对于国产 GPU 行业来说,当下正处在一个极为关键的时期。在政策支持硬科技企业上市的背景下,行业迎来了难得的上市黄金窗口期。然而,上市只是一个起点。当企业站上公开市场的那一刻,更为严酷的技术与产品考验才刚刚开始——其技术路线、产品能力乃至长期战略,都将被置于聚光灯下,接受市场与用户的严苛审视。
天数智芯上市后的首场技术发布会,之所以能在业内引发广泛讨论,正是因为其以一种工程师式的务实风格,将“架构”重新置于国产 GPU 技术叙事的中心。在 1 月 26 日召开的“智启芯程”合作伙伴大会上,关于架构层的创新与思考占据了相当的比重。基于这些思考,天数智芯清晰规划了其过去一代及未来三代的架构演进路线图:
- 2025 年,天数天枢架构已经超越英伟达 Hopper,在 DeepSeek V3 场景中的实测性能数据超出 20%;
- 2026 年,天数天璇架构对标 Blackwell,新增 ixFP4 精度支持;
- 2026 年,天数天玑架构超越 Blackwell,覆盖全场景 AI/加速计算;
- 2027 年,天数天权架构超越 Rubin,支持更多精度与创新设计。

国产 GPU,开启 AI++ 计算新范式
根据天数智芯公布的路线图,其策略相当明确:在 2027 年之前,通过多代产品实现对英伟达的全面追赶;在 2027 年之后,则转向更具创新性的架构设计,聚焦突破性的超级计算芯片。这条路径看似宏大,实则务实——只有先在工程化能力和性能上完成对标乃至超越,国产 GPU 才有资格进入更大规模的生产环境,应对真实业务挑战。
而当竞争进入规模化落地阶段,焦点早已从纸面的峰值性能指标,转向了真实的“有效计算能力”。在 AI 时代,Token 成为基本的生产资料,算力消耗必须对标真实的业务产出。无论是国际巨头还是国内厂商,共同的核心命题只有一个:如何在真实业务中,高效地将算力转化为有效的 Token。
围绕这一命题,天数智芯提出了两条明确的架构判断:其一,回归计算本质;其二,提供高质量算力。
