相较于入门级的 nano-vllm,mini-sglang 不仅实现了大模型推理的核心功能,更在架构设计上体现出工业级推理引擎的关键特征 —— 多进程架构支撑、功能模块高内聚拆分、关键节点可扩展设计。基于这一架构叠加新功能时,效率和稳定性优势将非常显著。因此,mini-sglang 不仅是大模型推理加速的入门学习材料,也是工业化推理引擎架构学习的优秀案例。
本文将先介绍 mini-sglang 的整体架构,再对其特有的核心技术要点进行深入解析。
系统架构全景
进程视角架构
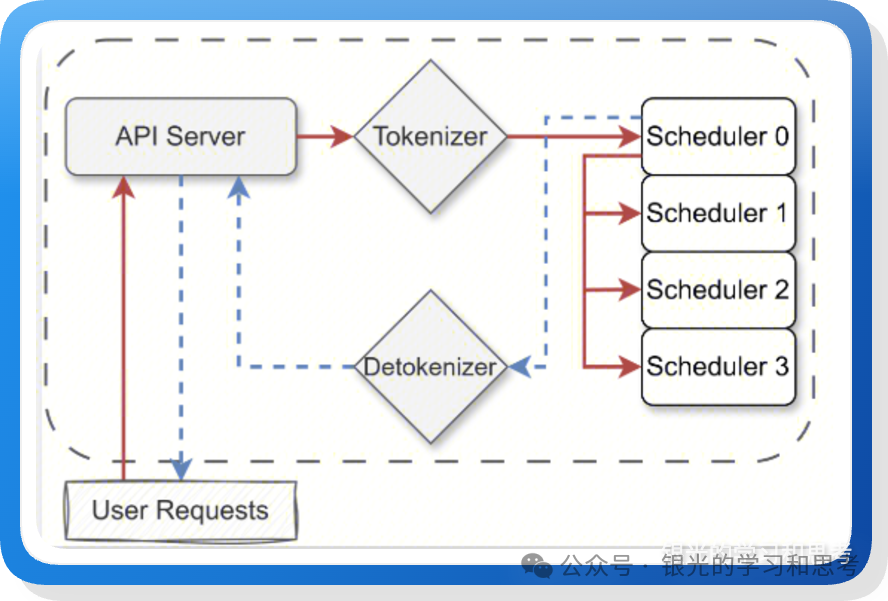
图 1: mini-sglang 多进程架构 (图来源:https://lmsys.org/blog/2025-12-17-minisgl/)
mini-sglang 包括 4 类进程:
- 入口进程:负责对外接口的 HTTP 服务、交互式 Shell。
- Tokenizer 进程:负责对 prompt 做分词,获取 token ID。
- Detokenizer 进程:负责将 token ID 转成文本。
- Scheduler 进程:即 TP worker 进程,负责核心的推理调度与计算。
类层面架构
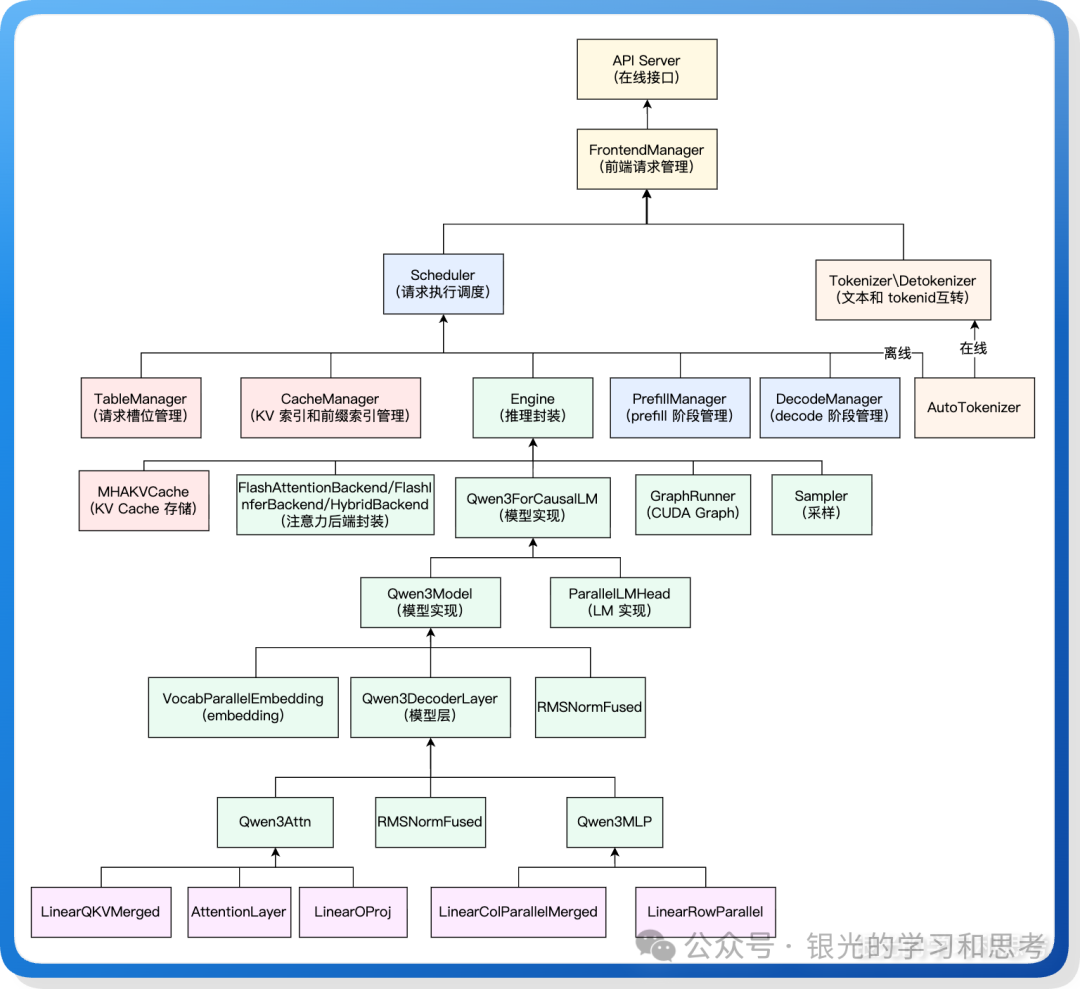
图 2: mini-sglang 核心类架构
上图中六种颜色代表系统的六个组成部分:
- 浅黄色:HTTP 入口。
- 浅蓝色:请求调度。
- 浅橙色:文本和 token id 互转。
- 浅红色:KV cache 管理。
- 浅绿色:模型推理。
- 浅紫色:权重加载和矩阵计算的封装。
可扩展设计亮点
相较于 nano-vLLM,mini-sglang 在类层面架构更为复杂,同时在一些关键节点上做了精心的可扩展设计:
- CacheManager(KV Cache 管理模块):以
BaseCacheManager 为基类,提供 RadixCacheManager 和空实现的 NaiveCacheManager,便于性能对比。
- MHAKVCache(KV Cache 存储模块):以
BaseKVCache 为基类,对存储层做了抽象,便于后续扩展。
- Attention Backend(注意力后端模块):以
BaseAttnBackend 为基类,支持 FlashInferBackend、FlashAttentionBackend 以及 HybridBackend,可根据场景灵活选择。
- 模型实现模块:以
BaseLLMModel 为基类,Qwen3ForCausalLM 作为具体实现,便于扩展新模型。
除了关键节点的可扩展设计,在代码封装复用上也有较多考量,例如提炼出注意力子层 RopeAttn 类,可以在多个模型中复用。
源码结构
目录结构清晰,职责明确:
minisgl/
├── attention # 注意力
├── benchmark # 性能评测
