主流大模型训练、推理及RLHF框架繁多,各有侧重。本文将基于真实使用体验,对其中几个代表性框架进行简评,旨在为技术选型提供参考。
Torchtitan
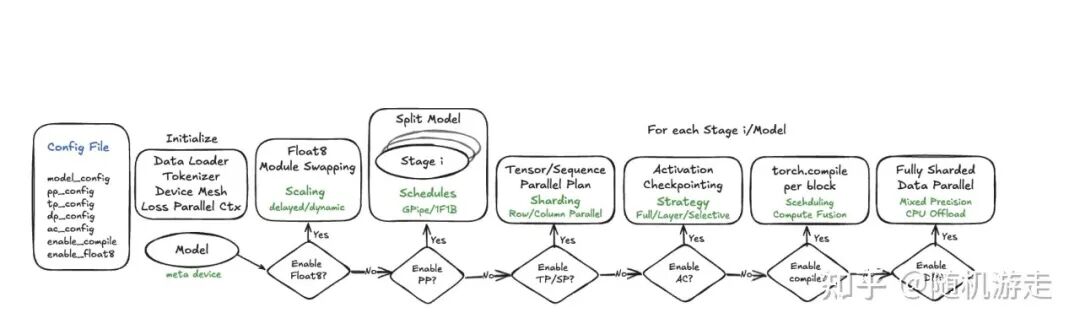
Torchtitan 本质上是 PyTorch Native 训练方案的打包解决方案与教程。其核心在于推广基于 DTensor 的张量并行(TP)方案。DTensor 提供了三种分布式语义:Shard、Replicate 和 Partial,其设计思想借鉴了早期 OneFlow 的 SBP 机制。
目前,Torchtitan 集成了 FSDP、基于 DTensor 构建的各种并行策略规划、Checkpointing 和分布式检查点(DCP)等功能。严格来说,它并非一个完整的训练框架,更像是一本手册或字典,当需要实现特定功能时可以从中查询参考。
Megatron
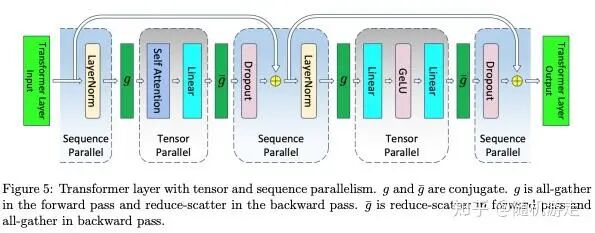
Megatron 的设计主要围绕两条主线展开:一是通过 mpu/parallel_state 和 initialize_megatron 初始化分布式环境,构建通信进程组与并行进程组;二是其经典的模型并行策略,相关思想体现在三篇著名论文中,涵盖了 MLP/Attention TP、交错式 1F1B 流水线调度以及 TP-SP(张量并行与序列并行)。
