英伟达与香港大学联合开源了ToolOrchestra模型。这项研究引人注目的是,其仅凭80亿参数的体量,在人类终极考试(HLE)等严苛任务中超越了GPT-5等大型前沿闭源模型。

该研究构建了一个智能编排系统,核心是训练一个小型指挥官模型。这个模型能够灵活调度包括GPT-5在内的顶尖大模型及各类专业工具。它证明了通往超级智能的路径不必单纯依赖堆砌参数,学会有效指挥往往比单打独斗更高效。
指挥艺术下的异构智能体网络
长期以来,业界存在一种惯性思维,认为只有参数量巨大的单一模型才能解决最复杂的推理任务。
这类“单体巨兽”虽然通用能力强,但在面对需要深度推理、复杂计算或特定领域知识的难题时,往往表现不佳且成本高昂。
传统的大模型工具使用范式,通常只是为其配备搜索引擎或计算器。这种做法未能充分挖掘工具的潜力,更忽略了一个关键的人类解决问题的逻辑:真正的专家懂得在何时、向谁求助。
ToolOrchestra提出的编排范式正是基于这一洞察。在这个系统中,智能不再源于单一的巨型大脑,而是涌现于一个协同工作的复合系统。系统的核心是一个经过特殊训练的8B模型,被称为指挥官。
指挥官的职责并非亲自解决所有问题,而是像一个精明的项目经理,动态判断当前步骤需要调用何种资源。它需要决策:是查阅本地数据库,是调用代码解释器,还是“聘请外援”——比如GPT-5或专业的数学模型。
这种分工协作的机制,使得小型模型得以驾驭超越自身能力的智慧。通过将需要高智商推理的子问题委托给更强的模型,系统实现了整体智能上限的突破。
指挥官的能力强大之处,在于其对“工具”定义的极大扩展。
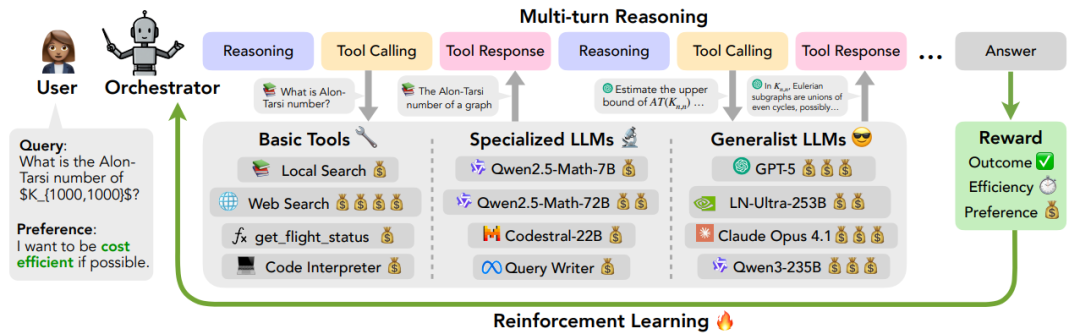
在它的工具箱里,不仅有传统的网络搜索、Python代码沙箱、本地检索,更重要的是,它将其他的大语言模型也视为可调用的工具。这种设计构建了一个异构的智能体网络。
- 基础工具:包括Tavily搜索API、代码解释器、Faiss本地索引等。
- 专用型LLM:针对特定任务优化的模型,如擅长数学的Qwen2.5-Math,擅长代码的Codestral。
