2025年第四季度,英特尔代工业务(IFS)交出的财报让人倒吸一口凉气。营收45亿美元,运营亏损却高达25亿美元。新任CEO Lip-Bu Tan在财报会上坦承:“公司投资太多、太快,但需求根本不够。”更致命的是,英特尔在SEC文件里承认,在其任何一个制程节点上,都还没有拿到真正有规模的外部客户订单。

这意味着什么?意味着英特尔代工厂虽然建起来了,设备也买了,但没人来下单。就像一家米其林餐厅装修豪华、设备顶级,却门可罗雀,每天亏损的不是几千块,而是几亿美元。
很多人把英特尔的困境简单归结为“信任赤字”,但这并未触及根本。代工业务的门槛,远比想象中更技术化、更结构化,也更依赖于时间和规模的复利效应。这篇文章将从三个维度拆解:为何代工业务对后来者如此艰难?英特尔在2纳米战场的真实实力与结构性限制是什么?它必须做出何种生死抉择,才能在半导体制造这条赛道上生存下来?
一、代工业务的护城河到底有多深?
许多人误以为代工厂的核心壁垒是技术。实则不然。其核心壁垒是时间和规模累积起来的技术资产。这是一道需要几十年才能垒起来的墙,后来者想要翻越,每一步都充满血泪。
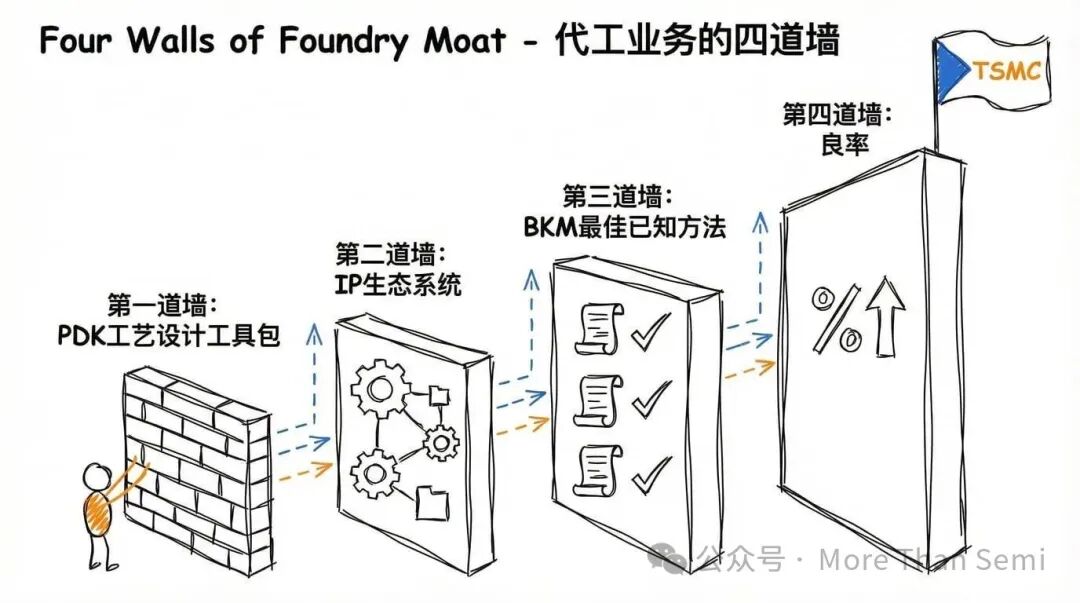
第一道墙:PDK(工艺设计工具包)
在芯片设计公司能在某个代工厂生产芯片之前,它需要一个叫做PDK的工具包。简单来说,PDK就是把代工厂的制程信息打包成设计工程师能用的形式,包括晶体管布局、电气仿真模型、成千上万条设计规则,以及让EDA工具能够分析设计的技术文件。
这里有一个最关键的概念:MHC——模型与硬件相关性。用大白话说就是:你的仿真结果,和实际生产出来的芯片行为,到底有多接近?
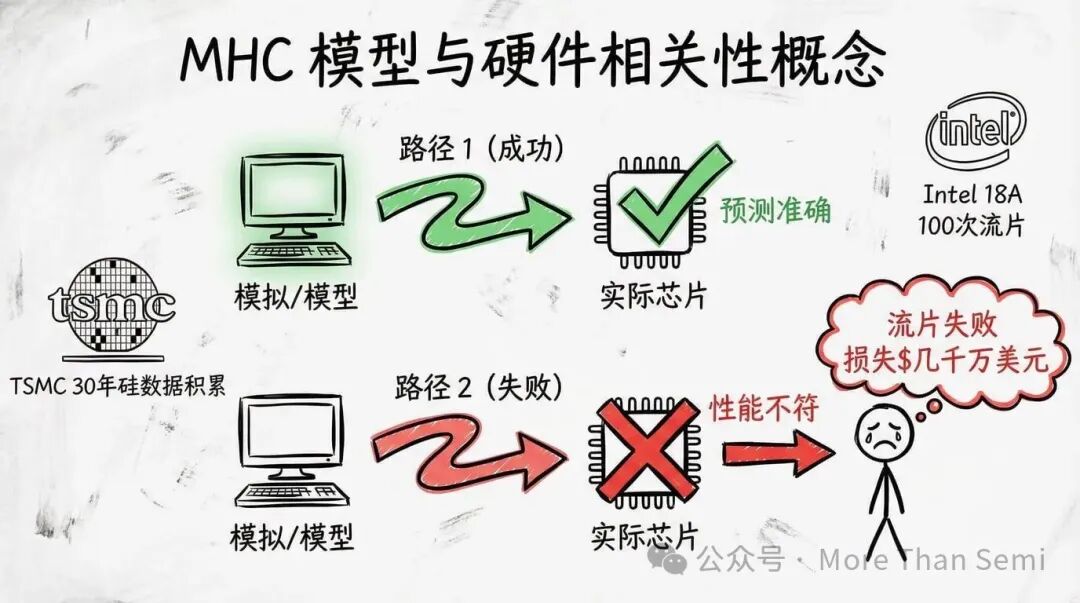
如果MHC崩塌会怎样?一家公司投入几千万美元流片,结果芯片性能与预期完全不符,那么这家客户很可能永远不会再回来。台积电的PDK为何如此强悍?因为30多年来,它为数以万计的客户生产芯片,积累的海量硅数据不断校准和优化着其模型的精度。
英特尔呢?其18A PDK 1.0在2024年7月发布,据报道已有超过100次流片。但业内普遍评估,它距离台积电达到的MHC验证水平,还有很长的路要走。
