随着模型规模从千亿级稠密模型迈向万亿级稀疏模型,大模型的训练对算力需求呈指数级增长。以GPT系列为例,GPT-3训练3000亿tokens,约需3000张卡训练10天;而到了GPT-4,面对1.3万亿的数据量,同等算力下训练时间竟拉长至两年之久。为了应对这一巨大挑战,业界广泛采用了数据并行(DP)、张量并行(TP)、流水线并行(PP)等并行计算策略来加速分布式训练。
在这一背景下,分布式训练加速库应运而生,其核心目标是通过一系列底层优化技术,充分挖掘集群算力价值。近年来,从Google的GPIPE到Microsoft的ZeRO、Megatron-TP,再到Alibaba的Dapple,各类优化技术层出不穷,涵盖了内存优化、通信掩盖、自动并行以及混合专家模型(MoE)等多个前沿方向。

图:加速套件核心技术的发展历程与分类
业界主流加速库概览
目前,业界主要的训练加速库以英伟达的Megatron-LM和微软的DeepSpeed为代表。这些库的核心优势在于提供了丰富的并行算法、融合算子优化、内存与通信优化等。例如,Megatron支持多种经典的并行技术,架构设计合理,社区活跃,已成为许多公司自研框架的重要参考基础。

图:主流大模型加速套件及其核心加速能力对比
