去年二月,DeepSeek 对外开源了 3FS,其基于 RDMA 的架构设计实现了极高吞吐,在 100Gb 网络下能用 Fio 跑满带宽,成为业界关注的标杆。微信 WFS 团队第一时间跟进学习,但我们面临的现实问题是:内部庞大的存量集群环境并不支持 RDMA 通信。因此,我们没有盲目追随 RDMA,而是将焦点转向了传统 TCP 网络下的吞吐极限优化,启动了 WFS Ultra 极限性能优化项目。最终,在同等 200Gb 网络环境中,我们实现了 Fio 吞吐超越 RDMA 加持的 3FS。目前该优化已在内部稳定运行半年,本文将详细分享其核心优化思路。
性能数据
测试环境如下:
- Client: 1 台 T0-CM6AX
- Server: 6 台 T0-CM6AX (WFS 与 3FS 同环境部署)
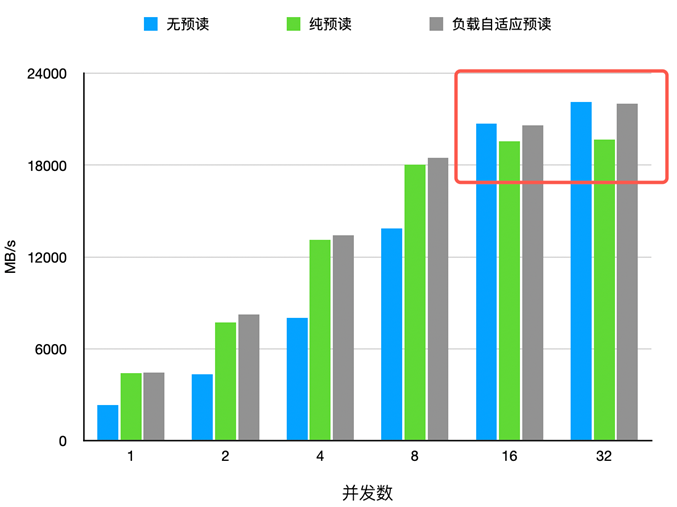
经过优化,WFS 可以轻松打满 200G 网卡带宽。从下面的 Fio 测试结果可以看到,带宽达到了 21.7 GiB/s (约 23.2 GB/s),完全占满了 200Gb 的理论带宽。
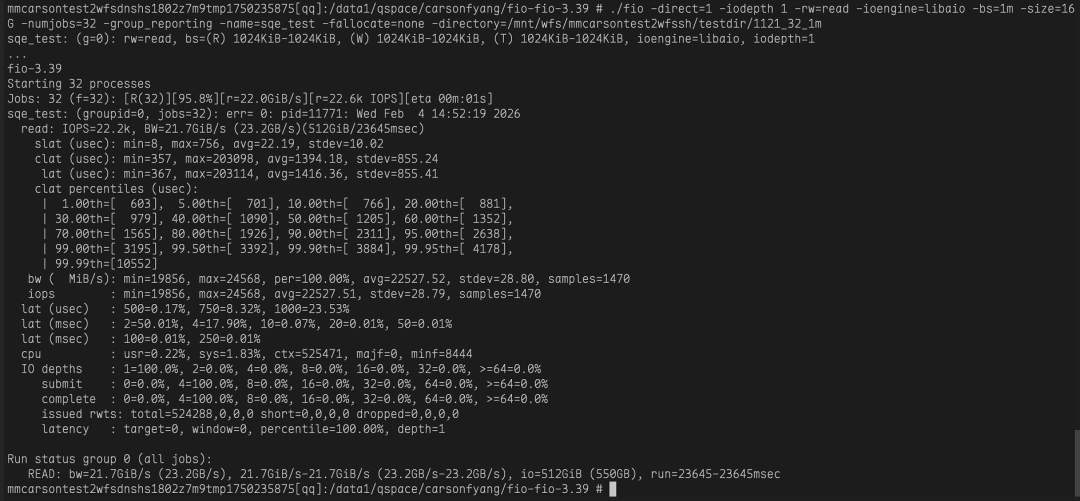
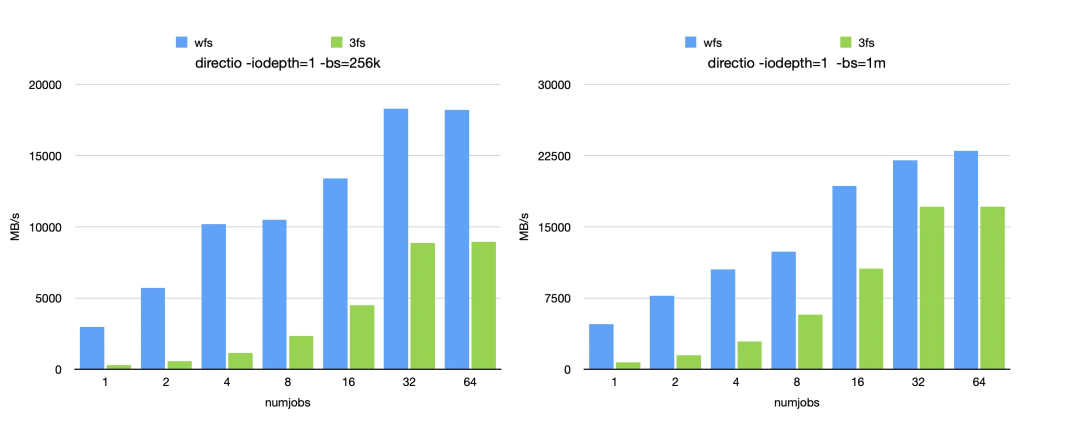