第二道墙:IP生态系统
光有PDK还不够。在SoC设计中,复杂的功能模块——比如CPU核心、PCIe接口、DDR控制器——通常是从第三方购买的预验证IP。这些IP必须在特定代工厂的特定制程上经过硅验证。
为台积电验证的IP,不能直接移植到英特尔18A上。物理设计要重做,时序约束要重新建立,硅验证也得从头开始。这个过程,最少需要12到18个月。
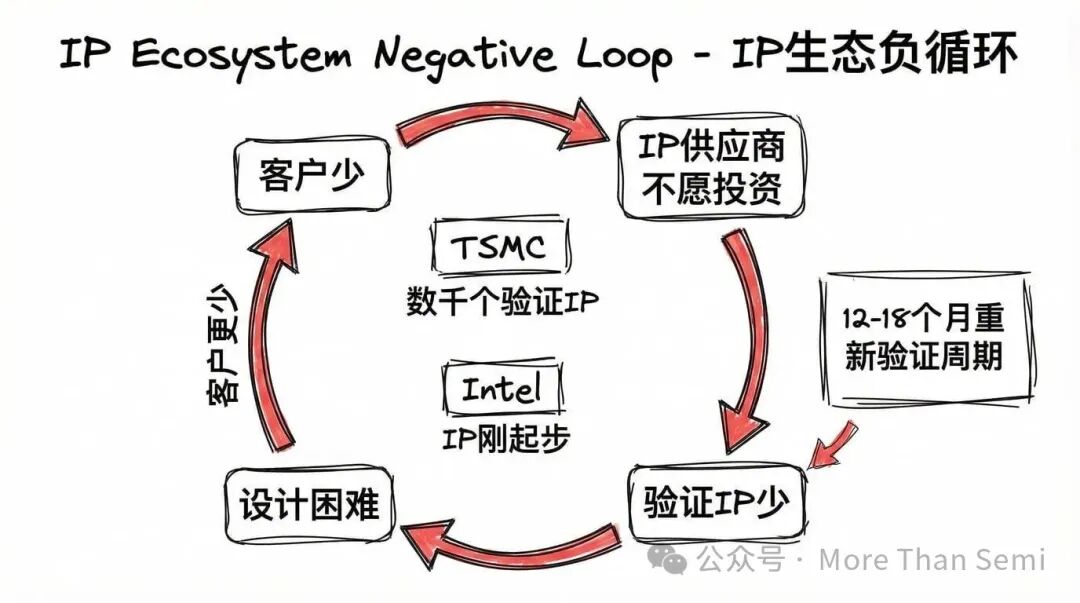
台积电的开放创新平台上,有成千上万个经过硅验证的IP模块。为何IP供应商优先为台积电开发?答案很简单:台积电客户最多,投资回报率最高。英特尔客户少,所以IP少;IP少,又导致客户更少。这是一个自我强化的负循环。
第三道墙:BKM(最佳已知方法)
在半导体制造里,BKM指的是对于先进制程中成百上千道工艺步骤的当前最优解。无论是光刻的最佳曝光条件、刻蚀的气体流量压力组合,还是CMP的抛光参数,BKM就是每个参数的优化组合。
关键是,今天的BKM并非终极答案。当发现更好的方法时,它会被实时更新。BKM不是在实验室里读论文就能学来的。它来自于跑真实的晶圆,在各种设计图案上积累工艺响应数据,发现意外的缺陷模式,并找到解决方案。你跑的晶圆越多,发现和解决问题的速度就越快。
这就是代工厂规模效应开始发威的地方。台积电同时为数百个客户生产芯片,设计千差万别,产生巨大的晶圆量。通过这个过程,各种缺陷模式的解决方案被编码成BKM,使得同一制程上的每个客户都受益。英特尔代工厂呢?几乎没有外部客户,主要通过自己的x86处理器积累BKM,自然缺少了移动AP、AI加速器、网络芯片等各种设计图案的宝贵工艺数据。
第四道墙:良率——最致命的经济学
所有上述技术积累,最终汇聚到一个点:良率。决定代工厂经济性的最关键变量是缺陷密度,用D₀表示,即每平方厘米晶圆上的关键缺陷数量。
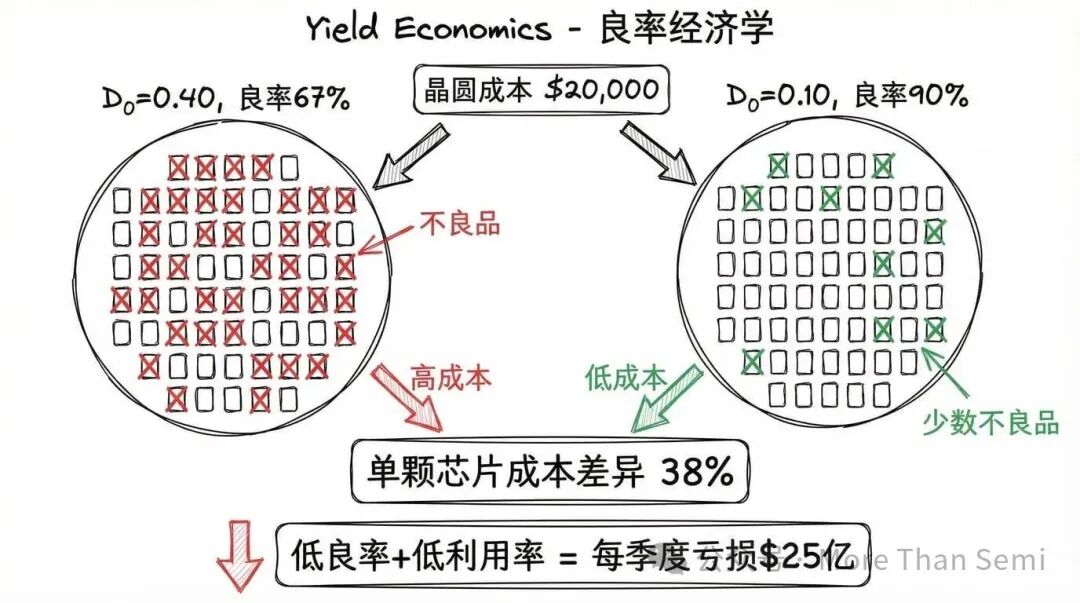
举个例子就明白了:在D₀ = 0.40、芯片面积1平方厘米的情况下,良率大约是67%。若将D₀改善到0.10,良率则会跃升至90%左右。
把这个良率差异转换成美元,问题的严重性便一目了然。一片领先的2纳米级晶圆,成本估计超过2万美元。