├── distributed # 通信
├── engine # 推理引擎入口
├── kernel # 内核(CU/CPP)
├── kvcache # kvcache
├── layers # 模型推理的层
├── llm # 离线推理接口
├── message # 进程间通信的消息
├── models # 模型实现
├── scheduler # 请求调度
├── server # HTTP 服务
├── tokenizer # 文本和 token id 转换
└── utils # 工具函数和类
结合上文分析,mini-sglang 不仅实现了基础推理功能,更在架构设计、代码内聚、接口抽象上做了工业级考量,体现了工业化推理引擎的特征。
下面的章节将对 mini-sglang 特有的重点功能展开介绍。
Shell 交互模式
除了常见的 HTTP API,mini-sglang 还提供了交互式 Shell 模式,方便本地测试与调试。
(1) 启动方式
python -m minisgl --model /data/modelscope/Qwen3-0.6B --shell
图 3: Shell 模式运行示例
(2) 实现原理
Shell 模式通过 prompt_toolkit 包实现,下面是一份简化的示例代码:
from prompt_toolkit import PromptSession
from prompt_toolkit.history import InMemoryHistory
from prompt_toolkit.auto_suggest import AutoSuggestFromHistory
async def main():
session = PromptSession(history=InMemoryHistory())
print("--- Welcome to demo Interactive Shell ---")
while True:
try:
text = await session.prompt_async(
'sglang >>> ',
auto_suggest=AutoSuggestFromHistory()
)
if text.lower() in ("exit", "quit"):
break
print(f"Model Response: (Simulated) Hello for '{text}'")
except KeyboardInterrupt:
continue # Ctrl+C 不退出,模拟真实 Shell
except EOFError:
break # Ctrl+D 退出
if __name__ == "__main__":
import asyncio
asyncio.run(main())
图 4: 简易 Shell 实现示例
分块预填充 (Chunked Prefill)
概念与价值