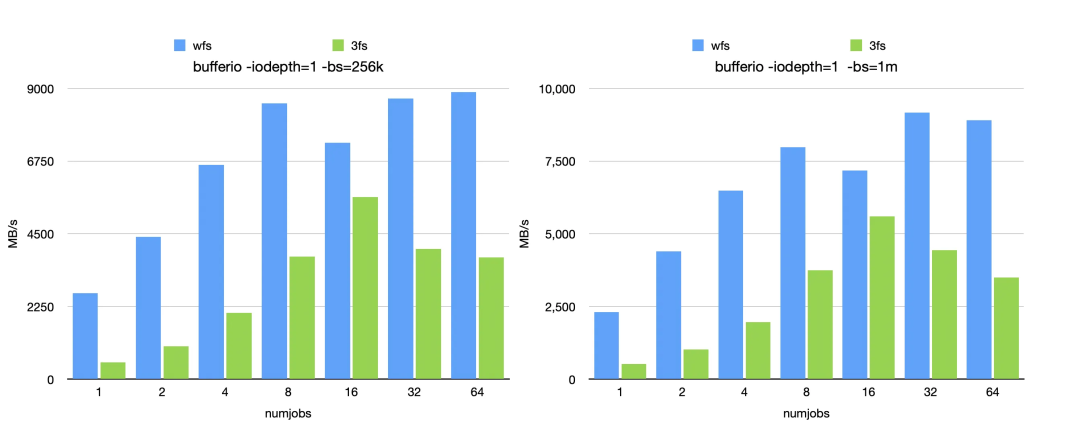
此外,在针对 DirectIO 与 BufferIO 不同块大小的读吞吐测试中,WFS 经过本次优化后,对比 3FS 均展现出明显的性能优势。从目前公开的资料看,WFS 是业界首个能够在传统网络下,不依赖 RDMA,仅凭 TCP 协议栈就能用 Fio 跑满 200Gb 网卡的分布式文件系统。
DirectIO 性能对比
BufferIO 性能对比
关键优化点
Run-To-Completion 线程模型
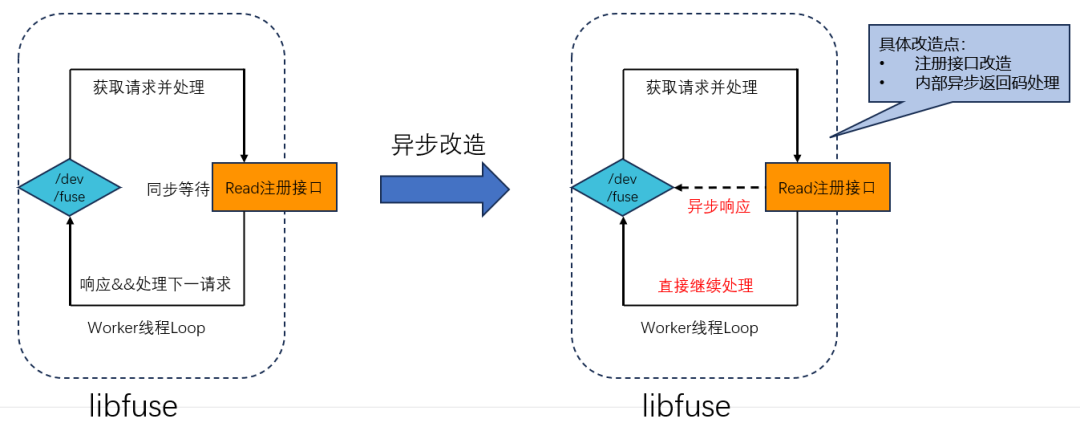
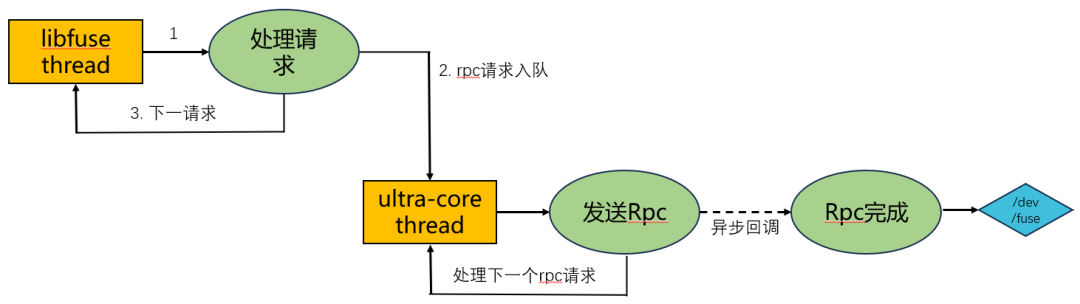
在 Fuse 使用场景中,传统线程由 libfuse 创建,不具备协程环境。这使得老版本 wfsfuse 采用同步等待线程模型:每个读请求占用一个线程,线程必须同步等待 RPC 调用返回才能继续工作。想要提升性能,就只能开启大量线程,这会造成严重的资源浪费和线程切换开销。为了实现高效的 Run-To-Completion 线程模型,我们实施了两项核心优化。
深度定制的 ultra-core 异步网络组件
