随着人工智能模型训练规模扩展到数千乃至上万个GPU,网络性能已然成为制约整个系统效率的关键瓶颈。尽管RoCE(基于融合以太网的远程直接内存访问)技术成功将RDMA功能引入了标准以太网,但当面对大规模AI集群时,传统以太网的丢包、拥塞与性能不稳定等问题便暴露无遗。本文将深入探讨RoCE在演进过程中面临的挑战,并解析NVIDIA Spectrum-X平台如何通过一系列软硬件协同创新,为大规模AI工作负载打造可靠、可扩展的高性能以太网连接。
一、RoCE:AI与HPC数据中心的网络加速器
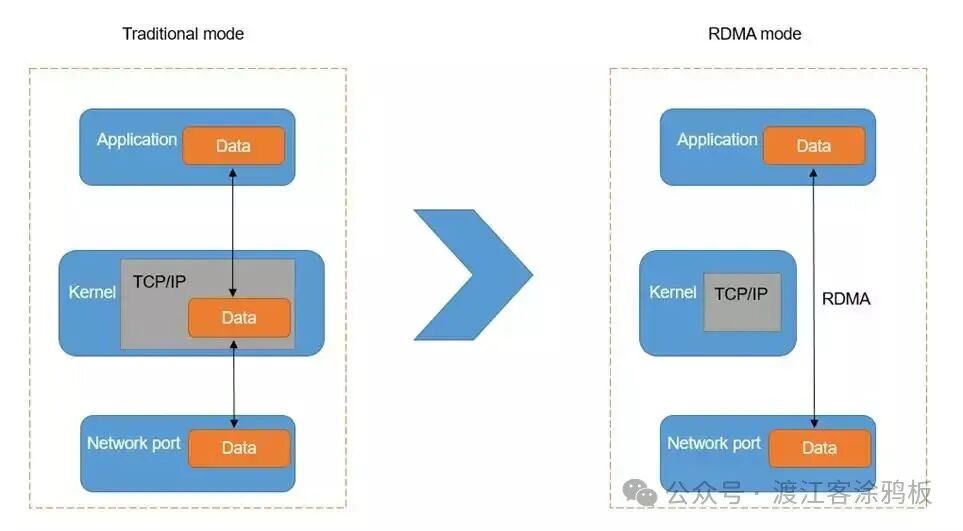
RoCE(基于融合以太网的远程直接内存访问) 是一种将RDMA能力赋予标准以太网的技术。与依赖CPU和内核协议栈的传统TCP/IP通信相比,RoCE允许数据直接在节点间内存(包括GPU内存)中传输,显著降低了通信延迟并提升了带宽效率。因此,RoCE已成为高性能计算(HPC)和大规模AI训练集群不可或缺的互连方案。
随着RoCEv2的成熟与普及,其在数据中心的部署规模持续增长。相较于依赖专用硬件的InfiniBand架构,RoCE在成本效益、部署灵活性以及生态兼容性方面展现出明显优势,为大规模云与AI集群提供了一条高性价比的高性能网络路径。
二、大规模AI集群中RoCE的典型挑战
尽管RoCE旨在提供低延迟与高带宽,但在真实的、大规模的AI训练环境中部署时,仍面临诸多严峻挑战。传统以太网本质上是一种“有损”网络,丢包和重传通常被认为是可接受的。然而,在AI训练这类对同步要求极高的场景中,即便微量的丢包也可能导致GPU等待、计算资源闲置,从而大幅拉低整体训练效率。
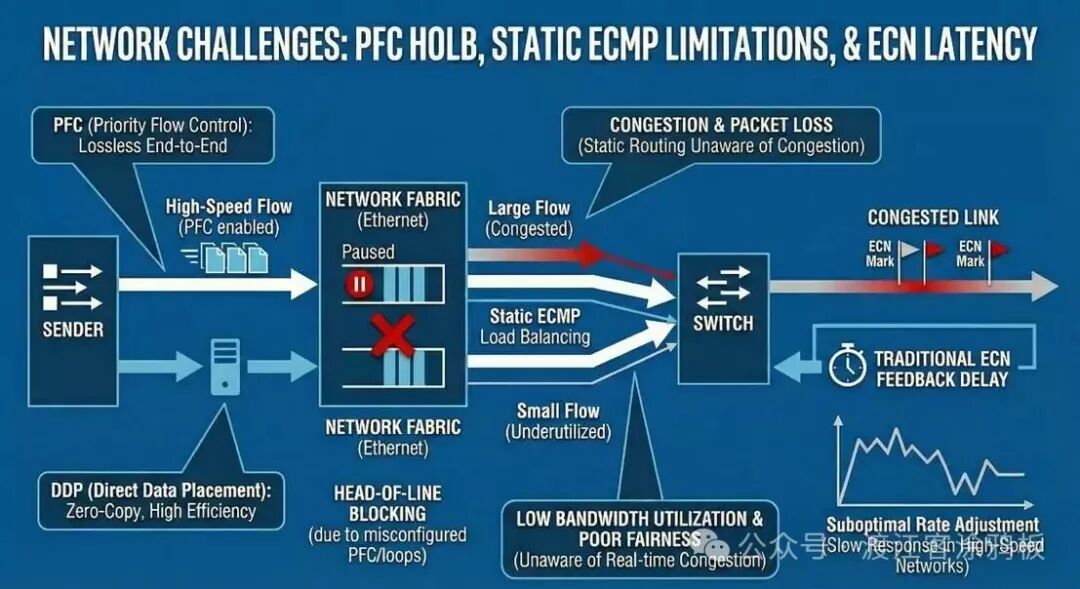
为实现RoCE所需的“无损”传输,通常需要引入优先级流控制(PFC)等机制。这虽然提高了交换机和网卡的流控能力,但也增加了网络配置与运维的复杂性。一旦配置不当,PFC本身反而可能引发新的性能问题,例如队头阻塞(HOLB)。
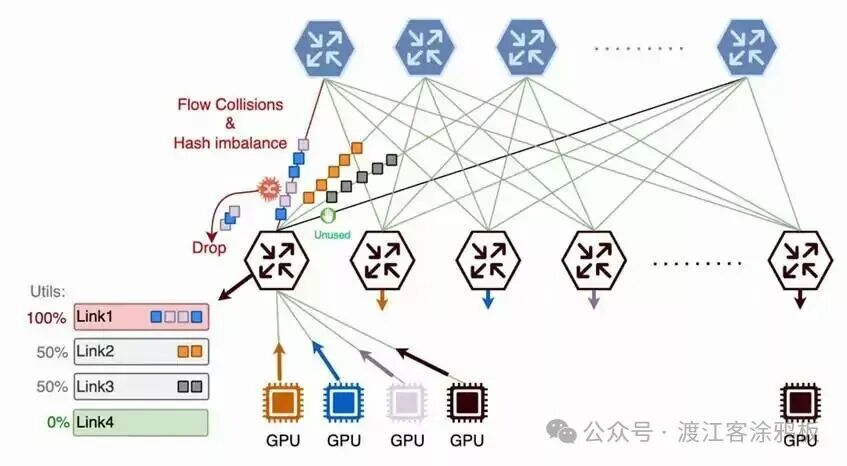
此外,传统以太网通常依赖基于静态哈希的等价多路径(ECMP) 进行负载均衡。这种“一劳永逸”的方式难以适应AI工作负载的特性——长时间运行、带宽密集的“大象流”与对延迟极其敏感的“老鼠流”常常并存。静态ECMP无法感知实时链路拥塞,极易导致热点链路、带宽利用不均、尾部延迟激增以及流完成时间不可预测。同时,传统的拥塞控制机制(如ECN)往往在拥塞发生后才做出反应,在高速、大规模分布式AI通信中显得力不从心。
