机器人领域的专家演示数据、互联网上的海量文本与图像,让生成模型在机器人操控、语言生成、视觉理解等任务上展现出强大潜力。然而,当面对一个具体任务时,这些通用模型往往表现欠佳。例如,大型语言模型需要微调才能遵守安全约束或贴合人类偏好,而机器人的策略模型也需要在演示数据的基础上进一步训练,以弥补其不足。
当前,扩散模型和流模型已成为生成任务的主流方法,而强化学习则是追求任务层面最优性能的经典途径。将两者结合,便催生了DDPO、DPPO、FPO、Flow-GRPO等一系列工作。这类方法通常运行在数十亿参数、高维的图像或文本环境中,计算开销巨大。因此,我们不妨换个思路:在一个极简的二维环境中研究其训练细节,专注于优化单条去噪轨迹。
这个环境训练耗时不到一分钟,对计算资源的要求几乎可以忽略。虽然其状态和动作空间过于简单,导致常规性能指标意义不大,但真正有趣的是在不同微调策略下涌现出的视觉行为模式。本文虽然聚焦于DPPO和扩散策略(将去噪数据视为“动作”),但其揭示的微调动态完全可以推广到其他基于强化学习的扩散模型应用场景。
环境设置
我们定义一个“环形”高奖励区域,目标是让模型学会将样本去噪到这个环上的任意位置。观察的重点在于:模型是会收敛到环上的某个单一模式,还是能将样本均匀地分布在环上?它对环的宽度敏感度如何?下图展示了一条典型的去噪轨迹演变过程:
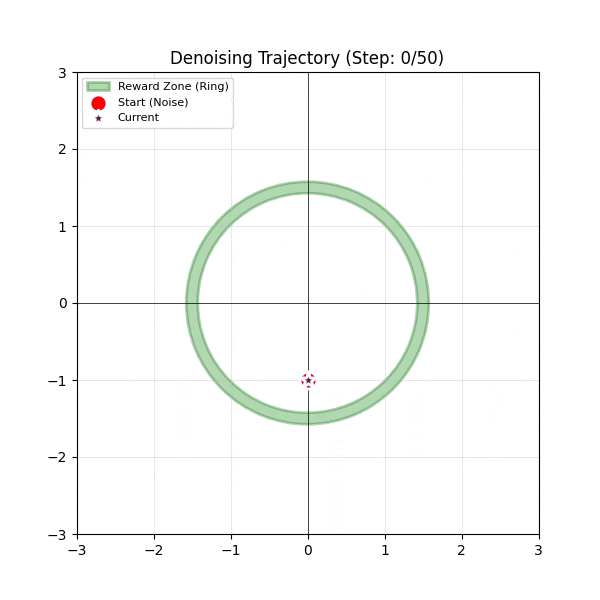
期望的行为是:从随机初始化的噪声状态出发,逐步走向高奖励区域,最后一步得到的就是去噪完成的样本。
在深入之前,我们需要先解释清楚DPPO算法及其相关术语,然后尝试用该算法来优化扩散模型,使其生成高奖励样本。
DPPO算法概述
DPPO是PPO(近端策略优化)的一个变体,属于同策略(on-policy)方法。其核心思路是更新扩散模型的参数,使得生成的样本能够获得更高的奖励。它将整个扩散过程建模为一个马尔可夫决策过程:每个扩散时间步对应一个状态,而“去噪”操作就是动作,奖励则来源于最终的去噪状态。奖励通过蒙特卡洛估计的方式,反向传播到有噪声的早期时间步——即通过对完整回合的折扣回报求平均,来估计期望累积奖励。DPPO原论文中的这张图清晰地展示了这一过程:
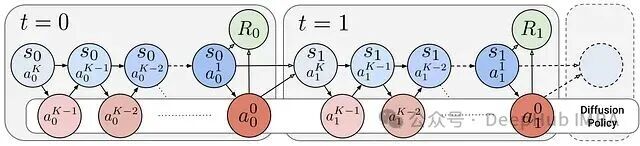
算法的外循环首先进行回合采样,存储每个扩散时间步的动作对数似然,以及状态、动作、奖励等标准信息。内循环则运行K个轮次(epoch),使用PPO风格的目标函数来更新扩散模型的参数。PPO的细节网上已有大量资料,这里我们只展开与本文相关的部分。内循环结束后,使用更新后的新策略再采样一批回合。损失函数通常包含信任域策略更新、价值函数损失以及鼓励探索的熵项。为简化说明,下文将主要关注上图中“t=0”这一步,它对应着单条扩散轨迹。

算法 1:结合DDIM与GAE的DPPPO伪代码。其中第5行的“动作”即指去噪得到一个样本。
步骤 1:回合采样
state = env.reset()
# (旁注:动作方差被设置为可学习参数)
action_var = nn.Parameter(torch.full((2,), action_std_init * action_std_init))
current_pos = state[:2]