首先,我们将 libfuse 的读接口改造为异步形式,完成非阻塞化。改造后,线程不再因等待 RPC 响应而阻塞,可以持续处理任务,大幅提升整体效率。通过重新设计接口调用逻辑,引入 ultra-core 的异步回调机制,读请求的发起与结果处理得以解耦。线程发起请求后无需等待,可以立即处理下一个任务,当请求结果返回时,再通过回调函数进行后续处理。这种对 TCP/IP 网络栈的深度异步化改造,是提升吞吐的关键。
libfuse/ultra-core 实施一致绑核策略
我们将 ultra-core 异步网络组件与 libfuse 的线程逻辑深度整合,通过将线程绑定到特定的 CPU 核心,避免线程在多个 CPU 核心之间频繁切换。这一措施有效减少了 CPU Cache Miss 的概率,进一步提升了线程的执行效率,使得整个请求处理流程在逻辑上近似于在一个线程内执行完毕。
全链路零拷贝
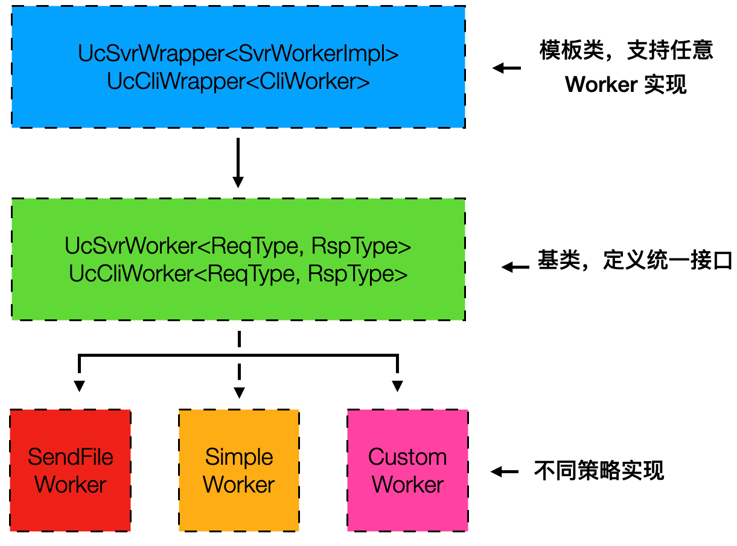
读写可插拔架构
Linux 系统提供了多种数据收发方式,性能与适用场景各异。为了快速验证各种方案的优化效果,我们设计并实现了 ultra-core 读写可插拔架构。该架构允许我们灵活替换不同的数据读写方案,通过对比测试,最终选定客户端采用 splice、服务端采用 sendfile 的组合方案作为读吞吐极限性能优化方案。
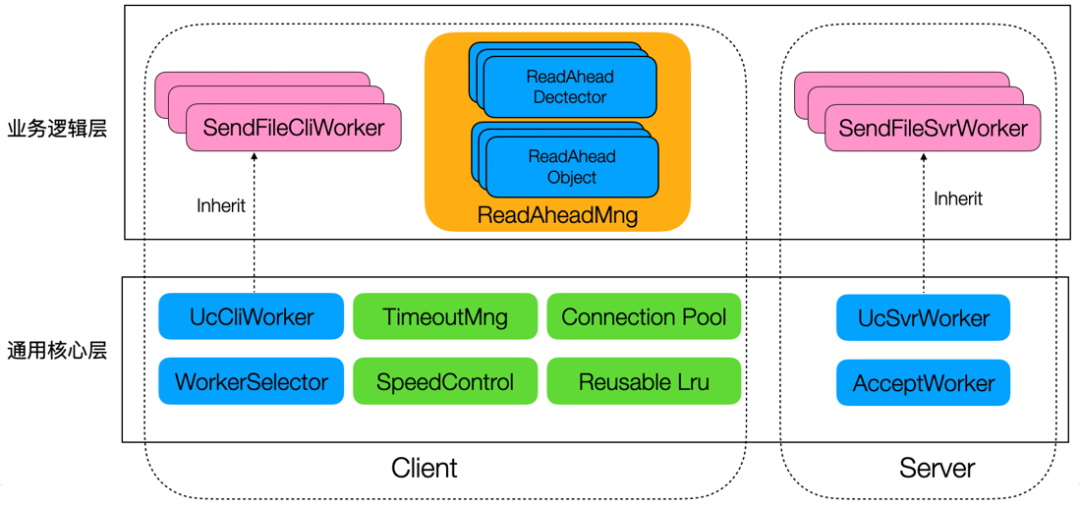
