多模态大模型(LMM)确实好用,但背后视觉令牌过多导致的推理慢、内存占用大一直是老大难问题。最近,Case Western Reserve大学的研究者提出了一种名为FMVR的创新方法,思路巧妙且实现简单,仿佛为臃肿的模型进行了一次成功的“抽脂手术”。
原论文信息如下:
- 论文标题: Frequency-Modulated Visual Restoration for Matryoshka Large Multimodal Models
- 发表日期: 2026年03月
- 发表单位: Case Western Reserve University
- 原文链接: https://arxiv.org/pdf/2603.11220v1.pdf
- 开源代码链接: 论文中提及“The code will be open.”,但链接暂未提供。
当你的多模态大模型对着图片“指点江山”时,它真的清晰地“看”到了画面吗?还是说,它只是在处理一堆密密麻麻、让计算卡顿的“视觉令牌”?今天,我们就来聊聊如何为这些模型高效“瘦身”,让它们既能跑得快,又能看得清。
视觉令牌太多?推理慢如蜗牛!
现今流行的多模态大模型,比如大家熟知的LLaVA,理解图片的过程可以简化为两步:首先,视觉编码器(如 CLIP)将图片切分成小块,编码成“视觉令牌”;然后,将这些令牌连同文字问题一起输入大语言模型进行理解并生成答案。
问题就出在第一步。一张 336x336 像素的图片,LLaVA 会将其转换为 576 个视觉令牌。这听起来不多?但要知道,LLM 处理输入序列时的计算复杂度和内存消耗是随序列长度 指数级增长 的。这 576 个令牌已经足以让推理速度变得迟缓。
若换成高清大图或一段视频,视觉令牌数量更会爆炸式增长到几千甚至上万。想象一下实时交互或移动端部署的场景,这种计算负担和延迟,无论对成本还是用户体验都是巨大挑战。
因此,为视觉令牌“瘦身”势在必行。此前的研究者尝试过多种方法,例如用固定查询总结图片信息,或根据重要性对令牌进行排序和丢弃。
但这些方法有一个共同缺陷:一旦压缩,令牌数量就固定不变,无法根据可用算力弹性调整。后来,研究者引入了“套娃”表示学习,训练模型能够处理从少到多不同档位的令牌数量,实现了弹性。
然而,弹性问题解决了,新问题随之而来:令牌数量大幅减少后,图片的细节信息严重丢失! 模型变得“眼拙”,回答也开始出现幻觉。
压缩令牌丢细节?Grad-CAM揭示视觉语义流失
单纯说细节丢失可能有些抽象。论文作者利用 Grad-CAM 技术将这一现象“可视化”了出来。Grad-CAM 能生成热力图,直观展示模型在回答问题时,其“注意力”主要集中在图片的哪些区域。

图:Grad-CAM可视化(576和36个视觉令牌)显示,减少视觉令牌会导致视觉注意力明显退化。
观察上图左侧,当模型使用 576 个令牌(全量)观察这张户外场景图时,热力图(红色区域)密集且精准地覆盖了咖啡杯、蛋糕、背包等关键物体,模型“眼中有物”。
再看右侧,当令牌数锐减至仅 36 个时,热力图变得稀疏、分散,甚至转移到了无关背景上。模型仿佛成了“睁眼瞎”,丢失了大量细节,注意力无处安放。
这清晰地解释了为何令牌减少后,模型在回答“图片里有什么”这类问题时容易出错——因为它根本没“看到”那些关键物体。
原来症结在此!那该怎么办?总不能为了效率而彻底牺牲精度吧。于是,本文的核心思想应运而生:我们不仅要压缩令牌,还要设法从这些被压缩的、信息残缺的令牌中,把丢失的视觉语义“恢复”出来!