Chunked Prefill 是针对长序列输入场景的优化策略,核心目标是解决长序列 prefill 阶段的显存溢出(OOM)和请求调度阻塞问题。
- 解决调度阻塞,提升响应及时性:常规 prefill 需一次性处理整个长序列,在此期间新请求必须等待。分块后,调度器可以在处理块间隙插入新请求,提升系统并发响应能力。
- 降低显存峰值,避免 OOM:这里降低的主要是中间激活值的显存占用。注意力计算中的 Q×Kᵀ 操作产生的中间矩阵大小与序列长度 n 的平方成正比。分块后,n 减小,中间矩阵急剧缩小,且每块计算完后其激活值可立即释放,从而显著降低显存峰值。
核心思路
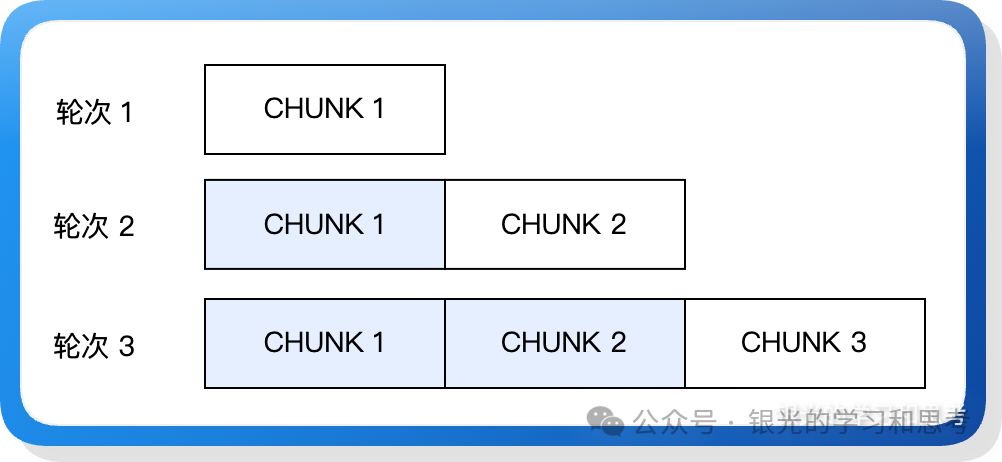
图 5: 分块预填充示意图
如上图所示,一个包含 3 个 chunk 的请求,分三次迭代执行完 prefill,每次处理一个 chunk,后续 chunk 需要复用前序 chunk 的 KV Cache。
执行流程
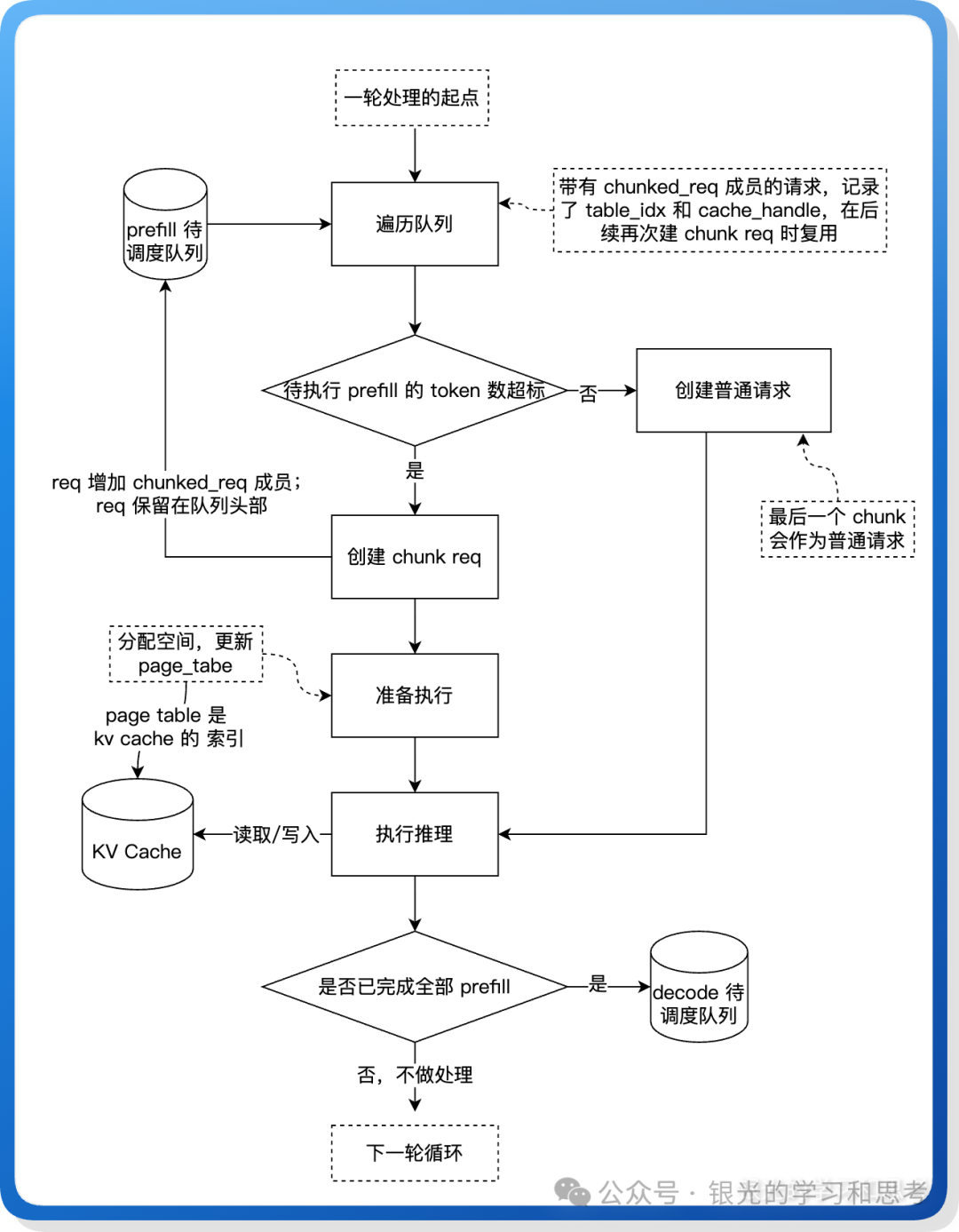
图 6: 分块预填充调度流程图
Scheduler 调度请求时,会判断请求的 token 数是否超过单次处理上限。如果超过,则创建 ChunkedReq 分块处理。其核心机制包括:
- KV Cache 复用:所有 chunk 共享同一个
table_idx,访问 page_table(KV Cache 索引)的同一行。每个 chunk 都将新生成的 KV Cache 物理页索引追加到 page_table 中,实现累积写入和复用。
- Meta 信息复用:非首 chunk 会检测
pending_req.chunked_req 是否存在,直接复用前序 chunk 的 table_idx 和 cache_handle。
- 完成后才进入 Decode:
ChunkedReq 的 can_decode() 返回 False。只有当最后一个 chunk(剩余 token 可一次处理完)被创建为普通 Req 对象时,请求才能进入 decode 阶段。
重叠调度 (Overlap Scheduling)
概念与核心价值
定义:Overlap Scheduling 是一种将 CPU 调度开销与 GPU 计算重叠执行的优化技术,通过双 CUDA Stream 实现 CPU 和 GPU 并行工作,有效隐藏 CPU 延迟。
核心价值:让昂贵的瓶颈硬件(GPU)保持持续的满负荷计算状态,避免其因等待 CPU 指令而“空转”,从而提高 GPU 利用率和系统吞吐量。
技术本质:这类似于经典的“生产者-消费者”模型。CPU 调度线程是生产者,准备任务元数据;GPU 计算流是消费者,执行计算任务。两者通过事件和流同步机制进行协作。
核心技术点与实现
异步执行的核心是创建异步环境和置位同步信号。
1. 创建推理流
# Engine 对象的 __init__:
self.stream = torch.cuda.Stream()
...