- 65%良率时,每片晶圆100颗芯片里,有65颗是好的。
- 90%良率时,则有90颗是好的。
单颗芯片的成本差异超过了38%。
这还没算上产能利用率。一座领先制程的晶圆厂,每年运营成本高达数十亿美元,这些固定成本不管你跑不跑晶圆都要付。当产能利用率仅为50%时,分摊到每颗芯片上的固定成本,几乎是80%利用率时的两倍。英特尔代工厂一个季度亏损25亿美元,正是低良率和低利用率同时叠加造成的结构性后果。
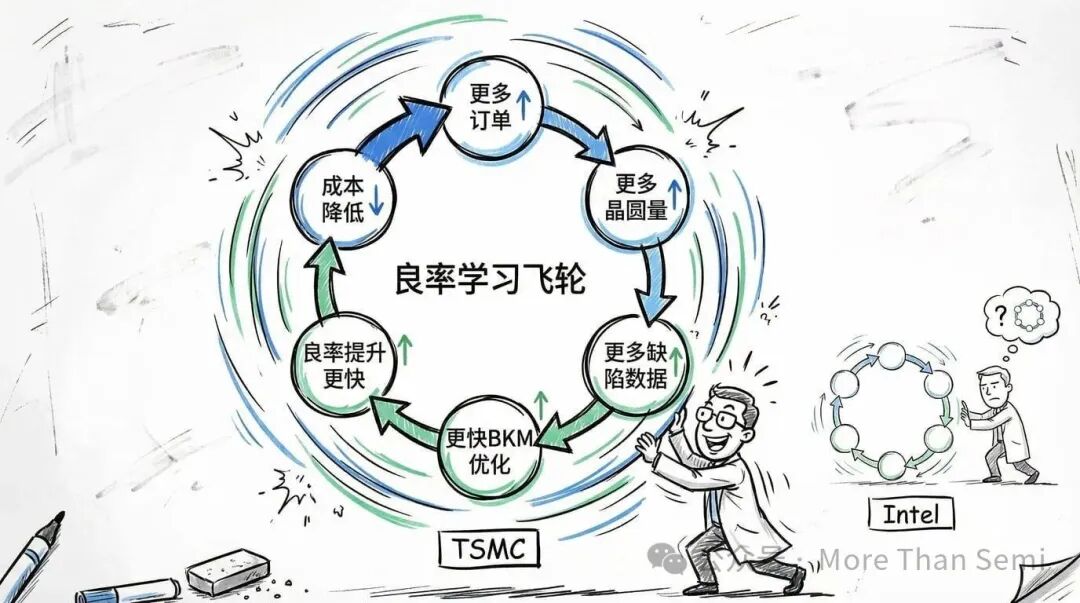
良率的改善遵循学习曲线。早期,系统性因素主导缺陷行为。随着时间推移,竞争转向如何快速降低随机缺陷密度。在那个阶段,决定性变量是:你跑了多少晶圆、有多少种不同的设计图案、以及跑得多频繁。
更多的晶圆量意味着能更快地观察到缺陷、更快地隔离根本原因、更快地更新BKM。良率在同等时间内成熟得更快。这就是为何大型代工厂能在新制程初期就迅速提升产能利用率,同时生产多样化的客户设计,从而实现学习速度的最大化。
一个外部订单有限的代工厂,学习数据少,良率爬坡慢,在单片晶圆成本和交付可靠性上存在结构性劣势。而这种成本和可靠性差距,又会让它更难赢得新客户,导致订单量进一步不足,从而再次拖慢良率学习。恶性循环就此形成。
PDK成熟度、BKM深度、良率学习速度,无一不是时间和规模的函数。一旦良性循环开始转动,先行者与后来者之间的差距便会呈指数级扩大。这就是台积电用30多年构建起来的护城河的实质。
二、Intel 18A的真实实力与局限
了解了代工壁垒的高度,我们再来看看英特尔在2纳米战场上的真实位置。
Intel 18A:技术进展 vs 商业现实
据了解,英特尔18A在2025年下半年进入了认真的量产爬坡阶段。英特尔将其定位为首个同时将RibbonFET和PowerVia带入高产量制造的制程。首款产品是Core Ultra Series 3,服务器版本Clearwater Forest也在路线图上。
良率没有官方披露,业内各种估计在60%多的低到中段范围。PDK方面,英特尔在2024年7月发布了18A PDK 1.0,流片正在进行中。但根本问题是:这些技术进展是为谁服务的?