在 MCore 代码实现中,model_provider 提供一个基础的 CPU 模型,随后由 Megatron 将其改造为并行版本。get_language_model 获取由 ParallelTransformer 模块堆叠而成的 TransformerLanguageModel,如需数据并行,可再配置 DDP 或 FSDP。Megatron 目前也支持 FSDP,既有集成 PyTorch 原生版本,也有其自身的实现。
Megatron 常被提及的两个特点是:框架与模型代码耦合较紧,以及 Hugging Face 模型参数转换需要额外工作。这体现了其“直接明了”的风格,将并行切分逻辑(如 RowParallelLinear、ColumnParallelLinear)和通信细节直接暴露给开发者。与 PyTorch Native TP 方案(通过配置 parallel_plan 实现,对算法透明)相比,Megatron 的方式在定制化时更直观,但集成新模型时需要更多手动实现。参数转换方面,已有诸如 MBridge 等工具来简化流程。
xDIT
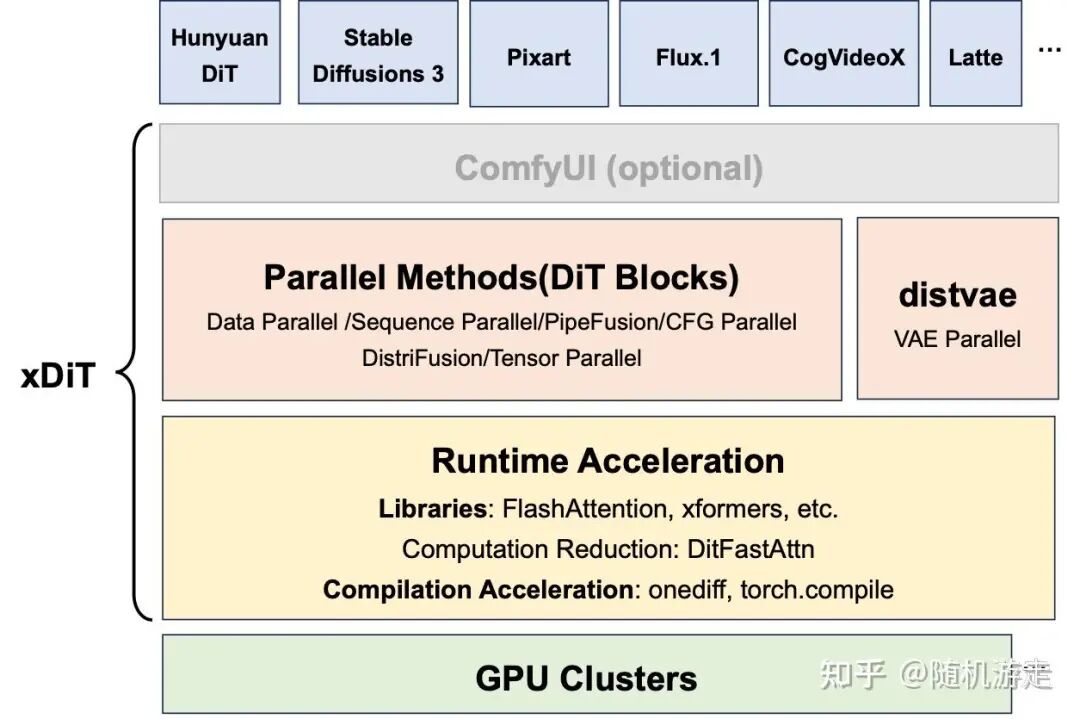
xDIT 是较早开源的、专注于视觉 Diffusion 模型推理的框架,核心理念是“Hugging Face + 并行”,可视为视觉生成领域的 vLLM。它创新性地提出了结合 Ulysses 和 Ring Attention 的 USP 注意力机制。但其通过 Wrapper 和 Decorator 的设计模式,使得框架层略显复杂。
