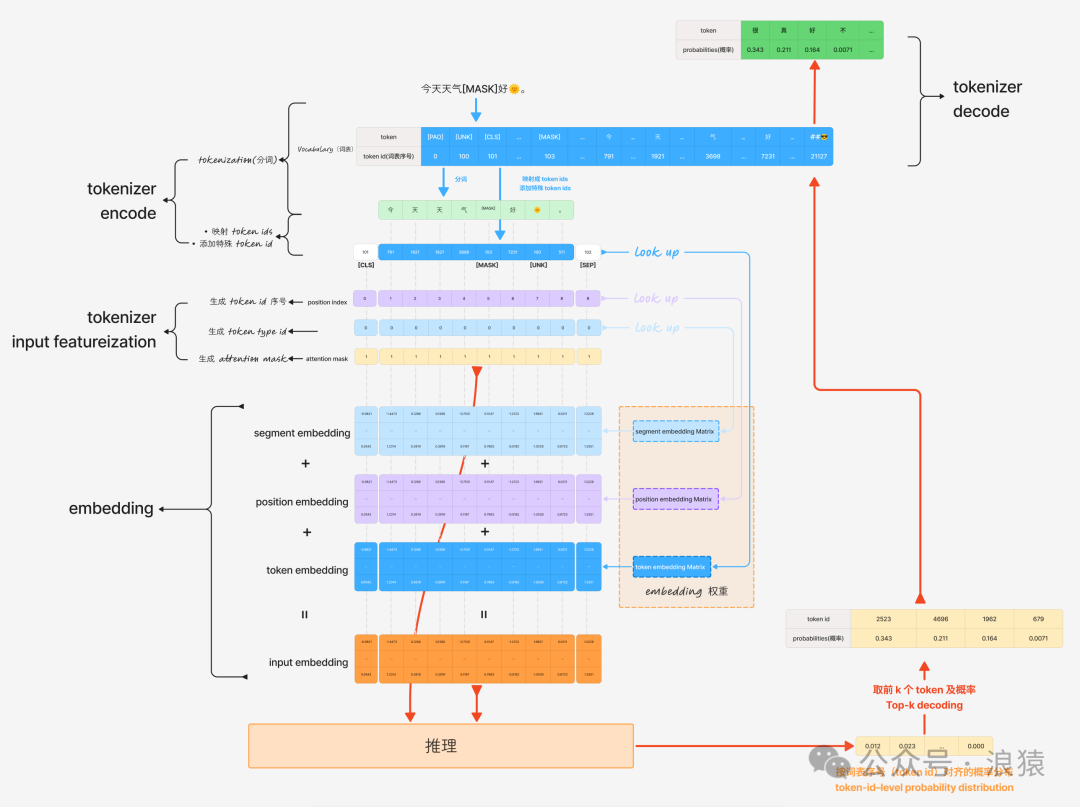
作用 7:Token IDs 映射回 Tokens(解码)
通过词表将 token ids 映射回 tokens,这一步被称为 Tokenizer 的解码(Decode)。并非所有任务都需要这一步:
- 需要解码的任务:MLM、TC、QA,它们的输出直接是 token ids。
- 不需要解码的任务:SC、MC、NSP,它们的输出是类别标签 id。
提示:综上所述,BERT 模型的 Tokenizer 主要完成以下工作:
- 分词:将句子切分为 tokens。
- 映射与组装:将 tokens 映射为 token ids,并添加特殊 token ids(用于检索 Token Embedding)。
- 生成位置信息:生成 position index(用于检索 Position Embedding)。
- 生成句子信息:生成 token type id(用于检索 Segment Embedding)。
- 生成注意力控制:生成 attention mask(用于在 Self-Attention 中屏蔽无意义的 token)。
- 解码:将 token ids 映射回 tokens(并非所有任务必需)。
四、Tokenizer 有哪些类型?
Tokenizer 是模型理解文本的“第一道工序”,其分词策略(“切割刀法”)决定了模型看到的是“词”、“字”还是“子词”,直接影响模型的认知方式。当我们讨论不同类型时,核心是在评估它们如何生成词表,因为这直接关系到两个根本问题:
- Token 的界定:最小的处理单元是什么?
- Vocabulary 的构建:如何从语料中生成一个大小固定且高效的词表?