MindSpeed分布式训练加速库:全栈联合优化
昇腾MindSpeed分布式训练加速库采用分层开放的架构设计,旨在为大模型训练提供端到端的加速解决方案。其架构主要分为三层:
- MindSpeed LLM/MM套件层:针对大语言模型(如Qwen、Llama、DeepSeek系列)和多模态模型(如类Sora、LLaVA系列),提供从数据处理、训练加速到偏好对齐、评价体系的完整支持。
- MindSpeed Core 亲和加速模块:这是本次分享的核心,提供了并行、内存、通信、计算四个维度的深度优化算法。官方数据显示,整网计算性能可提升30%,通信效率提升15%,内存节省高达35%。
- 底层硬件与框架支持:基于PyTorch/MindSpore框架,深度优化适配昇腾系列硬件及CANN计算架构。
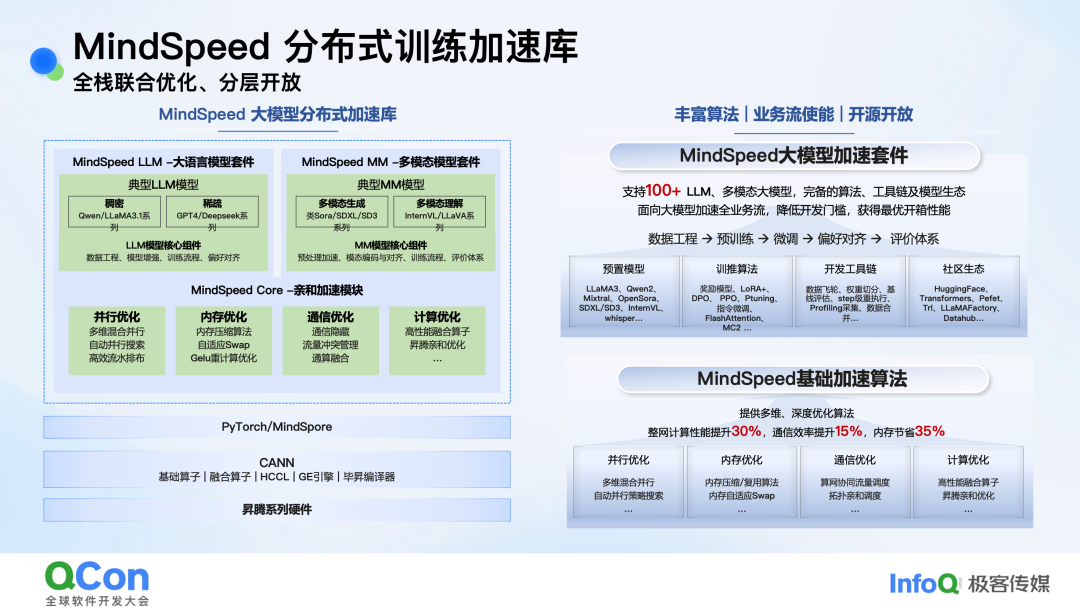
图:MindSpeed分层架构与核心加速模块
MindSpeed的一个关键设计理念是“非侵入式”集成。用户无需大规模修改自身训练框架,仅需通过简单的安装和代码导入即可使能加速特性,这极大地降低了使用门槛。
# 一键安装命令
pip install -e MindSpeed
