给AI一个“把牛变马”的指令,它如果只会去找马的视频,那它可能完全误解了“组合视频检索”(Composed Video Retrieval, CoVR)任务的真正挑战。实际上,用户的一句“让视频更浪漫”,背后隐藏的是光影、节奏、镜头语言等一系列复杂的视觉后果转换。当前许多主流方法像“关键词匹配师”,在需要深层因果推理的任务面前常常表现不佳。
今天,我们来深入解读一篇名为CoVR-R的论文,它提出了一种颠覆性的“先推理,后检索”范式,巧妙地利用一个参数冻结的大型多模态模型(LMM)作为“推理大脑”,在零样本设定下,性能全面超越了传统强监督方法。

在深入技术细节之前,我们先通过一张趣味漫画快速把握论文的核心思想。
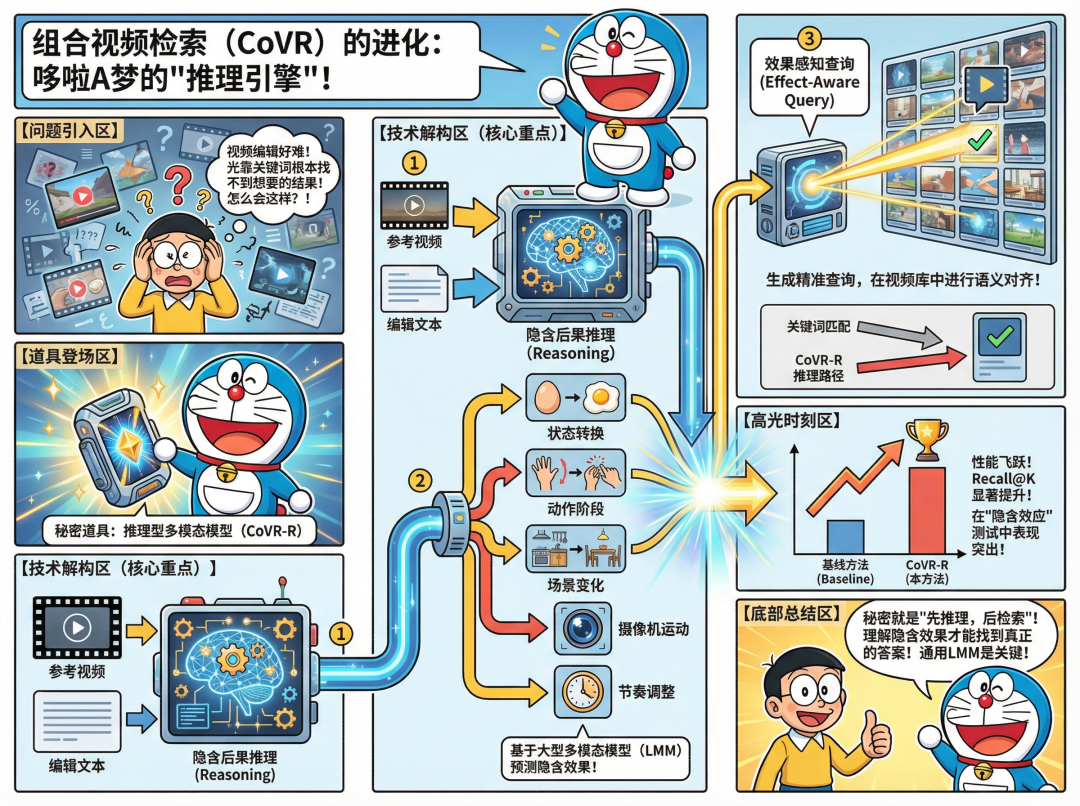
CoVR-R核心思想漫画解读
漫画虽有趣,但真正的技术内涵还需我们深入探究。接下来,让我们进入技术核心,看看它是如何实现这一突破的。
核心痛点:为什么传统方法在“组合视频检索”上频频翻车?
设想这样一个场景:你有一个参考视频,内容是“一头牛在吃草”。现在,你输入一条编辑指令:“将场景改为马在奔跑,背景是起伏的山丘。”
传统基于关键词匹配的模型会怎么做?它很可能会在视频库中机械地搜索同时包含“马”、“奔跑”、“山丘”这些关键词的视频。听起来似乎合理,对吧?