# 在rollout循环中...
with torch.no_grad():
# 条件噪声预测
pred_noise = policy.actor(current_pos, t)
# “T-1”步的预测即是去噪轨迹中的下一个位置
action_mean = policy.ddim_step(pred_noise, t, current_pos)
dist = Normal(action_mean, action_var.sqrt())
# 从带有可学习噪声的分布中采样
action = dist.sample()
action_log_prob = dist.log_prob(action).sum(dim=-1)
next_state, reward, done = env.step(action)
# 存储到缓冲区
buffer.states.append(state, action, action_log_prob, reward, done)
这段代码对应DPPO论文中的公式4.3。我们当前微调的是整个DDIM轨迹,后续会与仅微调最后几步的效果进行比较:
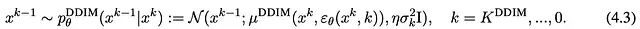
在代码中,去噪过程的每一步都被视为一个动作,这是DPPO内部MDP建模的关键。动作方差被设为可学习参数,因为DDIM本身是确定性的,需要添加探索噪声(即公式中的σ)。
DDIM步骤方法的实现如下,它通过求解概率流常微分方程来得到去噪过程的前一步(参考伪代码中的公式)。这个操作必须是可微的,梯度才能沿着 损失 → 对数概率 → 分布 → 动作 → ddim_step → 预测噪声 → 策略网络权重 的路径反向传播。噪声调度参数是预先设定好的。
# DPPO需要对扩散步骤进行微分,因此此函数必须可微
def ddim_step(self, model_output, timestep, sample):
# 处理t-1(如果t=0,则prev=0,但alpha_prev=1.0)
prev_timestep = torch.clamp(timestep - 1, min=0)
alpha_prod_t_prev = alphas_cumprod[prev_timestep].view(-1, 1)
alpha_prod_t = alphas_cumprod[timestep].view(-1, 1)
beta_prod_t = 1 - alpha_prod_t
# DDIM公式
pred_original_sample = (sample - torch.sqrt(beta_prod_t) * model_output) / torch.sqrt(alpha_prod_t)
pred_sample_direction = torch.sqrt(1 - alpha_prod_t_prev) * model_output
prev_sample = torch.sqrt(alpha_prod_t_prev) * pred_original_sample + pred_sample_direction
return prev_sample
步骤 2:奖励缩放与GAE
这部分基本上是标准PPO的操作。我们跟踪运行统计量来归一化奖励,因为过大的奖励方差会导致价值函数训练不稳定。然后,对缓冲区中的所有状态执行一遍价值函数的前向传播(不计算梯度),并使用广义优势估计(GAE)从回报中计算优势值,以在偏差和方差之间取得平衡。GAE的作用是为去噪过程中的每个“动作”分配功劳,而价值函数则为带有噪声的状态建模这个功劳(注意,其输入也包含了扩散时间步)。
# 从缓冲区获取状态
old_states = torch.cat(buffer.states, dim=0)
# 使用运行统计量缩放奖励
rewards_np = np.array(buffer.rewards)
rewards_norm = (rewards_np - reward_scaler.mean) / (np.sqrt(reward_scaler.var) + 1e-8)
# 计算GAE所需的价值估计
with torch.no_grad():
x_t = old_states[:, :2]
t_long = old_states[:, 2].long()
# 从评论家网络获取价值
values = policy.critic(x_t, t_long)
advantages = []
last_gae_lam = 0