老版本 WFS 在数据传输过程中存在大量的 CPU 拷贝操作,造成了严重的性能损耗。因此,性能优化的核心目标就是实现全链路零拷贝。
客户端零拷贝
客户端原有的数据传输链路中总共存在 5 次拷贝:内核 socket → 用户空间 → 反序列化 → 缓存 → fuse buffer → /dev/fuse。每一次拷贝都消耗 CPU 资源,拖慢速度。通过 ultra-core 网络组件配合 splice 接口,并结合自定义网络协议格式,我们实现了零拷贝传输。新流程简化为:内核 socket --(splice move)--> /dev/fuse,直接绕过了用户空间的多次拷贝。
服务端零拷贝
服务端原有的数据传输链路存在 3 次拷贝:内核 disk → 用户空间 → 序列化 → 内核 socket。多次拷贝导致服务端 CPU 负载高,限制带宽提升。我们采用 sendfile 接口,彻底消除了用户空间和内核空间的数据拷贝。数据从内核 disk 通过 DMA 传输到 page cache,再通过 SG-DMA 直接传输到 NIC。整个过程完全由 DMA 完成,不占用 CPU 资源,大幅降低了服务端的 CPU 消耗。这种极致的零拷贝优化,是性能突破的核心。
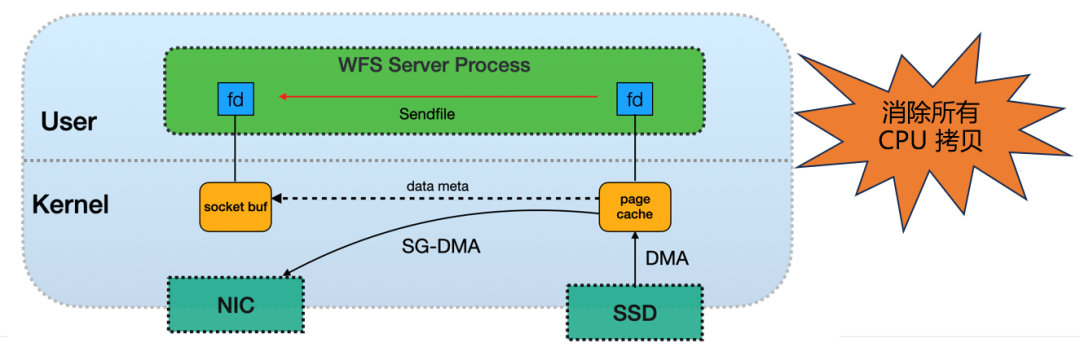