但问题恰恰出在这里。这条简单的编辑指令背后,隐藏着一连串未被明说的“视觉后果”:
- 状态转换:主体动物从“牛”变成了“马”。
- 动作变化:从相对静态的“吃草”变为动态的“奔跑”。
- 场景上下文:背景可能需要从平原变为有“起伏的山丘”。
- 镜头语言:“奔跑”可能意味着镜头需要跟随主体移动,或采用广角以展现山丘全景。
- 节奏感:视频的整体节奏和剪辑风格会从舒缓变得急促。

图:CoVR视频编辑任务中的复杂推理需求。仅匹配关键词(如“钢琴”)无法找到正确的目标视频(绿色框),必须依赖对状态、镜头、时序的深层推理。
如上图所示,仅仅匹配“钢琴”这个词,可能会返回任何包含钢琴的视频。但真正的目标视频,需要模型推理出“从单人演奏变为四手联弹”,这背后涉及人物数量、手部动作的协调性、镜头可能需要更紧凑等一系列隐含变化。传统方法在这里就像个“直男”,只懂字面意思,无法理解“弦外之音”。
这不仅是技术瓶颈,更是评估体系的缺失。现有的基准数据集大多奖励关键词重叠,而非模型的推理能力。因此,该论文首先构建了一个全新的基准——CoVR-R,专门用来评估和“拷问”模型的推理能力。

图:CoVR-R基准数据集的样本示例。每个样本不仅提供输入视频、编辑指令和目标视频,还提供了详细的“推理过程”标注,明确指出了编辑引发的状态、场景、光影等复杂变化。
这个数据集包含了带有结构化推理标注的(参考视频,编辑文本,目标视频)三元组,并精心设计了难以通过关键词区分的“困难负样本”。它的存在,就是为了回答一个根本问题:你的模型,到底是在“匹配文字”,还是在“理解意图”?
那么,如何让模型学会“理解意图”并进行有效推理呢?这就是CoVR-R方法的核心贡献。
架构解析:两段式“推理-检索”流水线
CoVR-R的整体架构清晰而优雅,它没有选择为任务从头训练一个模型,而是巧妙地利用了一个现成的、强大的多模态大模型—— Qwen-VL 作为其“推理引擎”。整个流程分为泾渭分明的两个阶段,如下图所示。
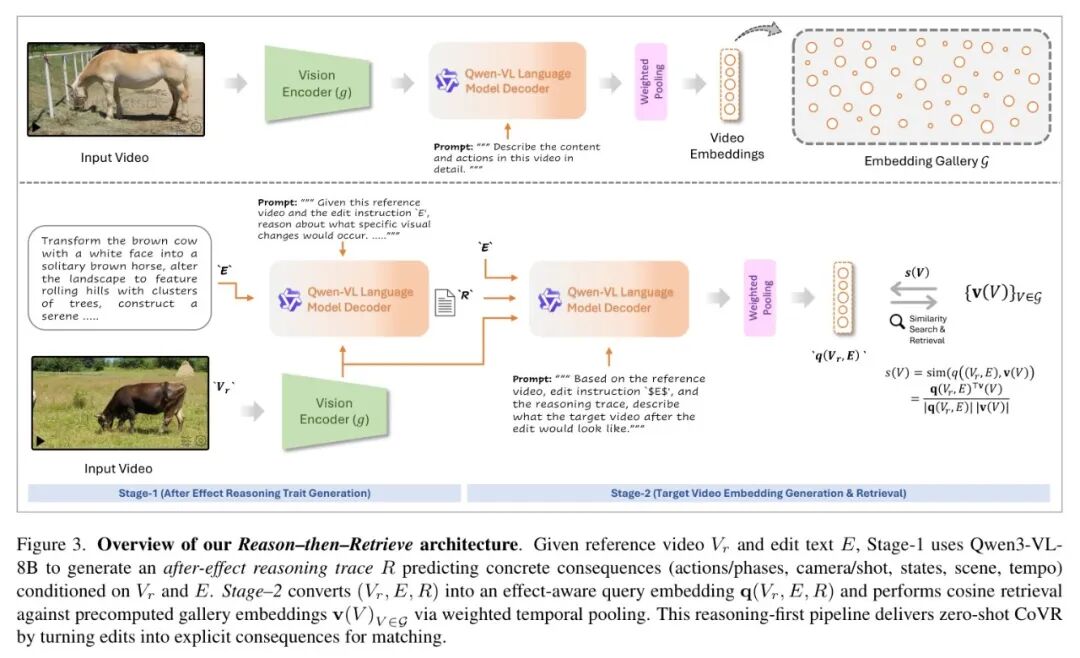
图:Reason-then-Retrieve 核心架构。Stage-1 利用Qwen-VL生成结构化推理轨迹;Stage-2 将推理、指令、参考视频结合,生成“效果感知”的查询嵌入,并从预计算的嵌入库中检索目标视频。
这个“先推理,后检索”的范式,是全文的灵魂所在。它不再试图让模型在特征空间里盲目地融合文本和视觉信息,而是先用自然语言“想清楚”编辑会导致什么结果,再把这个“思考结果”作为更精准的查询指令。下面我们拆解每个阶段的核心设计。
