扩散语言模型(Diffusion Large Language Model, DLLM)从理论上讲,应是一种极具表达力的范式。它将全局上下文与任意位置的生成能力相结合,而“任意位置”自然也包括了传统的自回归(Autoregressive, AR)从左到右顺序生成。从这个角度看,现有的各种SOTA AR模型都可以看作是DLLM的一个特例。那么,一个自然的推论是:作为AR模型的“超集”,DLLM理应展现出远超现有AR模型的性能。然而,现实却并非如此。即便是目前最好的离散DLLM,其在各项基准测试上的表现也往往逊于或仅仅持平于AR模型,并未展现出一种在性能上全面占优的新范式。
这种差距可能有多种解释,例如训练方法不够完善,或负对数变分下界(NELBO)作为优化目标约束力不足等,相关研究仍然任重道远。但无论如何,上述分析给了我们一种信念:离散DLLM的潜力巨大。
不过,当前主流的DLLM研究正走向半自回归(Semi-AR)的方向,即局部或块扩散(Block Diffusion)。这种方法的主要贡献是在宏观上为离散扩散引入了AR偏向,也就是常说的“块内扩散,块间AR”。整体上,一个块可以被看作是一个AR的元令牌(metatoken),可以进一步抽象为带有多令牌预测层的AR模型。这样一来,AR的各种优势,如KV缓存、动态长度扩展等,都可以套用在这一框架上。
在关于块扩散的论文中,作者展示了当块大小从全上下文长度逐步减小趋近于1时,模型从最初的纯全局扩散逐渐变为半自回归的块扩散,最终变为纯AR,并且这个过程里模型的困惑度(PPL)单调递减。这里弥补扩散与AR之间性能差距的方式,就是引入越来越多的AR偏向,使得宏观上执行AR操作的元令牌越来越小;当元令牌变为真实令牌时,半自回归也就变回了纯自回归。这似乎得出了一个“越是消融掉扩散特性,效果就越好”的实验结论。
扩散之所以为扩散,关键在于其每个令牌都具有全局视野,而非AR的单向历史视野。然而,随着块扩散的块尺寸变小,扩散所能利用的双向上下文也从全局变得非常局部。这从根本上限制了扩散模型的性能上限。我们正是从这里入手,试图在保留现有块扩散成果的基础上,重新引入全局扩散(Global Diffusion),为其解开更多可能性。