# 一行代码使能
import mindspeed.megatron_adaptor
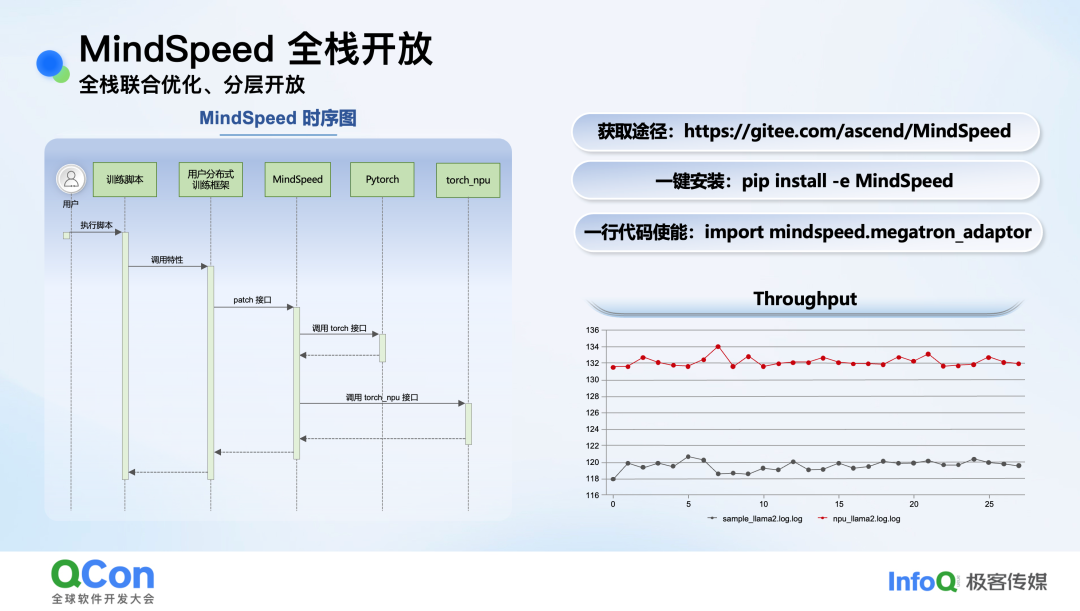
图:MindSpeed非侵入式集成的调用时序图
核心优化策略详解
1. 通信优化:计算与通信的“重叠艺术”
在TP(张量并行)和SP(序列并行)场景下,Allgather+Matmul和Matmul+Reduce-scatter是常见的通信计算模式。传统方式是串行执行,即先计算后通信,或先通信后计算,通信时间成为纯开销。
MindSpeed引入了计算通信掩盖技术,其核心思想是将大任务拆分为细粒度的小任务,实现计算流与通信流的并行执行。如下图所示,在通信任务0执行的同时,可以并行执行计算任务1,从而将原本的通信耗时“隐藏”起来。
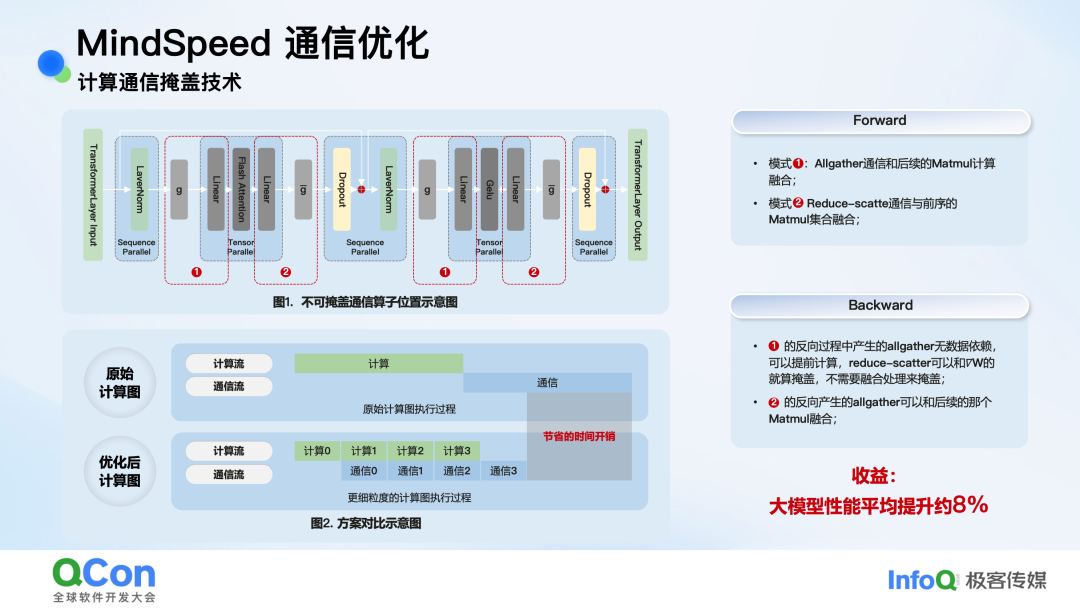
图:计算通信掩盖技术优化前后对比
实测表明,该技术能为大部分模型带来约 8% 的性能提升。此外,针对MoE模型中的流水线并行(如DualPipe),MindSpeed还通过分析计算依赖,利用共享专家计算与A2A通信无依赖的特性,在1F1B流水线的基础上额外掩盖了 50% 的异步通信。
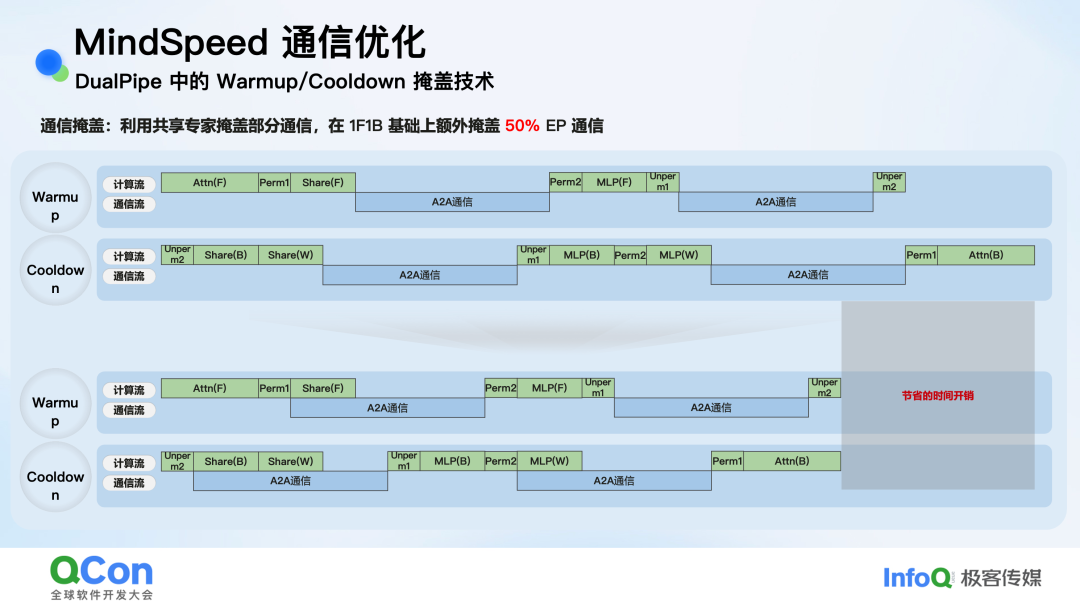