核心创新点一:结构化“后效推理”生成
第一阶段的目标是:给定参考视频 V_r 和编辑文本 E,生成一个结构化的推理轨迹 R*。
这可不是让模型随便写一段小作文。论文通过精心设计的 Prompt,引导 Qwen-VL 生成一个高度结构化、涵盖五个关键维度的推理记录:
- States(状态):物体或场景的可见状态变化(如“生的→熟的”、“空的→满的”)。
- Actions(动作):核心动作或阶段的变化(如“切菜→翻炒”、“走路→奔跑”)。
- Scene(场景):背景、环境、光照的整体变化。
- Camera(镜头):构图、视角、镜头运动(如“远景→特写”、“固定镜头→跟拍”)。
- Tempo(节奏):视频速度、节拍的变化。
这个过程的价值在于“显式化”。它将模型内部模糊的“理解”,外化成一条条可检查、可验证的断言。例如,对于“让视频更浪漫”的指令,推理轨迹可能输出:镜头:从快速剪辑变为慢镜头;场景:添加暖色调滤镜和星光效果;节奏:整体变慢。这就把主观的“浪漫”,转化成了客观的、可检索的视觉特征描述。
实战思考:这种结构化输出不仅利于检索,更重要的是带来了可解释性。如果检索失败,我们可以直接检查是哪个维度的推理出了错,是没理解状态变化,还是漏掉了镜头提示?这为模型调试和迭代提供了清晰的路标。
核心创新点二:推理感知的查询嵌入生成
有了推理轨迹 R*,第二阶段的任务是:生成一个融合了 V_r、E 和 R* 的、富含语义的查询嵌入 q(V_r, E, R*)。
具体操作非常巧妙:
- 目标描述生成:将参考视频、编辑文本和刚生成的推理轨迹 R* 一起,再次输入给 Qwen-VL,通过 Prompt 要求它:“基于以上信息,描述一下编辑后的目标视频应该是什么样子?” 这会生成一段详细的文本描述 T_tgt。
- 重要性加权池化:从 Qwen-VL 的最后一层提取 T_tgt 中每个 token 的嵌入向量 {h_i}。关键来了:不是简单地求平均,而是根据词性进行重要性加权。
其中,权重 w_i 遵循一个简单却有效的规则:对动作动词、物体名词(如“奔跑”、“山丘”)赋予高权重;对描述性形容词赋予中权重;对“的”、“在”等功能词赋予低权重。
这个设计的直觉是什么? 就好比你在用搜索引擎时,会把核心关键词加粗。加权池化就是在嵌入空间里做同样的事,强化关键语义信号的贡献,弱化语法功能词的噪声,让生成的查询嵌入 q(V_r, E, R*) 的“语义纯度”更高,从而在人工智能驱动的检索任务中表现更佳。