核心方法:扩散中的扩散

利用扩散模型独有的填充(infilling)能力,我们的方法相当直观:首先利用小尺寸块扩散与半自回归快速生成草稿,再使用全局扩散定点修改其中不合适的内容。这样既能利用AR偏向与KV缓存高效地产出不错的初稿,还能利用全局扩散的全局上下文视野来修正其中前后不一致或不够“整体”的内容。这种方法既避免了完全使用半自回归导致的全局性丧失,又避免了完全使用全局扩散的低效性以及缺乏AR偏向的现实问题。
也就是说,常规自回归的概率建模为:
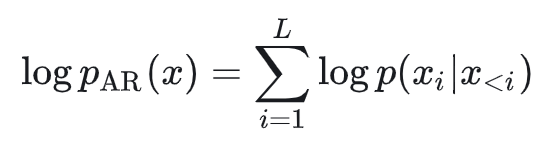
块扩散的概率建模为:
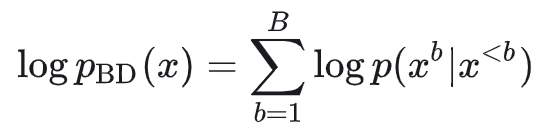
而我们提出的“扩散中的扩散”的概率建模为:
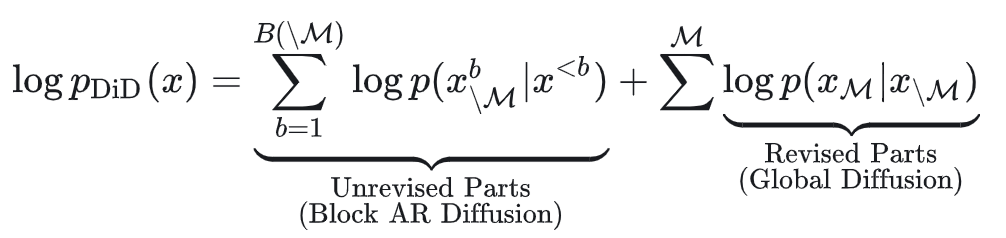
从结果来看,这种两阶段采样设计是有效的:
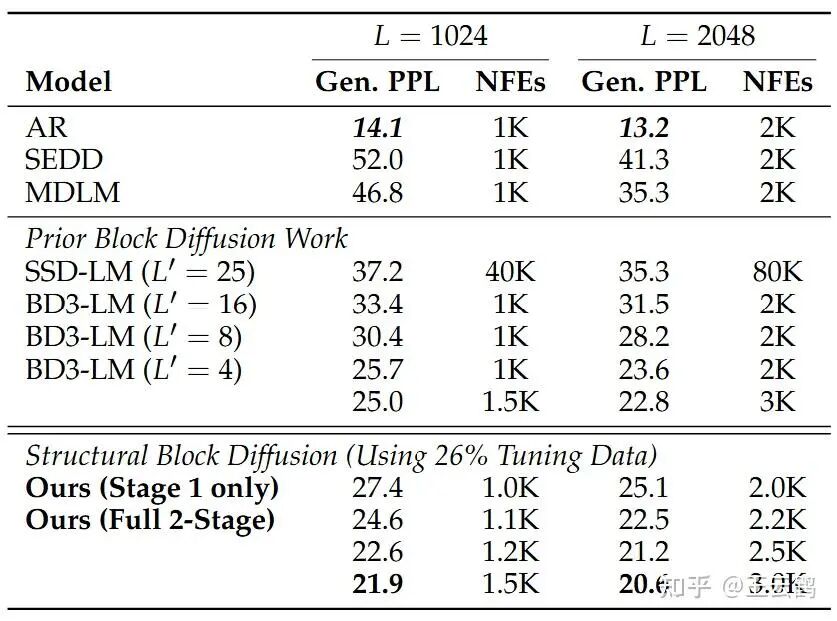
我们使用BD3-LM作为基线模型。我们的结果仅使用了基线模型四分之一(26%)的训练数据,因此在仅使用第一阶段时(相当于块大小为4的BD3-LM),其困惑度25.1比对应基线模型的25.7要高。然而,只要加上扩散中的扩散的第二阶段大块尺寸修订过程,效果立竿见影。通过逐步增加额外投入的计算量(NFEs,采样步数),困惑度可以稳步下降。在增加20%计算量时,困惑度即可低至22.6,最低可达21.9,大幅优于基线的25.7。即使为基线模型提供相对应的计算量,其困惑度也只能略微降低至25.0,仍然落后于我们的方法。
实现细节探讨
如何选择需要修改的内容? 这是扩散中的扩散方法的关键。我们希望精准定位第一阶段生成中最不理想的部分。这里有许多可能性,我们采用了一种无需额外成本的方法:将每一步去噪时被选中令牌的置信度(confidence)轨迹保留下来,后续再根据这份轨迹,将模型最不自信的位置变回掩码令牌,进行第二阶段的全局重新生成。这个选择机制可以随意更换,甚至变成可学习的模块,有待更多探索。
