随着大语言模型(LLM)的上下文长度不断增长,标准的 Softmax Attention 所固有的二次计算复杂度,正日益成为推理与部署过程中的结构性瓶颈。
尤其在预填充(prefill)阶段,其计算开销与显存占用会随着序列长度呈平方级增长,直接导致模型吞吐量下降与部署成本急剧上升。在此背景下,“如何线性化预训练好的大语言模型”成为了实现高效长上下文推理的关键研究方向。
近日,哈尔滨工业大学(深圳)张正团队联合鹏城实验室、昆士兰大学 UQMM Lab 以及华为技术有限公司,共同提出了业界首个能够在同层混合注意力范式下系统性恢复长上下文能力的框架——STILL。该方法彻底颠覆了以往主流的层间混合范式,仅用 0.04B 的训练令牌(token)就实现了大语言模型的线性化,显著改善了同层混合方案在长上下文建模中的性能退化问题,并在特定长序列任务上实现了最高 86.2% 的精度提升。

论文标题:STILL: Selecting Tokens for Intra-Layer Hybrid Attention to Linearize LLMs
论文链接:https://arxiv.org/abs/2602.02180
作者团队:哈尔滨工业大学(深圳)SMULL Group、鹏城实验室、昆士兰大学UQMM Lab、华为技术有限公司
论文作者:Weikang Meng, Liangyu Huo, Yadan Luo, Jiawen Guan, Jingyi Zhang, Yingjian Li, Zheng Zhang
层间混合的瓶颈与STILL的破局思路
目前,行业主流的混合注意力方案普遍采用层间混合策略,即在多数层中使用线性注意力(LA)进行加速,仅在间隔的少量层中保留标准注意力(SA)以弥补全局信息。
然而,这种策略存在一个根本性问题:那些对全局理解至关重要的证据和长程关联,很可能在前序的多层线性注意力(LA)的压缩与近似过程中被不可逆地削弱甚至丢失。等到后续插入标准注意力(SA)层时,为时已晚,难以恢复,最终导致模型的长上下文理解能力崩塌。
而现有的一些同层混合方案,则往往过度依赖基于位置的滑动窗口路由,难以有效覆盖长序列中分散各处的关键证据。
STILL 创新性地跳出了“按层补救”的传统思路,选择在每一层内部并行两条处理分支:
- 关键Token走SA:基于内容感知,筛选出少量的关键令牌,使用标准的 Softmax Attention 进行精确的全局建模。
- 其余Token走LA:剩余的大量令牌则通过线性注意力进行高效的线性汇聚。
这种“每层保关键、整体保效率”的设计,从根本上避免了关键信息在早期层中被提前丢失,从而成为首个能在同层混合范式下系统性恢复长上下文能力的方案。
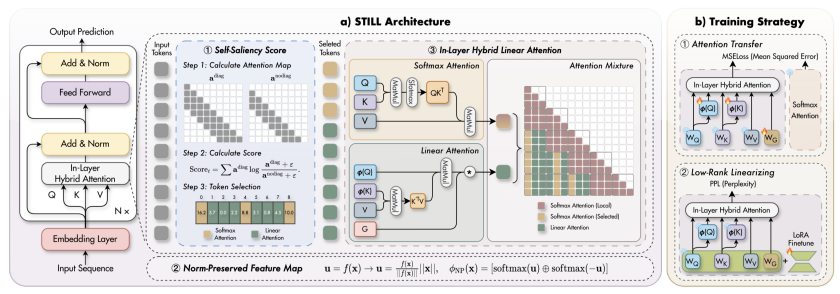
STILL三大核心技术:精准路由、特征保留与高效并行
