上周线上炸了。
支付业务出了问题,用户支付成功,但订单表没数据。更诡异的是,修改订单时有时也会提示获取锁超时。
DBA看了一眼数据库连接,发现几个事务一直没提交,锁着订单表的几行数据。
排查了半天,最后发现是某个业务接口忘了提交事务。
按理说,事务没提交应该很容易发现,但这个bug藏得比较深,出现了一些反常识的现象:
- 业务代码正常执行完毕:没有任何报错,日志也正常打印。
- 日志显示事务已提交:commit方法被调用了,但数据库里没数据。
- 偶尔会成功:大部分时候失败,但偶尔能正常插入订单。
这种情况让人摸不着头脑。代码没报错,日志也正常,为啥数据就是不进库?带着这个疑问,我开始了排查。
应急处理与问题定位
线上出问题,肯定先恢复业务。最快的办法就是重启应用,强制释放这些被占用的连接。
重启后,支付功能确实恢复了正常。但这只是权宜之计,必须找到根因。对比最近的发布记录,一个新上线的业务引起了我的注意。检查代码,果然发现了问题:
@Service
public class SomeService {
public void handleSpecialCase() {
// 开启事务
sqlSession.connection.setAutoCommit(false);
// 执行SQL
mapper.insert(data);
// 特殊情况下,忘记commit了!
if (specialCondition) {
// 某些情况下会return,但没commit
return;
}
sqlSession.commit();
}
}
看,在 specialCondition 这个特殊分支下,方法直接 return 了,commit 根本没执行。
快速修复很简单,立即补上遗漏的 commit,并确保异常时回滚:
@Service
public class SomeService {
public void handleSpecialCase() {
try {
sqlSession.connection.setAutoCommit(false);
mapper.insert(data);
if (specialCondition) {
sqlSession.commit(); // 补上!
return;
}
sqlSession.commit();
} catch (Exception e) {
sqlSession.rollback();
throw e;
}
}
}
修复后上线,问题暂时解决。但一个更大的疑问浮出水面:为什么一个业务的事务没提交,会影响到其他完全不相关的支付业务?这超出了我最初对 Java 事务管理的理解。
深入源码:复用的连接与“被污染”的事务
周末我花了半天时间调试 Spring 事务管理的源码,终于理清了这条诡异的传播链。
首先,我在 Spring 的 getTransaction 方法打了断点,发现出问题的支付请求都会走进一个特定的逻辑分支:
public final TransactionStatus getTransaction(@Nullable TransactionDefinition definition)
throws TransactionException {
// 使用默认的事务定义
TransactionDefinition def = (definition != null ? definition : TransactionDefinition.withDefaults());
// 关键:获取当前事务对象
Object transaction = doGetTransaction();
boolean debugEnabled = logger.isDebugEnabled();
// 判断是否是已存在的事务
if (isExistingTransaction(transaction)) {
// 发现已存在的事务,直接返回
return handleExistingTransaction(def, transaction, debugEnabled);
}
// 创建新事务的逻辑...
}
问题就出在 doGetTransaction() 这个方法获取到的 transaction 对象,以及后续 isExistingTransaction(transaction) 的判断上。
1. doGetTransaction 会复用连接
跟进 doGetTransaction:
protected Object doGetTransaction() {
DataSourceTransactionObject txObject = new DataSourceTransactionObject();
txObject.setSavepointAllowed(this.isNestedTransactionAllowed());
// 关键:从TransactionSynchronizationManager获取连接
ConnectionHolder conHolder = (ConnectionHolder) TransactionSynchronizationManager.getResource(this.obtainDataSource());
txObject.setConnectionHolder(conHolder, false);
return txObject;
}
TransactionSynchronizationManager.getResource() 会从线程本地存储(ThreadLocal)中获取连接资源(ConnectionHolder)。如果上一个业务没有正确清理,这里拿到的就是一个“被污染”的连接。
2. isExistingTransaction 的判断逻辑
然后,isExistingTransaction 会根据这个 ConnectionHolder 的状态进行判断:
protected boolean isExistingTransaction(Object transaction) {
DataSourceTransactionObject txObject = (DataSourceTransactionObject)transaction;
return txObject.hasConnectionHolder() && txObject.getConnectionHolder().isTransactionActive();
}
关键在于 isTransactionActive()。如果上一个业务用完连接后,事务没提交也没回滚,这个标记就一直是 true。当下一个业务通过 doGetTransaction 拿到这个 ConnectionHolder 时,Spring 会认为“当前已存在一个活跃事务”。
3. 被污染的连接从何而来?
