阿里巴巴 Qwen 团队近期发布了论文《Qwen-Image-Layered: Towards Inherent Editability via Layer Decomposition》,并同步开源了 Qwen-Image-Layered 端到端扩散模型。该模型旨在解决当前 AI 图像编辑中的一个核心痛点——“连带破坏”问题。
简单来说,这个模型能像专业的图形设计师一样,将一张普通的 RGB 图片自动分解成多个带有透明度(RGBA)且相互独立的图层。这种分解不仅是简单的分割,还能自动填补每一层中被其他层遮蔽的区域。
开源项目和论文地址如下:
https://github.com/QwenLM/Qwen-Image-Layered
https://arxiv.org/pdf/2512.15603
vLLM-Omni
vLLM-Omni 现已支持 Qwen-Image-Layered。具体配置和部署细节请查看官方使用指南。
1. 为什么要费劲“分层”?
当前的主流 AI 绘图模型在生成方面表现卓越,但在修改已有图像时存在显著缺陷。当你只想更换背景或移动人物时,AI 常常会不经意地改变人物的面部特征、衣物纹理,甚至导致画面整体畸变。
- 传统图片像一张画死在画布上的画:任何改动都可能“牵一发而动全身”,难以做到局部精准调整。
- 分层图片像一叠透明胶片:你可以单独修改其中一张胶片上的内容,完全不会影响到下方的其他图层。
通过这种分层表示,缩放、位移、变色等操作就能在不伤及其他元素的前提下精确完成,从物理上确保了编辑的独立性与一致性。
2. 核心技术“三剑客”
为了实现这种复杂的分层能力,研究团队设计了三个关键技术组件:
- RGBA-VAE(通用的编解码器):传统 VAE 编码器通常仅处理 RGB 三通道图像。为此,研究者开发了新型的 RGBA-VAE,它能同时理解普通 RGB 图片和带透明度的 RGBA 图层,使模型的输入和输出在统一的表征空间内对齐,极大减少了信息转换过程中的误差。
- VLD-MMDiT(变长分层大脑):这是模型的核心架构。它可以处理不固定数量的图层(简单的图可能只需两层,复杂的图则可能需要十几层)。通过引入“Layer3D ROPE”技术,它为每个图层注入了专属的层级位置信息,让 AI 清晰地理解图层间的上下叠放关系。
- 多阶段训练策略:模型采用了渐进式的学习路径。它首先学会生成带透明度的单图层,然后进阶到合成多层复合图像,最终才掌握“给定图片,逆向分解图层”这一高级能力。
3. 如何获得训练数据?(PSD 提取流程)
高质量的、带有精确图层标注的数据在互联网上极为稀缺。研究团队为此构建了一套自动化流水线,直接从真实的 Photoshop 设计文档 (PSD) 中提取图层数据,为模型训练提供了坚实基础。
- 数据采集与提取:收集海量 PSD 文件,利用脚本工具拆解出原始的图层和蒙版。
- 精简与合并处理:过滤掉模糊或无关紧要的图层,并将那些空间上不重叠的零碎小图层进行合并,以提升数据质量并让模型学习更高效。
- AI 自动化打标:使用 Qwen2.5-VL 模型为这些图层组合生成详细的描述文本,让模型能够理解每一层所代表的语义内容。
4. 实验结果:它有多强?
