在文档智能领域,传统的“检测-识别-理解”多阶段流水线(Pipeline)架构正面临挑战。复杂的文档形态、误差累积以及部署维护的复杂性,促使行业寻求更统一、高效的解决方案。近日,百度千帆平台正式发布了全新的端到端文档智能模型Qianfan-OCR,其基于统一的视觉语言架构,以约4B参数规模,实现了从文档解析、版面分析到文字识别与语义理解的全栈融合,标志着文档智能能力正从“流程拼接”迈入“模型统一”的新阶段。
一体化架构下的性能突破
Qianfan-OCR的核心优势在于其端到端的设计。该模型无需依赖多个独立模型的串联,能够直接从文档图像生成结构化结果,实现了从“看见”到“理解”的一步到位。这种转变带来的直接好处是性能的显著提升。
在权威基准测试中,Qianfan-OCR的表现尤为亮眼:
- 在 OmniDocBench v1.5 综合评测中,取得了 93.12 的高分,在端到端模型中位列第一,其成绩甚至超过了部分传统多阶段(Pipeline)的专用OCR系统。
- 在针对模型图表理解能力的 ChartQA、ChartBench 等关键评测中,Qianfan-OCR同样表现领先,在6项相关任务中拿下了5项最佳成绩。
这充分证明了统一模型在复杂结构理解与多模态推理上的能力优势。传统Pipeline在文本提取过程中,往往会丢失元素间的空间结构与视觉上下文信息,从而限制了其对图表、复杂表格等文档的理解深度。而端到端模型能够完整保留并利用这些视觉信息,使得其在结构理解与推理任务中具备更高的一致性与准确性。
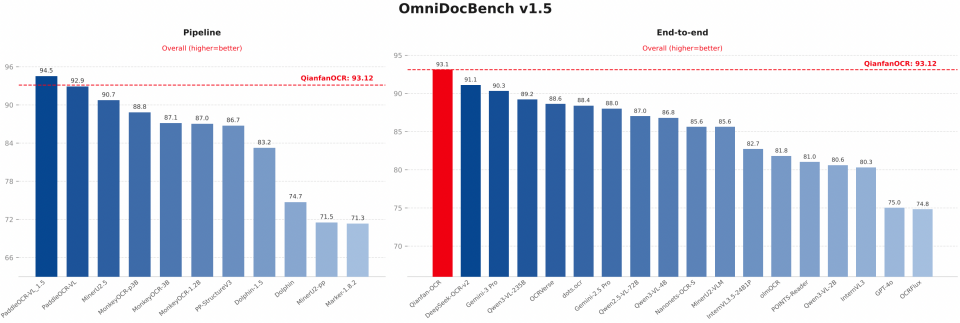
图为OmniDocBench v1.5基准测试结果,Qianfan-OCR在端到端模式(右图)下表现领先。
核心创新:Layout-as-Thought机制
当然,从Pipeline转向端到端并非没有挑战。一个核心问题在于,传统Pipeline中显式的版面分析能力在端到端模型中如何实现?为了解决这一问题,Qianfan-OCR引入了创新的 “Layout-as-Thought” 机制。
在生成最终输出之前,模型会通过一个特殊的 <think> token进入“思考阶段”。在这个阶段,模型首先对文档的结构进行显式建模,生成包括元素位置、类型以及阅读顺序在内的结构化布局信息,然后再基于这些“先验理解”完成整体的解析与输出。这一设计巧妙地将版面理解能力内化为模型推理过程的一部分,在统一的框架下同时赋予了模型结构感知与语义理解的能力。
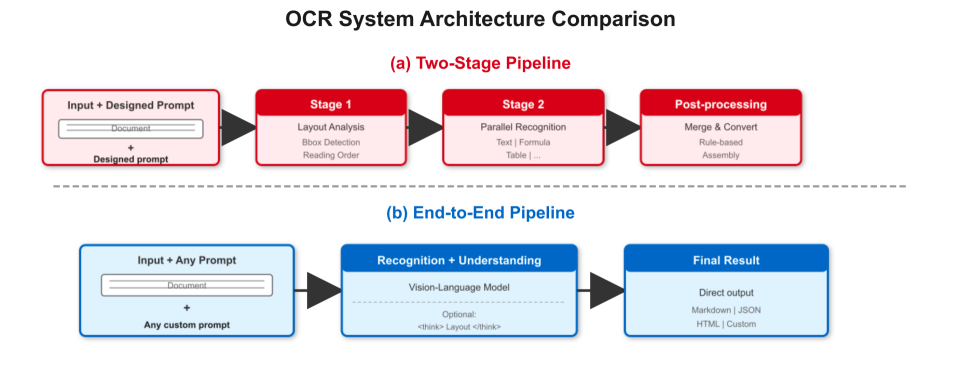
图为两阶段Pipeline(a)与端到端(b)架构对比示意图。端到端路径更短,由统一的视觉语言模型直接输出结果。
因此,在面对多栏排版、复杂表格或非标准阅读顺序等挑战性场景时,Qianfan-OCR展现出了更强的鲁棒性和解析一致性。这不仅提升了准确性,也从本质上简化了技术链路。