图:DualPipe中Warmup/Cooldown阶段的通信掩盖策略
2. 显存优化:从静态到动态的极致节省
大模型训练对显存的需求是另一个严峻挑战。MindSpeed从多个角度进行了创新优化。
- 参数副本压缩技术:混合精度训练(如BF16)时,模型权重在计算图(BF16格式)和优化器(FP32格式)中各存一份,导致显存翻倍。MindSpeed观察到BF16与FP32数据格式的前16位完全相同,便创新性地让BF16和FP32的Tensor指针指向同一块物理内存,通过动态增减一个“残差”值来切换精度视图。以70B模型、TP=8为例,此技术可为每张卡节约 17.5GB 显存。
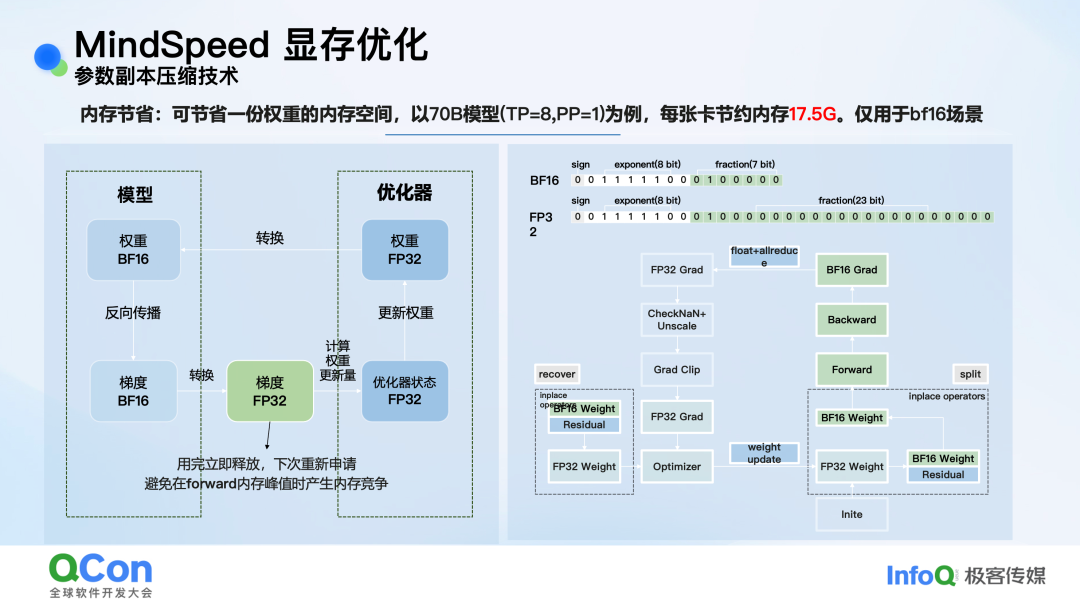
图:BF16/FP32权重共享同一内存地址的实现原理
- 激活函数重计算技术:传统重计算技术要么无法释放激活值,要么需要引入额外计算。MindSpeed采用了一种更巧妙的方法:在前向计算完成后,通过
storage().resize(0)释放激活值所占的物理显存,但保留其逻辑视图;在反向传播需要时,通过hook触发轻量级的前向重计算来恢复数据。由于激活函数计算极快,此方法对性能影响微乎其微,却能节省大量动态显存。