关于18A进展的所有已知信息,基本都锚定在英特尔自己的产品上。其SEC文件反复提及风险,指出外部客户订单量仍然有限。简而言之:制程在跑,但代工业务真正需要的外部订单量、客户信任和商业规模,尚未得到证明。
面向外部客户的变体18A-P正在准备中。有迹象表明其PDK已交付给选定客户进行评估,一些观察者预计客户认证和生产讨论将在2026年左右加速。最终,英特尔作为代工厂的真正考验,不是18A自身的内部成功,而是外部客户是否真的会把大额订单交给18A-P。
Intel 18A vs TSMC N2:不对称的竞争
英特尔18A的直接竞争对手是台积电N2。两者同属2纳米级世代,但在各维度上的实力差异显著。
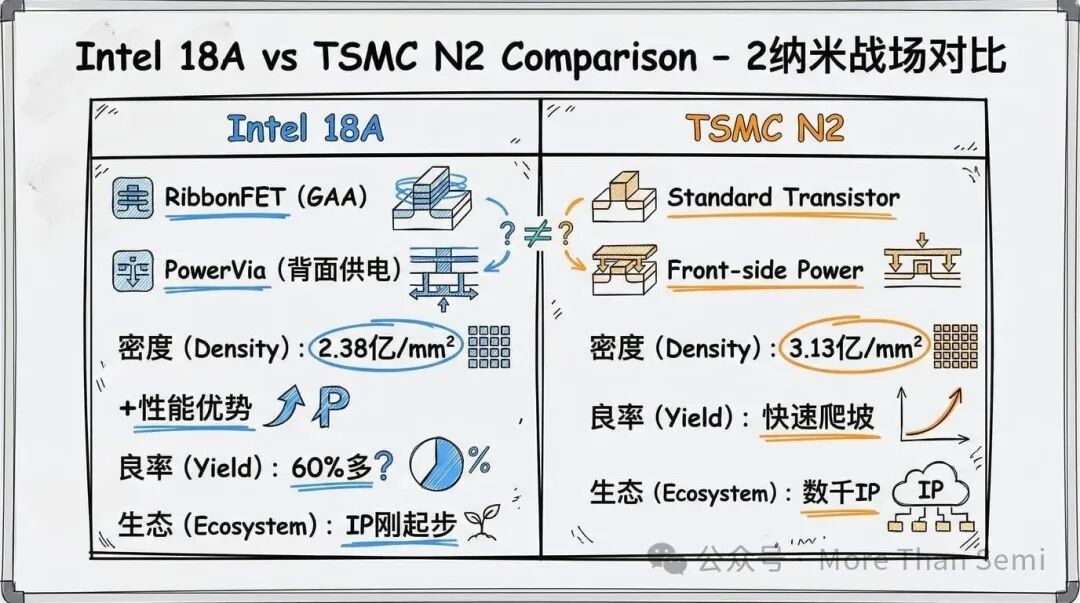
性能和功耗:英特尔做出了强有力的声明。公司展示的数据显示,在特定条件下,其等电压性能有提升,或等性能下功耗有节省,并指出PowerVia是底层关键技术。
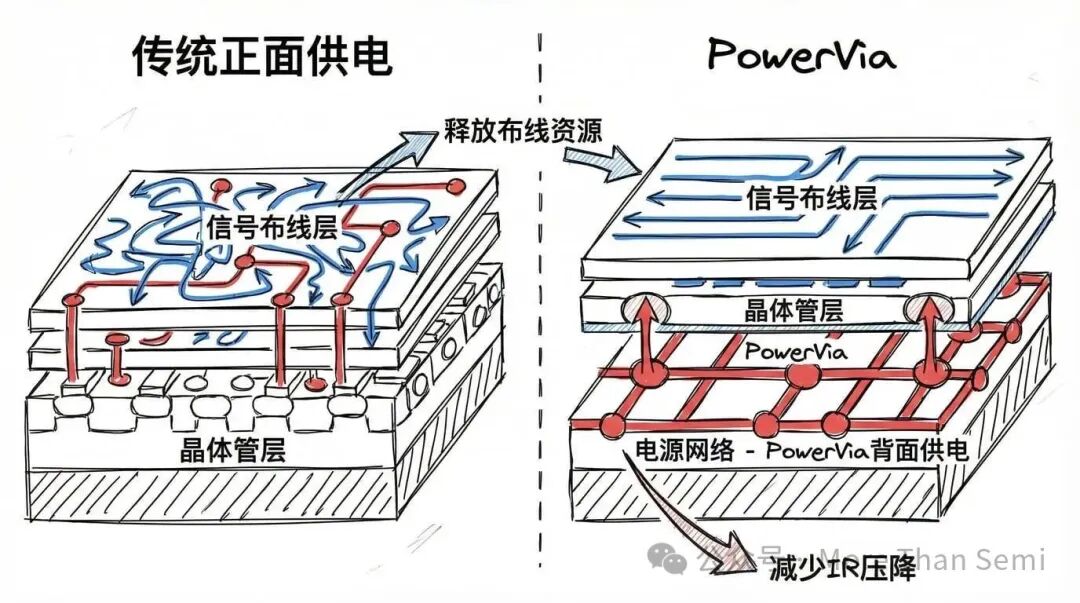
PowerVia将电源网络分离到芯片背面,释放正面布线资源用于信号传输,能减少IR压降。这个逻辑在纸面上很有说服力,承诺缓解设计瓶颈。但制程间的性能比较高度依赖产品配置和设计方法论,对于外部客户而言,硅片可重复性和生产数据最终才是最重要的。
密度:台积电有明显领先。TSMC N2达到每平方毫米3.13亿个晶体管,而英特尔18A是2.38亿。更高的密度意味着同样功能的芯片面积更小,也就是单颗成本更低。PowerVia确实回收了一些正面面积,所以“有效密度”差距可能比原始数字小,但背面供电所需的额外工艺步骤,可能会推高英特尔的晶圆制造成本。
良率差距:预计也很显著。确切数字未知,但英特尔未公开披露18A良率,而台积电在快速良率爬坡和量产驱动学习方面拥有长期的行业声誉。更根本的是,真正的比较不是当前的良率百分比,而是成熟速度。正如前面良率经济学所讨论的,爬坡速度的差异直接转化为单颗芯片成本和交付可靠性的差距。