回顾前面出问题的 SomeService 代码(用 Spring 事务管理器重写后更清晰):
@Service
public class SomeService {
public void handleSpecialCase() {
// 开启事务
TransactionStatus status = transactionManager.getTransaction(new DefaultTransactionDefinition());
try {
// 执行SQL
mapper.insert(data);
// 特殊分支:直接return,没commit!
if (specialCondition) {
return;
}
transactionManager.commit(status);
} catch (Exception e) {
transactionManager.rollback(status);
throw e;
}
}
}
当执行到特殊分支直接 return 时:
ConnectionHolder 已经被标记为有事务(isTransactionActive() = true)。- 但事务既没
commit,也没 rollback。
- 方法结束后,Spring 会清理资源吗?实际上,由于事务未完成,
ConnectionHolder 仍被绑定在 TransactionSynchronizationManager 中(ThreadLocal),等待后续操作。
- 这个带着活跃事务标记的连接,就这么留在了线程上下文中。
4. 复用导致的问题连锁反应
当支付业务 PaymentService.createOrder() 执行时,它同样会调用 transactionManager.getTransaction(...)。如果它所在的线程刚好复用了上面那个被污染的 ConnectionHolder,就会发生以下情况:
getTransaction 判断 isExistingTransaction 为 true。- 进入
handleExistingTransaction 流程,根据事务传播行为(默认是 REQUIRED),它会加入这个现有事务,而不是创建一个新事务。
- 此时,返回的
TransactionStatus 对象中,isNewTransaction() 方法会返回 false。
支付业务执行完,调用 commit,关键来了。在 processCommit 方法中:
private void processCommit(DefaultTransactionStatus status) throws TransactionException {
try {
boolean beforeCompletionInvoked = false;
try {
prepareForCommit(status);
triggerBeforeCommit(status);
triggerBeforeCompletion(status);
beforeCompletionInvoked = true;
if (status.hasSavepoint()) {
status.releaseHeldSavepoint();
}
// 关键判断:只有新事务才真正提交
else if (status.isNewTransaction()) {
if (status.isDebug()) {
logger.debug(“Initiating transaction commit“);
}
// 真正执行数据库commit
doCommit(status);
}
// 如果不是新事务,什么都不做!
} catch (UnexpectedRollbackException ex) {
// ...
}
} finally {
cleanupAfterCompletion(status);
}
}
因为 status.isNewTransaction() 返回 false(这是一个加入的事务),所以 doCommit(status) 根本不会执行!数据库连接上的 commit() 操作被跳过了。这就是为什么日志显示提交了,数据却没入库的原因。更糟糕的是,这个未提交的连接又被还了回去,继续污染下一个请求。