妙招:频率调制视觉恢复(FMVR)
论文提出了名为 FMVR 的方法,全称是 频率调制视觉恢复。名字听起来很高大上,但其原理相当巧妙。
想象一下,将一张高清图片压缩成马赛克(令牌减少),丢失了大量细节。FMVR 就像一个智能“修复工具”,它不满足于马赛克本身,而是对这个压缩后的特征进行 “频率分析”。
在信号处理中,任何信息都可分解为低频(变化平缓的部分,如图像的整体轮廓、背景)和高频(变化剧烈的部分,如图像的边缘、纹理、细节)。压缩令牌时,最容易丢失的正是高频细节。
FMVR 所做的,就是从剩余的马赛克(压缩令牌)中,重新分离出“疑似”的低频和高频信息,然后用轻量级的、可学习的参数去调制(增强或抑制)它们,再将调整后的信息融合回去,让这些压缩后的特征显得“细节更丰富”。
这个FMVR模块被嵌入到前述的“套娃”学习框架中,构成了 FMVR-LLaVA。其整体架构一目了然:
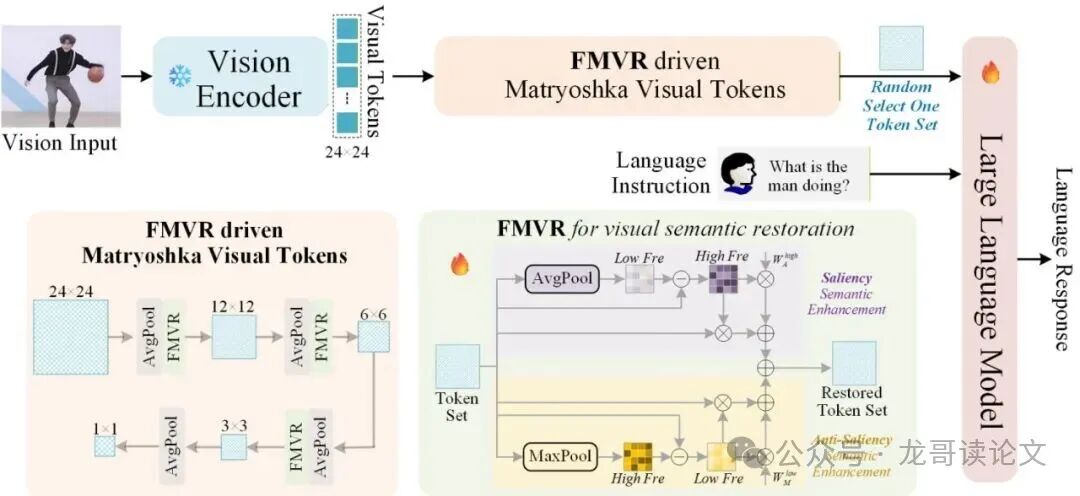
图:FMVR-LLaVA整体架构图。FMVR被注入到MRL中,用于在构建“套娃”式嵌套视觉令牌时,增强每一组令牌的视觉语义。
如图所示:原始图像经过视觉编码器(如CLIP),先得到 576 个令牌。随后通过一系列 2x2池化 操作,像金字塔一样逐步生成 144、36、9、1 个令牌,形成一个“套娃”集合。
关键之处在于:在每一次池化(令牌数量减少)之后,都会经过一个 FMVR 模块,对压缩后的令牌进行“语义恢复”。这样,每一档数量的令牌都得到了增强,再一同用于训练 LLM。在推理时,你可以根据实际算力,灵活选择使用 144 个、36 个甚至更少的令牌,同时性能更有保障。
原理拆解:AvgPool抓全局,MaxPool补细节
FMVR 的核心在于如何进行“频率分解”。论文采用了一种 双保险设计,包含两个并行的单元:AvgPool单元 和 MaxPool单元。
AvgPool单元:增强显著性语义
其思路如下:对压缩后的特征图 X 进行一次 平均池化。平均池化会“模糊”细节、保留整体趋势,因此其结果 $X_A^l$ 可被视为 低频分量(整体轮廓)。