# 反向遍历缓冲区
# buffer.is_terminals 告诉我们episode是否在该步结束
for step in reversed(range(len(buffer.rewards))):
if step == len(buffer.rewards) - 1:
next_non_terminal = 1.0 - float(buffer.is_terminals[step])
next_val = next_value
else:
next_non_terminal = 1.0 - float(buffer.is_terminals[step])
next_val = values[step + 1].item()
# Delta = r + gamma * V(s') * mask - V(s)
delta = rewards_norm[step] + gamma * next_val * next_non_terminal - values[step]
# Advantage = Delta + gamma * lambda * Advantage_next * mask
last_gae_lam = delta + gamma * gae_lambda * next_non_terminal * last_gae_lam
advantages.insert(0, last_gae_lam)
# 计算回报:Return = Advantage + Value
# 这是价值函数的学习目标
returns = advantages + values
# 归一化优势值(标准的PPO技巧)
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
步骤 3:PPO更新
此步骤旨在优化策略:降低低优势动作的概率,提高高优势动作的概率。这个过程会运行多个轮次,以充分利用缓冲区中的数据,而不是更新一次就丢弃。由于每次迭代后策略都在变化,我们需要在新策略下重新计算旧动作的对数概率,并使用新旧策略的概率比来控制策略改进的幅度。后文会实验不同的裁剪参数(eps_clip)。
# 下一状态(来自上一个cell)
state = next_state
old_actions = torch.cat(buffer.actions, dim=0)
old_logprobs = torch.cat(buffer.logprobs, dim=0)
# K_epochs定义了利用数据的次数
for _ in range(K_epochs):
x_t = old_states[:, :2]
t_long = old_states[:, 2].long()
pred_noise = policy.actor(x_t, t_long)
mean_action = policy.ddim_step(pred_noise, t_long, x_t)
# 可学习的动作方差(在rollout阶段定义)
dist = Normal(mean_action, action_var.sqrt())
# 在新策略下重新计算对数概率,用于计算策略比率
logprobs = dist.log_prob(old_actions).sum(dim=-1)
ratios = torch.exp(logprobs - old_logprobs)
surr1 = ratios * advantages
surr2 = torch.clamp(ratios, 1-eps_clip, 1+eps_clip) * advantages
policy_loss = -torch.min(surr1, surr2)
# 这次计算V(s)时保留梯度,用于训练价值函数
state_values = policy.critic(x_t, t_long)
value_loss = 0.5 * nn.MSELoss()(state_values, returns)
# 这里也可以加入熵项和KL项,但暂时省略
loss = policy_loss + value_loss
DPPO与DDPO的区别
网上很少有文章对比这两个名称容易混淆的方法:去噪扩散策略优化(DDPO)和扩散策略优化(DPPO)。除了动机不同(DDPO针对文本生成图像,DPPO针对扩散策略优化)之外,一个关键区别在于优势估计。DDPO采用按提示词(prompt)的奖励归一化,论文描述其“类似于价值函数基线”;而DPPO则使用了更成熟的GAE,并配合显式学习的价值函数。从概念上确实容易混淆,但本文的实现因为使用了GAE,在技术上更接近DPPO。
从头训练DPPO(为何失败?)