生态系统比较:这几乎无法在平等条件下进行。台积电的OIP拥有数千个经过硅验证的IP条目。英特尔18A的IP生态系统才刚刚起步。更根本的是,英特尔的PowerVia与现有的正面供电IP不兼容。适应背面供电制程需要对电源布线架构进行根本性重设计,这不仅仅是移植,而近乎是完整的IP重新开发。
台积电则在执行双轨策略:N2上采用正面供电,计划在2026-2027年的A16上引入背面供电,给客户选择。英特尔则是背面供电的单轨策略。综合来看,英特尔的定位很清楚:在性能至关重要的高端HPC和AI市场,存在有竞争力的案例。但对于由成本和密度驱动的移动和IoT市场,目前在结构上难以触及。其可触及的市场本质上是狭窄的。
Samsung的回归:教训与威胁
英特尔并非2纳米战场上唯一的挑战者。三星,另一家运营代工业务的IDM,正在重新加入战斗。
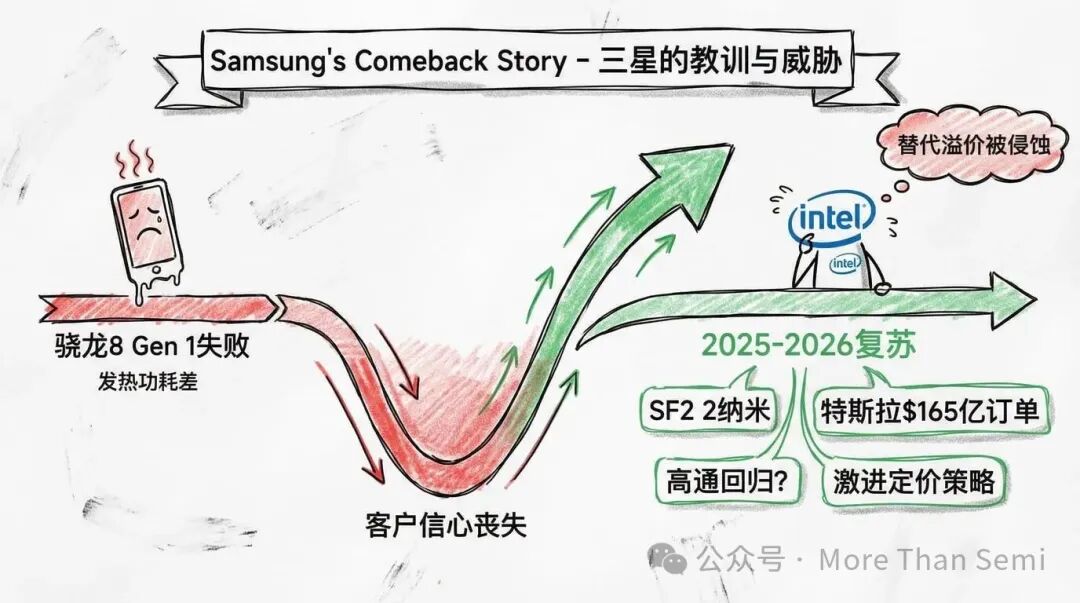
三星走过英特尔现在试图走的路,并为此付出了惨痛代价。当高通骁龙8 Gen 1在三星的4纳米制程上生产时,因发热和功耗问题而臭名昭著,导致高通的旗舰订单转向了台积电。
但从2025年下半年开始,气氛在转变。三星将SF2路线图重新置于叙事中心,并通过实际流片和产品化计划发出“这次不一样”的信号。在客户管道方面,一个意义重大的事件是据传与特斯拉签订的165亿美元长期供应协议,这为三星代工厂提供了持续订单和加速学习的基石。
高通也显示出回归的迹象。一些专用芯片公司和AI初创公司也被报道正在评估三星的制程。三星的激进定价一直是其市场策略的一部分,公司似乎决心重新确立自己作为台积电可信替代方案的地位。
并排来看,三个玩家的角色变得清晰:台积电仍然是基准;英特尔以PowerVia作为差异化因素,瞄准特定的高性能细分市场;三星则试图通过价格和供应可选性竞争,重新进入客户的考虑清单。对英特尔而言,三星既是教训也是威胁。教训是:技术领先不会自动转化为市场领先。威胁是:随着三星复苏,英特尔目前享有的“唯一替代选择”溢价正在被侵蚀。
三、Intel的窗口期与生死抉择
现在,我们来到最关键的问题:英特尔还有多少时间?它必须做什么才能活下来?