目前,LLM 推理框架也开始扩展视觉模态支持,例如 SGLang 通过引入 FastVideo 支持视频生成,vLLM-Omni 则旨在成为支持多模态编码器和解码器的统一引擎。这些体现了社区生态成熟后的能力拓展。
vLLM
vLLM 起源于 Continuous Batching 和 PagedAttention 两大创新。深入其源码通常源于解决实际问题的需求。例如,排查 LLM 循环输出问题时,需要理解其推理生成流程:输入 Prompt 经 Tokenizer 得到 Token IDs,通过 Embedding 层转为 Hidden States,随后经过多层 Decoder Layer(每层进行 QKV 投影、SDPA 计算、输出投影),最终由 LM Head 计算得到下一个 Token 的概率分布并进行采样。解决方案有时可能很简单,例如为生成过程添加一个 max_length 限制。
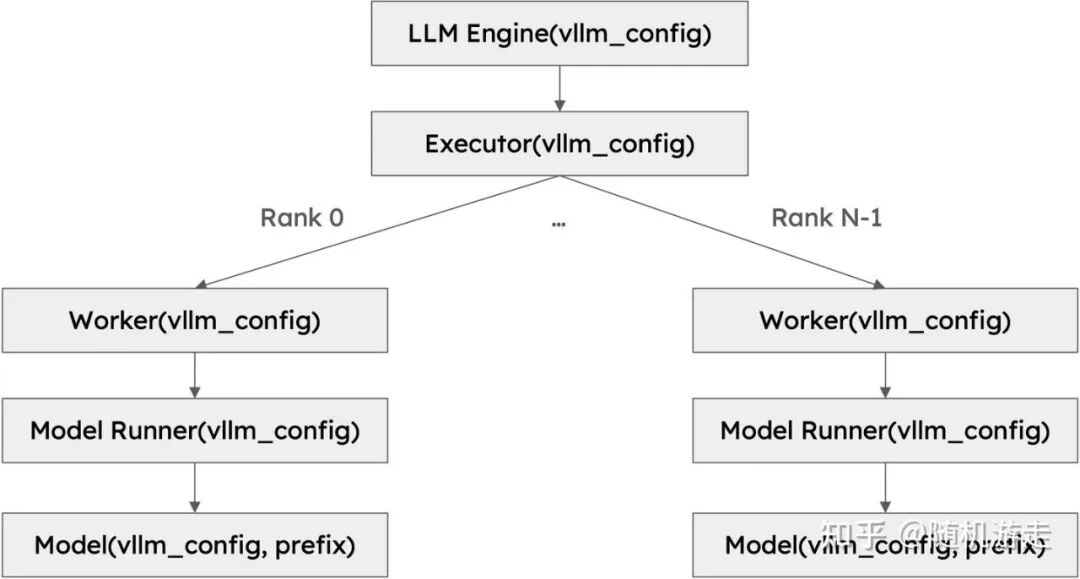
又如,排查 Ray 进程启动问题时,需要了解 vLLM 的 BackendExecutor,它支持单 GPU、多 GPU、Ray 等多种执行后端。Executor 可管理多个 Worker,通过 collective_rpc 在所有 Worker 上同步执行函数。
OpenRLHF