- 通用型LLM:行业顶尖的通才模型,如GPT-5、Claude Opus 4.1、Llama-3.3-70B。
指挥官通过一个统一的接口与这些形态各异的工具交互。为了让指挥官理解其他模型的能力,研究团队采用了一种巧妙的描述生成方法:系统先让各个模型试运行任务,再让另一个LLM根据运行轨迹总结该模型的能力描述,从而实现“知人善任”。
整个过程是一个多轮推理的闭环。面对一个复杂查询,指挥官在“推理”和“工具调用”之间循环迭代。它分析当前状态,规划下一步行动,选择最合适的工具并指定参数。环境执行工具后,将反馈结果作为新的观测值传回指挥官,循环此过程直至得出最终答案。
多维奖励重塑模型行为逻辑
仅仅把工具摆在面前,小型模型并不会自动学会高效指挥。简单的提示工程往往效果不佳,甚至会引入严重的偏见。
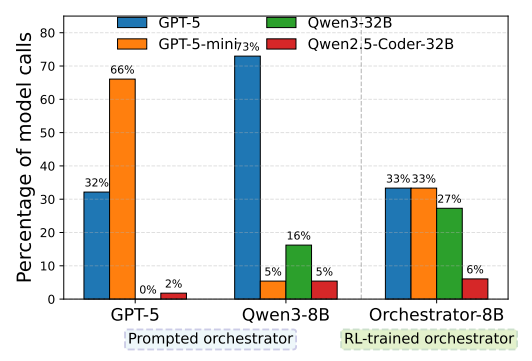
研究发现,GPT-5在被要求指挥时,表现出极强的“自我增强偏见”,会不成比例地偏向于调用自家的GPT-5-mini,或不计成本地盲目调用最强模型。这种做法既不经济,也未必高效。
而Qwen3-8B在使用提示工程时,则表现出对GPT-5的过度依赖,高达73%的调用都指向了GPT-5,几乎放弃了自主判断。
为了克服这些问题,ToolOrchestra引入了基于GRPO(组相对策略优化)的强化学习训练框架。研究团队设计了三种维度的奖励函数,从根本上重塑模型的行为逻辑:
- 结果奖励:关注任务最终是否正确完成。这是硬性指标,研究利用GPT-5作为裁判来验证答案的正确性。
- 效率奖励:关注方案是否经济高效。系统会根据第三方API定价,将计算消耗和时间延迟折算成货币成本进行惩罚。这迫使指挥官在能用廉价小模型解决问题时,绝不滥用昂贵的大模型。
- 偏好奖励:关注是否听从用户的非功能性需求。用户可能明确要求“尽可能省钱”,或“为了隐私只用本地搜索”。指挥官必须学会权衡这些偏好与任务成功率。
这种多维度的训练让指挥官学会了“精打细算”。它不再盲目迷信某个特定模型,而是根据任务的具体难度和性价比进行动态、理性的选择。
