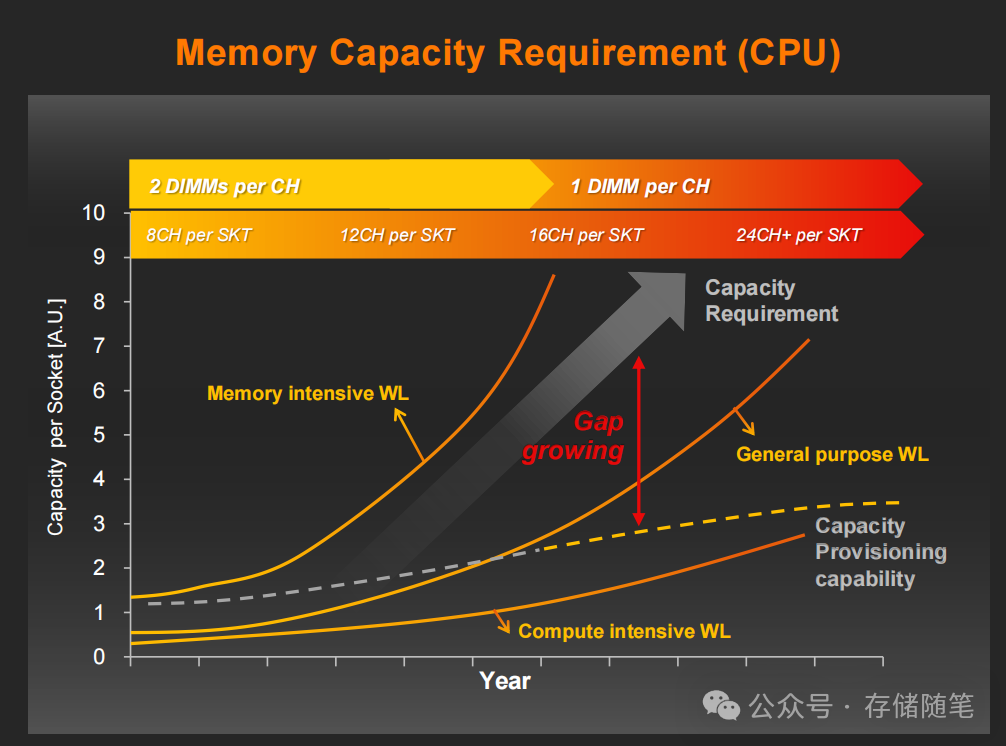
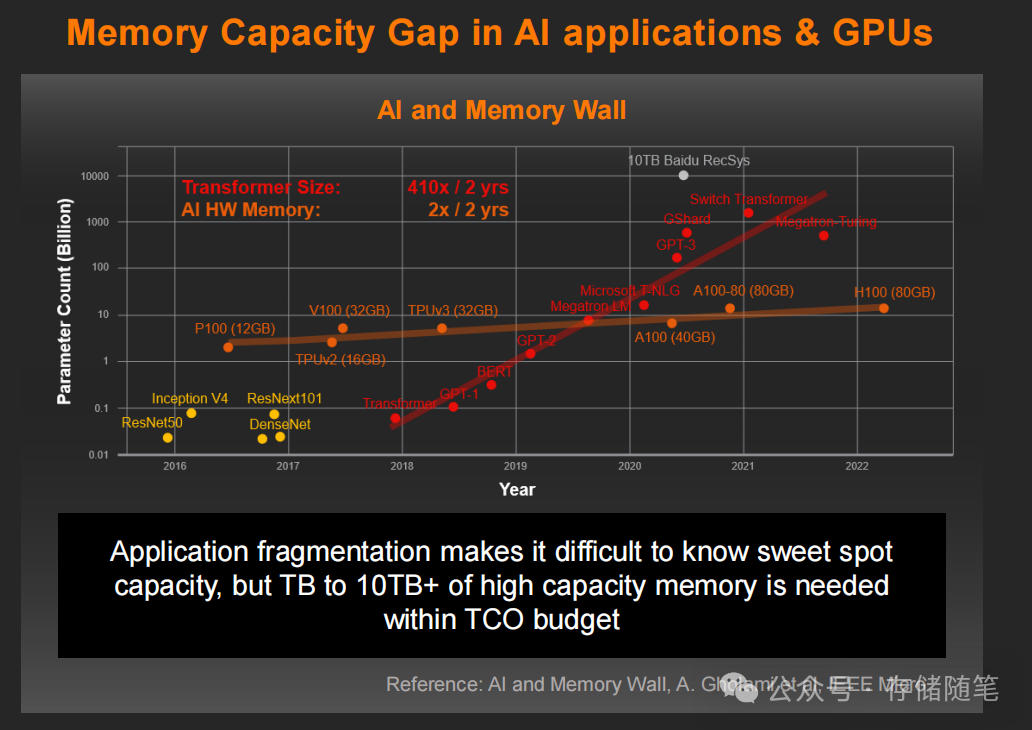
在大数据与AI爆发的时代,内存墙问题早已从技术瓶颈演变为业务扩张的核心阻碍。CPU与GPU性能飞速提升,但传统DRAM内存的容量、带宽与成本平衡始终难以突破。面对AI大模型训练所需的TB级内存,以及HPC计算渴求的超高带宽,纯DRAM架构的高昂成本让企业望而却步。此时,CXL(Compute Express Link)接口与低延迟闪存的结合,正以“内存扩展”的全新范式,打破内存与存储之间的“语义墙”。
一、CXL+低延迟闪存的协同突破
要理解CXL闪存扩展的价值,首先需要明确两个核心要素的技术突破:CXL接口的协议优势,以及低延迟闪存的介质革新。
1. CXL接口:打破架构壁垒的“统一总线”
CXL作为PCIe 5.0/6.0时代的高速互连协议,其核心价值在于统一内存与存储的访问范式。与传统PCIe仅支持“存储块访问”不同,CXL.mem协议允许CPU/GPU直接将外部介质识别为“内存地址空间”,无需通过文件系统或块设备驱动转换,从根本上消除了内存与存储之间的语义鸿沟。同时,CXL.io协议提供灵活的配置能力,确保多设备协同的兼容性,为内存池化、分层扩展奠定了基础。
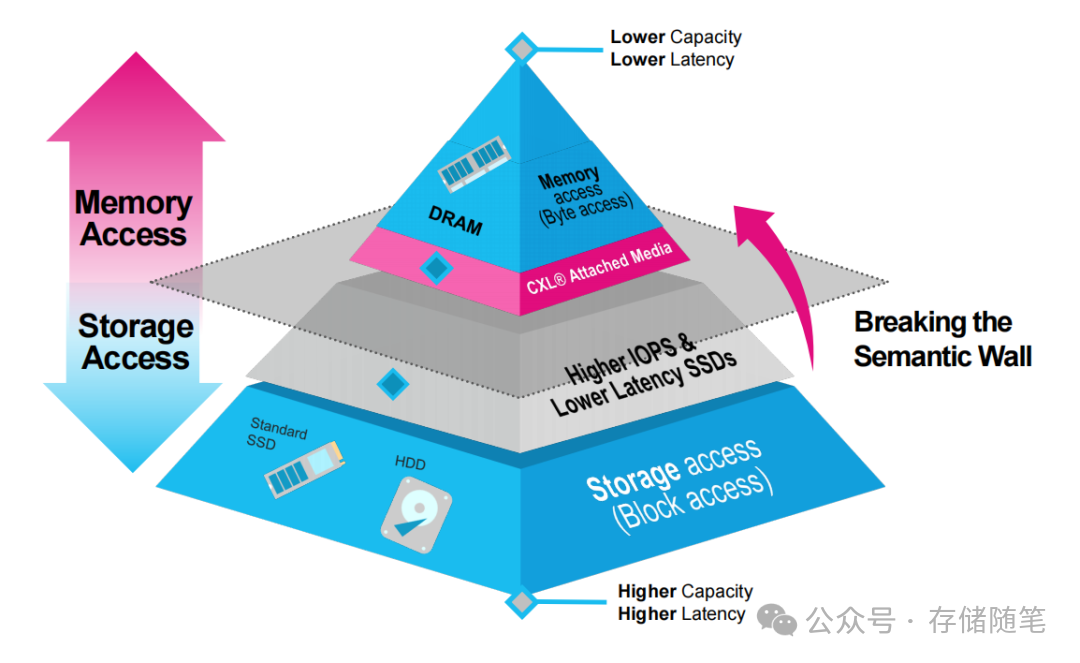
2. 低延迟闪存:从存储介质到内存扩展层
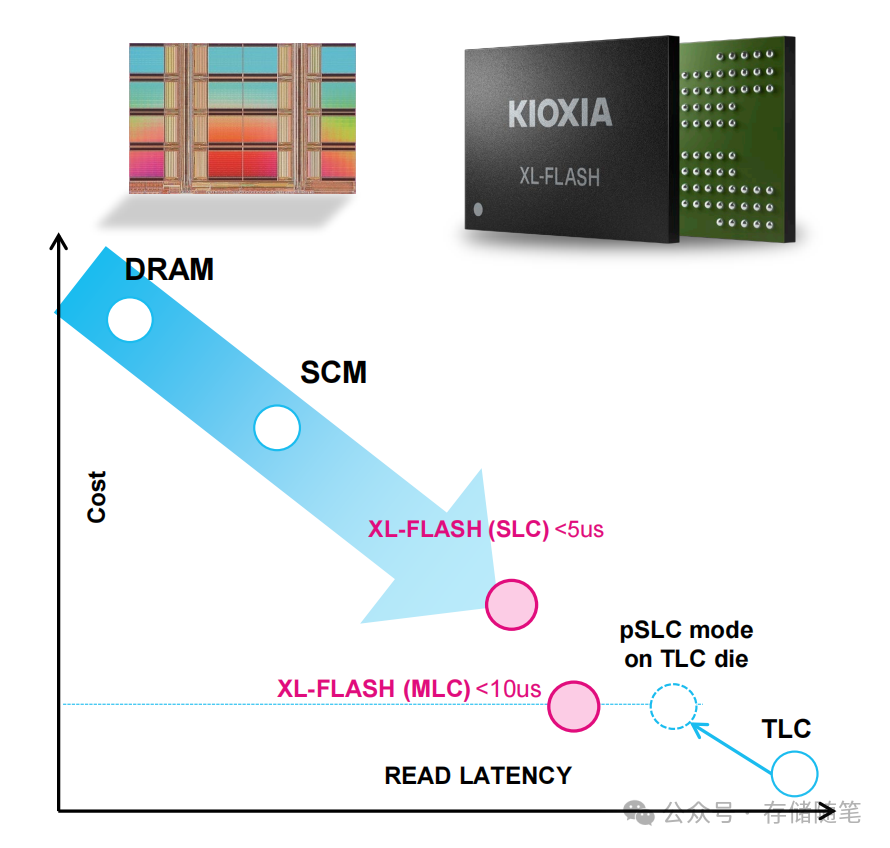