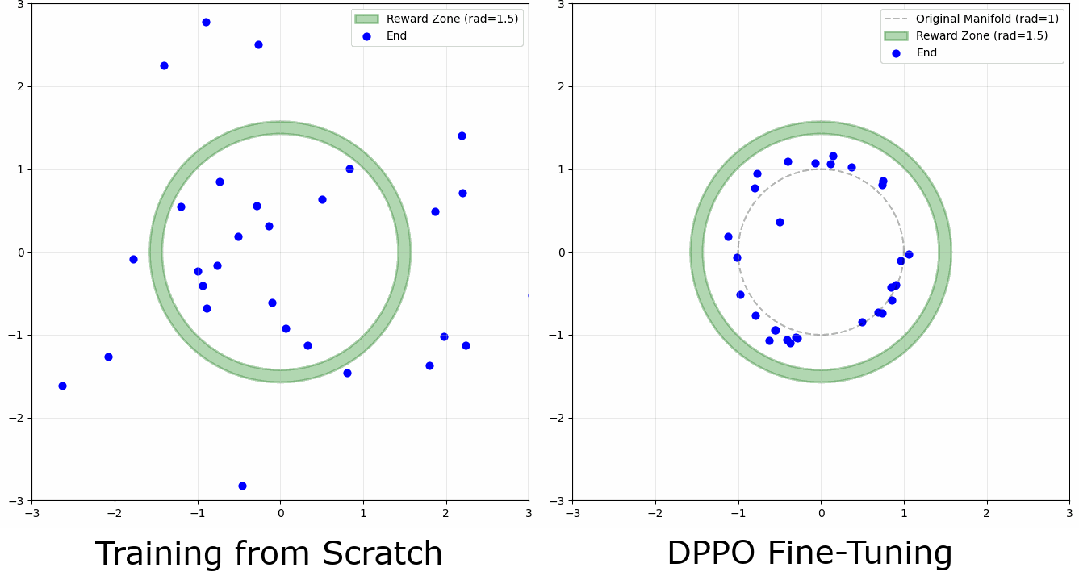
理论上,和PPO一样,只要提供足够多的回合数,就能最大化奖励。但在强化学习的实际训练中,样本效率才是关键。虽然我们的模拟环境降低了采样成本,但对于灵巧操控这类仿真到现实迁移效果差的任务,我们仍希望利用真实演示数据,用尽可能少的回合达成目标。因此,我们先尝试仅用300个回合从头开始训练,观察其性能曲线。在下图及后续图表中,蓝点代表去噪后的样本,这些是在训练过程中定期评估得到的。
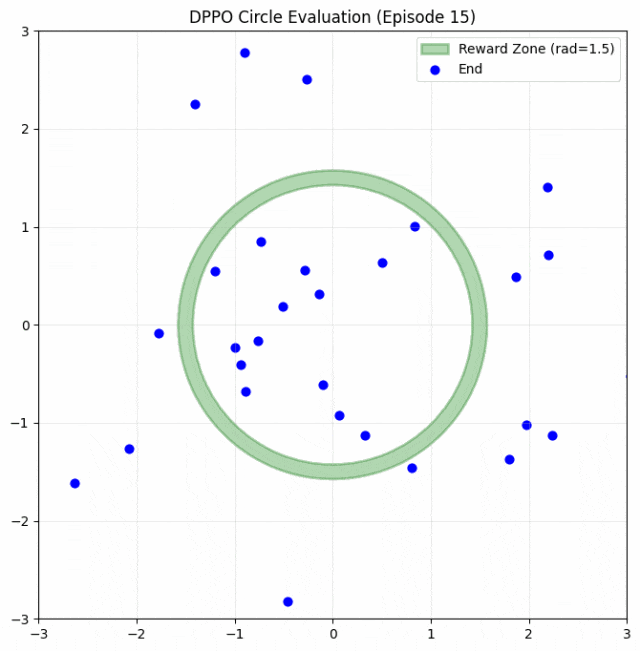
经过300个回合后,DPPO完全没有收敛的迹象,样本压根没有向高奖励区域靠近。这并不意外:扩散模型本身就需要大量样本,再叠加强化学习众所周知的样本低效问题,失败是常态。即使将回合数增加到5000,如果不仔细调整超参数,也同样难以收敛。
从专家演示进行微调
在现实场景中,我们不可能拥有无限多的训练回合。因此,专家演示通常用于引导策略走向奖励最大化。为了模拟“专家演示”,我们需要一个接近高奖励区域、包含多个模式、大体形状合理但又为RL优化留有空间的分布。这里,我们选择了一个半径为1.0的圆形分布,并使用监督学习训练一个扩散模型来去噪到这个区域——这可以类比为从演示中学习,或在互联网数据上进行预训练。经过3万个轮次后,生成数百个样本的可视化效果如下:
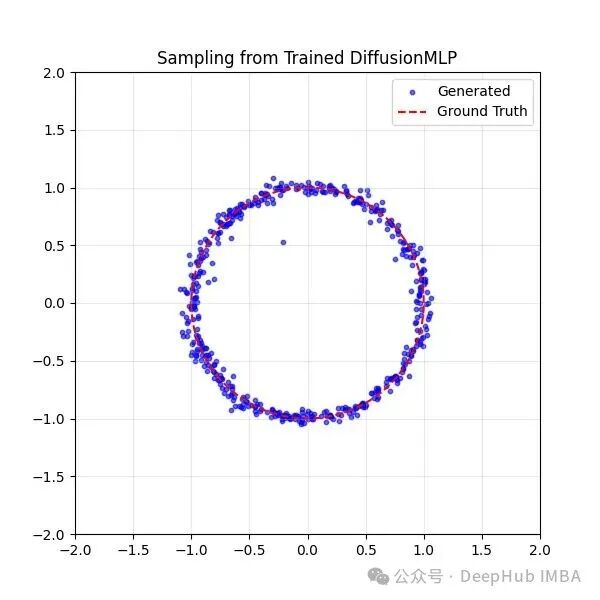
微调前的预训练动作分布(去噪轨迹未画出)。
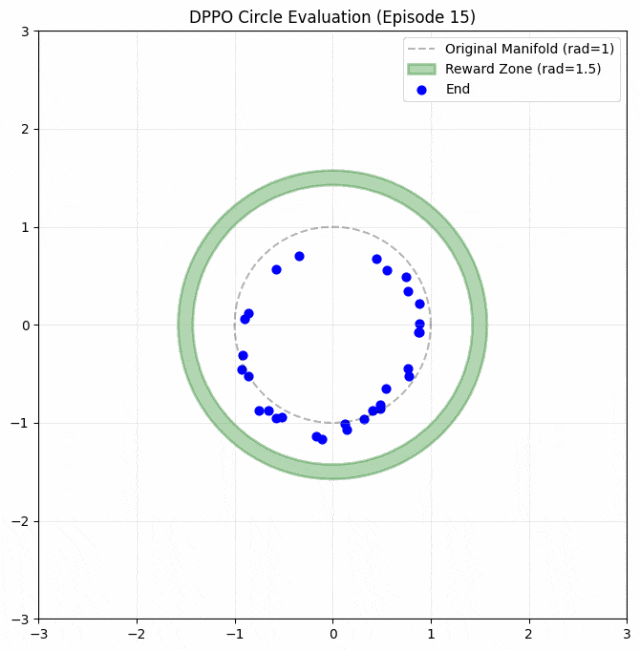