推理流程:轻量高效的检索匹配
至此,我们手上有两样东西:
- 一个针对当前查询生成的、推理感知的查询嵌入 q(V_r, E, R*)。
- 一个离线预计算好的视频嵌入库 {v(V)}。库中每个视频的嵌入,也是通过同样的 Qwen-VL 描述生成 + 重要性加权池化得到的。
检索过程变得极其简单和快速:计算查询嵌入 q(V_r, E, R*) 与库中所有视频嵌入 v(V) 的余弦相似度,然后按相似度排序即可。
整个流程的妙处在于“零样本”和“高效”。强大的 Qwen-VL 模型全程参数冻结,不进行任何针对 CoVR 任务的微调。它只作为通用的“描述生成器”和“推理器”被调用。所有针对检索任务的“适应性”,都通过 Prompt 工程和池化策略来体现。推理阶段虽然涉及两次 LLM 生成,但都是轻量级的文本生成;检索阶段则是简单的向量相似度计算,效率极高。
实验验证:数据证明“推理”的价值
理论再优美,也需要数据支撑。CoVR-R 在两个基准上进行了全面测试:其自建的、强调推理的 CoVR-R 数据集,以及大规模的 Dense-WebVid-CoVR 数据集。结果令人印象深刻。
首先,在需要强推理的 CoVR-R 数据集上,传统方法集体“翻车”。
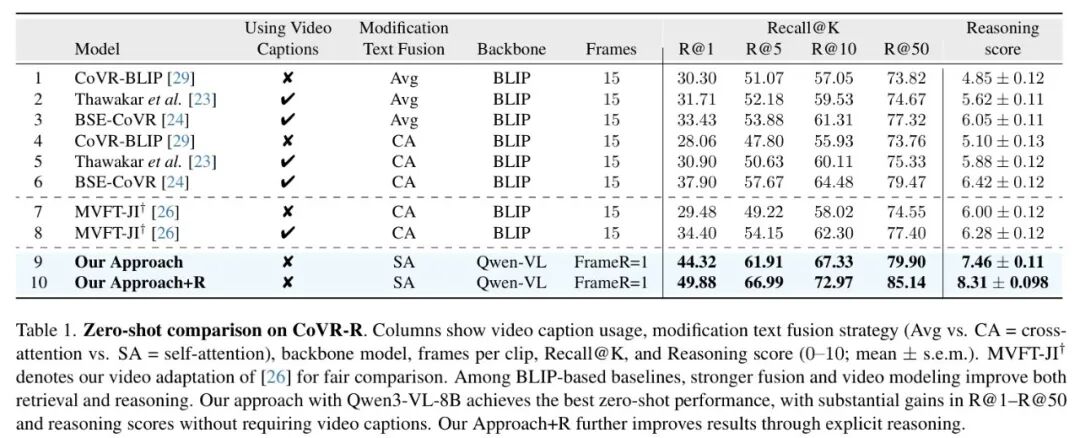
表1:在CoVR-R基准上的零样本性能对比。Our Approach(无推理)已显著超越基线,而加入显式推理(+R)后,在R@1和推理分数上进一步提升。
如表1所示,之前的 SOTA 方法(如 BSE-CoVR)在需要推理的数据集上,R@1 平均只有 32% 左右。而 CoVR-R 的基础版本(不加显式推理模块) 凭借 Qwen-VL 强大的多模态能力,直接将 R@1 提升到 44.32%,相对提升显著。
当启用显式推理模块后,性能进一步提升至 49.88%,并且获得了高达 8.31 的推理分数(满分10分)。这5.56个百分点的绝对提升,就是“显式推理”带来的纯收益,清晰证明了“先想清楚再找”这条路径的有效性,也体现了深度学习模型在复杂语义理解上的潜力。
其次,在标准的大规模数据集 Dense-WebVid-CoVR 上,CoVR-R 同样展现了强大竞争力。
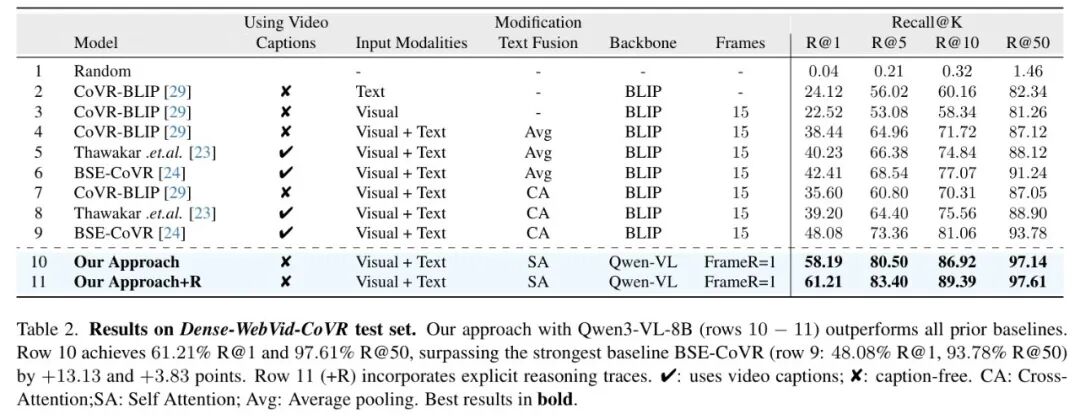
表2:在Dense-WebVid-CoVR测试集上的性能对比。CoVR-R(零样本,无字幕)在R@1上大幅超越所有需要视频字幕或特定训练的基线方法。