1. Self-Saliency Score:用局部计算评估全局重要性
传统的路由机制往往需要依赖全局注意力计算($O(N^2)$ 复杂度)来判断令牌重要性,这本身就违背了线性化的初衷。
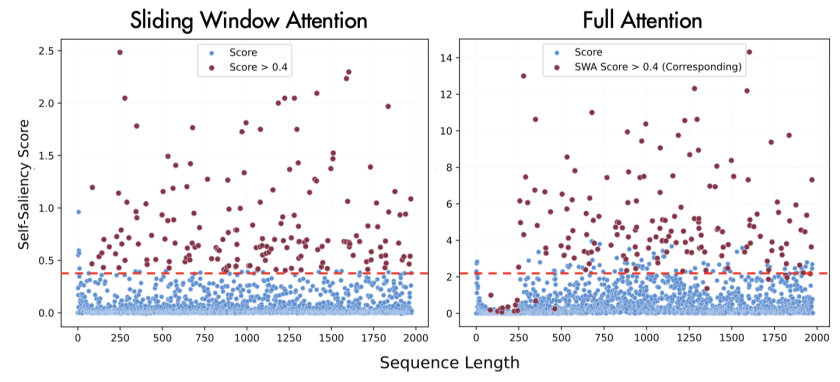
STILL 提出了 Self-Saliency Score(自显著得分)机制。其核心思想是:仅利用滑动窗口内的局部注意力计算,就能有效评估当前令牌对于整个全局上下文的重要性。
具体而言,该方法通过对比“包含自身对角线”与“不包含自身对角线”的滑动窗口注意力分布,来计算一个令牌对自身注意力的敏感度。敏感度越高的令牌(例如逻辑连接词、关键论点或长程指代信息),越可能是在全局上下文中扮演核心角色的令牌。
最终,STILL 实现了仅用局部滑动窗口计算,就能达到接近全局注意力机制的令牌筛选准确率,为同层混合提供了精准且低开销的路由基础,彻底摆脱了基于固定位置路由的局限性。
下图展示了自显著得分在滑动窗口注意力与全注意力下的分布一致性,验证了其局部-全局评估的有效性。
2. Norm-Preserved Feature Map (NP-Map):保留预训练模型的“力度感”
预训练大模型的 Softmax Attention 对令牌向量的模长(Norm,表征信息强度)高度敏感。一个基本规律是:越重要的令牌,其向量模长往往越长。
然而,此前的几乎所有线性化方案,都会通过 MLP 等结构无差别地缩放向量模长,这直接导致预训练模型中习得的注意力分布严重失真,引发性能断崖式下跌。对于同层混合方案,这个问题尤为致命:SA 和 LA 两个分支如果在同一层内的特征分布不一致,将直接导致模型能力崩塌。
STILL 通过 Norm-Preserved Feature Map (NP-Map) 解决了这一难题。其关键创新在于解耦特征向量的方向与模长,强制线性注意力分支“继承”预训练模型中的模长信息:
$$
u = f(x) \rightarrow u = \frac{f(x)}{\|f(x)\|}, \quad \phi_{NP}(x) = [\text{softmax}(u) \oplus \text{softmax}(-u)]
$$
这让线性注意力能够完美保留预训练模型的注意力“力度感”,实现了 SA 与 LA 分支间的无缝融合,从根源上避免了因线性化带来的性能失真。
3. Chunk-Wise并行与延迟选择:拥抱硬件的高效实现
如果进行逐令牌(Token-Level)的路由决策,会导致计算并行度低,硬件利用率差。
为此,STILL 针对性提出了 Chunk-Wise 分块并行方案:
- 训练/预填充阶段:将长序列切分为块(Chunk),在每个块内部统一计算自显著得分并批量筛选关键令牌,然后整批送入 SA 或 LA 分支进行并行计算。