加载这个预训练的模型检查点,然后再运行DPPO进行微调,性能提升明显且行为符合预期:大约150个回合后,样本点开始收敛到高奖励区域。然而,策略通常只是找到了第一个被探索到的高奖励模式,而不是均匀分布在半径为1.5的环上。
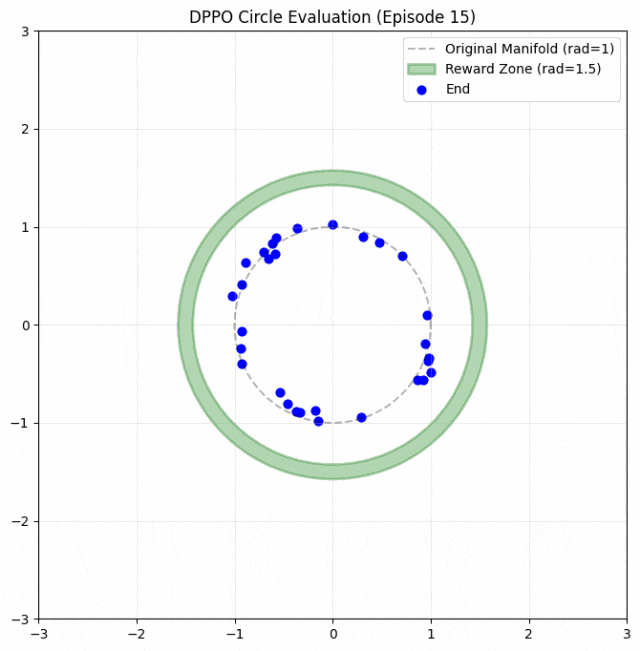
DPPO微调成功地将动作从半径1的预训练分布,引导至半径1.5的高奖励区域,效果远优于从头训练。
添加KL约束
Flow-GRPO等工作在PPO目标函数之外添加了KL散度约束。对于LLM和图像生成模型(Flow-GRPO的主要应用场景),倾向于生成有效的文本和语义正确的图像是有道理的。在机器人领域,我们可能不那么关心行为克隆的原始分布,只是用它来引导策略进入通常稀疏且初次尝试难以成功的高奖励区域(例如,“是否成功拿起咖啡杯”)。但是,如果使用的是可能被“利用”的密集奖励(例如,“杯子举得多高”),那么KL约束就很有用了——因为策略很容易学会用“向上抛杯子”这样的动作来钻奖励的空子。
DPPO和Flow-GRPO的目标函数对比如下:
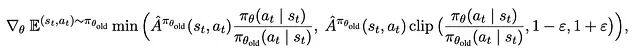
DPPO目标
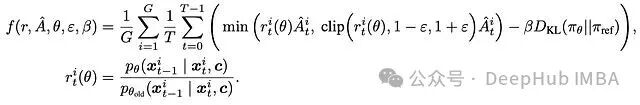
Flow-GRPO目标
Flow-GRPO中的组大小G可以替代GAE进行优势估计。KL约束确保新策略不会偏离旧策略太多,可以防止收敛过程中的策略发散。策略比率则保证了更新幅度不会过大。加上KL约束后,损失函数变为:
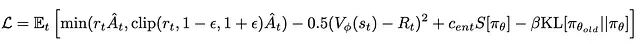
带KL约束的新DPPO目标
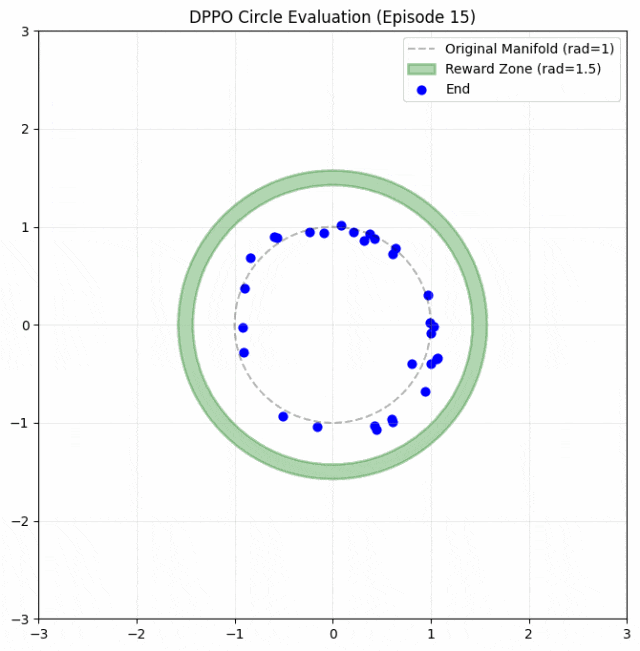