# Scheduler 对象的 __init__:
self.engine_stream_ctx = torch.cuda.stream(self.engine.stream)
2. Stream 同步(等待数据准备)
with self.engine_stream_ctx: # 切换到推理流
self.engine.stream.wait_stream(self.stream) # 等待调度流完成元数据准备
ongoing_data = (forward_input, self._forward(forward_input))
3. Event 同步(等待计算完成)
def _process_last_data(self, last_data, ongoing_data):
if last_data is None:
return
batch, (_, next_tokens_cpu, copy_done) = last_data[0].batch, last_data[1]
copy_done.synchronize() # 等待 GPU→CPU 数据拷贝完成
# 处理采样结果...
推理时序图
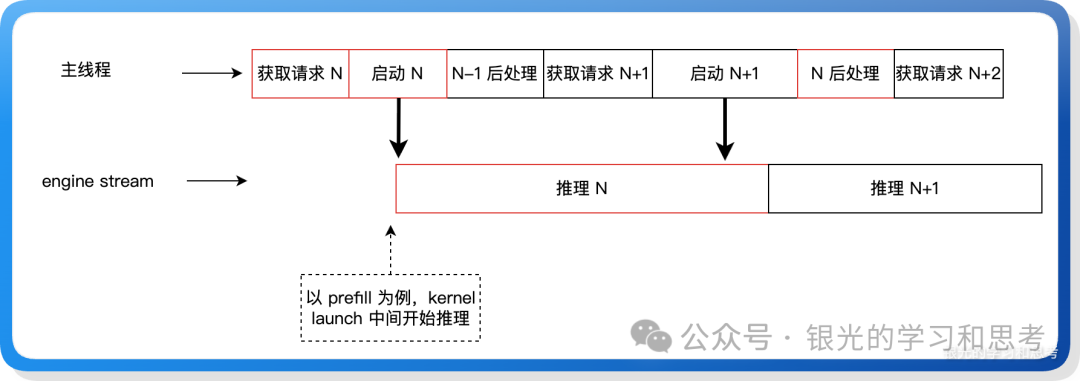
图 7: 重叠调度时序图
原型代码与效果
基于 mini-sglang 的思路,我们可以实现一个简化版的原型来对比效果:
"""Overlap Scheduling 原型"""
import torch
import time
import queue
# 模拟各 CPU 阶段耗时(秒)
PRE_PROCESS_TIME = 0.03 # 前处理(CPU: 接收请求、准备 Metadata, Tokenization)
POST_PROCESS_TIME = 0.02 # 后处理(CPU: Sample, De-tokenization)
TOTAL_REQUESTS = 10 # 测试总请求数
class OverlapEngine:
def __init__(self):
self.engine_stream = torch.cuda.Stream()
self.request_queue = queue.Queue()
self.results_queue = queue.Queue()
def _pre_process(self, req_id):
"""模拟前处理"""
time.sleep(PRE_PROCESS_TIME)
def _post_process_normal(self, req_id):
"""模拟 normal 模式的后处理"""
time.sleep(POST_PROCESS_TIME)
def _post_process_overlap(self, last_data):
"""模拟 overlap 模式的后处理"""
if last_data is not None:
_, sync_event, _ = last_data
sync_event.synchronize()
time.sleep(POST_PROCESS_TIME)
def _mock_forward(self):
"""模拟 GPU 推理"""
dummy_tensor = torch.randn(1000, 1000, device="cuda")
for _ in range(1000):
dummy_tensor = torch.matmul(dummy_tensor, dummy_tensor)
return dummy_tensor
def _gpu_inference_async(self, req_id):
"""模拟异步 GPU 推理"""
with torch.cuda.stream(self.engine_stream):
result = self._mock_forward()
sync_event = torch.cuda.Event()
sync_event.record(self.engine_stream)
return req_id, sync_event, result
def _gpu_inference_blocking(self):
"""模拟同步 GPU 推理"""
result = self._mock_forward()
torch.cuda.synchronize()
return result
def run_normal(self):
"""模拟运行 normal 模式"""
start_time = time.time()
for i in range(TOTAL_REQUESTS):
self._pre_process(i)
self._gpu_inference_blocking()
self._post_process_normal(i)
return time.time() - start_time
def run_overlap(self):
"""模拟运行 overlap 模式"""
start_time = time.time()
last_data = None
for i in range(TOTAL_REQUESTS + 1):
ongoing_data = None
if i < TOTAL_REQUESTS:
self._pre_process(i)
ongoing_data = self._gpu_inference_async(i)
self._post_process_overlap(last_data)
last_data = ongoing_data
return time.time() - start_time
# 预热
dummy_tensor = torch.randn(1000, 1000, device="cuda")
torch.matmul(dummy_tensor, dummy_tensor)
engine = OverlapEngine()
print(f"开始测试 {TOTAL_REQUESTS} 个请求...")
duration_normal = engine.run_normal()
throughput_normal = TOTAL_REQUESTS / duration_normal
duration_overlap = engine.run_overlap()
throughput_overlap = TOTAL_REQUESTS / duration_overlap
print("-" * 30)
print(f"Normal 模式耗时: {duration_normal:.4f}s | 吞吐: {throughput_normal:.2f} req/s")
print(
f"Overlap 模式耗时: {duration_overlap:.4f}s | 吞吐: {throughput_overlap:.2f} req/s"
)
print(f"提升效率: {((throughput_overlap/throughput_normal)-1)*100:.2f}%")
运行该原型代码,可以看到明显的吞吐提升:
开始测试 10 个请求...