结构性机会:多源化策略
无晶圆厂客户的“多源化”策略正在为英特尔创造一个结构性机会。苹果、英伟达、AMD、高通都想降低对台积电单一来源依赖的风险。GlobalFoundries已退出领先制程竞赛。日本的Rapidus瞄准2纳米但无量产记录,量产预计不早于2027年。
通过排除法,英特尔看起来像是唯一真正的替代方案。但这个窗口正在缩小。
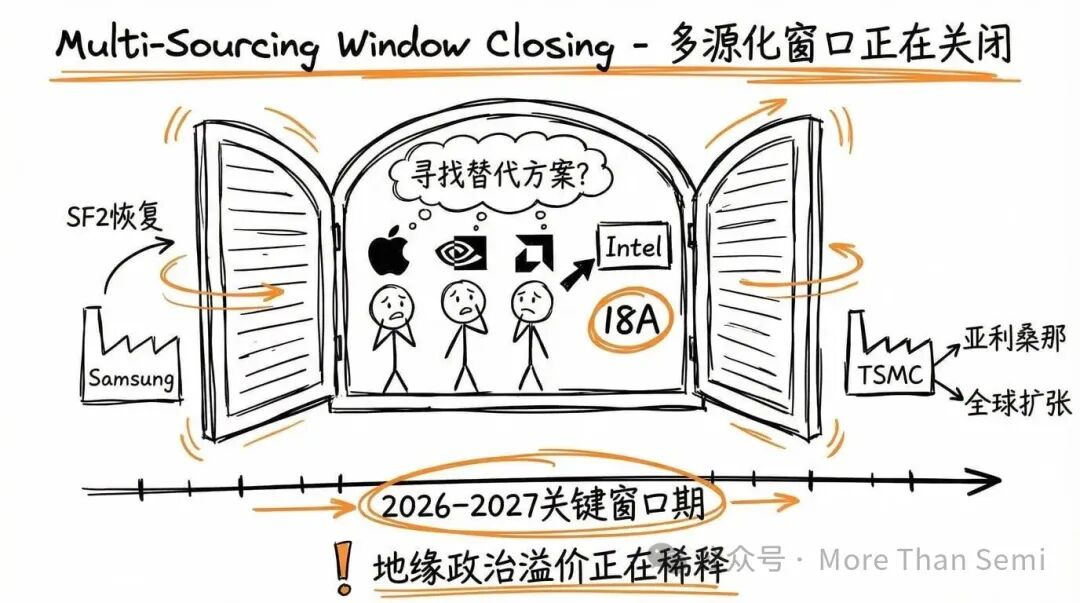
三星正在推高SF2良率,同时准备SF2P,并开始再次被视为真正的选项。三星的定价竞争力及其在美国德州泰勒的生产能力,直接削弱了英特尔的差异化因素。
台积电也没有停滞不前。其在亚利桑那州的N4厂已在运营,日本熊本的JASM在运行,德国德累斯顿的晶圆厂在建设中。英特尔从美国本土生产中获得的地缘政治溢价,每过一个季度都在被稀释。这使得2026年和2027年成为英特尔的时间问题。如果英特尔不能在这个窗口内证明外部客户所需要的生产可重复性和生态系统深度,那些客户要么留在经验证的台积电,要么转向复苏的三星。
苹果:可能改变一切的名字
自2025年底以来,行业最热门的故事一直是苹果成为英特尔代工厂客户的可能性。
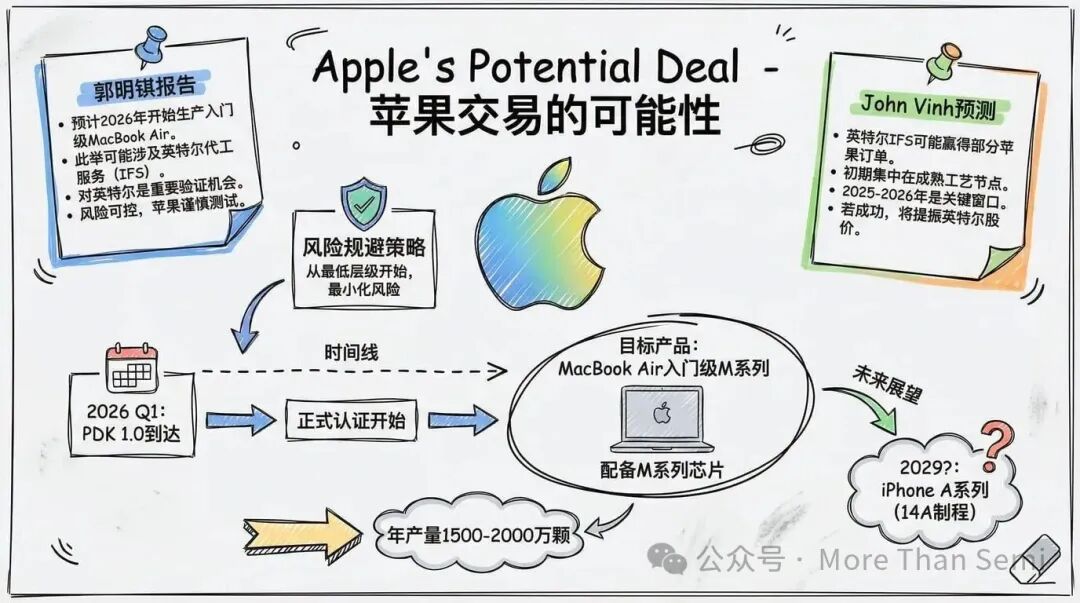
根据分析师郭明錤的说法,苹果已收到英特尔的18A-P PDK 0.9.1GA,并正在进行内部仿真,据报道结果符合预期。当PDK 1.0在2026年第一季度发布时,预计正式认证将认真开始。目标产品是MacBook Air和iPad Pro的入门级M系列处理器,估计年产量1500万到2000万颗。
从最低层级芯片开始,而不是Pro或Max产品线,这是务实的做法。从苹果的角度看,这最小化了风险,同时验证英特尔的生产能力,如果结果令人满意,还有逐步扩大订单的空间。KeyBanc Capital Markets分析师John Vinh走得更远,表示苹果正在讨论在2029年左右,于英特尔的14A制程上生产入门级iPhone的A系列处理器。
苹果考虑英特尔代工的动机很直接。在2026年第一季度财报电话会议上,Tim Cook直接承认了供应约束,并表示难以预测何时恢复供需平衡。100%依赖台积电削弱了苹果的谈判筹码,并使其暴露于台海的地缘政治风险中。交易尚未确认,2026年上半年将是关键的决策拐点。
英伟达:谨慎的方法,但有意义的信号
英伟达与英特尔的关系更复杂。
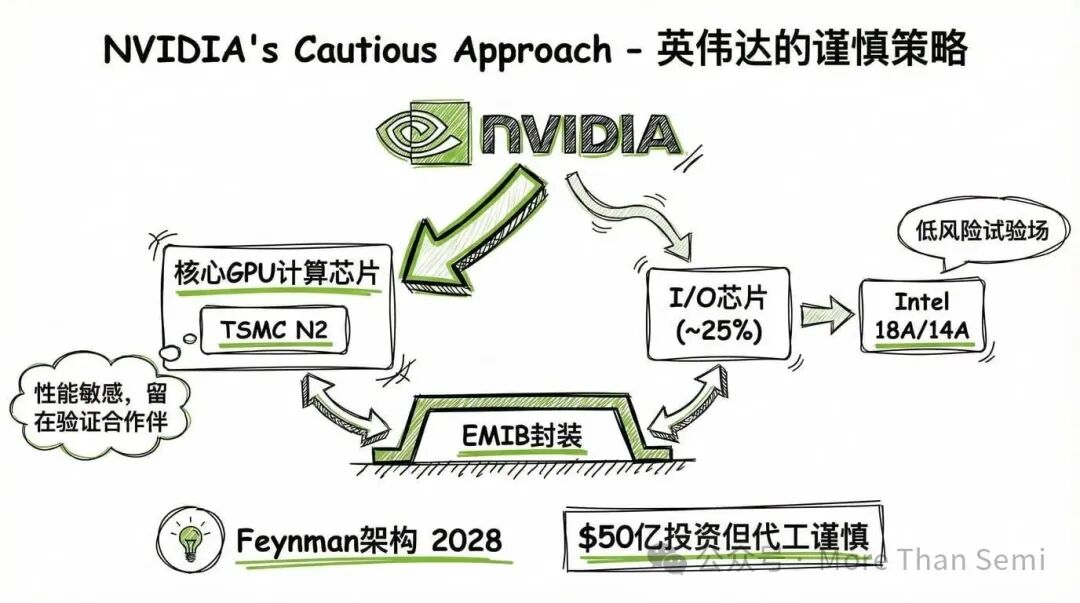