那么,用原始特征 X 减去这个低频分量,得到的就是 高频残差 $X_A^h$,它代表了那些被平均池化“平滑掉”的细节和边缘。
$X_A^h = X - X_A^l$, $X_A^l = AP(X)$
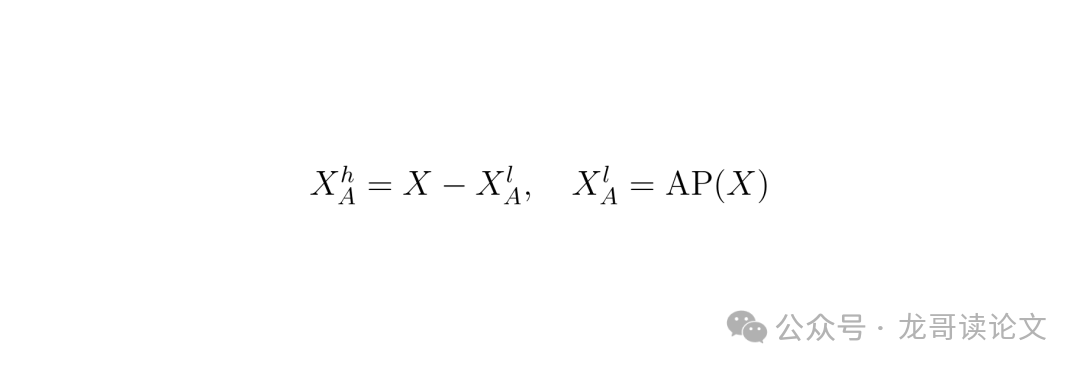
接着,用一个可学习的参数 $W_A^h$ 去调制这个高频分量,得到增强后的高频 $\hat{X}_A^h$。然后,巧妙的一步来了:将这个高频分量 本身作为一个注意力图,与原始特征 X 进行点乘,从而 激活那些细节丰富的区域。最后,将增强的高频和注意力加权后的特征相加,得到 AvgPool 单元的输出。
$\hat{X}_A = \hat{X}_A^h + X_A^h \cdot X$
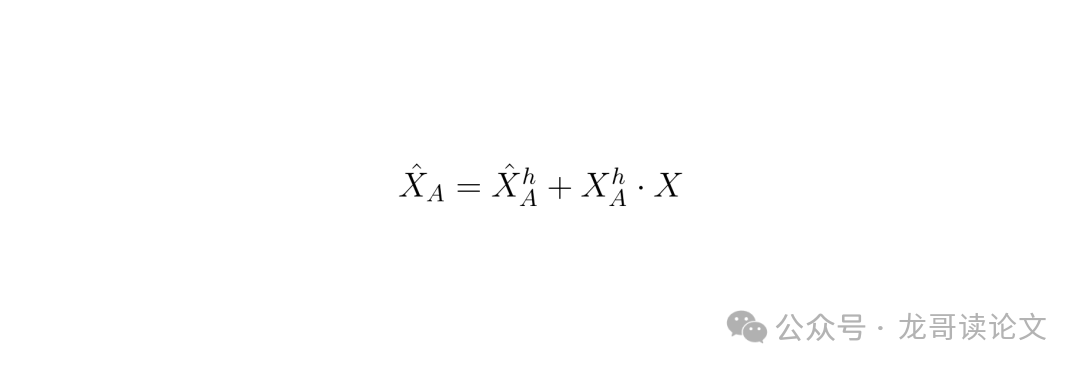
MaxPool单元:增强非显著性语义
只增强显著细节足够吗?可能不够。如果图片中存在一个特别醒目的大物体(例如画面中心的一头大象),AvgPool 单元可能会将所有注意力都集中于此,导致旁边的小鸟、花朵等“非显著”物体被忽略。
因此,需要 MaxPool单元 来扮演“补充者”的角色。最大池化 会保留局部最突出的特征,因此其结果 $X_M^h$ 可被视为 高频分量(最显著的部分)。
那么,用原始特征 X 减去这个“最显著”的高频,得到的就是 低频残差 $X_M^l$,它代表了那些 被“最强特征”所掩盖的、相对较弱的信息。
$X_M^l = X - X_M^h$, $X_M^h = MP(X)$
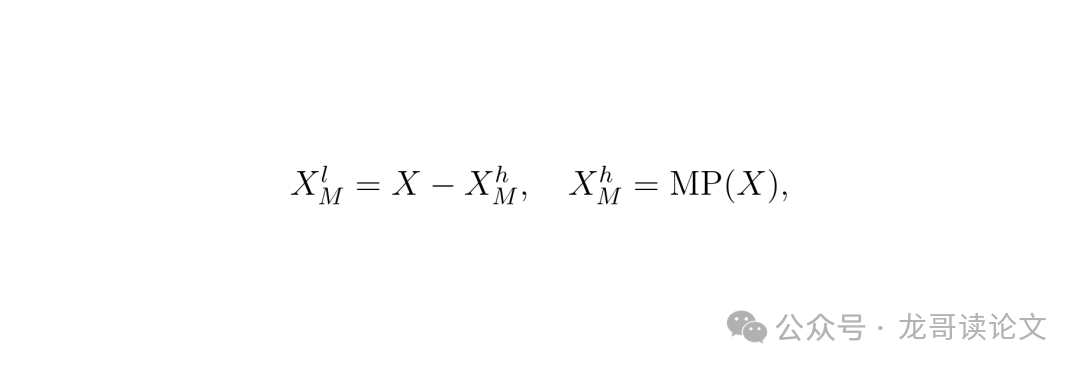
同样地,使用可学习参数调制这个低频分量,并将其作为注意力图去激活原始特征中被抑制的区域。这样一来,“红花”旁的“绿叶”也能被注意到了。
最后,将 AvgPool 单元和 MaxPool 单元的输出相加,就得到了经过 FMVR 恢复后的、语义更丰富的视觉特征。
这个设计非常精妙!它仅使用两种最基础的池化操作,通过“原始特征减去池化结果”这种简单的差分,就模拟出了频率分解的效果。一个负责把握大局、提升细节(AvgPool),一个负责弥补短板、关注弱项(MaxPool),双管齐下,构成了视觉语义恢复的“双保险”。