提示:词表的 生成方式 和 使用方式 共同影响着 Tokenizer。虽然理论上可以任意组合,但实践中存在一些自然适配的配对。我们主要关注生成方式。
词级分词 (Word-based)
字符级分词 (Character-based)
子词级分词 (Subword-based)
这是目前最主流的分词方式,旨在词级和字符级之间取得平衡。它将“词”拆分为有意义的“子词”单元。
1. WordPiece
- 使用模型:BERT, ALBERT, DistilBERT。
- 构建方式:从字符开始,迭代合并那些能最大程度提升语言模型似然值的相邻符号对。
- 特点:
- 有效缩减词表,保留较多语义信息(如
token, ##ization能共享-ization后缀的语法信息)。
- 能部分解决OOV问题(通过子词组合新词)。
- 对于完全无法拆分的生僻词或特殊符号,仍会标记为
[UNK]。
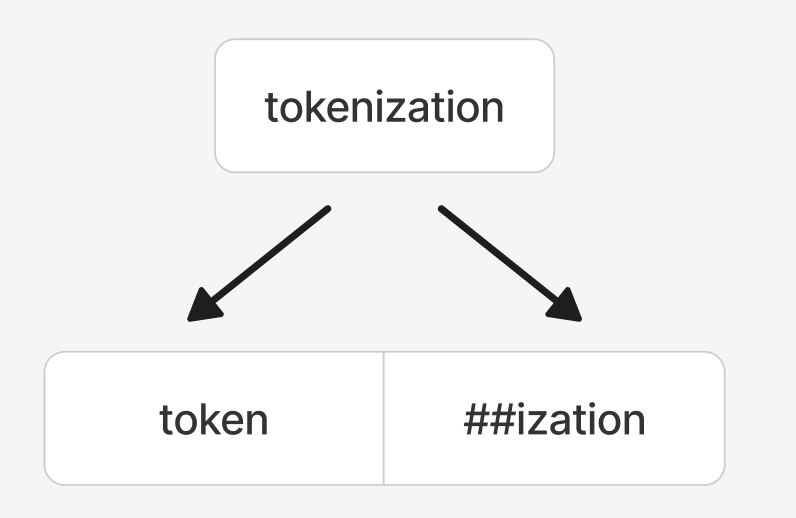
提示:Google官方指出,bert-base-chinese对中文实际采用字符级(Character-based),对其他语言采用WordPiece,是一种混合策略。
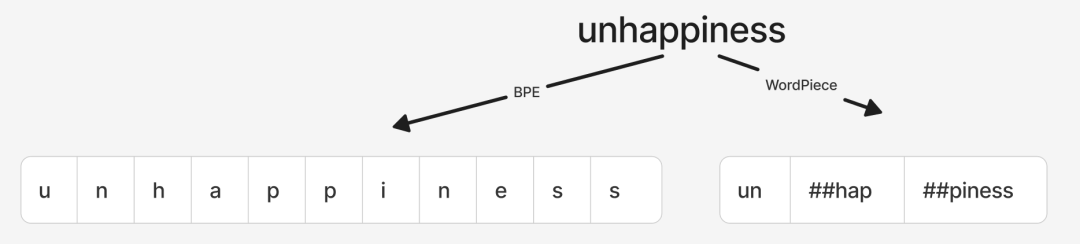
2. BPE (Byte-Pair Encoding)
- 使用模型:GPT-1, 早期机器翻译模型。
- 构建方式:从字符开始,迭代合并出现频率最高的相邻符号对。
- 特点:
- 词表颗粒度通常比WordPiece更细。
- 对未知词的拆分能力更强(例如,
unhappiness可能被拆为更细的字符序列)。
- 但拆出的子串可能不够自然,语义信息较少。
3. Byte-level BPE (BBPE)
- 使用模型:GPT-2及以后系列、Qwen系列。
- 构建方式:BPE的升级版,将“最小单位”从字符变为字节(通常采用UTF-8编码)。这意味着所有文本在最初都被视为字节序列。

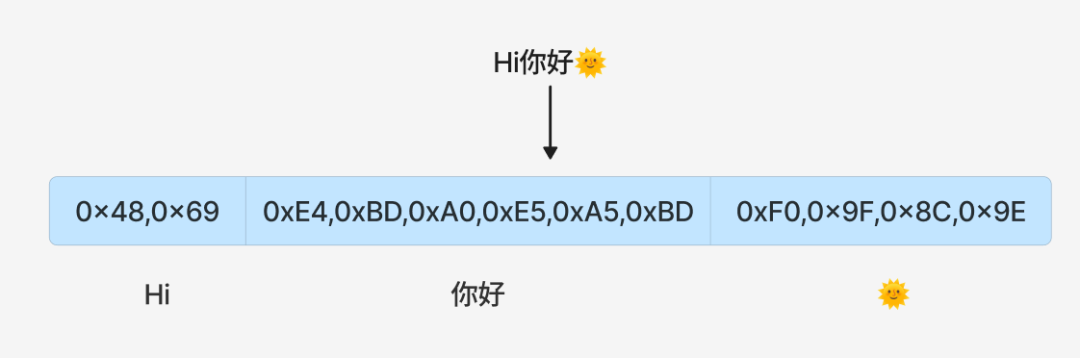
- 特点:
- 彻底解决OOV问题:理论上可以表示任何能用UTF-8编码的字符,包括Emoji、罕见符号等。
- 天然多语言友好。
- 词表可以更小。
- 初始分割在字节级别,完全不保留显式的语言单元(词/字),所有语义依赖模型从海量数据中自行学习,因此对模型容量和数据规模要求极高,主要用于大语言模型(LLM)。
结语
Tokenizer 作为连接人类语言与机器计算的桥梁,其设计和选择深刻影响着模型的性能与效率。从基于规则的分词到基于统计的子词切分,再到完全基于字节的表示,演进历程反映了NLP领域追求更高泛化能力和多语言支持的努力。理解这些基础知识,是深入使用和调优各类Transformer架构模型的基石。
希望这篇文章能帮助你建立起对 Tokenizer 的系统认识。如果你想了解更多关于模型实现或开源社区中常见的Tokenization算法实现,欢迎在技术社区继续探索与交流。
 发表于 2026-1-28 06:42:36
|
查看: 210|
回复: 0
发表于 2026-1-28 06:42:36
|
查看: 210|
回复: 0