传统NAND闪存的毫秒级延迟无法满足内存访问需求,而KIOXIA的XL-FLASH与SK hynix的CMM-DDR5模块,通过介质优化实现了质的飞跃:
- KIOXIA XL-FLASH:基于BiCS FLASH 3D技术,SLC模式下读取延迟低至<5us,MLC模式<10us,接近DRAM的微秒级响应(典型DRAM延迟为1-3us)。单芯片容量达128Gb(SLC)/256Gb(MLC),支持2/4/8芯片封装,单模块容量≥512GB,最高可实现256TB扩展,向1PB容量演进。
- SK hynix CMM-DDR5:采用DDR5与CXL协同设计,单模块容量128GB,支持与本地DRAM形成混合内存架构,带宽可达6400Mbps,与DDR5原生带宽持平,确保扩展后系统性能不打折。
3. 关键创新:打破语义墙的技术组合
两者的结合形成了“低延迟介质+CXL协议”的黄金组合,其核心价值体现在三方面:
- 成本平衡:闪存的单位容量成本仅为DRAM的1/3-1/5,256TB XL-FLASH的总成本远低于同等容量DRAM;
- 无缝扩展:系统无需重构,通过Linux TPP(透明页放置)等技术自动管理内存分层,热数据驻留DRAM,冷数据迁移至CXL闪存;
- 灵活部署:支持单服务器直接连接(容量/带宽扩展)与多服务器内存池化(资源共享),适配不同业务场景。
二、实测数据验证四大核心价值
KIOXIA与SK hynix的实测报告覆盖了AI、HPC、数据库、内存池化四大核心场景,用数据证明了CXL闪存的实用价值。
1. AI/LLM推理:带宽扩展提升30%性能
SK hynix在Llama 3.1(70B Q8)模型推理测试中,对比了“DDR5-only”与“DDR5+CXL”架构的性能差异:
- 配置:Intel Granite Rapids CPU,2通道DDR5(128GB×2)+1通道CXL CMM-DDR5(128GB);
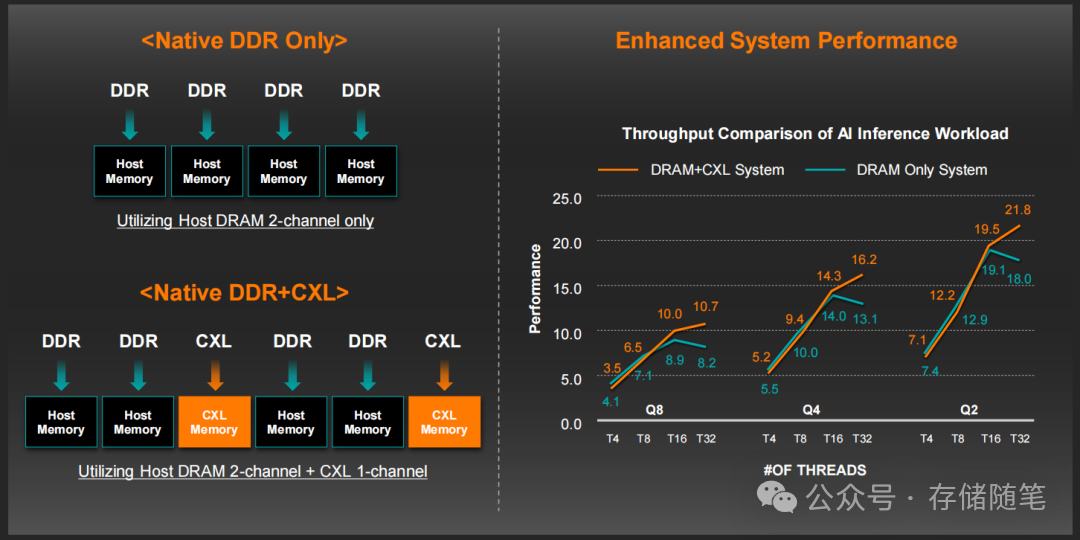
- 结果:在T8-T32线程数下,CXL混合架构的吞吐量比纯DDR5提升30%,Q8量化模式下性能优势尤为显著。核心原因是CXL模块提供了额外的内存带宽,缓解了LLM推理过程中的内存访问瓶颈——70B模型的权重数据达70GB,单通道DDR5带宽不足,而CXL补充的带宽让数据并行处理效率大幅提升。
2. 内存数据库(IMDB):25%内存卸载仅5%性能损失
Redis作为主流内存数据库,其性能对内存容量和延迟高度敏感。两家厂商的测试均验证了CXL闪存的适配性:
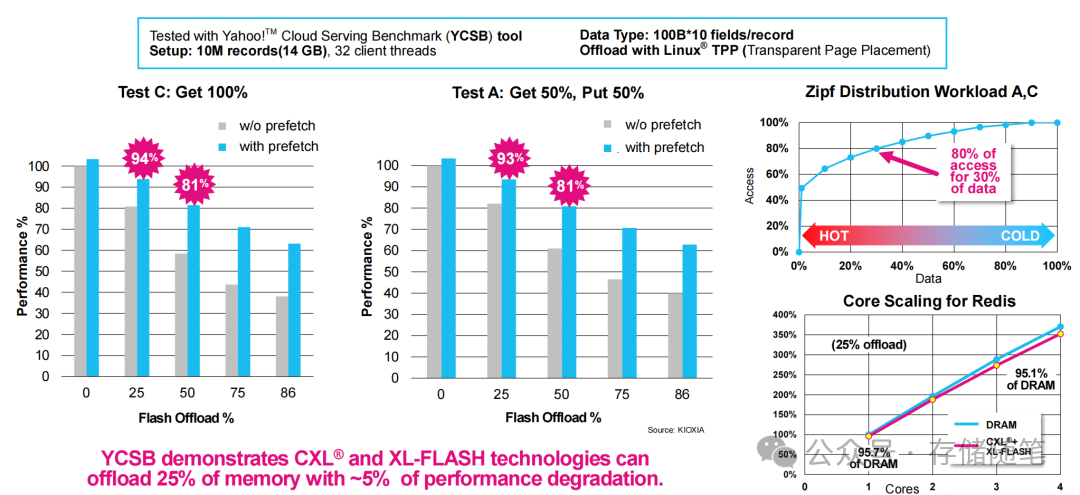
- KIOXIA测试:采用YCSB基准测试,100B×10字段/记录,1000万条数据(14GB),32客户端线程。通过Linux TPP技术将25%的内存数据卸载至XL-FLASH,Test A(50%Get+50%Put)性能保持95.7%,Test C(100%Get)性能保持95.1%,仅5%左右的性能损失换来了显著的成本优化。同时,预取技术(prefetch)可将闪存卸载比例提升至86%,性能损失控制在19%以内。
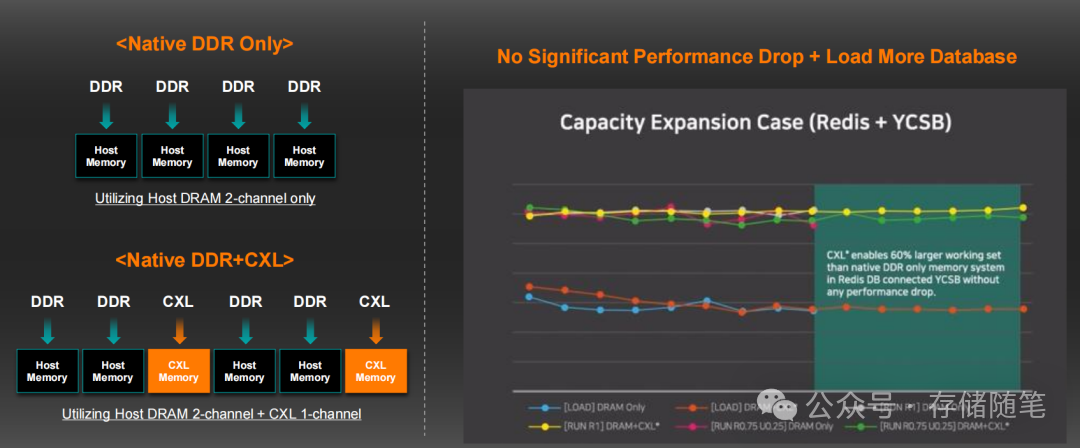
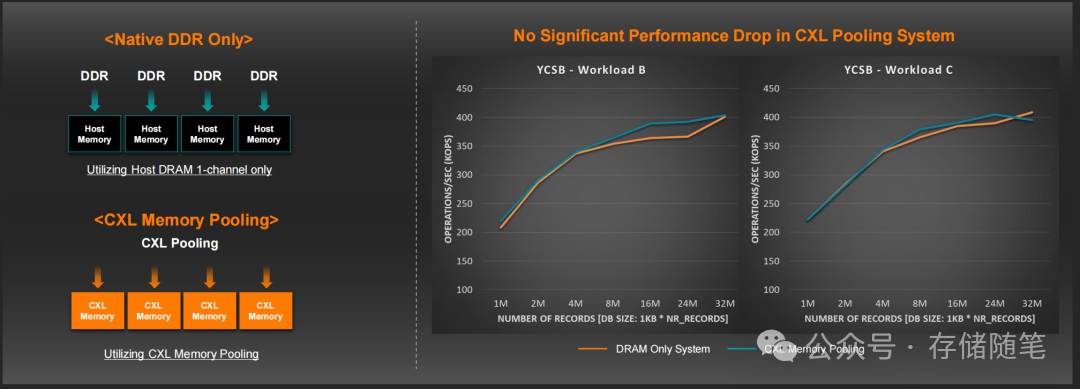