效果如何?精度几乎无损,速度提升数倍
理论听起来很美好,那么实际效果如何?论文在 10 个主流的图像理解基准上进行了全面测试。我们直接看最核心的对比结果:
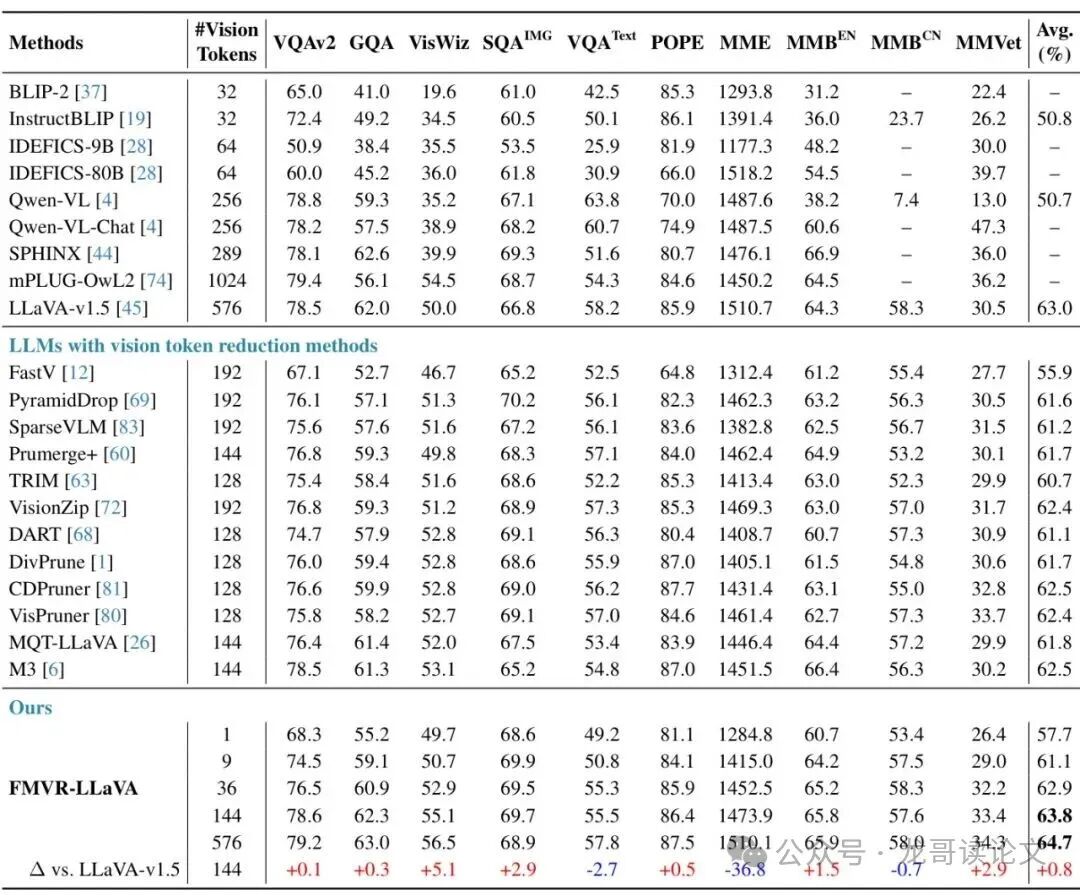
表:在10个图像基准上的性能对比(基于LLaVA-1.5-7B)。‘#视觉令牌’是视觉令牌数量。最后一行是与原始LLaVA的对比变化。
观察“Avg.(%)”平均性能这一列,重点对比:
- 惊人发现一: 原始的 LLaVA-1.5 使用 576 个令牌,平均性能为 63.0%。而 FMVR-LLaVA 仅使用 144 个令牌(减少了75%),平均性能竟达到了 63.8%,反超了0.8个百分点!这堪称“减肥”后反而变强了。
- 惊人发现二: 即使将令牌数大幅削减至仅 36 个(减少了94%),FMVR-LLaVA 的平均性能仍保持在 62.9%。这个成绩 超过了表格中所有其他视觉令牌削减方法(它们的令牌数通常在128或192个)。
再看具体的效率提升,数据更为震撼:
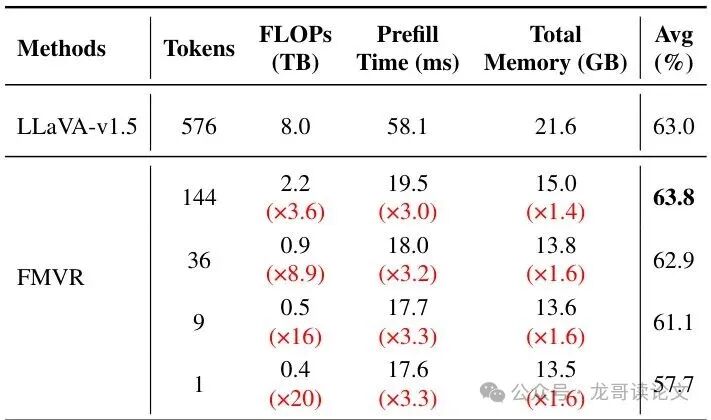
表:不同视觉令牌数量下的效率分析(基于LLaVA-1.5-7B)
当令牌数从 576 个减少到 36 个时:
- 计算量: 从 8.0 TB 降至 0.9 TB,减少了 89%!
- 内存占用: 从 21.6 GB 降至 13.8 GB。
- 平均性能: 几乎保持不变,仅从 63.0% 微降至 62.9%。
下面的折线图更直观地展示了在不同令牌数量下,FMVR 相比其他“套娃”方法的优势:

图:在不同视觉令牌数量下的对比。本方法在多种基准上取得了比M3和MQT-LLaVA更高的准确率。
图中四条曲线,代表 FMVR 的紫色实线在大部分令牌数量下都处于最高位置。这说明 FMVR 的语义恢复能力,确实让模型在令牌稀缺时表现更加稳健。
再看 Grad-CAM 的可视化对比,效果立竿见影:

图:有/无FMVR的Grad-CAM可视化和回答对比(36个视觉令牌)。
左侧是没有 FMVR 的模型,使用 36 个令牌观察一张室内场景图。热力图散乱,模型回答错误地声称看到了“a bed”(一张床)。