回归计算本质,核心在于“不设限”
过去十年的算力发展带有一定的“野蛮生长”色彩,虽然带来了产业繁荣,但也导致了能效比失衡、资源浪费等问题。幻想计算任务永远运行在理想环境中是不切实际的,产业真正需要的,是能够适应各种复杂场景的“全能越野车”。
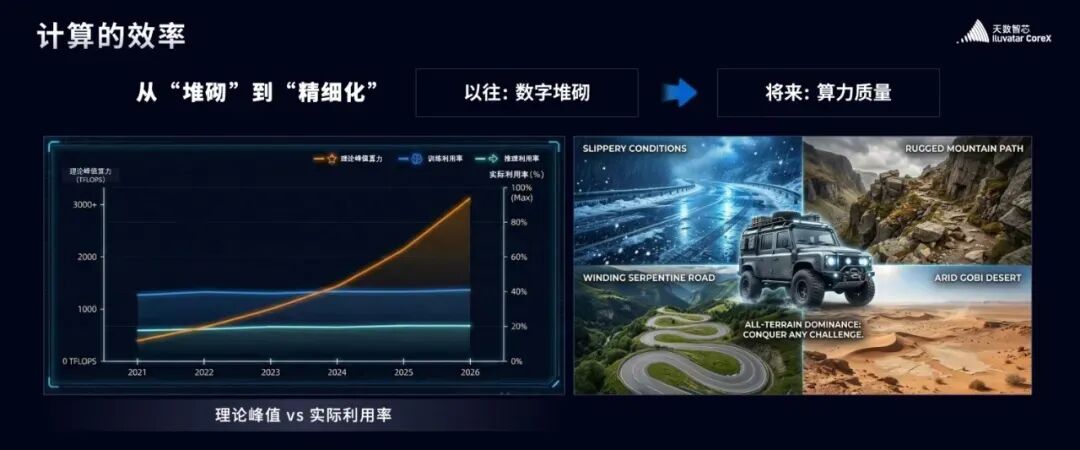
天数智芯坚持研发并量产通用 GPU,其设计哲学并非押注某一种特定算法,而是回归计算本质,旨在覆盖更广泛甚至未来全新的计算需求。在它们看来,硬件不应成为算法进化的枷锁,而应通过通用算力为探索未知提供一个坚实的底座。
支撑这一理念的关键在于“不设限”:
- 计算层面:追求覆盖从 Scalar、Vector、Tensor 到 Cube 的几乎所有数学运算图谱,支持从高精度科学计算到 AI 精度计算,无论是当前的 Transformer 模型中的 Attention 机制、前沿的科学计算,还是未来的量子计算模拟,都力求全面支持。
- 执行层面:追求更高的算力利用率。通过将大、中、小任务精准分配到不同的计算单元,配合高密度的多任务核心设计,算力可以被更精细地拆解与调度,从而减少浪费,提升效率。
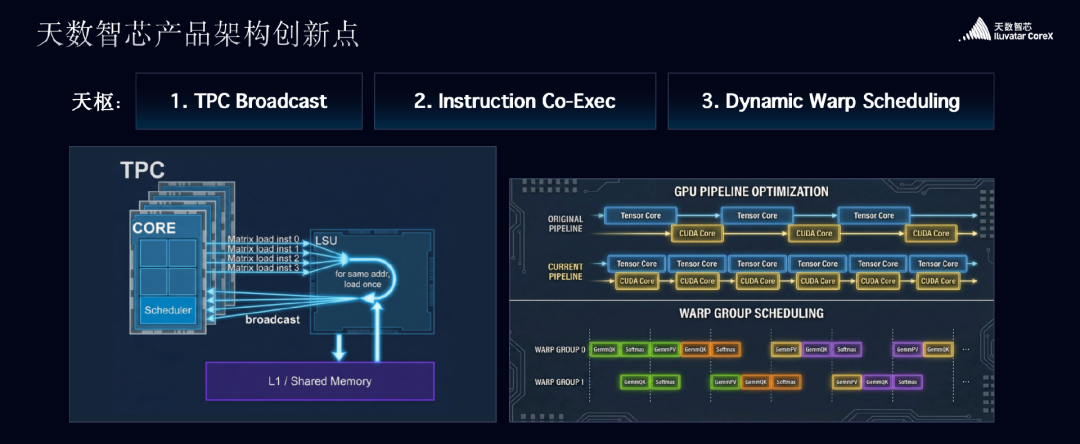
这种“不设限”的理念,直接催生了天数天枢架构的三大核心创新,这也是其能够超越英伟达 Hopper 架构的根本原因:
- TPC Broadcast(计算组广播机制)设计:其核心不是单纯增加带宽,而是提升单位带宽的使用效率。当芯片内部需要访问相同地址的数据时,load store 单元不会进行重复访问,而是在上游进行广播,从而有效减少不必要的内存访问次数,降低访存功耗,等效提升了访存带宽。