------------------------------
Normal 模式耗时: 1.2408s | 吞吐: 8.06 req/s
Overlap 模式耗时: 0.8476s | 吞吐: 11.80 req/s
提升效率: 46.39%
张量并行 (Tensor Parallelism) 与通信
mini-sglang 的 TP 实现与 nano-vllm 思路类似,但通信机制不同:nano-vllm 采用共享内存,而 mini-sglang 使用 CPU 通道的 PyTorch Dist 和 ZMQ 混合通信。
通信架构
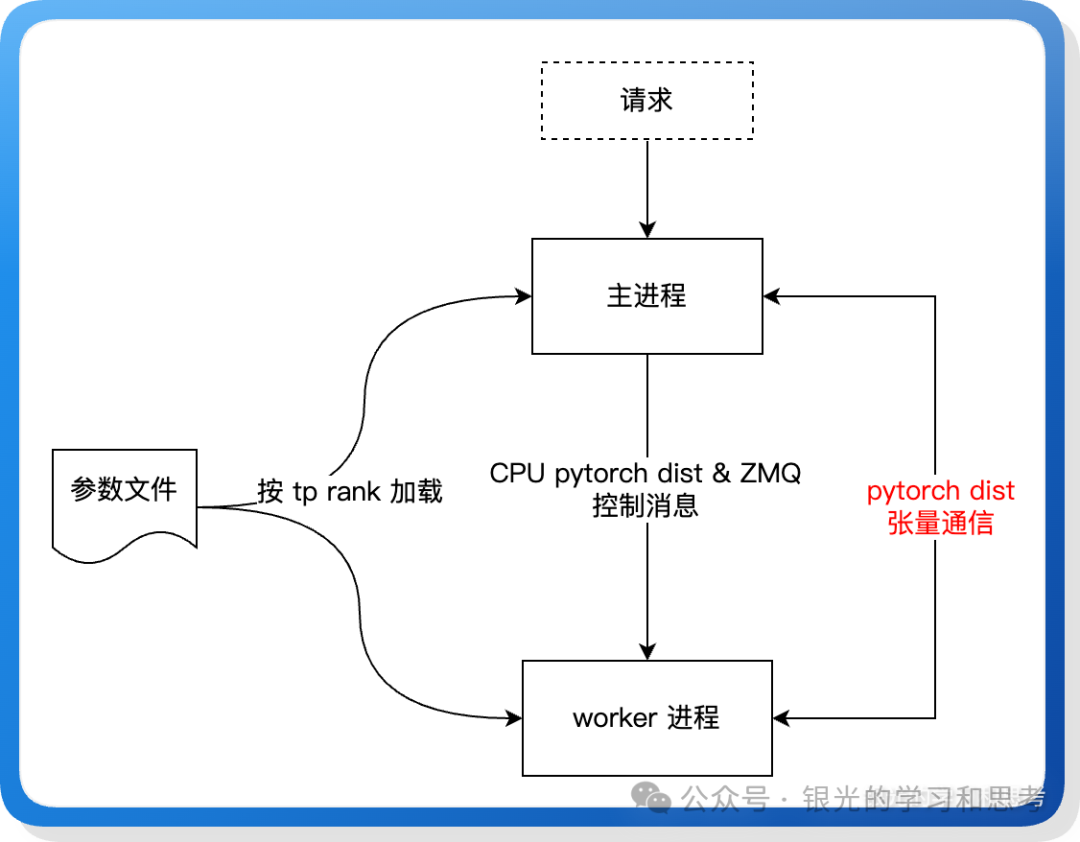
图 8: TP 通信架构示意图
通信方式对比:
| 特性 |
mini-sglang |
nano-vllm |
SGLang |
| 请求元数据同步 |
PyTorch Dist (个数) + ZMQ (详情) |
共享内存 (Shared Memory) |
PyTorch Dist (CPU Group) |
| 通信开销 |
中等(涉及序列化与 Socket 交互) |
极低(零拷贝,直接读内存) |
较高(依赖 NCCL/Gloo CPU 进程间通信) |
mini-sglang 使用 PyTorch Dist (gloo后端) 在 CPU 通道上广播请求个数,然后使用 ZMQ (PUB/SUB) 广播请求的详情(序列化后的对象)。这种设计分离了控制信息和数据,提供了灵活性。
注意力后端的多态封装
概念与设计
mini-sglang 针对注意力后端构建了标准化的多态封装层,对不同后端(如 FlashAttention, FlashInfer)的接口进行抽象与统一,实现了调用层与实现层的解耦。当前已支持 HybridBackend,允许在 prefill 和 decode 阶段使用不同的后端,以充分发挥各自性能优势(例如在 Hopper 架构上,FA3 负责 Prefill,FlashInfer 负责 Decode)。
关键技术点
- 抽象接口:定义
BaseAttnBackend 基类,所有后端(包括混合后端)继承于此。
- 工厂注册模式:基于装饰器和泛型实现工厂容器,便于灵活注册和获取不同的后端实例。
多态类图
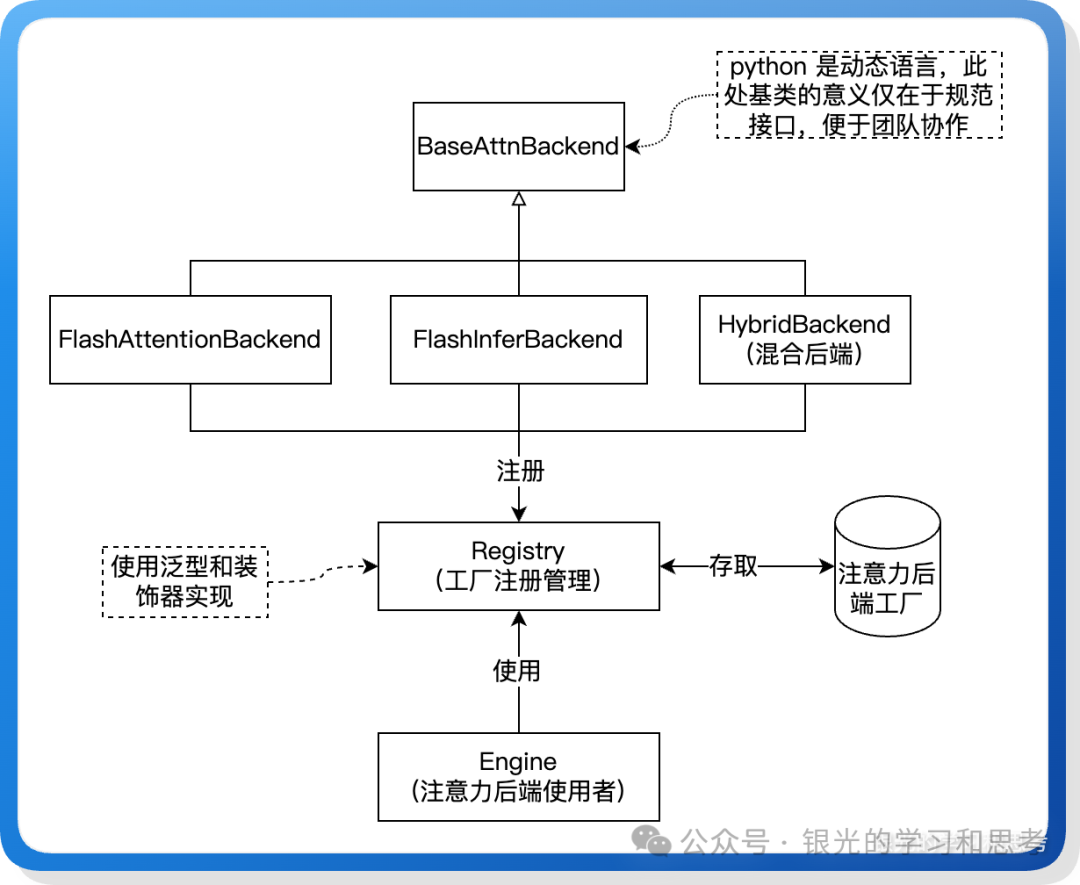
图 9: 注意力后端多态类图