经过优化,全链路总共减少了 8 次 CPU 拷贝。服务端启用 sendfile 模式后,性能表现极为出色,跑满 200Gb 带宽仅占用 3 个 CPU 核心。但该模式存在一个缺点:不支持实时 CRC 校验。为了规避这一风险,我们通过定期数据巡检的方式,来降低在该模式下访问到静默损坏数据的概率。
负载自适应预读
预读策略
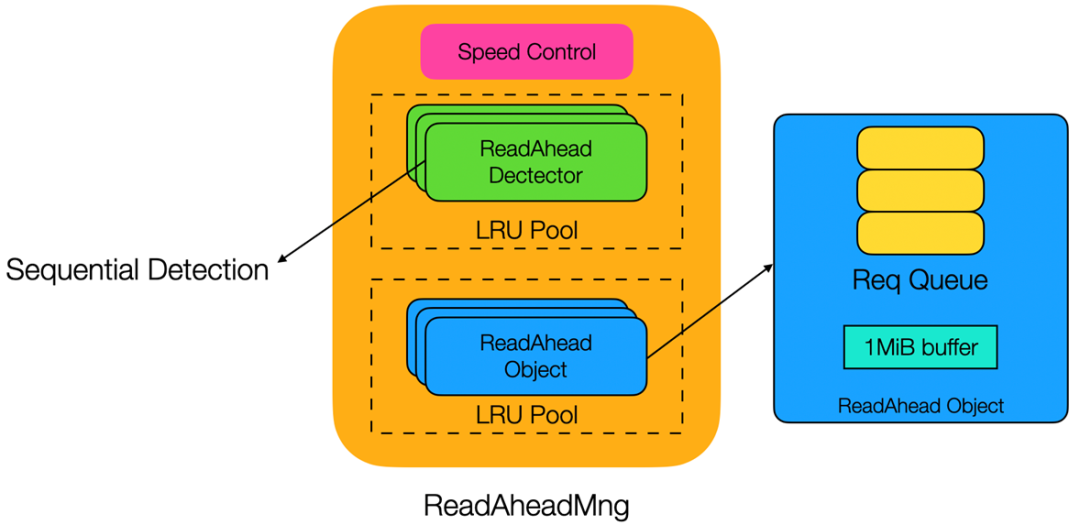
预读是提升文件读取速度的有效手段。为了提高低并发下的读取速度,我们引入了预读机制。当系统探测到顺序读行为时,会主动发起 ReadAhead 操作,提前将后续可能需要的数据读取到内存中。但预读需要开辟额外内存,内存分配可能带来不可预期的抖动。我们采用内存池优化方案,预先分配固定大小的内存块,避免了运行时的内存申请与释放。由于内存有限,WFS 采用细粒度流式预读,在相同内存消耗下,最大程度提升单路文件吞吐。
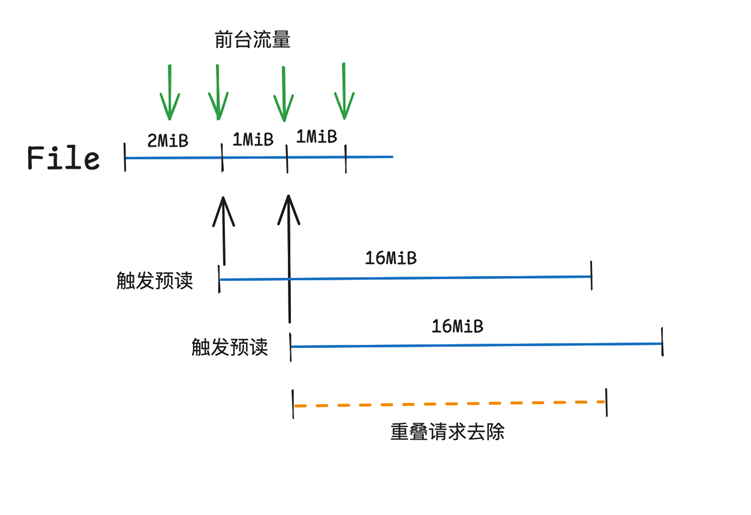
负载自适应策略
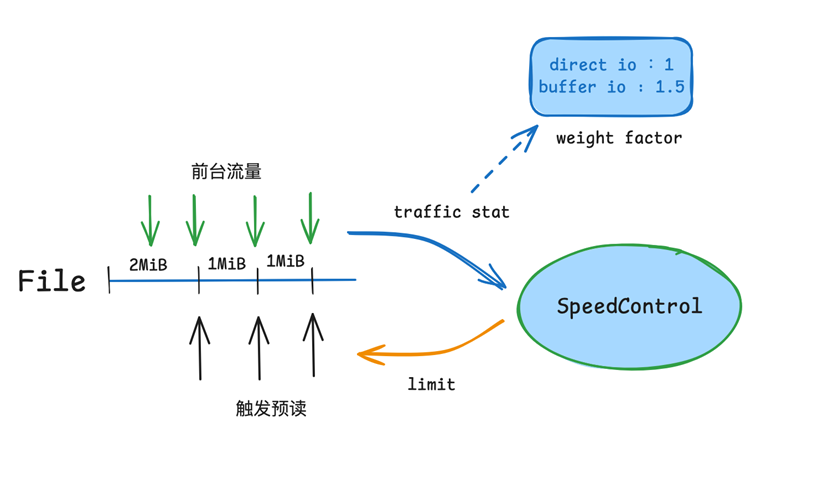
其次,在多并发场景下,预读引入的额外 CPU Copy 会影响 Client 整体的读性能。针对这一问题,我们对预读机制实施了严格的限速策略,保证在高并发场景下,系统的吞吐性能不受影响。