在当下火热的多模态AI领域,想要找到一个既强大又轻便,还能轻松上手的开源模型并非易事。本文将聚焦于一个在开发者社区中备受瞩目的选择——MoonDream。我们将深入探讨这款开源视觉语言模型(VLM)的核心特性,并一步步带你完成从环境搭建到核心功能测试的完整流程,最后帮你理清不同版本的关键授权差异。
MoonDream 模型概览
MoonDream 是由开发者 Vikhyat Korrapati 发起并维护的一个开源、轻量级的视觉语言模型(VLM)。它的设计初衷非常明确:专为端侧设备和资源受限的环境而生。这意味着,它能够在极低的能耗和内存占用下(例如,不到 4GB 显存,甚至在 CPU 上也能流畅运行),实现与大模型(如 LLaVA 甚至早期 GPT-4V)相媲美,甚至在特定任务上实现超越的视觉理解能力。
截至2025年底,MoonDream 已经演进到第三代。其前两代模型 MoonDream 1/2 的参数规模大约在 1.6B 到 2B 之间,甚至还提供了仅 0.5B 参数的“迷你版”,以满足更极致的资源需求。而最新的 MoonDream 3 模型则采用了先进的 MoE(混合专家)架构,总参数量达到了 9B,但通过路由机制,单次推理激活的参数只有约 2B,在保持强大能力的同时进一步优化了效率。
什么是视觉语言模型(VLM)?
在深入 MoonDream 之前,我们先简单理解一下 VLM 到底是什么。简单来说,VLM 是一类能够同时“看懂”图像和“理解”文字,并实现两者间交互的 AI 模型。
我们可以从工作流程上来更直观地理解它:
- 输入:一张图片 + 一段针对这张图片的自然语言指令(例如:“描述这张图”、“图里有猫吗?”、“找出所有的汽车”)。
- 输出:一段文本信息。即使需要输出坐标等结构化信息,最终也是封装在文本中(如 JSON 格式)。
- 核心任务:模型根据你的文字指令,对输入的图像进行分析、理解、检索,并生成相应的文本回答。典型的应用包括图像描述、视觉问答、目标检测与定位、OCR文字识别等。
除了 MoonDream,业界还有其他优秀的 VLM 模型,例如阿里的 Qwen2-VL、开源的 LLaVA 系列、微软的 Phi-3.5/Phi-4 Vision 以及 Florence-2、谷歌的 PaliGemma、国产的 InternVL 2 等。
环境搭建与核心功能实战
接下来,我们将以应用较为成熟、License 最为宽松的 MoonDream 2 为例,展示如何搭建环境并进行功能测试。
第一步:下载模型
首先需要从 HuggingFace 获取模型。MoonDream 2 的模型仓库地址为:vikhyatk/moondream2。模型权重文件约 4GB,为了提升国内下载速度,可以使用 HuggingFace 镜像站。
以下 Python 脚本可将模型及相关文件下载到本地指定目录(例如 D:/models/moondream2):
import os
from huggingface_hub import snapshot_download, login
# Set the Hugging Face endpoint to use the mirror
os.environ['HF_ENDPOINT'] = 'https://hf-mirror.com'
# Define model options
MODEL_OPTIONS = {
'moondream2': 'vikhyatk/moondream2', # Non-gated, works without HF_TOKEN
'moondream3-preview': 'moondream/moondream3-preview' # Gated, requires access and HF_TOKEN
}
# Default to moondream2 which doesn't require authentication
selected_model = 'moondream2'
model_id = MODEL_OPTIONS[selected_model]
download_path = 'D:/models/' + selected_model
# Ensure the download directory exists
os.makedirs(download_path, exist_ok=True)
snapshot_download(
repo_id=model_id,
local_dir=download_path,
local_dir_use_symlinks=False,
cache_dir=download_path + '/cache',
token=os.environ.get('HF_TOKEN')
)
第二步:安装依赖与功能测试
MoonDream 2 提供了四种核心功能模式:caption(图像描述)、query(视觉问答)、detect(目标检测)和 point(指向定位),覆盖了从整体理解到局部定位的不同颗粒度任务。
首先安装必要的 Python 库:
pip install transformers accelerate pillow
然后,使用以下代码加载本地模型并进行多功能推理演示:
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
import os
# 配置本地路径
MODEL_PATH = "D:/models/moondream2"
IMAGE_PATH = "D:/test/Bear/122.jpg"
def run_inference():
print(f"--- 正在从本地加载模型: {MODEL_PATH} ---")
try:
# 核心设置:local_files_only=True 彻底禁止联网
model = AutoModelForCausalLM.from_pretrained(
MODEL_PATH,
trust_remote_code=True,
local_files_only=True,
device_map="auto", # 自动选择 GPU/CPU
dtype=torch.float16 if torch.cuda.is_available() else torch.float32
)
tokenizer = AutoTokenizer.from_pretrained(MODEL_PATH, local_files_only=True)
print("✅ 模型加载成功!")