我们观察到的现象是:动作没有像之前那样收敛到一两个模式,而是保留了更多原始圆形分布的形状,分散在多个高奖励模式周围。总奖励确实偏低,但这在预期之内。Flow-GRPO论文也有类似发现:
“…我们发现省略KL约束会导致视觉多样性崩溃,这是一种奖励利用的形式…”(第5.2节)
分布在多个高奖励模式上,对应了现实中完成任务可以有多种方式的情况(例如,抓杯子既可以抓杯身也可以抓杯把)。KL约束还可能增强泛化能力,防止策略只收敛到单一的高奖励模式。例如,普通的DPPO可能只学会抓杯身,当遇到杯子烫手这种分布外的场景时就失效了;而加了KL约束的DPPO,可能还保留了抓杯把的能力。
即使抓杯把原本不在演示分布中,这个好处也可能成立。一个值得后续研究的问题是:PPO更新中的KL约束,究竟是在保持预训练分布的“形状”,还是在保持分布“本身”?在这个玩具环境中,如果带KL约束的DPPO的最优策略确实收敛到均匀分布在半径1.5的圆上,那么我们可以定性地认为“形状”被保留了,只是低奖励的特性被替换了。如果KL约束仅仅是将动作值锁死在半径1.0的圆上,那么这个结论就不成立。
消融实验
微调流程跑通之后,我们就可以探究PPO各个组件对性能的具体影响。
只微调最后几个扩散步骤
DPPO论文建议一种提高效率的做法:预训练后,复制两份模型,一份冻结用于去噪前面的时间步,另一份微调用于去噪最后几步(附录C.2建议微调最后10%的步骤以平衡效率)。但在我们的环境中,微调最后30%到50%的步骤似乎更合适(总共有50个去噪步骤)。
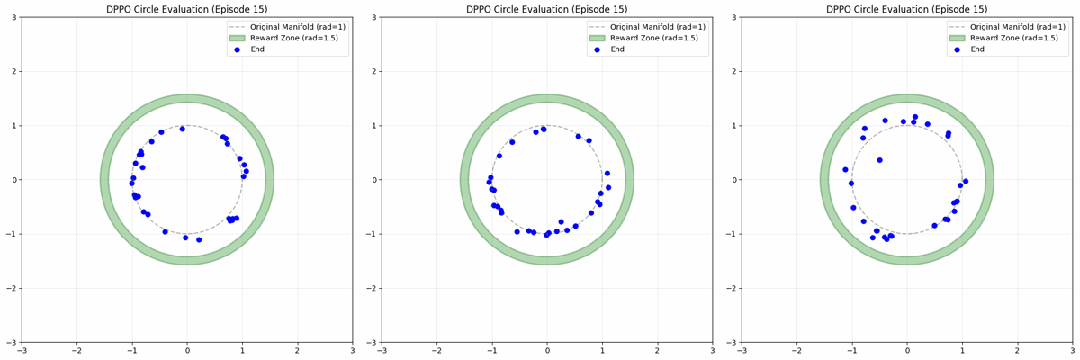
仅微调最后10%、30%、50%的步骤(从左到右)。30%到50%之间效果提升明显。
在这个环境中,我们还可以对比不同设置下产生的扩散轨迹。训练结束后,可视化20个样本的轨迹:
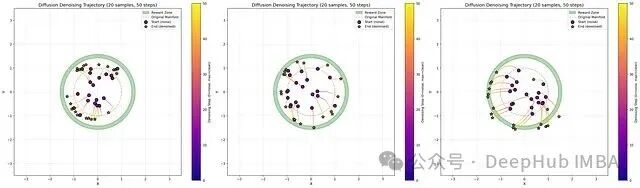
仅微调最后10%、30%、50%步骤的采样轨迹(从左到右)。
仔细观察只微调最后10%步骤产生的轨迹(最左边),可以看到样本在越过预训练流形后,有一个向高奖励区域的急剧“转向”。这个转向点之后的去噪步骤就是被微调的模型。有趣的是,微调的步骤越多,这个转向就越平滑,但预期仍然会在某个地方出现——在最左边的轨迹中,可以在第90百分位步骤看到;中间的轨迹偶尔在第70百分位出现;最右边的轨迹在第50百分位已经是平滑过渡了。如果转向的急剧程度与微调效果差相关(急剧可能意味着最后几步在过度补偿),那么可以考虑将轨迹的急剧程度作为拟合质量的指标,尤其是在高维场景下难以直接定位问题时。
与微调整个轨迹的结果进行对比:
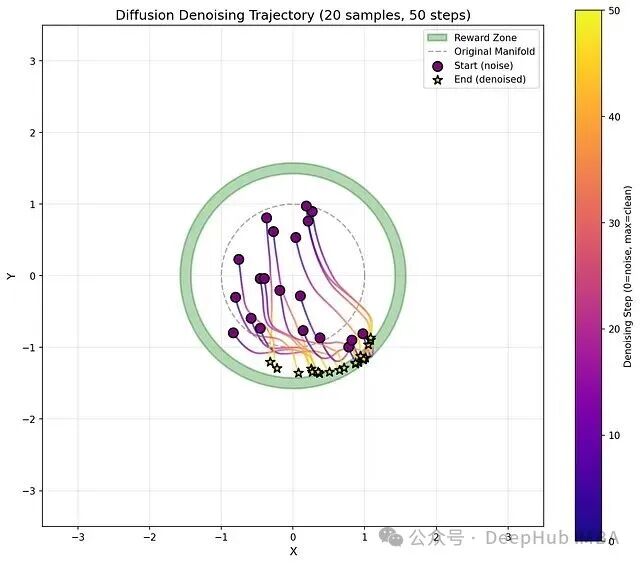
线条颜色更深,表明样本被显著地推向了高奖励区域,这也显示了初始扩散步骤的重要性。
策略比率裁剪与学习率的交互
直觉上,这两者作用类似。策略比率裁剪控制着策略变化的幅度,而执行器(actor)的学习率也决定了参数更新的速度。
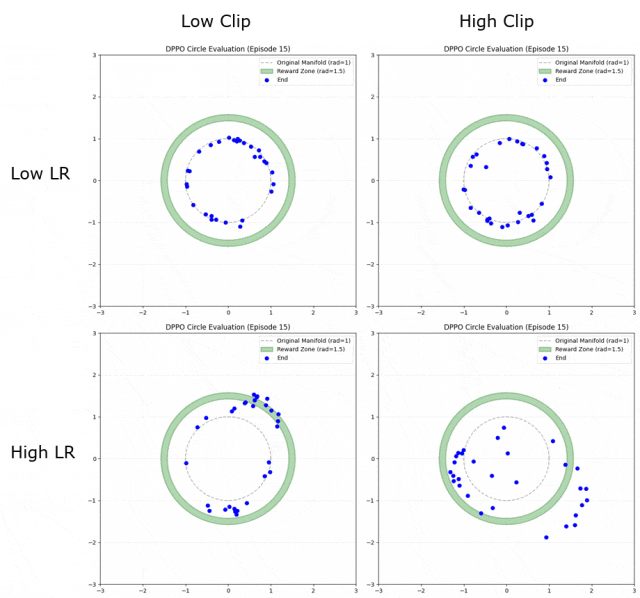
低/高裁剪幅度与学习率的对比(裁剪幅度 = 0.1/0.4,学习率 = 1e-4, 5e-3)。高裁剪幅度意味着允许更大的策略偏移。
实验结果表明,学习率的影响超过了策略裁剪。这说得通——如果参数空间的偏移过大,策略比率会变得非常巨大。运行了几个实验后,结论很清晰:学习率是最需要仔细调校的超参数,策略裁剪无法阻止过于激进的更新(即使将裁剪幅度设到0.01,配上高学习率也无济于事)。有趣的是,低学习率似乎有助于保留奖励区域内的多个模式。
移除策略比率裁剪