右侧是加入了 FMVR 的模型,同样使用 36 个令牌。热力图明显更集中在了沙发、餐桌、电视等实际物体上,回答也正确了。FMVR 让模型“重见光明”。
不止于图像:视频、高分辨率通吃
FMVR 的潜力不止于此。对于 高分辨率图像,令牌膨胀问题更为严重。论文在 LLaVA-NeXT(支持更高分辨率)上进行了测试:
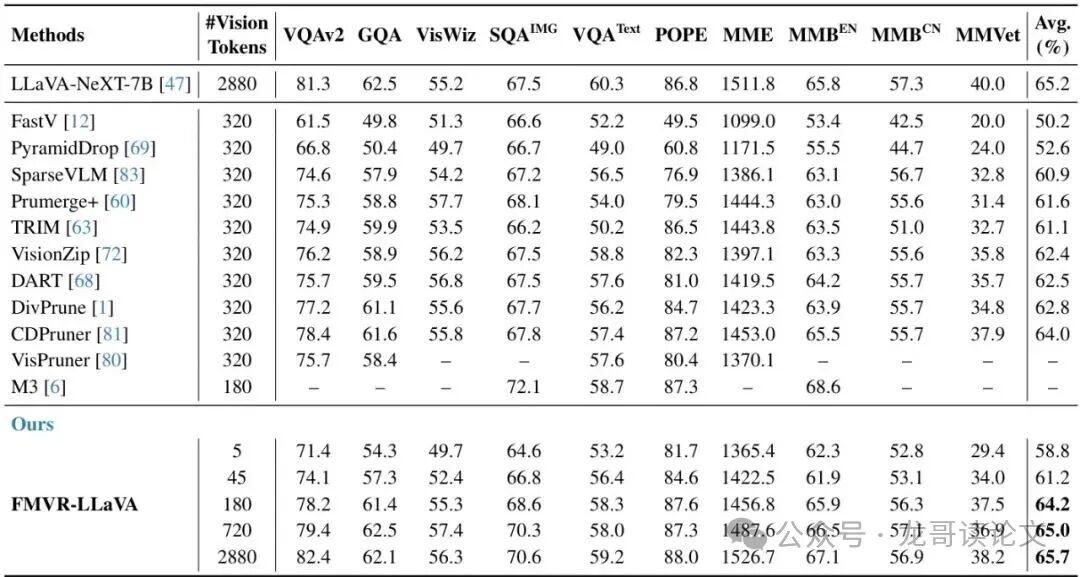
表:在LLaVA-NeXT-7B上的性能对比(高分辨率,10个图像基准)
原始 LLaVA-NeXT 使用 2880 个令牌(高分辨率),平均性能为 65.2%。FMVR-LLaVA 仅使用 720 个令牌(减少75%),就达到了 65.0%,几乎无差别!甚至仅使用 5 个令牌 的 FMVR,其性能也远超其他一些令牌削减方法。
对于 视频理解,帧数增多会导致令牌数量海量增长。论文在 4 个视频问答基准上进行了测试:

表:在LLaVA-NeXT-7B上的性能对比(4个视频基准)
FMVR-LLaVA 使用 180 个令牌(相比基线大幅减少),在视频问答平均准确率上,比一个强劲的基线方法 Video-LLaVA 高出 5.1 个百分点(63.5% vs. 58.4%)。这证明了 FMVR 在时序信息压缩上同样有效。
纵观一系列实验,FMVR 这种“抽脂增肌”的效果确实显著。它以极低的额外计算成本(FMVR 模块本身的 FLOPs 几乎可忽略不计),换来了在弹性令牌压缩下 惊人的精度保持和全面的效率提升。
技术概念解读
为了帮助大家更好地理解,这里解答几个可能存在的疑问:
1. 视觉令牌到底是什么?
可以将其想象成图片的“单词”。大语言模型原本是处理文本单词的。为了让 LLM 能“看懂”图片,需要先将图片转换成它熟悉的格式。视觉编码器(如 CLIP)把图片切分成许多小块,每一块经过编码变成一个向量,这个向量就是一个“视觉令牌”。LLM 就像阅读句子一样,按顺序“阅读”这些视觉令牌,结合文字问题来理解图片内容。
2. 频率调制在这里具体指什么?