- 分解精度高:在对比实验中,Qwen-Image-Layered 分解出的图层,在边缘清晰度(Alpha 通道质量)和语义独立性上,均显著优于 LayerD 等先前模型。
- 编辑稳定性强:在实际编辑任务中,它能轻松完成如“移动滑板少女的位置”或“修改海报文字”等指令,同时确保背景纹丝不动,人物样貌特征完全一致。
- 具备生成与分解双重能力:它不仅可以将现有图片拆分为图层,还能根据一句文本描述直接生成一套完整的、可分层的 PSD 风格素材。
总结来看,这项工作的意义在于将“AI 生成”与“专业级后期编辑”进行了深度融合。未来的 AI 图像工具或许将不再仅仅输出一张“固化”的图片,而是直接提供一个可自由、无损编辑的“工程文件”,这为人工智能在创意设计领域的应用打开了新的想象空间。
效果演示
图层分解的应用
给定一张输入图像,Qwen-Image-Layered 可以将其分解为多个 RGBA 图层。

分解完成后,所有的编辑操作仅作用于目标图层,使其在物理上与其他内容隔离,从而从根本上确保了编辑前后的内容一致性。
例如,我们可以为特定图层重新着色,而保持所有其他内容原封不动:
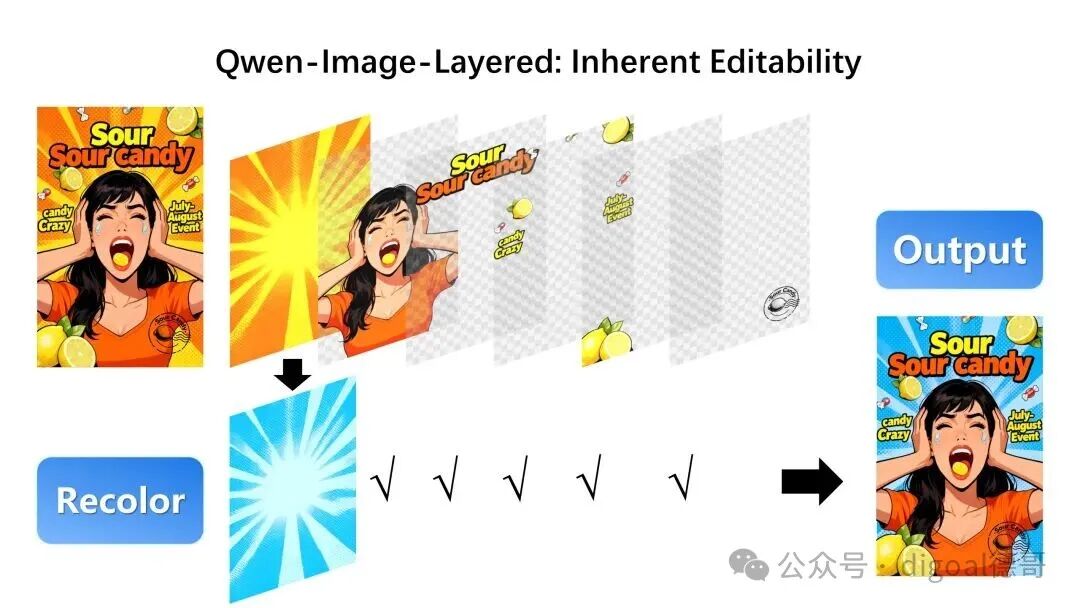
我们还可以将图层中的元素进行替换(目标图层使用了 Qwen-Image-Edit 进行编辑):
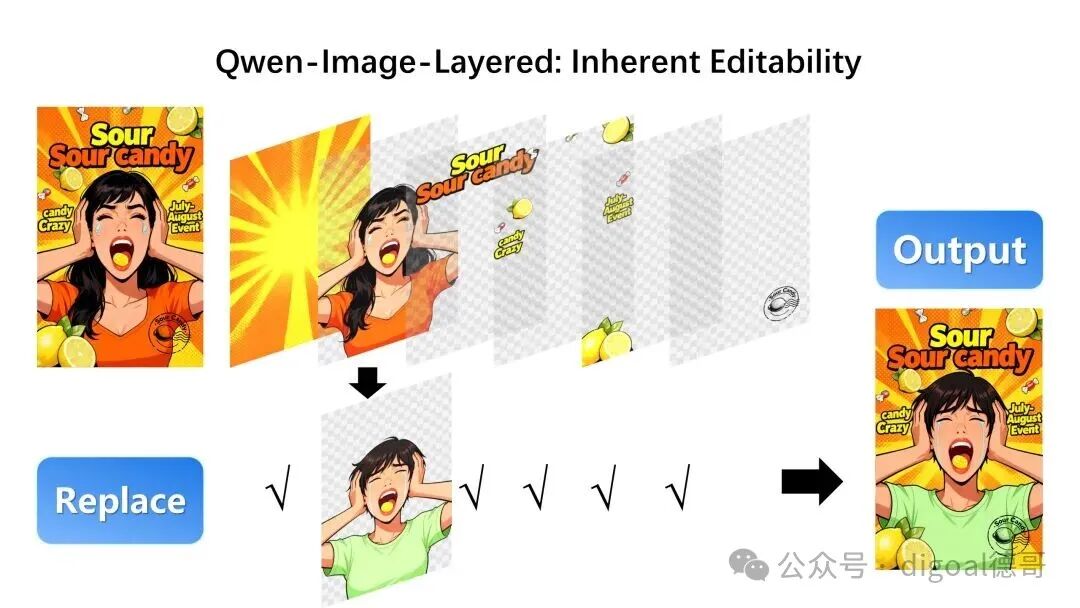
这里,我们对文本图层进行了修改(目标图层使用 Qwen-Image-Edit 进行编辑):