完整问题链路与图解
整个问题的传播链条可以清晰地总结为以下步骤:
SomeService.handleSpecialCase() 在特殊分支未提交事务便返回。- 方法结束,
ConnectionHolder 仍绑定在 TransactionSynchronizationManager 中,且 isTransactionActive() = true。
PaymentService.createOrder() 调用 doGetTransaction()。doGetTransaction() 从 TransactionSynchronizationManager 拿到了被污染的 ConnectionHolder。isExistingTransaction() 判断为 true,认为已有事务。- 走
handleExistingTransaction 流程,支付业务加入了这个现有事务(isNewTransaction = false)。
- 支付业务代码执行完,调用
commit。
processCommit 中判断 isNewTransaction() 为 false,跳过 doCommit。- 数据未入库,
ConnectionHolder 继续留存,污染下一个业务。
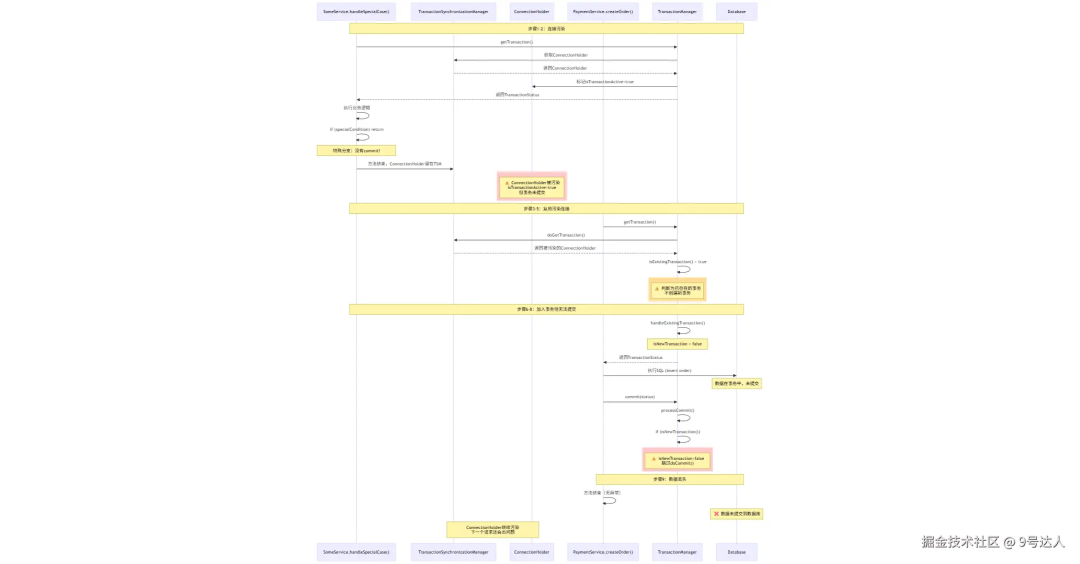
为什么偶尔会成功?
因为 TransactionSynchronizationManager 是基于 ThreadLocal 实现的。如果支付请求被分配到一个“干净”的、没有遗留被污染连接的线程,它就能正常创建新事务并提交。但只要分配到那个“脏”线程,就会中招。这解释了问题的随机性。
预防与加固措施
吃了这次亏,我们加强了预防措施。
1. 连接池健康检查
配置连接池(如 HikariCP),在取出连接时重置其状态,这是一个有效的“消毒”手段。
spring:
datasource:
hikari:
connection-test-query: SELECT 1
validation-timeout: 3000
# 从池子取连接前先执行此SQL,重置自动提交状态
connection-init-sql: SET autocommit=1
2. 数据库层监控告警
应用日志正常不代表数据库没事。必须建立 数据库 层面的监控,特别是长事务监控。
-- 查找执行超过30秒的事务
SELECT *
FROM information_schema.innodb_trx
WHERE TIME_TO_SEC(TIMEDIFF(NOW(), trx_started)) > 30;
配置告警规则,一旦发现长事务立即通知。
踩坑总结与反思
这次事故给我上了深刻的一课:
- 连接池不只是性能优化:它意味着状态复用。一个连接上的残留状态(如未提交事务)会像病毒一样传染给后续所有复用它的业务,理解这一点对排查复杂问题至关重要。
- 事务管理必须严谨:手动管理事务时,
try-catch-finally 结构要写全。commit 和 rollback 一个都不能少,尤其要警惕所有可能提前退出的分支路径。
- 监控要立体化:不能只盯着应用日志。数据库的慢查询、长事务、锁等待、连接数等指标,是发现此类“静默”故障的关键。
- 调试优于空读:遇到无法从逻辑上解释的诡异问题,直接动手调试源码。跟着调用栈一步步走,查看关键变量的状态,往往比埋头看文档和代码更快找到答案。
每一次线上事故都是昂贵的学费,但也是团队成长的契机。把问题现象、排查思路、根本原因和解决方案清晰地记录下来并分享,不是为了追责,而是为了建立共同的技术认知,避免在同一个地方摔倒两次。技术债的可怕之处不在于欠债本身,而在于欠了债却无人知晓、无人总结。
在云栈社区这样的平台上交流分享,正是将个人经验转化为团队乃至社区知识资产的有效途径。
 发表于 2026-2-11 20:51:14
|
查看: 183|
回复: 0
发表于 2026-2-11 20:51:14
|
查看: 183|
回复: 0