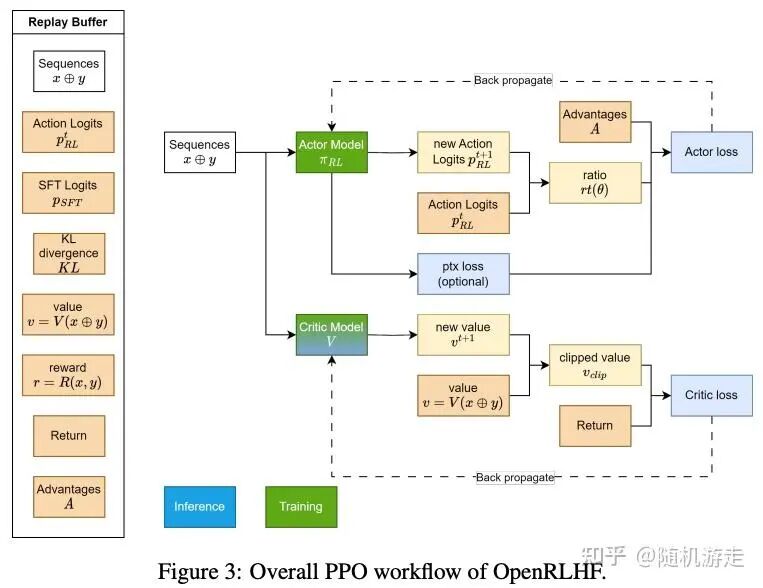
OpenRLHF 是国内较早开源且影响力较大的 RLHF 框架之一。它使用 Ray 的 Placement Group 进行资源管理,在 Group 内部复用已有的推理/训练框架执行 SPMD 计算。后续许多 RL 框架都沿用了这一设计范式。该框架对于入门 RLHF 流程很有帮助,其核心开发者也对国内相关领域的发展贡献颇多。
TRL
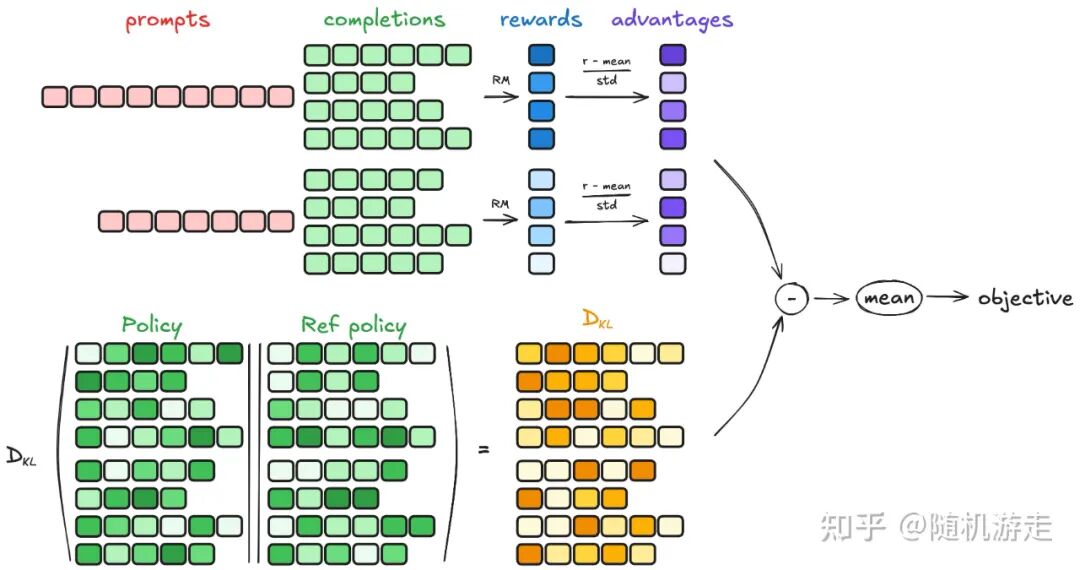
TRL 深深扎根于 Hugging Face 生态,以易用性见长,非常适合快速上手和单步 Debug RL 流程。在代码实现上,它更像是在 Hugging Face Trainer 的基础上,通过插入 RL 流程相关的 Hook(如在 prepare_inputs 中整合参数更新和 Rollout 逻辑)来实现功能。
veRL
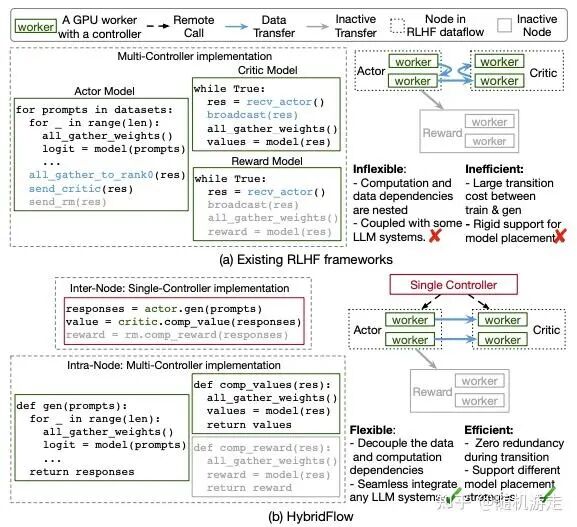
veRL 的核心理念是将 RL 计算流程建模为数据流(Dataflow),其中每个节点都是一个分布式的 SPMD 程序。在节点间(Inter-Node),为了灵活性,使用 Ray 作为“胶水层”实现中心化的单控制器模式;在节点内(Intra-Node)的模型层面,为了通信效率,则采用多控制器模式,从而可以复用现有推理/训练系统的并行编程模型。组件间通过基于 DataProto 的数据协议连接。它更像是一个从内部生产系统提炼出来的、面向机器学习系统工程师的框架,而非单纯面向强化学习算法研究员。
