前几天,一篇关于如何恢复Antigravity账号的文章引起了大家的讨论。有朋友留言说:“狠狠的折腾比不过美国原生住宅ip,别人的起点就是折腾的终点。” 也有人说:“最近我一直在想,还是要训练自己使用低智能模型的能力的,总用Claude,万一哪天不能用了,耽误干活儿,整个人都焦虑了。”
这不禁让我思考,除了依赖外部服务,我们是否有可能构建一个不依赖云端、完全由自己掌控的AI辅助编程环境呢?恰好在此时,国内智谱AI发布了GLM-4.7模型,新闻中称其“专为Agentic Coding打造,在多个权威编程基准上超越了Claude Sonnet 4.5”。
这激起了我的好奇心,既然有开源模型,能否将它部署在本地,并与代码助手工具结合起来?说干就干,我决定尝试用智谱GLM-4.7和OpenCode搭建一个专属的本地开发环境。
第一步:下载GLM-4.7量化模型
首先,我需要一个可以在本地运行的模型文件。我选择在Hugging Face上寻找量化版本,最终找到了DavidAU/GLM-4.7-Flash-Uncensored-Heretic-NEO-CODE-Imatrix-MAX-GGUF这个仓库。量化模型能显著减少对显存和内存的需求,更适合在资源有限的设备上运行。
使用huggingface-hub命令行工具下载指定的Q4_K_M量化文件(约18GB)到本地目录:
huggingface-cli download DavidAU/GLM-4.7-Flash-Uncensored-Heretic-NEO-CODE-Imatrix-MAX-GGUF --local-dir ./data/models/llama.cpp --include *Q4_K_M*
由于网络原因,这个18GB的文件下载了相当长一段时间。
第二步:在本地服务器加载模型
我使用的硬件是一台拥有64GB内存的NVIDIA Jetson AGX Orin开发套件。为了在本地提供服务,我选择了llama.cpp项目及其附带的llama-server工具。
使用以下命令启动模型服务:
llama-server \
-m /data/models/GLM-4.7-Flash-Uncen-Hrt-NEO-CODE-MAX-imat-D_AU-Q4_K_M.gguf \
--temp 1.0 --top-p 0.95 --top-k 2 \
--port 9000 \
--host 0.0.0.0 &
命令成功执行,服务在后台启动。从系统监控可以看到,模型加载后占用了大量内存,已使用约50GB,所剩资源不多了。
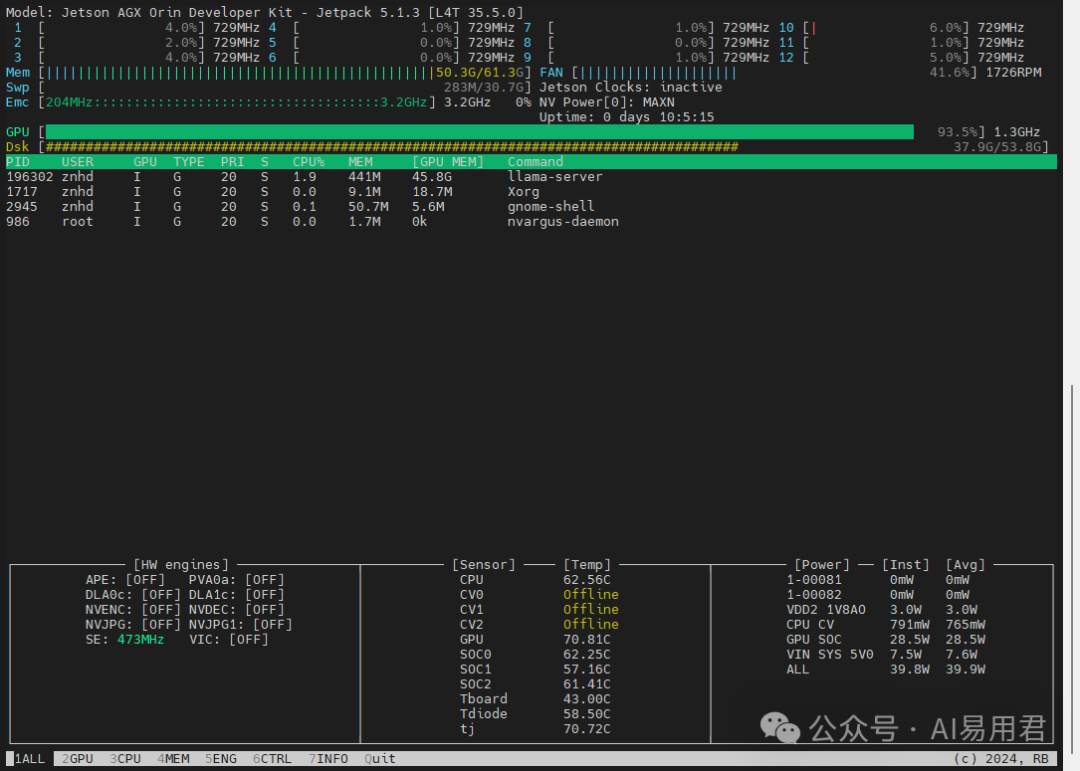
通过服务启动日志,可以确认加载的正是“GLM 4.7 Flash Heretic”版本,并打印出了详细的模型参数信息。
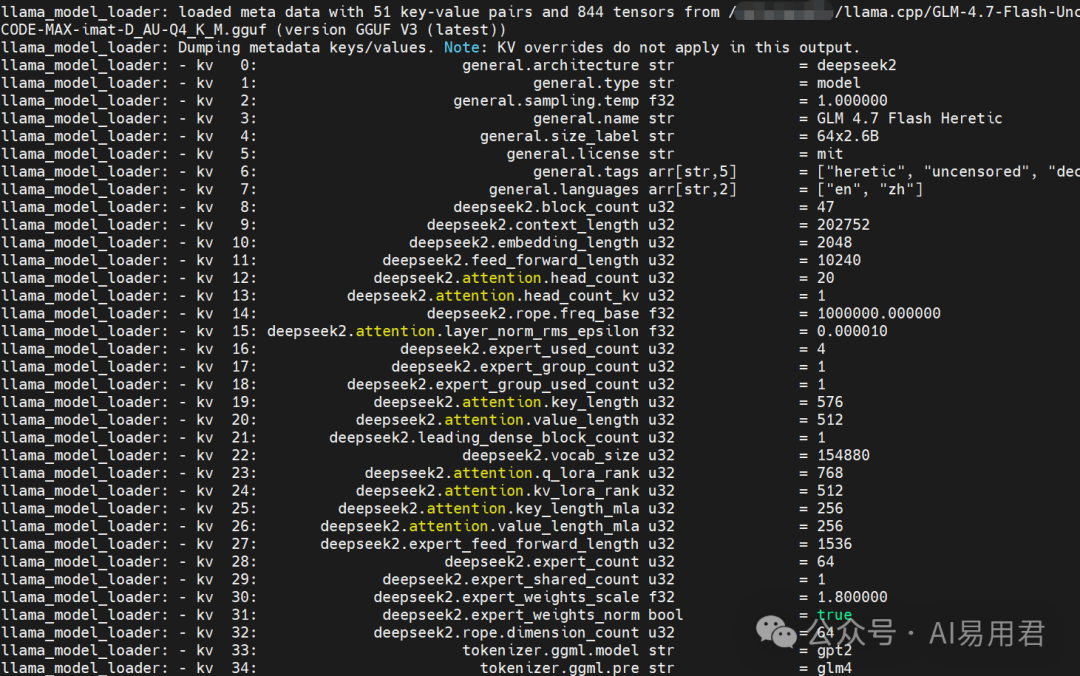
第三步:配置OpenCode客户端