同时,系统内部会区分 BufferIO 和 DirectIO。BufferIO 模式下存在额外的 Page Cache 拷贝,叠加预读拷贝后性能下降会更严重。因此,我们在限速统计流量时,给 BufferIO 赋予更大的权重(例如 1.5倍),当系统负载较大时,自动停止预读操作,保障高并发场景下的带宽性能。这种动态调整策略,体现了高性能架构设计的灵活性。
优化应用场景
预热Overlap加速模型加载
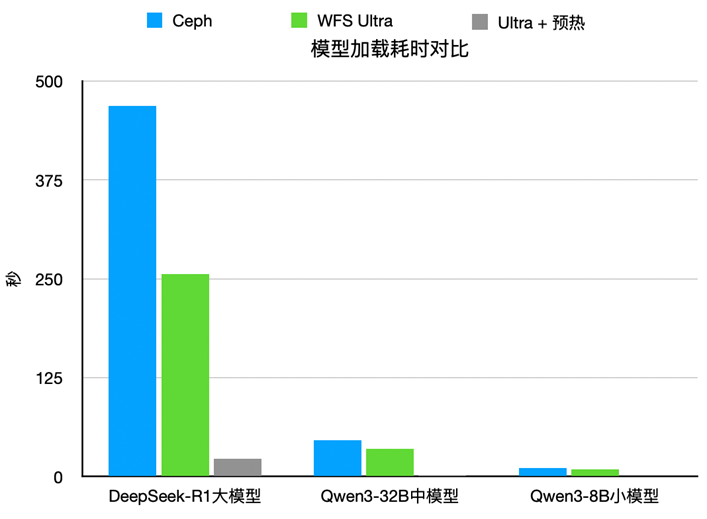
在 AI 模型训练与推理场景中,模型加载耗时直接影响业务启动效率。我们将 WFS 的优化方案应用于此,通过预热 Overlap 策略,进一步实现了模型加载速度的大幅提升。该策略通过提前将模型数据加载到内存中,实现模型加载与框架初始化的并行执行,极大缩短了整体启动时间。测试数据显示,不同规模模型的参数加载耗时均有显著下降。
| 模型 |
Ceph加载耗时 |
WFS直接加载耗时 |
WFS预热优化耗时 |
| DeepSeek-R1(642GB) |
7分49秒 |
4分16秒 |
23秒 |
| Qwen3-32B(62GB) |
46秒 |
35秒 |
2秒 |
| Qwen3-8B(16GB) |
11秒 |
9秒 |
小于1秒 |