- SK hynix测试:单服务器场景下,CXL扩展让Redis数据库容量突破本地DRAM限制,加载3200万条记录(32GB)时,吞吐量与纯DRAM架构无显著差异;多服务器内存池化场景下,22通道CXL内存池支持多节点共享,YCSB Workload B/C测试中,操作吞吐量维持在400KOPS以上,与本地DRAM性能持平。
3. HPC计算:带宽敏感负载性能提升33%
SK hynix在SPEC CPU 2017基准测试中,针对内存敏感型子项(502.gcc、505mcf、549.lotonk3d)进行测试:
- 结果:CXL混合架构的性能比纯DDR5提升11%-33%,其中549.lotonk3d(3D流体模拟)性能提升最显著(33%)。原因是HPC负载的内存访问具有高并行性,CXL提供的额外带宽让多核心同时访问内存时的冲突减少,数据传输效率提升。这一优化对于处理海量数据集的大数据计算任务同样具有重要意义。

- KIOXIA的混合应用测试也验证了这一点:将内存密集型应用(ScyllaDB)与计算密集型应用(SPEC CPU)结合,33%内存卸载至XL-FLASH后,系统整体性能保持98.4%,实现了“容量扩展+性能稳定”的双重目标。

4. 内存池化:多服务器资源共享,降低TCO
在多服务器场景中,CXL内存池化解决了传统架构中“内存孤岛”问题:
- 配置:基于AMD EPYC Turin处理器,多节点共享22通道CXL内存池(128GB×22);
- 结果:Redis数据库跨节点共享内存资源,当单节点DRAM不足时,自动调用池化内存,3200万条记录场景下无性能损失。这意味着企业无需为每个节点配置足额DRAM,通过资源共享可减少30%以上的服务器数量,大幅降低TCO。