我的主力开发机是Windows系统。接下来需要在电脑上配置OpenCode,让它连接到我们刚刚启动的本地模型服务。
OpenCode的配置文件位于用户目录下的.config/opencode/opencode.json。我们需要创建并编辑这个文件。
其内容如下,核心是指定自定义的AI服务提供商和端点:
{
"$schema": "https://opencode.ai/config.json",
"disabled_providers": [],
"provider": {
"myprovider1": {
"name": "My AI Provider",
"npm": "@ai-sdk/openai-compatible",
"models": {
"glm47": {
"name": "glm_4.7"
}
},
"options": {
"baseURL": "http://192.168.1.2:9000"
}
}
}
}
baseURL:需要修改为你本地llama-server服务运行的实际IP地址和端口(这里是9000)。models:这里定义了一个名为glm47的模型,在OpenCode中会显示为glm_4.7。
第四步:实践与测试
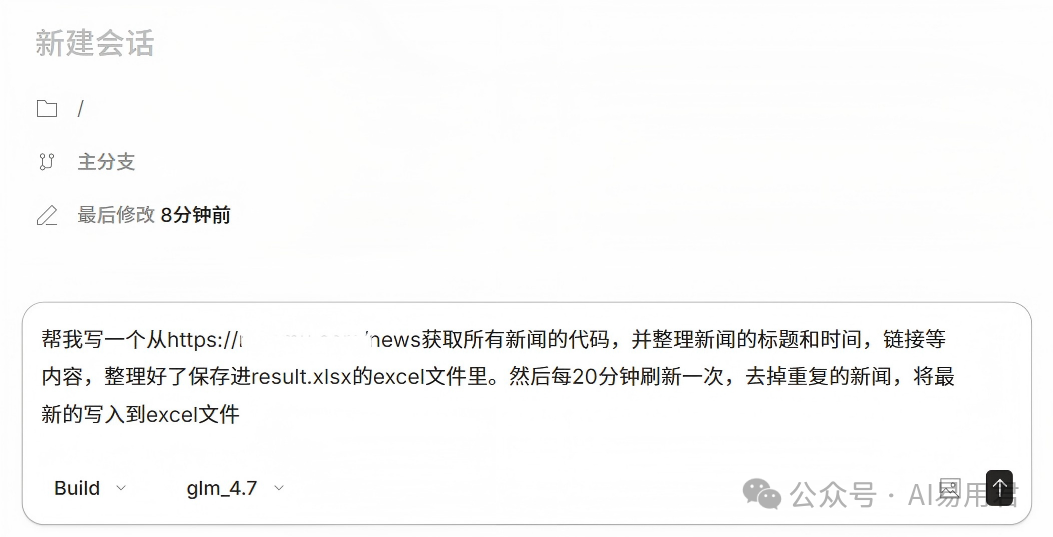