- 解码阶段:采用 Chunk 粒度的延迟选择策略,避免逐令牌计算带来的效率损耗。
这一设计在保证同层混合精度的同时,实现了真正的线性计算复杂度,并且完全适配现代 GPU 等硬件的并行计算特性,让理论创新得以走向工程实践。其总体复杂度可概括为:
$$
O(Nmd) + O((N - m)dd’) + O(T \log(C)) = O(N) \quad (\text{Total})
$$
实验结果:全面领先,逼近全注意力性能
STILL 在常识推理、长上下文理解以及推理效率三大维度上均表现出了显著优势。
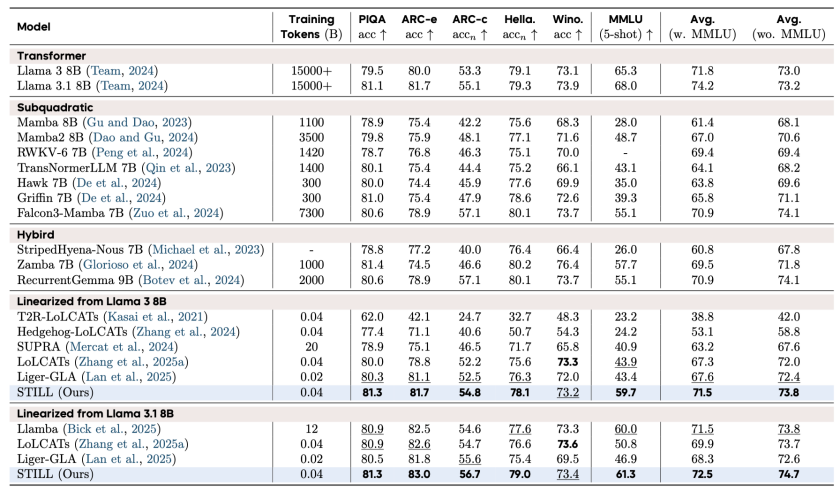
✅ 常识与推理任务:性能超越现有线性化基线
以 Llama 3.1 8B 为基座模型,STILL 仅使用 0.04B 训练令牌,便在 MMLU(5-shot)基准上达到了 61.3% 的准确率,远超 Liger-GLA 的 46.9%,平均性能领先主流同层混合方案 LoLCATs 约 4.5%。
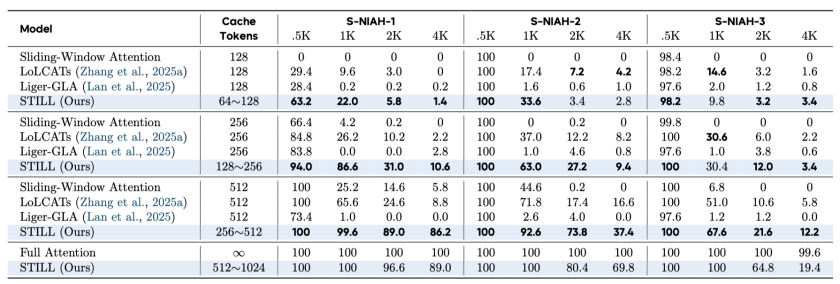
✅ 长上下文任务:恢复率超过85%,逼近全注意力模型
在 RULER 基准的 S-NIAH 长上下文任务(4K 上下文)上,STILL 在相同的缓存令牌数设置下,取得了 86.2% 的准确率,而作为对比的滑动窗口注意力基线仅为 8.8%,性能恢复率极高,已非常接近全注意力模型的性能上限。
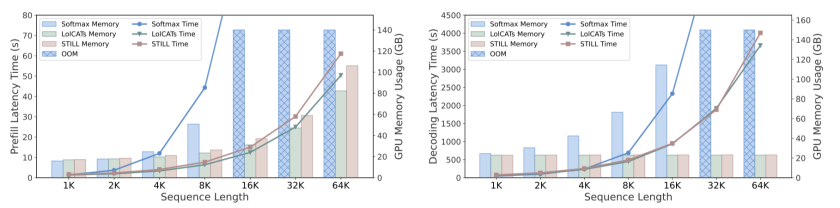
✅ 效率优势显著:内存大幅降低,支持超长序列推理
- 预填充阶段:当序列长度达到 64K 时,STILL 的内存占用仅为标准 Softmax Attention 的 20%。
- 解码阶段:STILL 能够在不发生内存溢出(OOM)的情况下完成 64K 长序列的批量推理,其解码延迟相比基线方法降低了 28%。
下图清晰展示了 STILL 在预填充延迟和解码延迟/内存占用上相对于基线方法的巨大优势。
总结与展望
STILL 通过创新的同层混合注意力架构,结合内容感知的令牌选择、模长保留的特征映射以及硬件友好的分块并行策略,成功打破了层间混合范式的性能瓶颈。实验证明,该框架能够以极低的训练成本(0.04B tokens)实现大语言模型的高效线性化,在保持强大常识与推理能力的同时,显著恢复并提升了模型的长上下文处理性能,且具备优异的推理效率。
这项研究为下一代高效、长上下文大语言模型的设计提供了新的思路和强有力的技术支撑。对Transformer架构的线性化优化感兴趣的研究者与工程师,可以在云栈社区的人工智能板块找到更多相关的深度讨论与技术资源。
 发表于 2026-3-22 02:56:02
|
查看: 323|
回复: 0
发表于 2026-3-22 02:56:02
|
查看: 323|
回复: 0