2025年9月,英伟达宣布向英特尔投资50亿美元,两家公司同意合作开发集成x86 CPU和英伟达GPU的SoC。在代工方面,信号是混杂的。路透社曾报道英伟达测试了英特尔的18A制程但“停止推进”,解释是良率和性能低于预期。英伟达已为其下一代2纳米级设计确保了台积电N2产能,因此切换到英特尔18A的动机有限。
但2026年1月,DigiTimes反转了叙事。报道指出英伟达正在探索在英特尔的18A或14A制程上,生产其下一代GPU架构的I/O芯片。策略是将核心GPU计算芯片留在台积电,同时通过EMIB封装将大约25%的I/O芯片工作分配给英特尔。这让英伟达能将最性能敏感的部分留在已验证的合作伙伴那里,同时用I/O芯片作为英特尔的低风险试验场。这是教科书式的代工多元化策略。
微软和AWS:已经在行动的锚定客户
除了苹果和英伟达,其他客户已经在行动。微软计划在英特尔18A上生产其用于Azure数据中心的AI加速器Maia 2。AWS正在与英特尔合作开发定制Xeon处理器和AI互连芯片。这些超大规模云厂商选择英特尔,与其说是看中其绝对的技术优势,不如说是出于战略多元化的考量。随着AI基础设施需求爆炸式增长,台积电先进制程产能长期受限,在美国本土确保替代生产能力是理性的供应链韧性决策。
Intel必须跨越的五道关卡
现在,让我们梳理一下英特尔必须跨越的五道关卡。
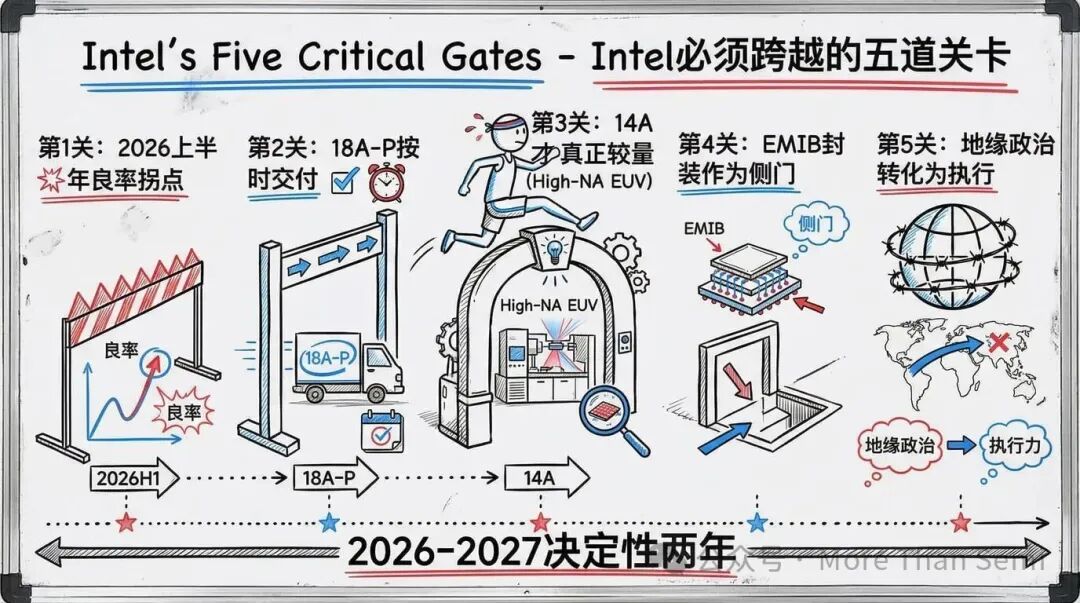
第一关:2026年上半年的良率拐点。在任何事情之前,18A制程良率必须达到足以接受外部客户的水平。Panther Lake和Clearwater Forest的量产需要作为18A成熟度的活证明。没有外部客户会为一个连英特尔自己芯片都无法可靠生产的制程签约。
第二关:18A-P必须按时交付。如果18A是为英特尔自己的CPU优化的,那么18A-P才是真正的代工制程。其PDK 1.0和生产爬坡的时间表必须与外部客户(包括苹果)的时间表对齐。在代工业,时间表滑移等于客户流失。
第三关:真正的较量是14A。英特尔18A对大多数外部代工客户而言并非理想制程。决定性战役将转向14A,预计在2027年左右,这将是High-NA EUV光刻的首次商业应用。如果英特尔能在那个节点上建立相对于台积电的真正技术优势,可能是游戏改变者。但英特尔已宣布,不会在没有客户承诺的情况下投资。“建好了他们就会来”的模式不再有效。