配置完成后,启动OpenCode。为了测试这套搭建AI开发环境的效果,我提出了一个简单的编程任务:“编写一个从指定网站抓取新闻,整理后存入Excel,并每20分钟自动更新去重的脚本。”
在OpenCode界面中创建新会话,并选择我们刚配置好的glm_4.7模型,然后输入任务描述。
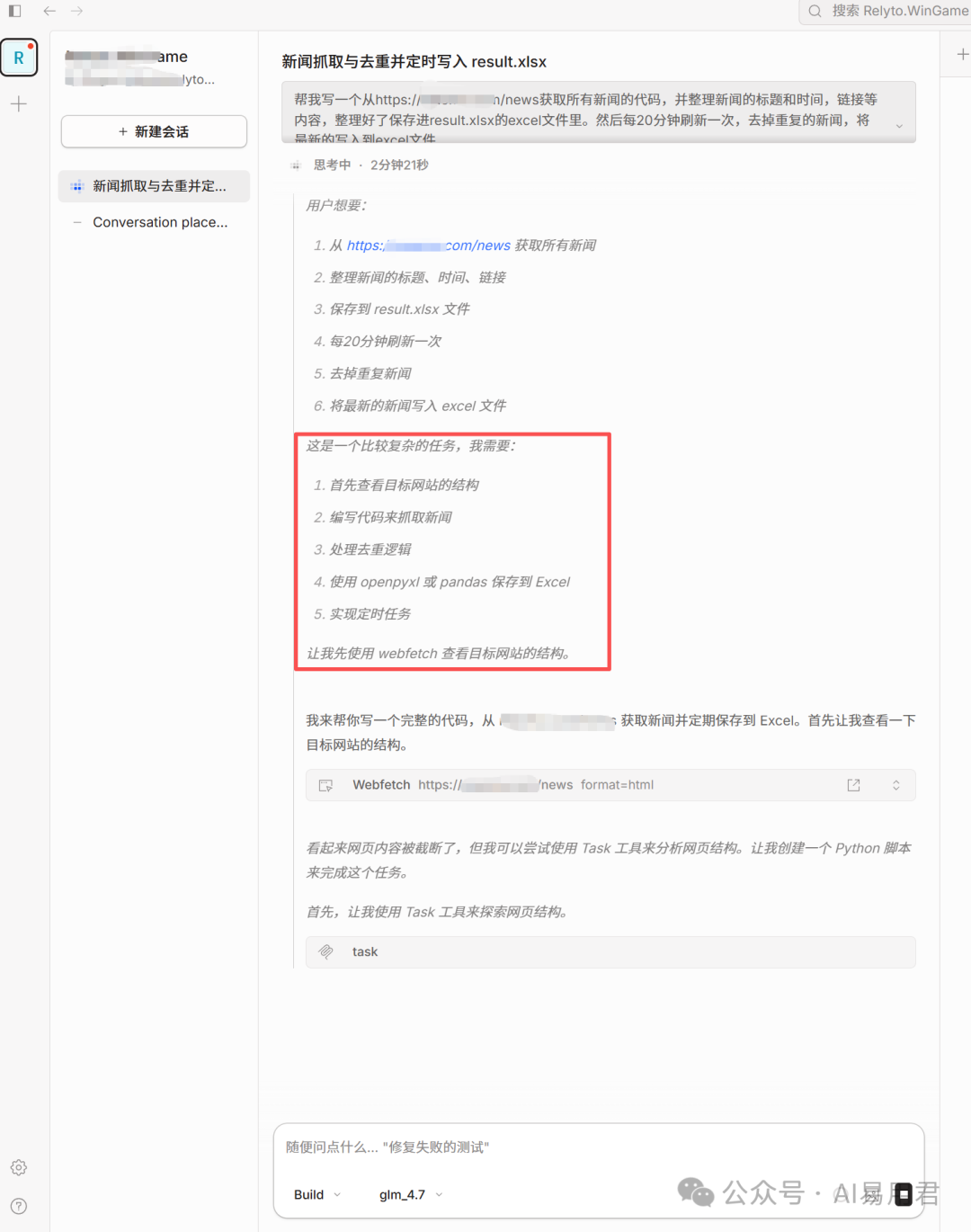
提交任务后,观察Jetson服务器的资源监控,可以看到llama-server进程的CPU使用率明显上升,模型正在“思考”并生成代码。
同时,在OpenCode的对话界面中,GLM-4.7开始逐步分析任务,规划实现步骤(查看网页结构、编写爬虫、处理去重、保存Excel、设置定时任务),并尝试生成代码。
总结与展望
通过以上步骤,我们成功地将一个开源的大语言模型部署在本地硬件上,并通过OpenCode这个客户端工具与之交互,实现了一个完全私有化的AI编程辅助环境。这套方案的优点显而易见:数据完全本地化,无需担心隐私泄露或服务中断;同时,它也为深入研究和定制化开源项目提供了极好的平台。
当然,这只是初步的搭建。本地模型的推理速度、响应质量以及如何更有效地将其集成到完整的开发工作流中,还需要进一步的测评和优化。如果你对这类本地化AI应用实践感兴趣,或者有更好的想法,欢迎在云栈社区的相关板块进行交流探讨。
 发表于 2026-2-28 09:20:23
|
查看: 339|
回复: 0
发表于 2026-2-28 09:20:23
|
查看: 339|
回复: 0