- Instruction Co-Exec(多指令并行处理系统)设计:在指令执行层面,实现了多种指令类型的并行执行。不仅支持 Tensor Core 与 Vector Core 的协同工作,还将 Exponent 计算、通信等操作纳入统一调度。这使得不同指令之间的并行处理能力大幅增强,无论是 MMA、Engram,还是更复杂的模型计算,都能在此框架下被高效并行处理。
- Dynamic Warp Scheduling(动态线程组调度系统)设计:随着 MoE 架构在大模型中普及,推理效率成为普遍挑战。天数智芯首创的动态调度机制,能让芯片中同时驻留的多个 warp(线程束)在资源使用上实现有序协作,避免计算资源闲置,也减少了对同一资源的无序争抢。
这三项设计的共同目标指向高性能与高效率。数据显示,这些创新让天数天枢的算力效率较行业平均水平提升 60%,并最终实现在 DeepSeek V3 场景中平均性能超越 Hopper 架构约 20%。更重要的是,这类微架构层面的精细优化,一直是英伟达等巨头保持领先的“内功”,天数智芯在这些单点上的突破,标志着国产 GPU 正在向顶级玩家的核心能力看齐。
提供高质量算力:高效率、可预期、可持续
在天数智芯看来,回归计算本质是实现高质量算力的前提。只有当 GPU 从底层开始对计算本身负责,高质量算力才成为可能。天数智芯将“高质量算力”具体拆解为三个维度:高效率、可预期与可持续。

- 高效率:为客户创造最优的总体拥有成本(TCO)。
- 可预期:通过精准的仿真模拟,让客户在部署前就能清晰预判性能,实现“所见即所得”。
- 可持续:算力不仅能适配当前主流的 CNN、RNN、Transformer,也能无缝支持未来可能出现的新算法。
围绕这三个方向,天数智芯在架构及系统层面进行了多维度布局。例如,基于“不设限”的理念,其 GPU 在 PD(Prefill/Decode)分离的架构下,不仅承担计算任务,还精准调度通信、KV 数据传输等关键任务,通过 IX 并行任务处理模块,让各类任务并行不悖。在实际业务中,该模块已帮助头部互联网客户实现了端到端 30% 的性能提升。