如表2,在不需要强推理也能取得不错成绩的标准数据集上,CoVR-R 的零样本方法依然取得了 58.19% 的 R@1,远超需要额外视频字幕作为监督的最强基线 BSE-CoVR(48.08%)。加入推理后,R@1 进一步提升至 61.21%。这充分说明,推理能力并非“偏科”,而是能普遍提升检索性能的“硬通货”。
消融实验:每一个设计都经得起推敲
为什么加权池化比平均池化好?模型是不是越大越好?迭代推理有用吗?论文通过一系列消融实验,给了我们扎实的答案。
1. 模型规模越大越好吗?是的,但架构也重要。
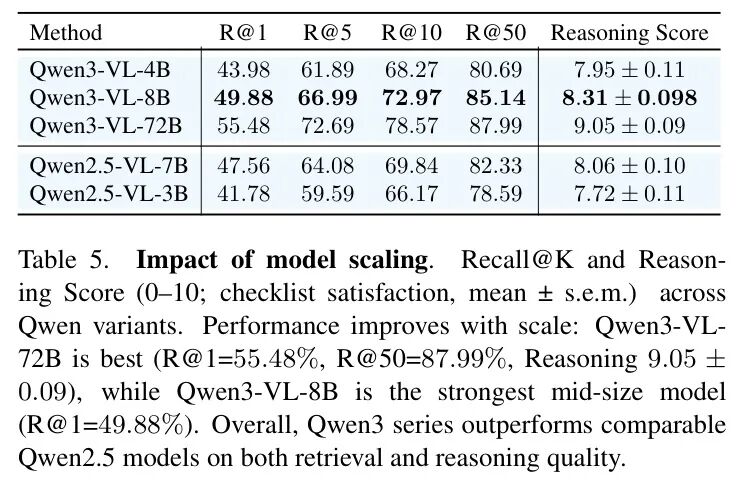
表5:模型规模对性能的影响。Qwen3-VL系列性能随参数增长而稳定提升,且同规模下优于Qwen2.5-VL系列。
如表5所示,从 4B 到 72B,模型性能(R@1 和推理分数)随着参数规模增长而持续提升。同时,同参数级别下,新一代的 Qwen3-VL 架构全面优于 Qwen2.5-VL。这说明:第一,“力大砖飞”定律在需要复杂语义理解的检索任务上依然有效;第二,模型架构的进步(如更优的视频理解、更长的上下文)能带来实打实的增益。
2. 迭代精炼推理有用,但性价比不高。
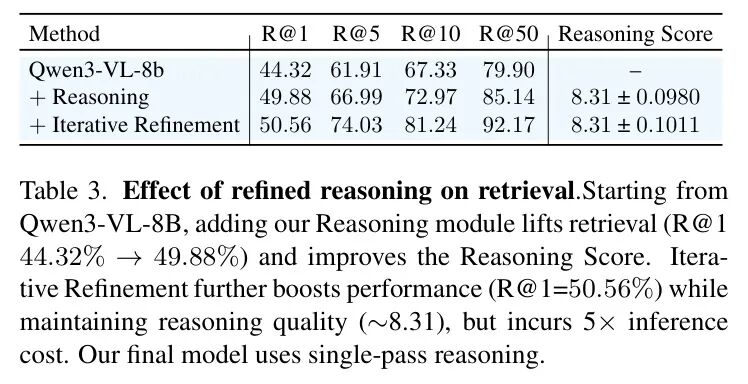
表3:推理模块与迭代精炼的消融实验。添加推理模块带来显著提升,但迭代精炼带来的额外收益有限,且计算成本激增。
如表3,相比基础模型,添加单次推理模块能将 R@1 从 44.32% 提升至 49.88%,这是巨大的飞跃。如果进行多轮迭代精炼(让模型自我修正推理轨迹),R@1 能再提升约 0.7%,达到 50.56%。然而,这微弱的提升却需要付出 5 倍的推理成本。因此,论文最终选择了性价比最高的单次推理方案。这是一个非常工程化的务实决策。
3. 加权池化:简单策略,显著收益。
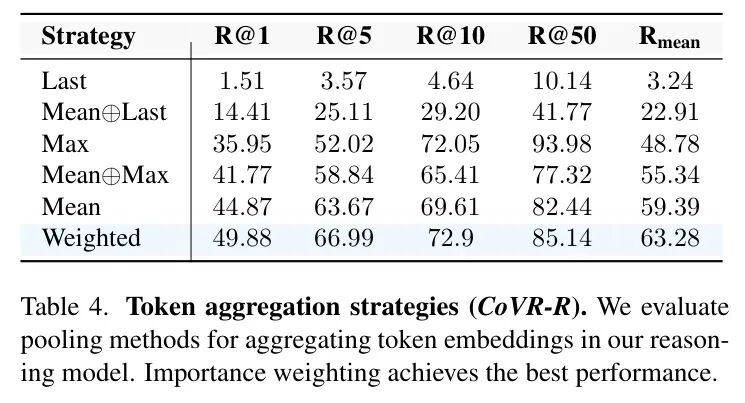
表4:不同token聚合策略的消融实验。重要性加权池化策略在所有召回率指标上均取得最优结果。
如表4,论文对比了多种池化策略。取最后一个 token(Last)效果灾难,均值池化是一个强基线。但简单的、基于词性的重要性加权池化策略,在 R@1 上比均值池化高出超过 5 个百分点(相对提升11.2%),全面领先。这证明,在生成式模型的时代,从语言模型中“抽取”嵌入时,语义筛选至关重要,不能把所有的词都平等对待。
客观评价与未来展望
优势总结:
- 范式创新:“先推理,后检索”的框架清晰有力,将复杂的多模态对齐问题,分解为可解释的推理生成和高效的语义匹配两个阶段。
- 零样本能力强:充分利用现成大模型的涌现能力,无需任何任务特定标注和微调,降低了应用门槛。
- 可解释性:结构化的推理轨迹为检索结果提供了“理由”,让黑箱模型变得透明,这在实用中价值巨大。
- 效率与性能平衡:尽管使用了大模型,但通过冻结参数、离线计算嵌入库,检索阶段极其高效。
局限性与挑战:
- 依赖大模型能力:整套流程的上限受限于所选 LMM(如 Qwen-VL)的视觉推理和描述生成能力。如果它“看不懂”视频或“说不清”变化,后续检索无从谈起。
- 对超具体指令敏感:论文在失败案例分析中指出,当编辑指令包含一长串极度细致、零碎的修改要求时,模型可能无法在推理轨迹中完整捕捉所有细节,导致检索偏差。
- 计算成本:虽然检索快,但为每个查询生成两次文本描述(推理+目标描述)的成本依然高于传统单次前向传播的方法,在超大规模、低延时场景下需权衡。
未来方向:
论文在结尾也暗示了有趣的未来工作:自适应推理。不是所有查询都需要深度推理。未来系统可以学习一个“路由控制器”,自动判断当前编辑指令的复杂度。对于简单的“关键词匹配”型指令,走轻量级快速通道;对于复杂的、隐含后果多的指令,才启动完整的“推理-检索”流水线。这将是迈向更智能、更高效视频检索系统的关键一步。
价值升华与行动号召
回顾全文,CoVR-R 给我们带来的启示远不止一个SOTA模型:
- 重新思考任务定义:它告诉我们,组合视频检索的本质不是“文字找画面”,而是“意图理解与视觉化”。这一定义的升维,打开了新的技术思路。
- 大模型应用的新范式:它展示了如何将通用大模型作为“技能模块”(这里是推理器和描述器),通过精巧的流程设计和接口设计(结构化 Prompt),来解决特定领域问题,避免“拿着锤子找钉子”式的蛮力微调。
- 评估驱动创新:没有CoVR-R这个强调推理的新基准,就很难凸显传统方法的局限和新方法的优势。构建好的评测体系,本身就是推动领域前进的重要力量。
CoVR-R的工作展示了将高级语义推理与高效检索相结合的巨大潜力。对于开发者而言,理解这种“先推理,后执行”的范式,或许能为解决其他复杂的多模态任务提供新的思路。想了解更多关于前沿AI技术、大模型应用与实践的深度讨论,欢迎持续关注云栈社区。
 发表于 2026-4-5 09:49:34
|
查看: 144|
回复: 0
发表于 2026-4-5 09:49:34
|
查看: 144|
回复: 0