Python 作为动态语言,其“鸭子类型”特性使得基类的主要价值在于描述统一接口、规范团队协作和提升代码可读性,而非实现多态的必要条件。
KV Cache 前缀索引与空间管理
核心管理类
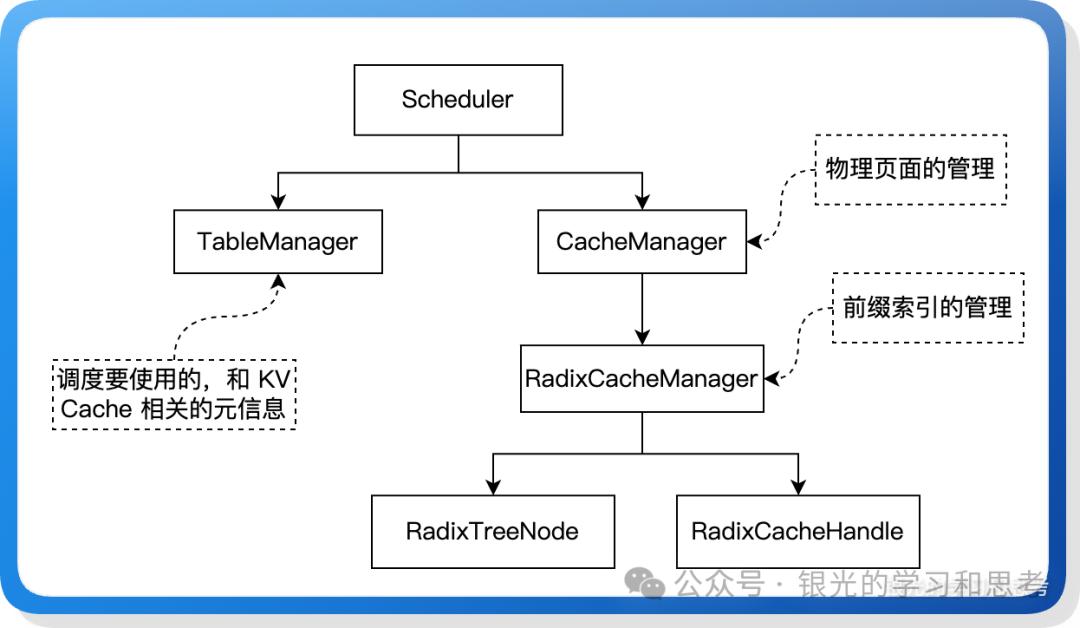
图 10: KV Cache 管理核心类图
mini-sglang 采用 Radix Tree (基数树) 实现前缀 KV Cache 管理,核心类包括:
- TableManager:记录调度所需的 KV Cache 元数据。
_free_slots: 当前可用的请求槽位。page_table: KV Cache 的物理页索引,二维数组,一行代表一个请求。token_pool: 请求的 token ID 序列,二维数组。
- CacheManager:KV Cache 管理的入口,包含空闲物理页列表和前
RadixCacheManager。
- RadixCacheManager:基于 Radix Tree 实现前缀索引的具体管理。
多态设计
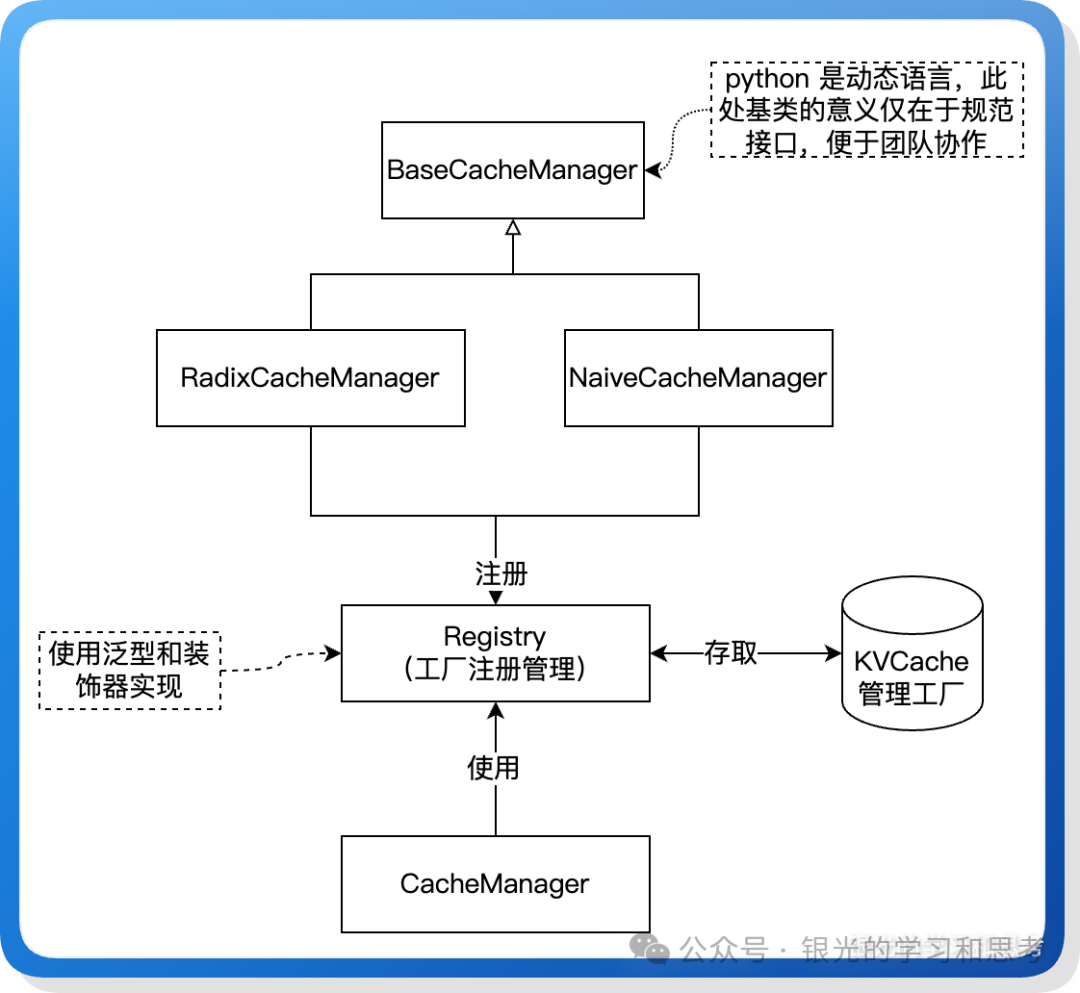
图 11: KV Cache 管理器工厂模式类图
与注意力后端类似,KV Cache 管理也采用了工厂模式实现多态,提升了代码的内聚性和可扩展性。
核心技术机制
- KV Cache 前缀复用:通过 Radix Tree 查找与新请求 token 序列匹配的最长前缀路径,复用其 KV Cache,避免重复计算。
- 前缀索引写入:请求完成后,将其完整的 token 序列及 KV Cache 写入 Radix Tree,构建全局共享前缀索引,供后续请求复用。
- 空间管理与按需驱逐:
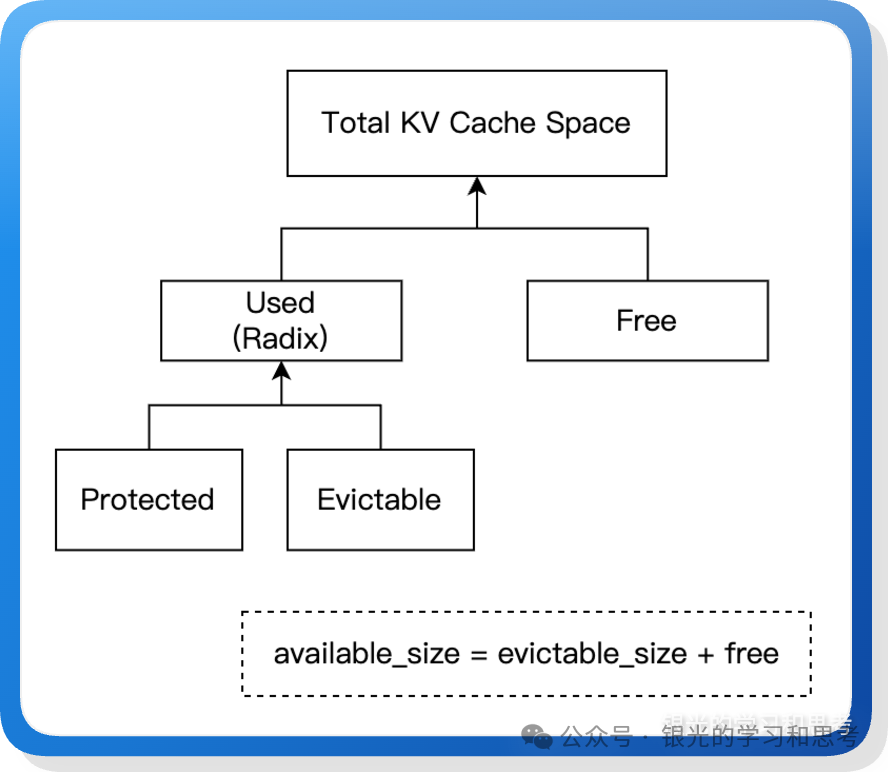
图 12: KV Cache 空间划分
- Protected:正在被请求使用,不可驱逐。
- Evictable:已存入 Radix Tree 但未被使用,可驱逐。
- Free:未分配空间。
- 采用按需驱逐 (Lazy Eviction) 策略:当空间不足时,优先驱逐
ref_count == 0 的最早创建的叶子节点。
- 物理空间预留(防死锁):mini-sglang 在请求进入 Decode 前,强制预留其后续生成所需的最大 KV Cache 空间。这以牺牲部分并发度为代价,彻底避免了因空间耗尽导致的系统死锁,是一种“吞吐量换稳定性”的设计。相比之下,nano-vllm 采用回滚重试策略,可能引起延迟毛刺。