三、深入RoCE的技术瓶颈
在以太网上实现高效的无损RoCE传输,需要在协议和实现层面解决多个核心问题。
首先,在传统有丢包的网络基础上确保RDMA的可靠性与低延迟,通常依赖于端到端的无损设计。这包括利用PFC防止丢包,以及通过直接数据放置(DDP)减少内存拷贝来提升协议效率。然而,在复杂的网络拓扑或高负载场景下,粗粒度的PFC控制可能引发连锁反应,导致队头阻塞。
其次,静态ECMP缺乏对实时链路状态的感知,无法区分不同类型流量的资源需求。在“大象流”与“老鼠流”混合的环境中,这会严重限制带宽利用率和流量公平性。
再者,传统拥塞控制的反馈延迟限制了其有效性。ECN等机制通常只能在拥塞发生后提供通知,难以遏制拥塞在高速网络中的扩散。
这些限制在小规模部署中或许不明显,但在由成百上千个GPU组成的AI训练集群中,其影响会被急剧放大,最终成为制约整体训练效率与网络稳定性的关键因素。
在此背景下,NVIDIA推出了专为AI优化的以太网平台——Spectrum-X。其主要目标在于,使基于标准以太网的RoCE网络能够实现可与InfiniBand相媲美的无损、确定且可预测的性能,同时完美适应大规模GPU集群与生成式AI云环境的需求。
Spectrum-X平台由基于NVIDIA Spectrum-4 ASIC的以太网交换机、ConnectX SuperNIC、BlueField DPU及配套的网络软件生态组成。通过深度的软硬件协同,它提供了超越单设备优化的端到端性能保障。

四、构建无损传输基石:PFC、DDP与硬件拥塞感知
Spectrum-X的设计核心理念是打造真正无损的以太网传输环境。它在利用RoCE实现CPU旁路通信的基础上,深度融合PFC和DDP技术,确保端到端的数据包无损交付,而非依赖传统以太网的丢包重传机制。
在这一层,交换机与SuperNIC之间的紧密协作至关重要。SuperNIC能够在硬件层面实时检测网络拥塞,并动态参与流量调度,从而预防因拥塞导致的突发延迟或丢包。这种设计使得以太网的性能表现更接近于InfiniBand的确定性特征,满足了AI训练对延迟与可靠性的苛刻要求。
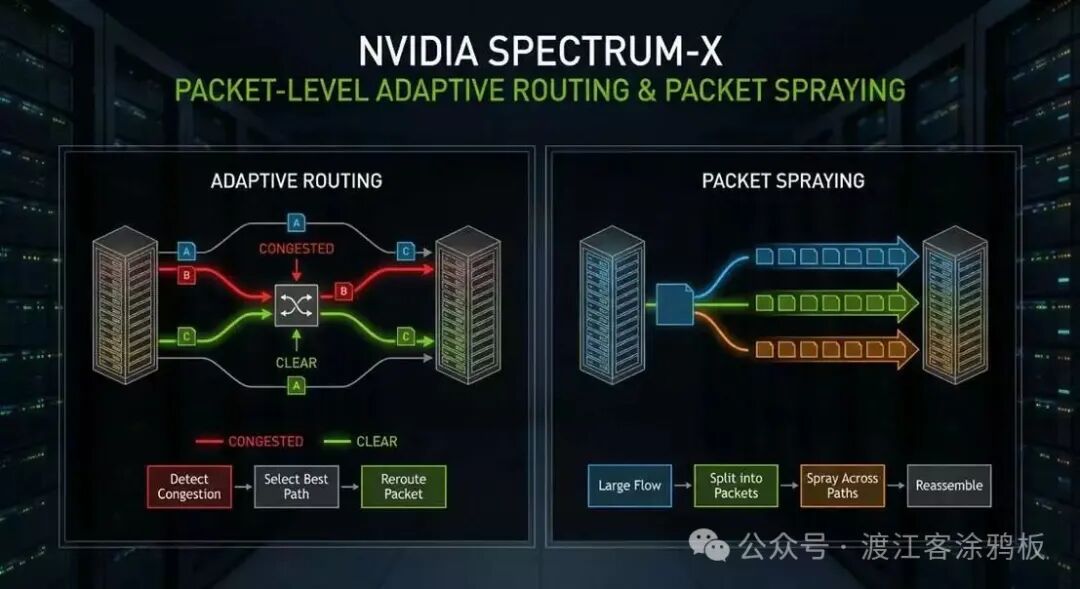
五、突破静态路由限制:动态路由与包级调度
为了彻底解决静态ECMP在大规模流量场景下的局限性,Spectrum-X引入了两项关键技术:数据包级自适应路由 与 数据包喷射。