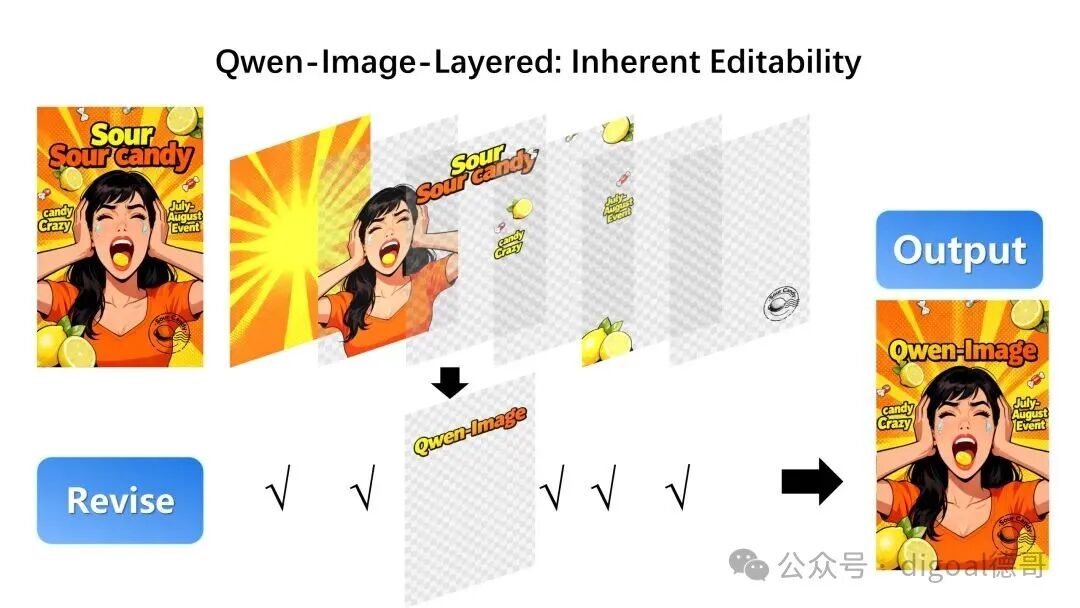
此外,图层化结构天然支持各种基础操作。例如,我们可以干脆利落地删除不需要的物体:
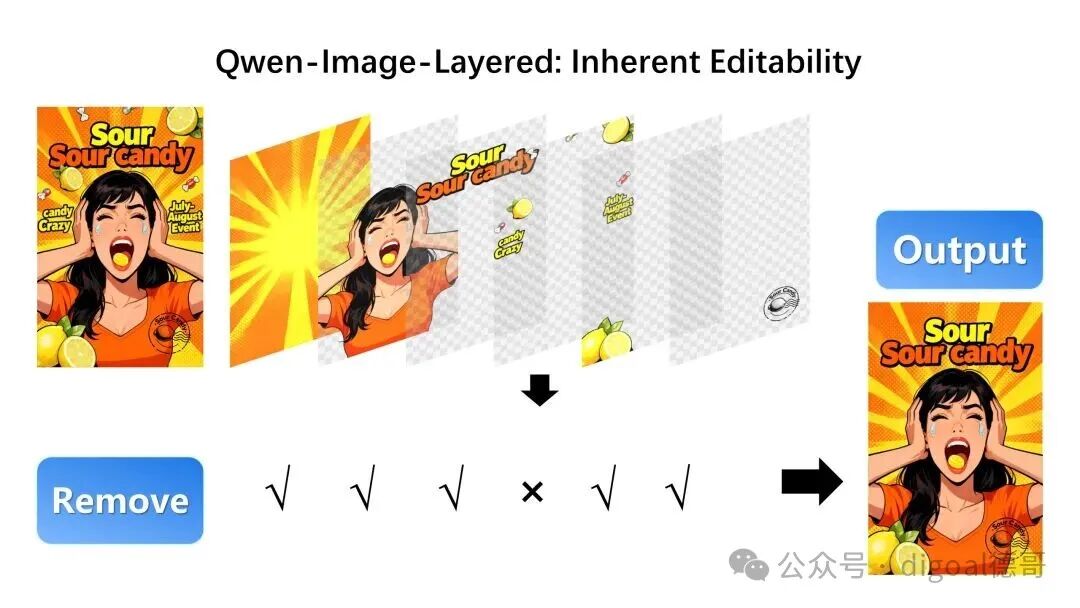
我们还可以在不产生畸变的前提下调整物体的大小:
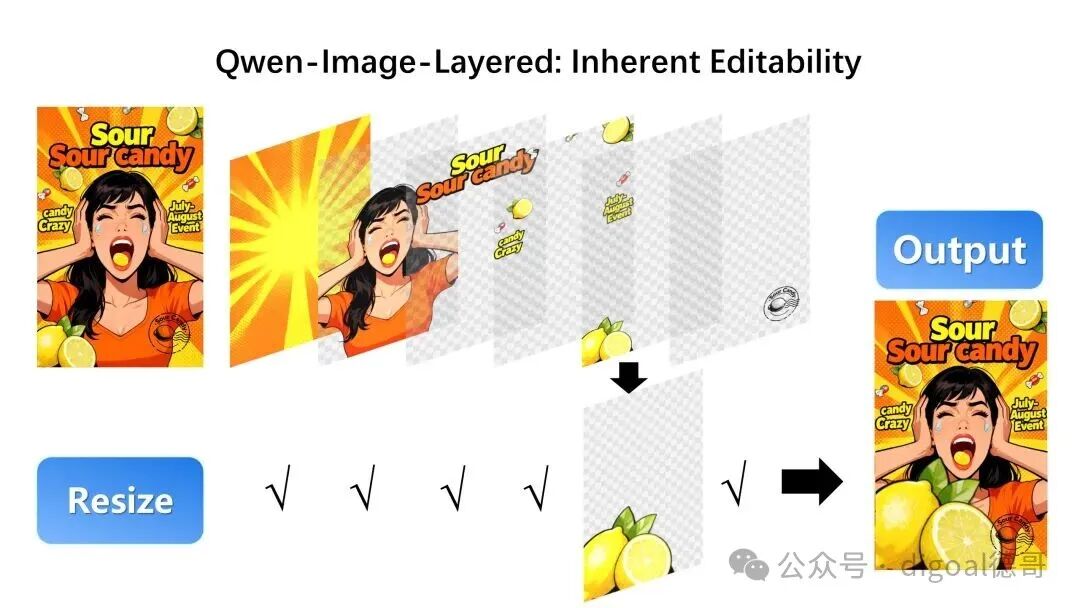
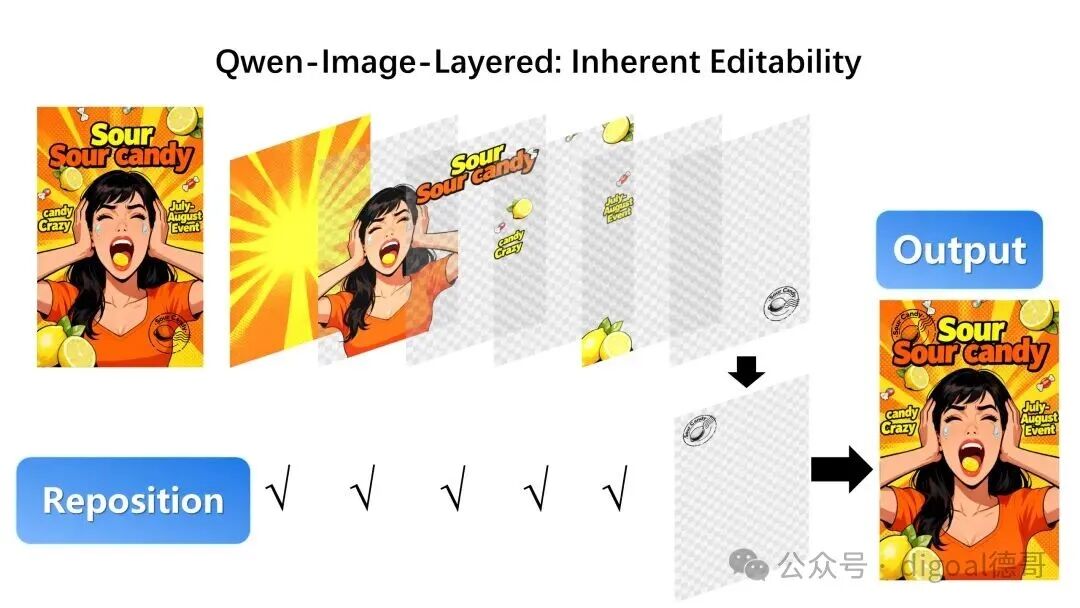
在图层分解之后,我们可以在画布内自由移动物体:
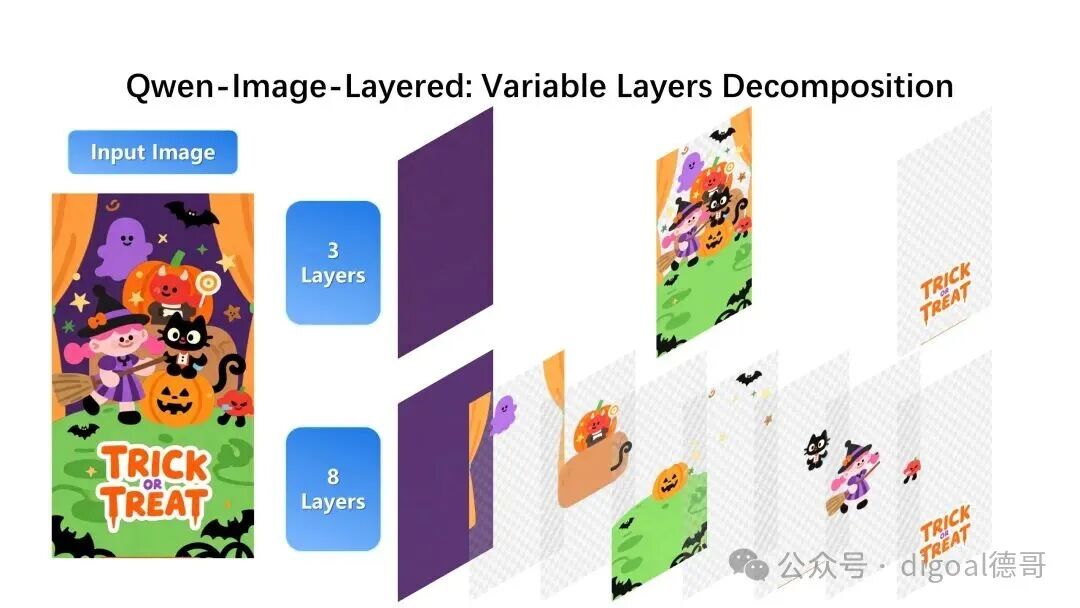
灵活且可迭代的分解