TVM FFI 高性能绑定
概念简介
TVM FFI 是面向机器学习的高性能跨语言调用组件。mini-sglang 使用其 JIT(即时编译) 模式,通过 tvm_ffi.cpp.load_inline 或 load 接口在运行时编译 C++ 代码,并利用缓存避免重复编译,兼顾了开发灵活性和运行性能。
性能优势示例
官方及自测表明,使用 TVM FFI 绑定自定义内核函数,性能通常优于纯 Python 或默认 PyTorch 接口。例如,实现一个查找两数组最长公共前缀的函数 fast_compare_key:
C++ 实现 (compare_key.cpp):
#include <dlpack/dlpack.h>
#include <tvm/ffi/container/tensor.h>
#include <tvm/ffi/dtype.h>
#include <tvm/ffi/extra/c_env_api.h>
#include <tvm/ffi/function.h>
#include <tvm/ffi/object.h>
#include <algorithm>
#include <stdexcept>
namespace {
// ... 输入检查等辅助函数 ...
auto fast_compare_key(const tvm::ffi::TensorView a,
const tvm::ffi::TensorView b) -> size_t {
// ... 类型检查和指针转换 ...
const auto common_len = std::min(a.size(0), b.size(0));
if (a.dtype().bits == 64) {
const auto a_ptr_64 = static_cast<const int64_t *>(a_ptr);
const auto b_ptr_64 = static_cast<const int64_t *>(b_ptr);
const auto diff_pos =
std::mismatch(a_ptr_64, a_ptr_64 + common_len, b_ptr_64);
return static_cast<size_t>(diff_pos.first - a_ptr_64);
} else {
// ... 32位版本 ...
}
}
} // namespace