如果完全移除策略比率裁剪,将min()函数两边的项都设为优势值乘以对数概率(注意,如果只用优势值而不乘以对数概率,梯度就断了),动作会收敛到一个比不加KL项时更紧密的分布(与上一节高裁剪幅度的结果类似),但奖励仍然较高。这也暴露了环境复杂度的局限性——这里没有那种一旦性能下降就难以恢复的区域,而策略比率裁剪正是为防止这种情况而设计的。不过有趣的是,这又一次成为了一个能防止奖励模式崩溃的因素。另一个有趣的现象是,训练久了策略会在多个奖励模式之间跳跃——像是高学习率行为的稍微稳定版本。
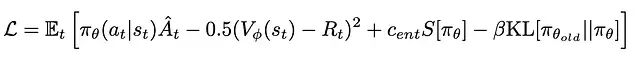
其他超参数的一些观察
- 优化轮次数(K_epochs)确实与裁剪幅度(eps_clip)成反比,两者都在权衡每次更新中策略改进的幅度。
- DPPO更新间隔的时间步数与学习率成反比,两者都在权衡策略改进的速度。
总结
本文详细解释了如何在一个极简的单步环境中为扩散模型实现DPPO,旨在提供一个比典型机器人环境更易于理解训练动态的平台。我们进行了多项实验,包括仅微调最后几个去噪步骤,以及调整各种PPO超参数。读者可以从这些结果中得出自己的见解,也可以动手修改环境,尝试提升样本效率——这仍然是PPO算法面临的关键瓶颈。
完整的实验代码可以在此查看:https://gist.github.com/nsortur/ec9660a0026598e54f1e4fb583e077ed 。对于此类前沿技术的深入讨论与实践分享,欢迎访问云栈社区的人工智能板块,与更多开发者交流。
 发表于 2026-2-10 07:58:22
|
查看: 216|
回复: 0
发表于 2026-2-10 07:58:22
|
查看: 216|
回复: 0