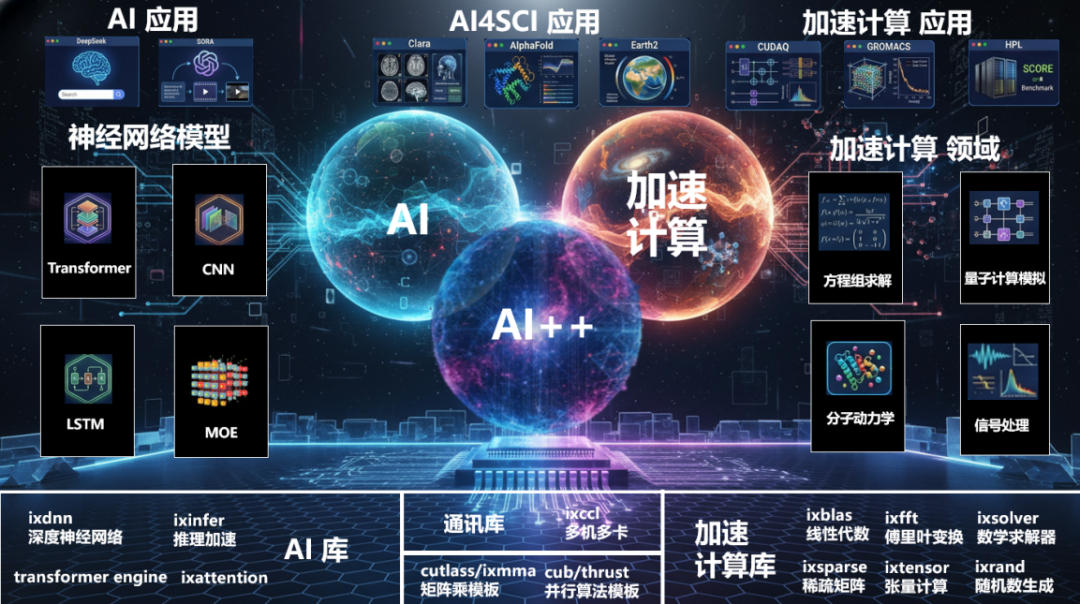
为了确保算力的可持续性,天数智芯构建了统一的 IXAI++ 算力系统。该系统通过不断更新的软件栈,以 AI 库、通讯库(ixccl)、加速计算库为基石,向上直接支撑 CNN、Transformer、LSTM 等各类神经网络模型以及科学计算各个领域,并最终服务于 AlphaFold、Clara、Earth2 等 AI4Sci 应用及 Gromacs、HPL 等高性能计算应用。
IXAI++ 的目标是成为连接算法创新与物理世界的桥梁。 而其中最引人注目的两项技术,当属 IX-Attention 模块和 IX-SIMU 全栈软件仿真系统。前者直击大模型长上下文推理的效率痛点,后者则旨在解决企业部署算力时最头疼的“不可控”难题。
在大模型推理中,长上下文处理效率低下是普遍问题,直接影响首字延迟和推理成本。天数智芯的 IX-Attention 模块从底层重构了 Attention 的执行路径。Attention 底层涉及 exponent、reduce、MMA、atomic 等多种指令,IX-Attention 的核心思路是将这些分散的组件有机整合、协同调度。
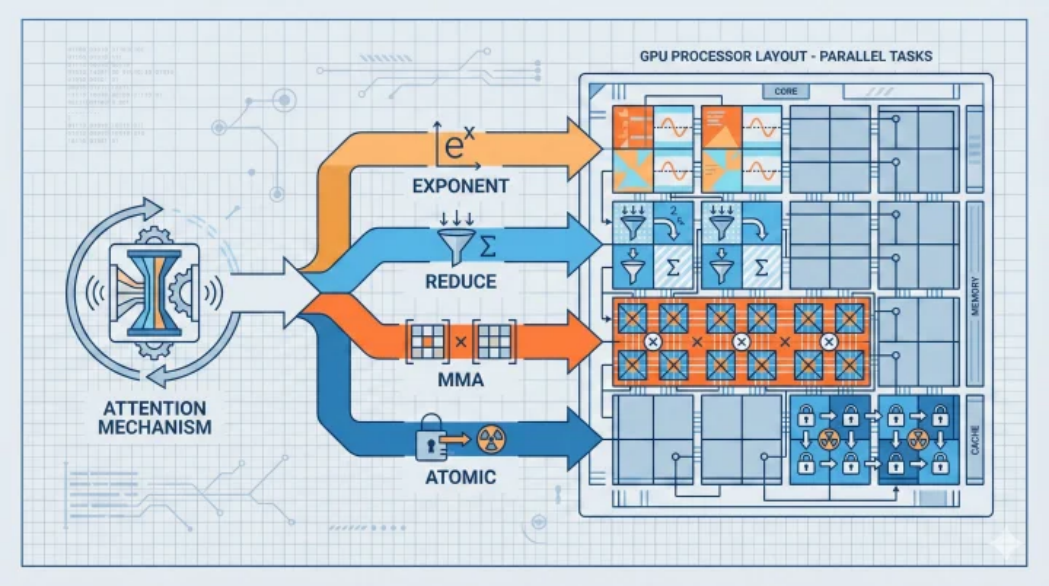
“技术难点在于调度,任何一个环节成为瓶颈都会拖慢整个系统。”天数智芯技术负责人表示。在实际应用中,该模块为长上下文推理带来了约 20% 的效率提升。
针对算力部署的不可控性,天数智芯搭建了 IX-SIMU 全栈软件仿真系统,目标就是实现 “零意外、可预期” 。它通过对芯片硬件行为与软件策略的联合仿真,能够精准预测任意模型在目标硬件上的性能表现。
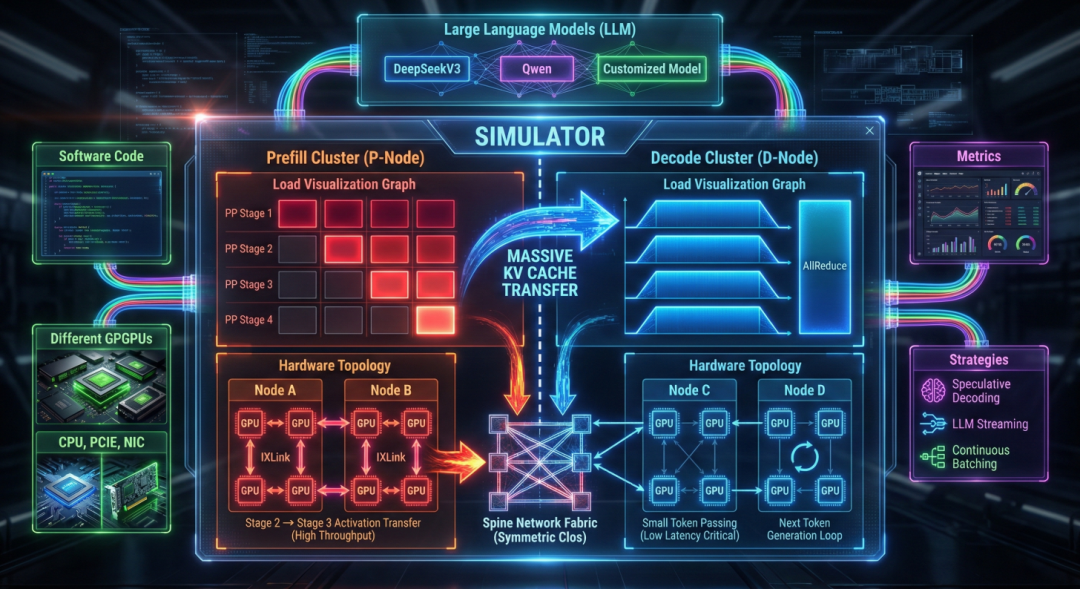