这里的“频率”借用了信号处理的概念。简单来说,图像中变化平缓的部分(如大块色块、天空)是低频,变化剧烈的部分(如边缘、纹理)是高频。FMVR 并非进行真正的傅里叶变换,而是利用 AvgPool 和 MaxPool 这两种池化操作及其残差,来模拟和分离特征图中的低频与高频成分。“调制”则是用可学习的参数去调整这些分离出的成分的强度,该加强的加强(如丢失的细节),该抑制的抑制(如过于突出的物体),最后再融合回去,达到恢复和增强语义的目的。
3. 为什么FMVR看似简单却如此有效?
它的有效性建立在两个深刻的洞见之上:1) 令牌压缩的核心损失是高频细节,这通过 Grad-CAM 可视化得到了证实。2) 基础的池化操作是分离频率信息的有效代理。AvgPool 趋向于平滑(产生低频),其残差自然包含高频;MaxPool 趋向于抓取最显著特征(一种特殊高频),其残差则偏向被忽略的非显著信息(一种特殊低频)。通过这种巧妙的“差分”设计,再用轻量的可学习参数进行自适应调制,就能以极小的成本实现显著的语义恢复。方法简单,却直击要害。
总结与展望
这项研究为解决多模态大模型部署中的核心效率瓶颈——视觉令牌爆炸——提供了一个新颖、有效且通用的思路。FMVR 作为一种即插即用的语义恢复模块,其“频率调制”的思想很可能启发其他模态压缩或特征增强任务。
对于希望在保持模型精度的同时大幅提升推理效率的开发者而言,这项工作无疑提供了宝贵的开源实战参考。当相关代码开源后,将其集成到现有的多模态框架中将具有很高的实践价值。
本文仅代表个人理解及观点,不构成任何论文审核或者项目落地推荐意见,具体以相关组织评审结果为准。欢迎就论文内容交流探讨。想了解更多技术实现细节,可以访问 云栈社区 的人工智能版块进行深入交流。
参考文献:
Qingtao Pan, Zhihao Dou, Shuo Li. Frequency-Modulated Visual Restoration for Matryoshka Large Multimodal Models. arXiv preprint arXiv:2603.11220v1 (2026).
 发表于 2026-3-15 06:47:13
|
查看: 151|
回复: 0
发表于 2026-3-15 06:47:13
|
查看: 151|
回复: 0