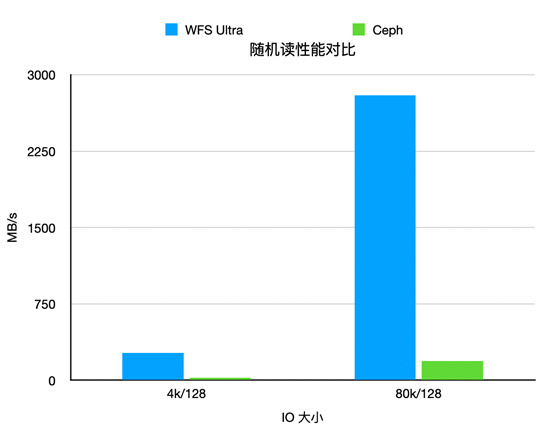
异步化加速随机读
在高并发场景,或网络延迟较高的部署环境下,异步化改造对随机读性能的提升效果尤为显著。我们在内部生产环境实测,在相同并发条件下,WFS Ultra 版本的随机读性能相较于常规实现,差距可达 10 倍以上。
总结
以上是 WFS 针对传统 TCP 网络的极限性能优化实践。通过 Run-To-Completion 线程模型、全链路零拷贝、负载自适应预读等关键优化,我们充分发挥了传统 TCP 网络的性能极限。最终在 200Gb 网络环境下,实现了 Fio 吞吐超越 RDMA 加持的 3FS,稳稳跑满 200Gb 网卡带宽。
相较于 3FS 依赖 RDMA 硬件的方案,WFS 的优化方案更具普适性,无需额外的硬件升级支持,为存量大规模集群的性能提升提供了可行路径。当然,我们也认识到 RDMA 在 KVCache 等延迟敏感场景、以及更大吞吐网卡环境下的性能上限优势,WFS 团队也正在完善这部分的支持。本文分享的实践,希望能为业界在传统网络环境下追求极致性能提供一些参考。更多类似的系统架构与性能调优讨论,欢迎关注云栈社区的技术论坛。
 发表于 2026-2-12 12:59:10
|
查看: 132|
回复: 0
发表于 2026-2-12 12:59:10
|
查看: 132|
回复: 0