Qwen-Image-Layered 并不局限于固定的图层数量。该模型支持变长图层分解。例如,我们可以根据需要将一张图像分解为 3 层或 8 层:
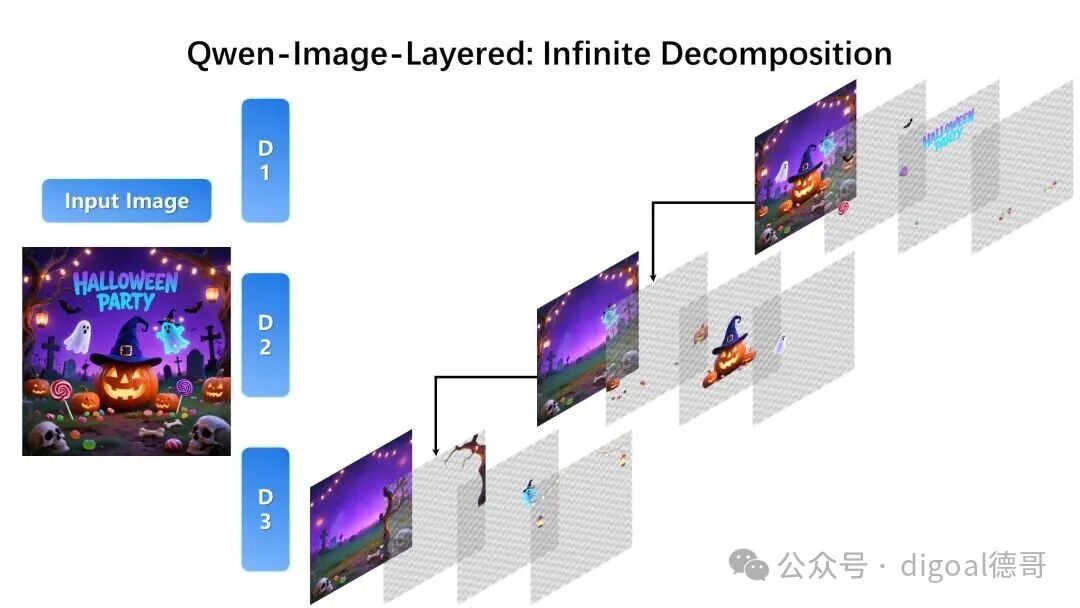
此外,分解操作还可以递归执行:任何图层本身都可以被进一步分解,从而实现无限深度的分解。
这项开源实战项目展示了AI在理解图像结构方面的重大进步,为设计师和创作者提供了前所未有的编辑灵活性。对这项技术感兴趣的开发者,可以在云栈社区的人工智能板块找到更多相关的深度讨论和技术资源。
 发表于 2026-1-15 00:26:07
|
查看: 280|
回复: 0
发表于 2026-1-15 00:26:07
|
查看: 280|
回复: 0