合成数据流水线解决训练瓶颈
训练这样一个聪明的指挥官,面临的最大瓶颈是数据匮乏。现有的数据集缺乏这种多工具、多模型协同的复杂交互轨迹。
研究团队为此构建了ToolScale,这是一套自动化的数据合成流水线,能够生成包含10个领域、数千个可验证的多轮工具使用案例。
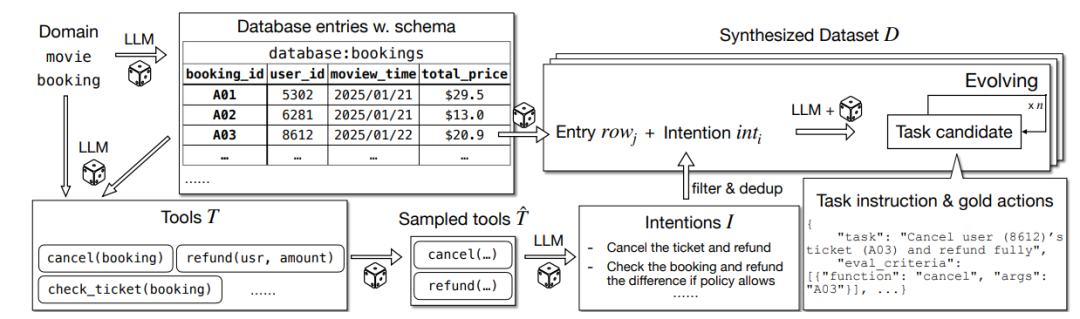
ToolScale的生成过程始于环境模拟。系统先选定一个领域(例如电影预订),让LLM生成逼真的数据库架构和API定义,从而构建一个虚拟的交互环境。
接着是意图演化。基于该环境,LLM生成多样化的用户意图,并将其转化为具体的任务指令和标准的操作序列。为了防止任务过于简单,系统会引入额外的LLM为任务添加约束条件,增加其复杂度。
最后是质量过滤。通过严格的执行检查,系统剔除会报错、无法解决或过于简单的样本,确保每一条合成数据都具备高训练价值。这套Python驱动的自动化流程,解决了高质量训练数据从无到有的难题。
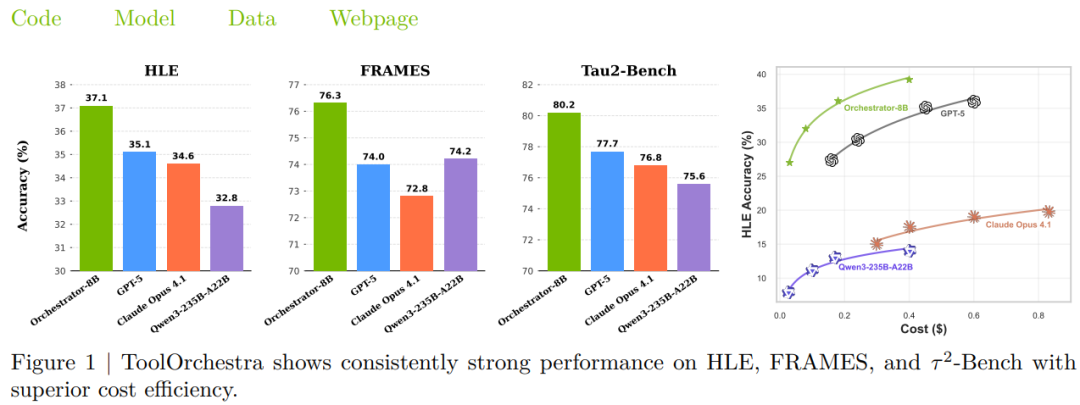
在三大高难度基准测试中,指挥官模型(Orchestrator-8B)交出了一份令人瞩目的答卷。
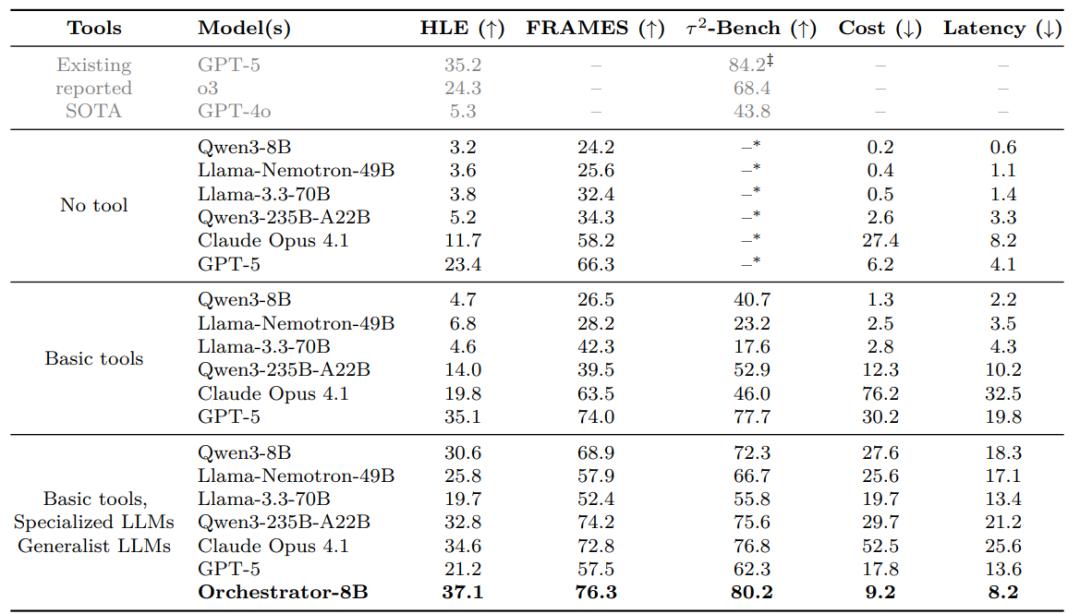
- HLE(人类终极考试):一个汇集各学科难题的极具挑战性的测试。Orchestrator-8B取得了37.1%的得分,超越了GPT-5的35.1%。
- 效率对比:在获得更高分的同时,Orchestrator-8B消耗的算力成本仅为GPT-5的几分之一,整体效率提升了2.5倍。
- 横向比较:作为对比,未配备工具的Qwen3-8B仅得4.7%;配备了工具的Claude Opus 4.1得分为19.8%。
- 其他基准:在事实推理基准FRAMES上,Orchestrator达到76.3%的准确率,超过GPT-5的74.0%。在函数调用基准Tau2-Bench上,它以80.2%的成绩刷新纪录,而成本仅为GPT-5的30%。数据显示,它学会了在60%的步骤中使用廉价工具,仅在关键的40%步骤中调用昂贵的GPT-5。