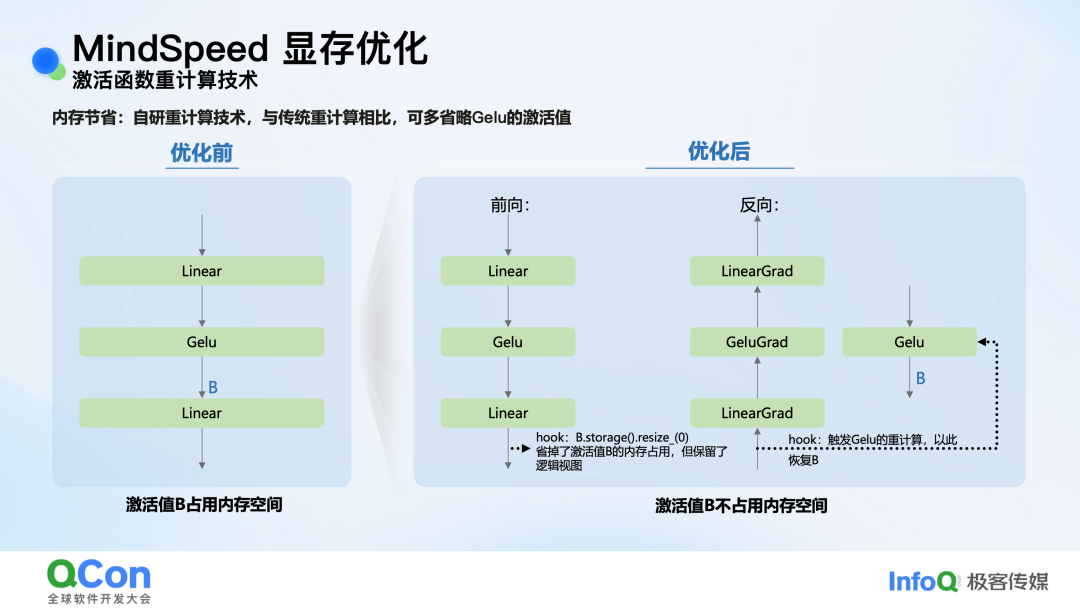
图:自研重计算技术省略Gelu激活值存储
- 优化器虚拟显存技术:此技术将部分显存访问“透明”地转发到更大的主机(Host)内存。与传统的Offload技术相比,其优势在于对算子完全透明,算子自身的数据搬运与计算流水可以自然地掩盖Host与Device之间的数据搬运开销。在DeepSeek V3等大梯度累积场景下测试,端到端性能损耗仅约 1%,却能节省数十GB显存。
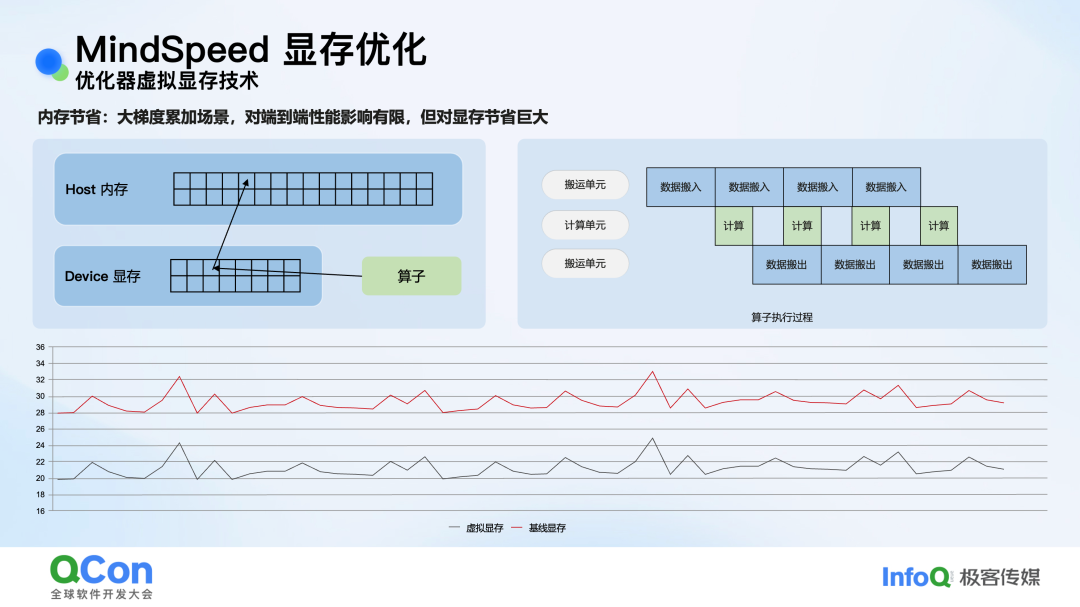
图:优化器虚拟显存技术的工作流程与效果
3. 计算优化:融合算子与等价改写
MindSpeed提供了一系列高性能融合算子,如npu_fusion_attention(类似FlashAttention)、npu_gmm_v2(用于MoE)、fused_rmsnorm等,通过将多个小算子融合,减少内核启动开销,提升计算效率。用户通常只需一个参数开关即可启用。
此外,还包含一些看似微小但收益显著的优化。例如,将条件掩码的赋值操作等价改写为纯计算操作:
# 原始写法
target_mask = (target < vocab_start_index) | (target >= vocab_end_index)
masked_target = target.clone() - vocab_start_index
masked_target[target_mask] = 0
# 优化后等价写法
target_mask = (target < vocab_start_index) | (target >= vocab_end_index)
masked_target = target.clone() - vocab_start_index
masked_target *= ~target_mask # 将赋值改为乘法计算
另一个亮点是矩阵向量并行。针对MoE模型中存在的Permute和Unpermute等向量计算操作,MindSpeed利用硬件中矩阵计算单元与向量计算单元可并行的特点,将向量操作剥离到单独的流中,与主要的矩阵计算并行执行,从而掩盖这部分开销。
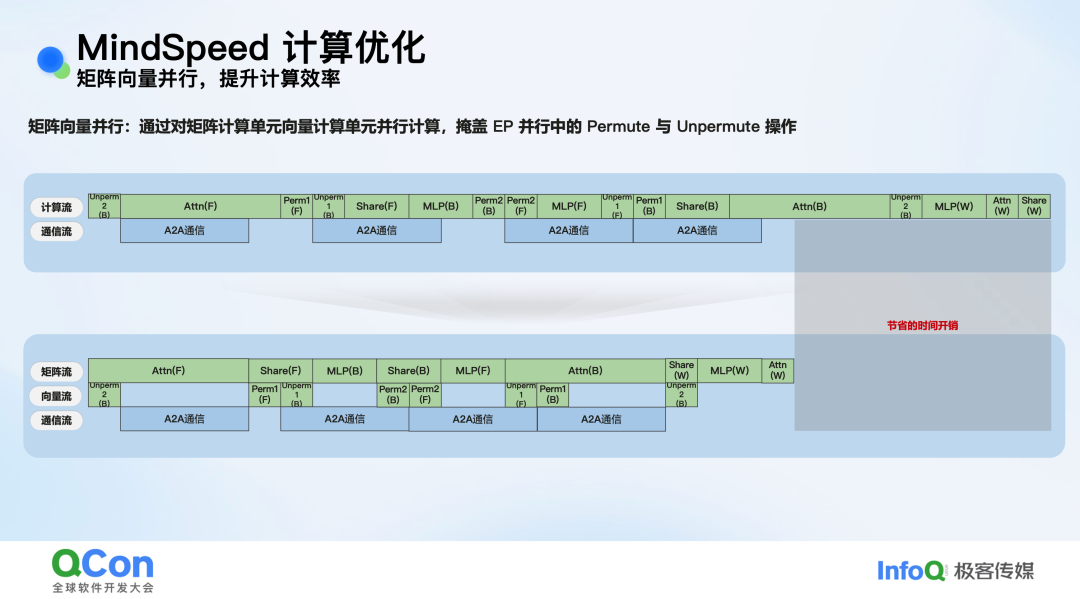
图:矩阵计算流与向量计算流并行示意图
4. 并行优化:调度策略与负载均衡