# 加载并预处理图片
image = Image.open(IMAGE_PATH)
image_embeds = model.encode_image(image)
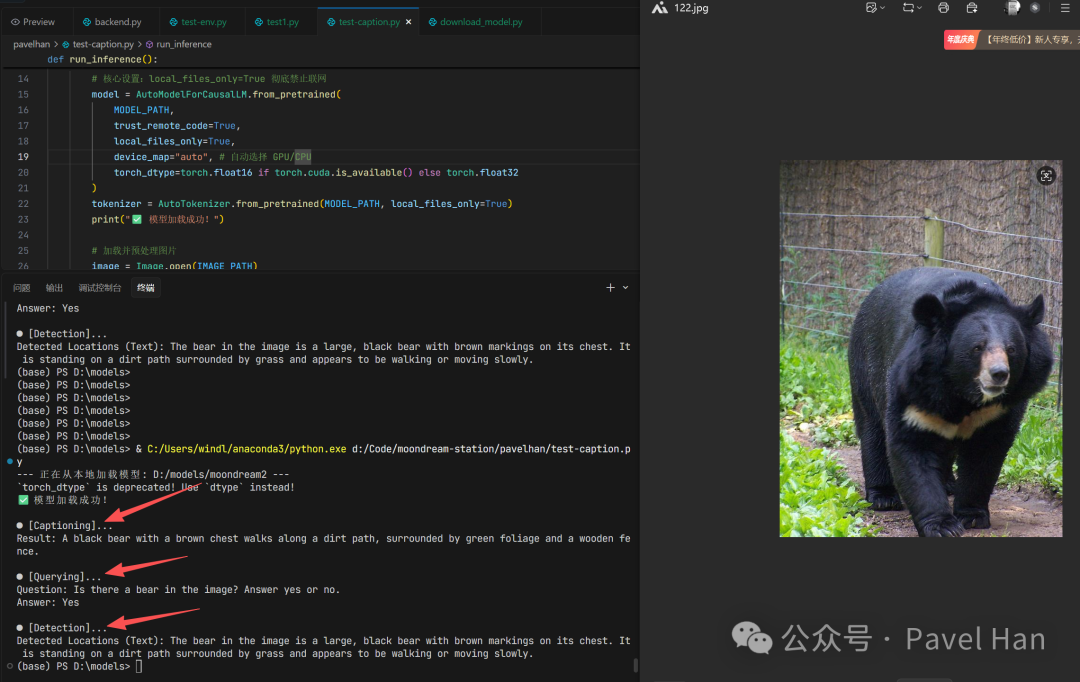
# 1. 执行 Caption (图像描述)
print("\n● [Captioning]...")
caption = model.answer_question(image_embeds, "Describe this image using less than 15 words.", tokenizer)
print(f"Result: {caption}")
# 2. 执行 Query (视觉问答)
print("\n● [Querying]...")
question = "Is there a bear in the image? Answer yes or no."
answer = model.answer_question(image_embeds, question, tokenizer)
print(f"Question: {question}\nAnswer: {answer}")
# 3. 执行 Detection (目标检测 - Moondream2 特色)
# 注意:Moondream2 的检测是通过特定 Prompt 触发的
print("\n● [Detection]...")
detect_prompt = "Find the bear."
locations = model.answer_question(image_embeds, detect_prompt, tokenizer)
print(f"Detected Locations (Text): {locations}")
except Exception as e:
print(f"推理失败: {e}")
print("\n提示:请确保 D:/models/moondream2 目录下有 model.safetensors 且文件大于 3GB。")
if __name__ == "__main__":
run_inference()
代码执行后,你将看到类似下图的输出结果,模型成功地对图片进行了描述、问答和初步的目标定位。
至关重要的 License 解析
对于任何希望将开源模型应用于实际项目的开发者而言,理解其授权许可(License)是必不可少的一步。MoonDream 不同版本的授权策略差异显著,选择不当可能带来法律风险。
| 版本 |
授权 (License) |
核心优势与限制 |
| MoonDream 1 |
Apache 2.0 |
极其宽松。允许商业使用、修改和分发。 |
| MoonDream 2 |
Apache 2.0 |
目前商业应用最主流的选择。完全开源,对商业盈利没有强制限制。 |
| MoonDream 3 (最新) |
BSL 1.1 (Business Source License) |
有限制的准商业授权。由其背后的 M87 Labs 公司发布,主要防范“直接竞争”。 |

简单来说:
- MoonDream 1 & 2 (Apache 2.0):你可以自由地将它们用于任何商业产品、提供服务或进行二次开发,几乎没有限制。
- MoonDream 3 (BSL 1.1):使用时需要仔细核对条款。
- 允许:在公司内部部署使用、作为公司产品的一个功能嵌入、用于非盈利和研究目的。
- 可能需额外授权:如果你搭建服务器并通过 API/SDK 等方式对外提供与 MoonDream 官方付费服务构成直接竞争的收费服务,则需要获得商业许可。
因此,对于大多数商业应用和希望避免合规风险的个人开发者,MoonDream 2 是目前更稳妥、更自由的选择。在尝试最新技术的同时,厘清这些技术文档中的法律条款,是负责任开发的体现。
希望这篇从实践出发的解析,能帮助你快速上手这个强大的轻量级 VLM 模型,并将其潜力应用到你的项目之中。如果你在部署过程中遇到其他问题,欢迎在技术社区进行交流探讨。
 发表于 2026-2-10 05:44:57
|
查看: 447|
回复: 0
发表于 2026-2-10 05:44:57
|
查看: 447|
回复: 0