修订时使用的上下文长度: 我们还尝试在第二阶段使用其他块尺寸的块扩散,结果很有趣:只有使用足够大的上下文窗口才能产生正向作用;若是在第一阶段块尺寸为4的生成基础上,挑出一部分重新掩码后再做一次块尺寸为4或16的生成,反而会使文本质量变差。推测可能是这些“难例”已经无法通过当前的小上下文窗口来解决。同时,实验也确实表明,上下文窗口越大,修订效果越好。
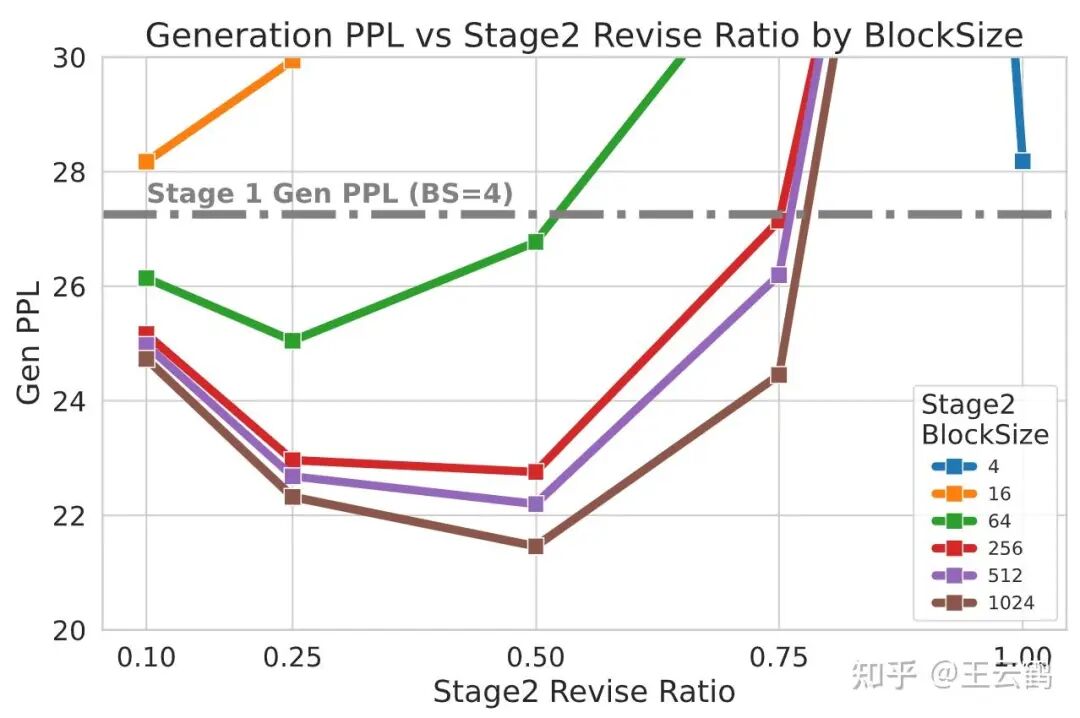
修订力度: 修订比例越大,修改力度就越大,当前该设定与重新掩码策略绑定。比例过小时等于没有作用;比例过大时,扩散中的扩散退化为大块尺寸的单独扩散生成,失去了全部的AR先验,效果变差,这与先前关于块扩散的结论一致。只有当修订比例处于中等水平时,才能达到最佳的平衡效果。
训练相关: 理想情况下,扩散中的扩散是一个无需训练的即插即用的采样优化方法。我们当前的训练目的是弥补当前模型在全局扩散性能上的短板。我们发现,经过块扩散训练出来的模型通常只在一种块尺寸上最有效,同时几乎完全丧失了全局扩散的能力。因此,我们采用了自己的“向量化混合尺度训练”来替换原有的单一尺度训练,从而使模型同时具备小尺寸块扩散与全局扩散两种能力:
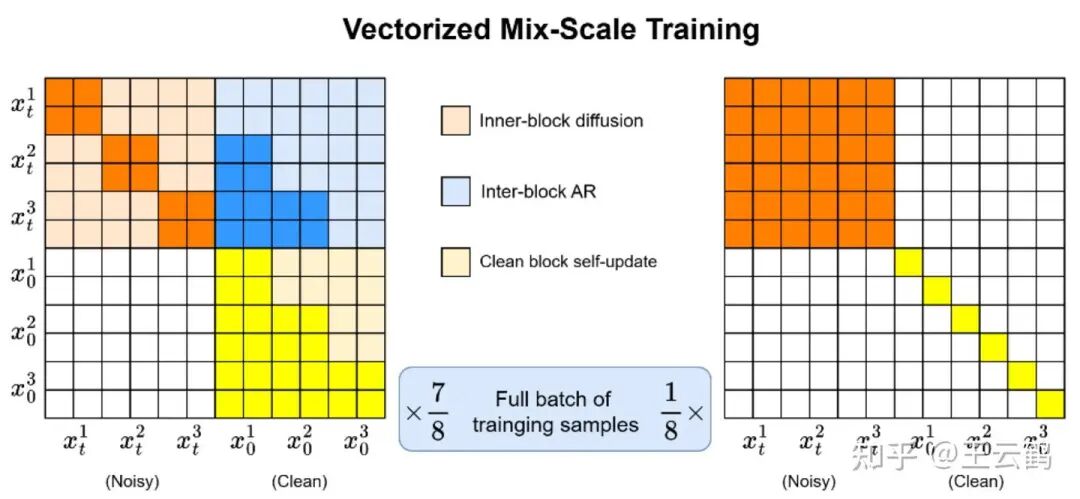
随着基础模型参数量的提升以及预训练更加鲁棒之后,我们认为模型大概率会自然地同时具备小尺寸块与全局两种扩散能力,届时很可能就不再需要这一段专门的训练。
未来展望
接下来,我们会将扩散中的扩散方法从当前的110M小模型扩展到1B甚至7B+的大模型,以确认其在各种参数量级上都有效。我们还会在重新掩码令牌的选择方案上进行更多探索。除此之外,在二次扩散时为修改位置赋予动态长度,也是一个非常有趣的研究方向。
这种“草稿-修订”的范式,为语言模型生成提供了一种新的、兼具效率与质量的思路。如果你对Transformer架构下的新型生成范式或优化技巧感兴趣,欢迎在云栈社区交流探讨。
 发表于 2026-2-6 02:22:27
|
查看: 222|
回复: 0
发表于 2026-2-6 02:22:27
|
查看: 222|
回复: 0