- 更优的VPP调度策略:虚拟流水线并行(VPP)中,Warmup阶段数量通常等于设备数,这导致前向与反向之间存在强依赖,无法掩盖通信。MindSpeed提出,只需额外增加一个Warmup,即可打破此依赖,实现类似DualPipe的1F1B流水掩盖效果。该方法相比开发完整的DualPipe更为简单,且所需设备数减半。
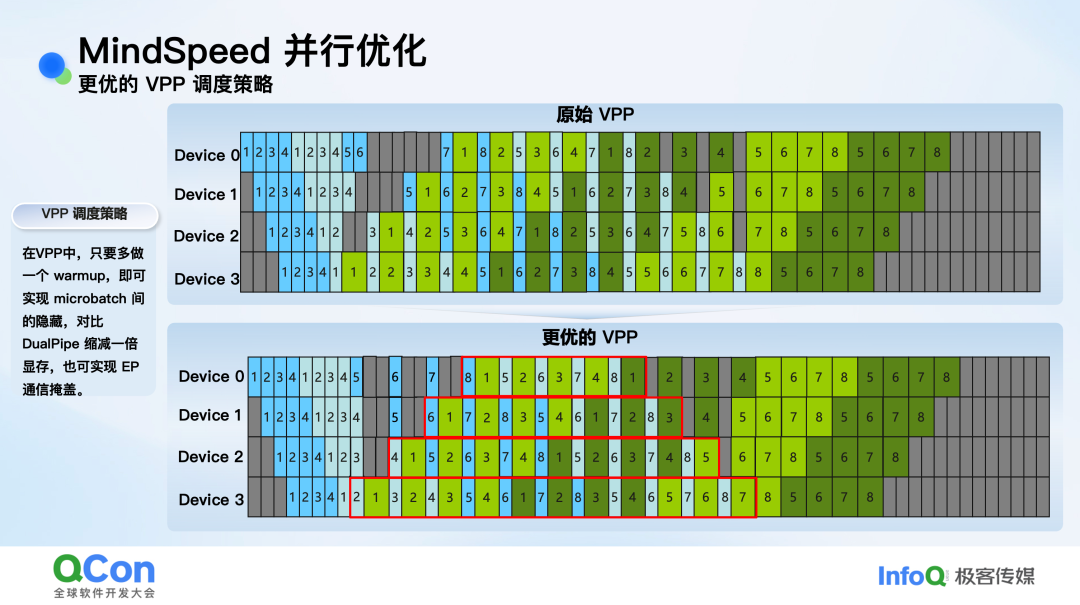
图:优化后的VPP调度策略(下)相比原始策略(上)更紧凑
- MoE负载均衡:数参互寻:MoE模型性能瓶颈常在于负载不均。传统“数据找计算”方式导致热门专家所在卡通信压力大。MindSpeed提出“数参互寻”思路,除了数据寻址,还支持“计算找数据”,即通信热门专家的参数到有数据的卡上。结合昇腾超节点内D2D高带宽优势,用冷门专家的计算时间去掩盖热门专家的参数传输,实测在训练前期可获得约 7% 的端到端收益。
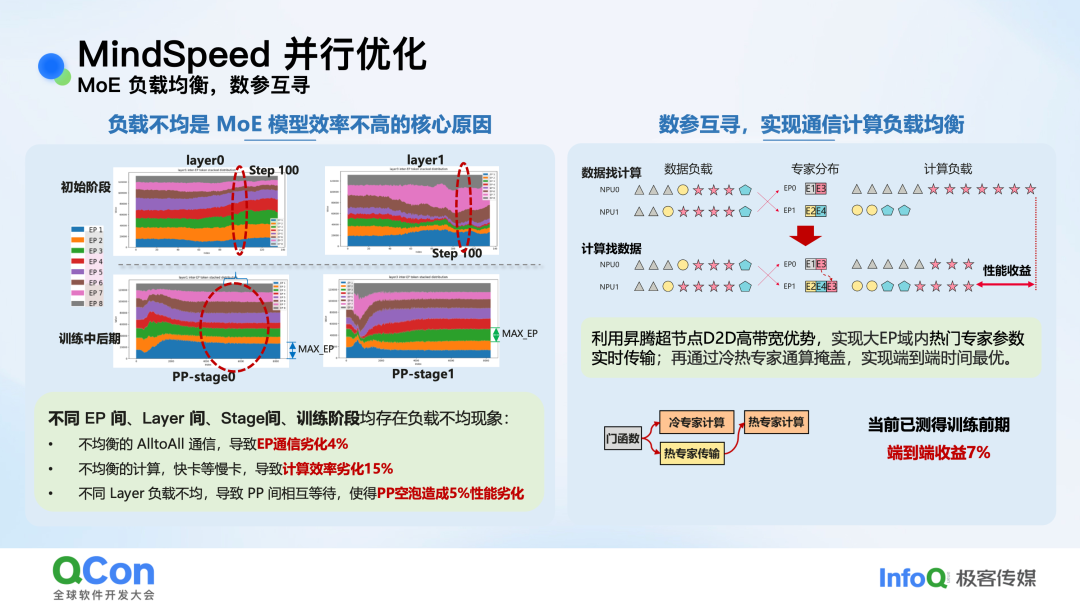
图:数参互寻实现MoE通信与计算负载均衡
- 更多并行技术创新:
- Swap Attention:将Attention后的激活值换出到Host内存,在后续MLP计算时异步换入,实现H2D传输与计算并行,节省显存且无重计算开销。