单个数据包可以根据实时链路利用率动态选择最佳转发路径,有效规避拥塞热点,从而显著提升全网链路利用效率。由于数据包可能经由不同路径、乱序到达,Spectrum-X会在SuperNIC层面完成重排序,确保传输接口的正确性与一致性。
这种方法极大地增强了网络在流量不均衡情况下的可扩展性,使得大型GPU集群间的数据交换更加高效。
六、实现实时拥塞控制:带内遥测与快速反馈
Spectrum-X通过集成基于硬件的带内遥测技术,对传统拥塞控制进行了革新。网络状态信息被持续收集并实时反馈给SuperNIC。基于这些高精度的遥测数据,SuperNIC执行流量计量与速率调整,形成一个亚微秒级的快速反馈闭环。
这套机制使得网络能够在拥塞萌芽阶段就迅速做出响应,通过动态调整路由和发送速率,防止缓冲区堆积和延迟飙升。因此,Spectrum-X可以实现高达约95%的有效数据吞吐率,远优于传统大规模以太网环境中通常仅约60%的水平。
七、Spectrum-X相比传统RoCE网络的优势
相较于传统的RoCEv2部署或基于静态ECMP的RDMA网络,Spectrum-X在多个维度实现了显著跃升:
- 端到端的无损与确定性:通过硬件与DPU的深度协同,Spectrum-X实现了媲美InfiniBand的无损传输和确定性性能,将以太网真正打造成了高性能AI训练的可靠基石。
- 动态化与智能化:动态路由与智能拥塞控制克服了静态路由的性能天花板,大幅提升了带宽利用率与流完成时间的可预测性。
- 更强的容错与隔离性:对数据包重排序和实时反馈的支持,增强了网络的容错能力与性能隔离性,这对于多租户AI云环境尤为重要。
总而言之,Spectrum-X正在将以太网从一个通用的、易丢包的网络,转变为一个能够满足现代AI工作负载严苛需求的高性能RDMA平台。
八、总结与展望
RoCE技术正从传统以太网向高性能RDMA网络不断演进。它在吸收InfiniBand诸多优点的同时,依然保持了标准以太网的部署便利性与生态兼容性。NVIDIA Spectrum-X通过硬件优化、智能路由与高级拥塞控制的组合创新,使得RoCE在大规模AI部署中变得更加可靠、高效与可扩展。
这为生成式AI云和超大规模GPU集群的网络基础设施设计指明了新方向。随着AI工作负载对数据移动性能的需求持续增长,RoCE与Spectrum-X等增强技术的深度结合,无疑将成为未来数据中心网络架构演进的关键趋势。对于深入探讨相关技术的开发者,可以关注云栈社区上的更多深度讨论。
 发表于 2026-3-14 02:27:46
|
查看: 198|
回复: 0
发表于 2026-3-14 02:27:46
|
查看: 198|
回复: 0