显著提升的部署与运行效率
除了性能优势,Qianfan-OCR在部署和运行效率上也带来了显著的改进。传统Pipeline系统通常需要CPU进行检测、GPU进行识别、再调用大语言模型(LLM)进行理解的异构编排,资源调度复杂。
相比之下,Qianfan-OCR作为一个统一的视觉语言模型,部署时只需一个vLLM实例。根据官方数据,在单张A100 GPU上,使用W8A8量化后,吞吐量可达 1.024页/秒,极大地简化了生产环境的部署复杂度并提升了资源利用率。对于希望快速集成文档智能能力到现有系统中的开发者而言,这无疑降低了门槛。你可以在 GitHub 上找到相关的开源实现与集成案例。
资源获取与体验
目前,Qianfan-OCR模型已正式上线百度千帆平台,并向开发者和企业用户开放使用。同时,其模型权重也已同步在ModelScope和HuggingFace开源,体现了百度在推动人工智能技术进步与开放协作方面的努力。
为了方便社区开发者快速上手与应用,项目团队还在GitHub上发布了配套的“Skills”(技能工具),用户可轻松下载并集成,实现多样化的文档转化与理解任务。
相关资源链接:
- 论文地址:
https://arxiv.org/abs/2603.13398
- ModelScope模型:
https://modelscope.cn/models/baidu-qianfan/Qianfan-OCR
- GitHub主仓库:
https://github.com/baidubce/Qianfan-VL
- 配套Skills:
https://github.com/baidubce/skills/tree/develop/skills/qianfanocr-document-intelligence
- 千帆平台体验:
https://console.bce.baidu.com/qianfan/modelcenter/model/buildIn/detail/am-52d29fea1063
范式演进:从工具到系统能力
Qianfan-OCR的发布,不仅是单一模型能力的升级,更代表了文档处理技术路径的一次重要演进:从多模型拼接的流程式架构,走向统一建模的端到端范式。这使文档智能从一种“工具能力”演进为更完整的“系统能力”,为企业级应用提供了更高效、稳定且易于维护的技术文档基础。
对于开发者社区而言,关注此类前沿模型的进展与落地,是把握技术趋势、提升解决方案竞争力的关键。未来,随着多模态模型在产业场景中的持续深入,类似的端到端、统一化技术路线有望在更多领域释放价值。想了解更多AI与云计算领域的前沿动态与技术实践,欢迎关注 云栈社区 的相关讨论。
 发表于 2026-3-20 05:24:38
|
查看: 183|
回复: 0
发表于 2026-3-20 05:24:38
|
查看: 183|
回复: 0