该系统的核心能力在于能够对底层指令执行进行精细建模。用户只需输入软件代码,IX-SIMU 便能自动整合 GPU、CPU、网卡等硬件组件,匹配网络拓扑,结合各类软件策略,最终精准输出从单卡到万卡集群的扩展性能,实现了从代码到性能的“精密仿真”。
决定上限的,最终还是应用和生态
坚实的架构是产品的下限,而决定其市场天花板与生命力的,始终是应用落地与生态建设。数据显示,天数智芯的产品已在互联网、大模型、金融、医疗等超过 20 个行业落地,服务客户超 300 家,并通过软硬件协同优化完成了上千次模型部署。
支撑这些广泛落地的,是 “产品 + 解决方案” 的双轨模式。这与英伟达聚焦解决方案落地的思路相近,在当下大模型深入产业的阶段显得尤为务实。在兼容性与稳定性方面,天数智芯也已取得进展,国内新的大模型发布当天便能跑通,目前已稳定运行 400 余种模型。
在本次发布会上,天数智芯还面向物理 AI 场景,发布了“彤央”系列边端算力产品,覆盖从 100T 到 300T 的实测稠密算力范围。在多项实测中,其性能表现优于英伟达同类型产品。目前,“彤央”系列已在具身智能、工业智能、商业智能和交通智能等边端核心领域实现落地应用。
整体来看,天数智芯虽然坚持底层技术自研,但在生态上持开放态度。通过兼容主流开发生态、持续开放底层能力,并联合硬件厂商、解决方案商等生态伙伴,天数智芯正致力于完善国产 AI 算力生态闭环,降低开发者的使用与迁移门槛。
从底层架构创新,到产品矩阵完善,再到应用生态构建,以天数智芯为代表的国产算力正在实现从芯片到解决方案的完整闭环。这种协同能力不仅让国产算力变得更可用、更可持续,也为整个行业探索新的计算范式与商业模式提供了更多想象空间。
想要了解更多关于 云计算、芯片架构与前沿技术实践的深度讨论?欢迎在技术问答社区 云栈社区 与众多开发者一同交流。
 发表于 2026-1-30 00:21:45
|
查看: 226|
回复: 0
发表于 2026-1-30 00:21:45
|
查看: 226|
回复: 0