- Ulysses融合RingAttention:结合节点内All-to-All通信快和节点间P2P通信灵活性强的优势,融合两种长序列并行技术。
- MoE EDP模式:在小专家场景下,将TP并行域限制在Attention层,将节省出的并行维度用于扩大EP域,避免专家权重被切分,从而提升Matmul计算效率。
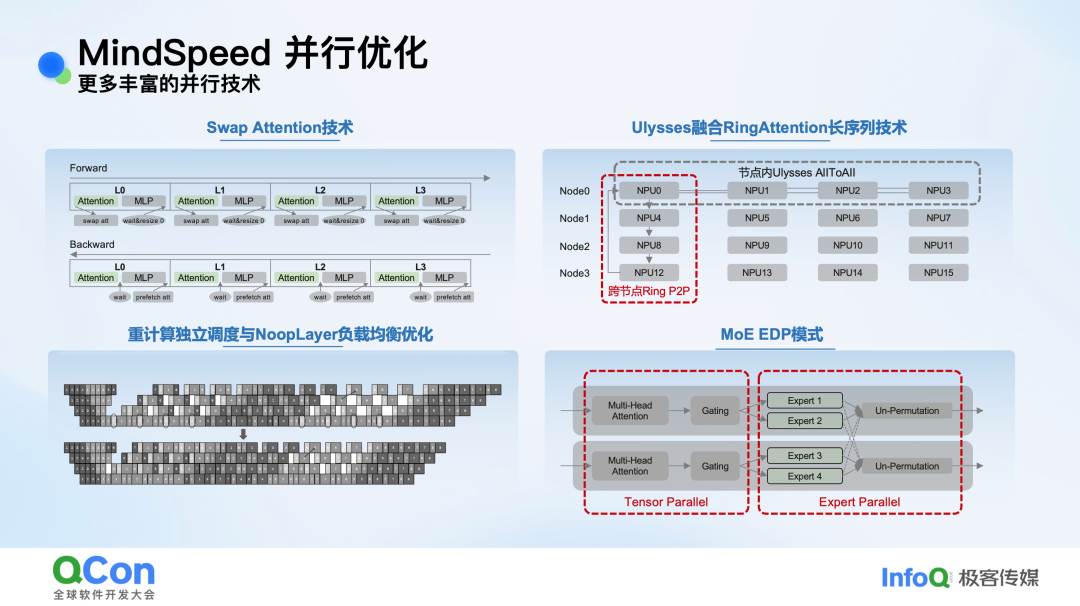
图:Swap Attention、融合长序列并行等多种高级并行技术
总结
昇腾MindSpeed分布式训练加速库通过在全栈各层的深度联合优化,针对大模型训练中的通信、显存、计算和并行调度等核心痛点,提出了一系列创新且实用的解决方案。从细粒度的计算通信掩盖,到巧妙的参数副本压缩,再到智能的负载均衡调度,这些优化措施共同作用,显著提升了训练效率,降低了使用门槛。对于希望在昇腾硬件平台上高效开展AIGC模型研发的团队而言,MindSpeed提供了一个强有力的工具选择。技术的持续演进离不开社区的交流与碰撞,欢迎关注云栈社区的后续技术动态,共同探索AI训练效率的边界。
 发表于 2026-1-30 00:27:19
|
查看: 264|
回复: 0
发表于 2026-1-30 00:27:19
|
查看: 264|
回复: 0