第四关:EMIB封装作为侧门。有趣的是,英特尔吸引代工客户的最快路径可能根本不是晶圆加工,而是先进封装。英特尔的EMIB和Foveros技术是业内领先的,而台积电的CoWoS封装在AI需求激增下一直供应受限。英伟达的潜在交易本身就以EMIB为中心。封装收入可能先于晶圆加工收入到来,它可能是建立与代工客户关系的敲门砖。
第五关:把地缘政治顺风转化为执行力。台海风险、近80亿美元的CHIPS法案直接拨款、以及美国国防部对国内生产的需求——所有这些在结构上都对英特尔有利。但随着台积电亚利桑那州工厂产能爬坡和三星泰勒工厂上线,这个溢价正在随时间缩小。政府补贴可以弥补早期的成本差距,但英特尔必须独立建立其技术竞争力。窗口期就是台积电亚利桑那州和三星泰勒工厂达到满产能之前的这段时间。
牛市情景 vs 熊市情景
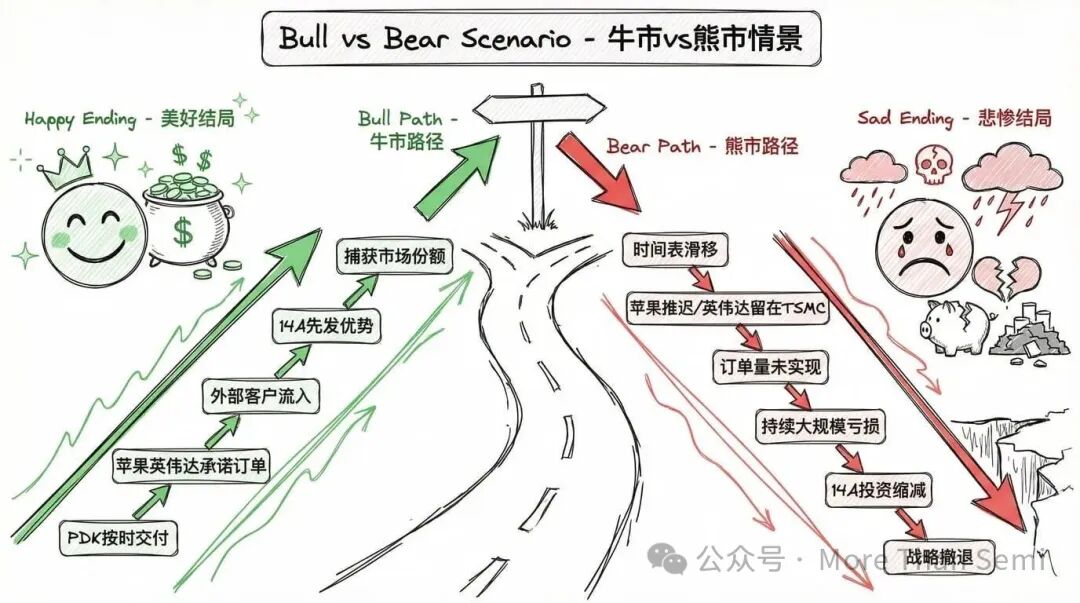
牛市情景:飞轮开始转动。PDK时间表得以保持;内部产品生产证明了制程成熟度;苹果和英伟达承诺了有意义的订单;外部客户流入加速了良率学习;14A按时到达,捕获了High-NA EUV的先发优势;代工运营亏损开始收窄;到这个十年结束时,英特尔在全球代工市场捕获了有意义的份额。
熊市情景:窗口关闭。制程时间表出现滑移;生产成熟度令人失望;苹果推迟决定或将参与限制在小型试点;英伟达最终留在台积电;台积电亚利桑那州工厂产能爬坡,侵蚀了国内生产溢价;外部客户订单未能实现;大规模亏损持续;对14A的投资被缩减;从代工业务战略撤退的选项重新摆上桌面。
写在最后
英特尔代工厂的较量,已经越过了“潜力”的阶段,进入了“证明”的阶段。如果18A通过内部产品展示了技术的方向,那么18A-P就是外部客户必须决定是否付出信任和进行流片的第一道门。如果这道门被顺利打开,订单开始流动,学习加速,生态系统跟上,14A或许能成为扭转战局的关键。如果错过了这个时机,客户留在经验证的台积电,剩余的替代市场与复苏的三星分割,英特尔的代工战略将再次面临收缩的巨大压力。
哪一个场景会最终展开,根本上取决于英特尔自身的执行力。2026年和2027年,将是决定性的两年。这不仅关乎英特尔的生死之战,也是全球半导体产业格局重塑的关键时刻。让我们拭目以待。
参考原文链接:https://x.com/damnang2/status/2024345308063473910
讨论半导体制造的挑战与未来,欢迎访问云栈社区。
 发表于 2026-2-20 20:31:19
|
查看: 215|
回复: 0
发表于 2026-2-20 20:31:19
|
查看: 215|
回复: 0