三、关键优化技术:让延迟“隐形”的核心手段
CXL闪存的成功落地,离不开软件层面的优化技术,这些技术让闪存的微秒级延迟对应用透明:
1. 透明分层管理:Linux TPP与内存 tiering
Linux内核的TPP(Transparent Page Placement)技术自动识别数据热冷属性,将高频访问的热数据保留在DRAM,低频访问的冷数据迁移至CXL闪存。KIOXIA正在推动CXL Hotness Monitoring Unit补丁融入Linux内核,进一步提升数据分类的准确性,让分层策略更智能。
2. 预取与上下文切换:隐藏闪存延迟
- 预取技术:在应用访问数据前,提前将CXL闪存中的数据加载至DRAM缓存,将闪存访问延迟掩盖在计算周期内。KIOXIA测试显示,预取可将Redis的闪存卸载比例从81%提升至93%;
- 多上下文切换:CacheLib等库通过在单个核心上运行多个上下文,当一个上下文访问CXL闪存时,切换至其他上下文执行,隐藏闪存延迟。实测显示,CacheLib的get操作CPU penalty仅0.5us,set操作0.8us,接近DRAM的访问效率。
3. 硬件-软件协同:NUMA交织与带宽优化
SK hynix在HPC测试中采用NUMA交织技术,让DDR5与CXL内存的访问请求均匀分布,避免单通道带宽瓶颈;KIOXIA的XL-FLASH支持16 Plane并行访问,4096B页大小与DRAM保持一致,减少数据传输中的格式转换开销。
四、挑战与未来展望
尽管CXL闪存表现亮眼,但仍面临一些待解挑战:
- 场景适配限制:对延迟极端敏感的应用(如高频交易核心引擎)仍需纯DRAM架构,CXL闪存更适合容量/带宽需求高、延迟容忍度中等的场景;
- 生态成熟度:部分应用尚未针对CXL内存分层优化,需要行业共同推动软件栈完善;
- 成本平衡:当前CXL控制器与闪存模块的成本仍高于传统SSD,规模化应用后成本有望进一步下降。
未来,CXL闪存将向三个方向演进:
- 容量与速度升级:KIOXIA计划推出1PB级XL-FLASH模块,SK hynix将CMM-DDR5带宽提升至8000Mbps以上,进一步缩小与DRAM的性能差距;
- 多介质协同:结合SCM(存储级内存)与3D NAND,构建“DRAM+SCM+CXL闪存”的三级内存架构,兼顾性能、容量与成本;
- 生态扩张:适配更多应用场景,包括GPU图形处理、大数据分析、虚拟化集群等,成为通用计算的标准内存扩展方案。
结语
CXL接口与低延迟闪存的结合,不仅是技术上的突破,更是内存架构的范式革新——它打破了“内存=DRAM,存储=SSD”的固有认知,构建了“按需扩展、弹性伸缩”的内存池化生态。从实测数据来看,AI推理性能提升30%、内存数据库25%卸载仅5%性能损失、多服务器TCO降低30%,这些指标充分证明了CXL闪存的实用价值。对于企业而言,CXL闪存作为DRAM的互补者,让企业能够以更具成本效益的方式获得超大容量内存,从容应对AI、HPC、大数据带来的内存需求爆炸。随着生态的完善,CXL闪存必将成为下一代数据中心的核心基础设施之一。 |  发表于 2025-12-7 01:03:19
|
查看: 219|
回复: 0
发表于 2025-12-7 01:03:19
|
查看: 219|
回复: 0