成本效益分析清晰地显示,Orchestrator-8B展现了最优的性价比曲线。
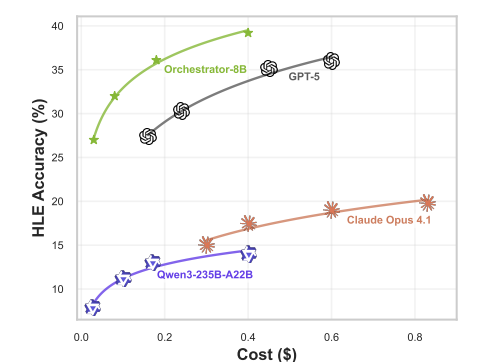
随着可用预算(允许的推理轮数)增加,它的性能稳步提升,且在任何成本点上都优于GPT-5和Claude Opus 4.1等巨型模型。这意味着在花费更少的情况下,它始终能提供更准确的答案。
编排策略的深层优势
Orchestrator-8B的成功揭示了AI系统发展的几个关键趋势。
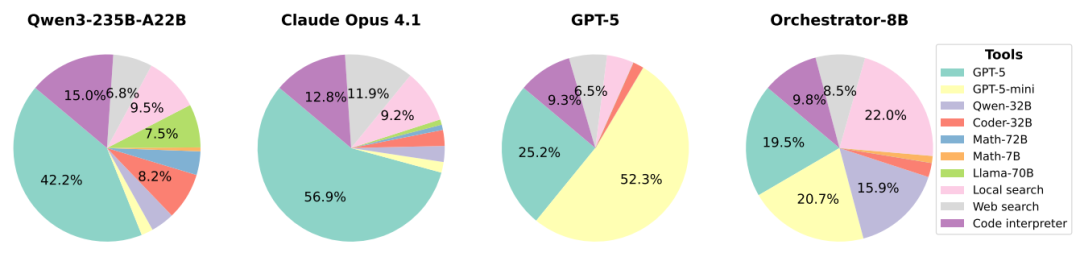
首先,有效克服了模型偏见。统计显示,Orchestrator-8B的工具调用分布非常均衡:GPT-5占25.2%,数学模型占9.8%,本地搜索占22%。相比之下,Claude Opus 4.1极度依赖GPT-5(56.9%),而GPT-5则过度依赖GPT-5-mini(52.3%)。指挥官模型去除了这种“门户之见”,真正做到了“只选对的,不选贵的”。
其次,展现了强大的泛化能力。即便面对训练时从未见过的工具和模型(如Claude Sonnet或DeepSeek-Math),指挥官也能通过阅读模型描述迅速上手,并取得良好的协同效果。
最后,实现了更好的用户对齐。当用户提出“我想省钱”的偏好时,指挥官能真正听进去。在偏好遵循度测试中,它对用户约束的遵循程度远超GPT-5,这证明了其在真实部署中具有更高的可控性。
ToolOrchestra的研究打破了“模型越大越好”的线性思维,证明了一个经过精心训练、懂得如何高效调动资源的80亿参数模型,完全有能力在复杂任务上超越当前最强的万亿参数级模型。对于希望构建更聪明的AI应用的开发者而言,这种“用小模型撬动大生态”的智能编排策略,提供了一个极具启发性和实用价值的新方向。
参考资料:
 发表于 2025-12-11 04:51:15
|
查看: 309|
回复: 0
发表于 2025-12-11 04:51:15
|
查看: 309|
回复: 0