TVM_FFI_DLL_EXPORT_TYPED_FUNC(fast_compare_key, fast_compare_key);
性能对比测试结果:
测试场景 Python(μs) C++(μs) 加速比
短数组-开头不匹配 2.401 0.312 7.70x
中等数组-完全匹配 12.688 0.342 37.11x
...
内存节省: 0.44 KB (79.0%)
C++ 版本在性能和内存开销上均显著优于纯 Python 实现。
模型算子与通信插件的设计
极简的算子基类
mini-sglang 自研了 BaseOP 类替代 PyTorch 的 nn.Module,通过基于字典树的反射机制,使用点号分隔的字符串键直接映射成员变量,实现了模型权重加载与推理计算的解耦。这种设计代码更简洁,权重管理完全自主可控。
计算与加载的拆分
权重读取采用集中处理模式,与 nano-vllm 的内聚处理不同。这将算子计算和权重加载逻辑拆分,有利于未来扩展新的分布式模式或复用旧模型的加载逻辑,减少了 TP 模式下不同算子的重复代码,更适合大型项目。
可插拔的通信组件
通信操作被封装到 DistributedCommunicator 类中,并通过插件列表 (plugins) 实现可扩展性。新增通信组件(如 PyNCCL)只需将插件实例追加到列表中,无需修改其他调用代码,设计巧妙。
总结
通过对 mini-sglang 的深入剖析,我们可以看到其在 nano-vllm 的基础上,引入了分块预填充 (Chunked Prefill)、重叠调度 (Overlap Scheduling)、注意力后端多态封装、基于 Radix Tree 的 KV Cache 管理等高级特性,并采用了更工业化的多进程架构和模块化可扩展设计。
它在架构上权衡了性能、稳定性与扩展性,例如在 KV Cache 管理上采用“预留空间”策略确保稳定性,在代码组织上拆分计算与加载以提升可维护性。这些设计决策使其不仅是一个学习大模型推理原理的优秀样板,也为构建生产级推理服务提供了宝贵的架构参考。
对于希望从入门迈向进阶,深入理解工业化大模型推理引擎设计的开发者而言,研究 mini-sglang 的源码和设计思想无疑是一条高效的路径。欢迎大家在 云栈社区 的智能与数据板块继续交流探讨相关技术细节。
 发表于 2026-2-25 04:44:47
|
查看: 220|
回复: 0
发表于 2026-2-25 04:44:47
|
查看: 220|
回复: 0