SLIME
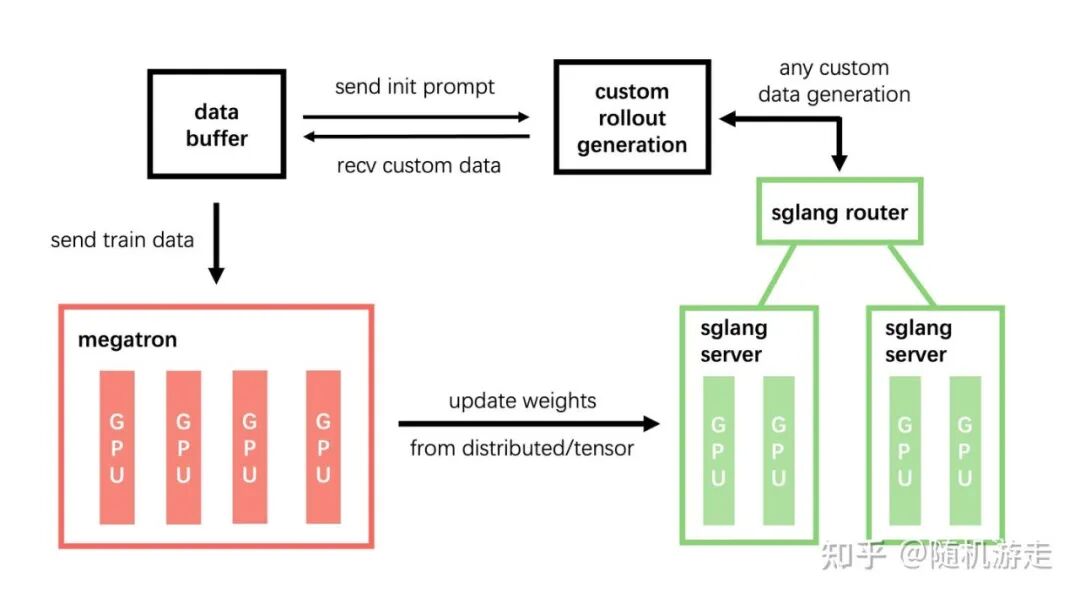
SLIME 的代码结构清晰,基于 SGLang、Megatron 等作为高性能推理/训练后端。它支持共置式与分离式架构,将 RL 流程清晰地拆分为 Rollout、DataBuffer、Train 三个独立模块,提供了较高的定制自由度,是 RL 框架领域值得关注的新兴项目。
Ray
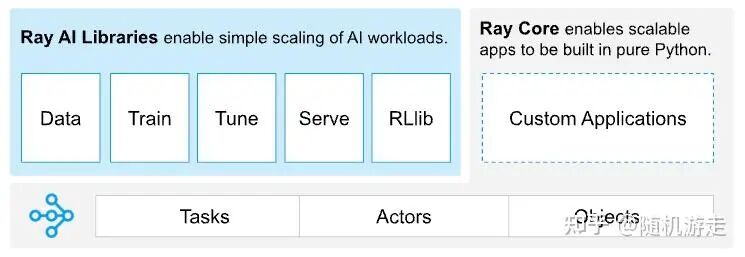
Ray 最初旨在解决复杂 RL 环境交互的编程问题,现已发展为一个通用的分布式计算框架。其 Task 和 Actor 抽象非常简洁,底层强依赖于 gRPC。Ray Core 提供了进程级资源管理和远程 RPC 调用的能力,能够出色地充当不同框架或组件间的协调层。目前主流的 RL 框架几乎都选择 Ray 来处理资源管理与控制平面逻辑。随着 Ray 进入 PyTorch 基金会,它正朝着 云原生 AI 基础设施标准的方向演进。PyTorch 团队也推出了类似的 Monarch 项目,其发展值得关注。
 发表于 2025-12-10 05:36:03
|
查看: 232|
回复: 0
发表于 2025-12-10 05:36:03
|
查看: 232|
回复: 0
