本文深入剖析LwIP协议栈中核心的数据容器——PBUF的结构与设计理念,并分享在适配底层驱动时,如何利用其特性实现零拷贝(Zero-Copy)优化,从而显著提升网络收发性能。
一、PBUF概述
PBUF是LwIP协议栈数据处理的基石。当一个以太网数据包被接收后,其整个生命周期(从链路层解析到最终将应用层数据交付给用户,或反之从用户数据到网络发送)都在PBUF中流转。其核心设计目标在于最大限度地减少数据拷贝。因此,在PBUF的众多操作中,直接操作payload指针成为常态:通过在数据区前端预留各层协议头空间,协议栈在层层解析或封装时,仅需移动payload指针即可定位到对应协议层的数据位置进行处理,而无需进行实际的数据搬运。这种设计思路非常值得驱动开发者在实现自定义协议解析或进行性能优化时借鉴。
二、PBUF核心机制解析
了解PBUF的基本机制是进行优化的前提,其具体实现可参阅pbuf.c/h源码。
2.1 数据结构
PBUF的核心是一个结构体,其定义如下:
struct pbuf {
struct pbuf *next;
void *payload;
u16_t tot_len;
u16_t len;
u8_t type_internal;
u8_t flags;
LWIP_PBUF_REF_T ref;
u8_t if_idx;
LWIP_PBUF_CUSTOM_DATA
};
- next: 指向下一个
pbuf,用于将多个pbuf链接起来存储一个大的数据包。
- payload: 指向实际存储数据的缓冲区地址。
- tot_len: 表示从当前
pbuf开始,整个数据包(包含后续链接的所有pbuf)的总长度。关系为 p->tot_len == p->len + (p->next? p->next->tot_len: 0)。
- len: 当前
pbuf中存储的数据长度。
- type_internal: 内部类型标志,指示
pbuf的类型(如PBUF_RAM,PBUF_POOL)及其内存来源。
- ref: 引用计数。这是实现零拷贝优化的关键。当
ref > 1时,表示有多个实体引用此pbuf,pbuf_free函数不会立即释放其内存。只有当ref递减至1时,释放操作才会真正执行。
- if_idx: 网络接口索引,用于区分数据包来自哪个物理接口。
2.2 包队列与PBUF链
LwIP设计非常灵活,允许两种组织形式:
- 一个数据包由多个PBUF组成:通过
next指针形成链表,用于存储超过单个pbuf负载能力的大包。
- 多个数据包组成队列:通过
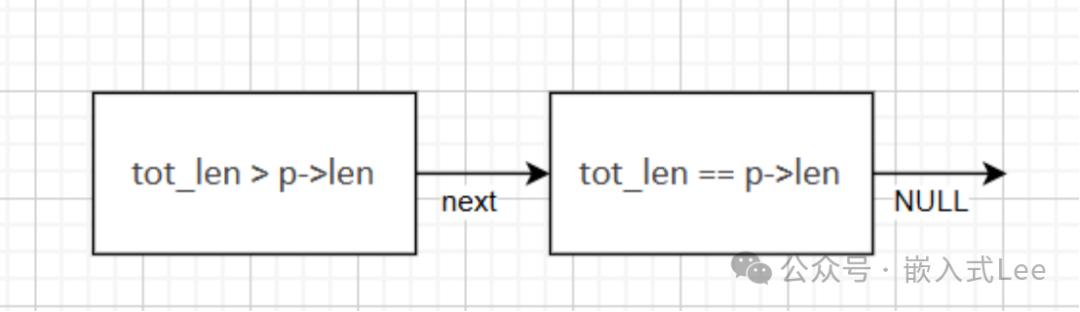
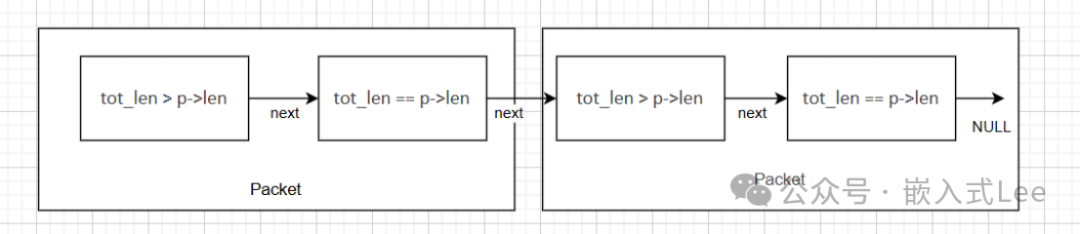
pbuf链表的特定边界(tot_len == len且next != NULL)来标识一个包的结束和下一个包的开始。
一个Packet由PBUF链存储示意图:
多个Packet组成PBUF链队列示意图:
2.3 PBUF的申请与释放
2.4 关键辅助接口
LwIP提供了一系列操作pbuf的接口,核心思想是操作指针而非拷贝数据:
pbuf_header(p, size): 向前(size为负)或向后(size为正)移动payload指针,用于跳过或预留协议头。pbuf_ref(p): 增加引用计数。这是实现发送零拷贝的关键函数,用于防止协议栈过早释放待发送的pbuf。pbuf_chain(h, t) / pbuf_dechain(p): 用于链接或拆分pbuf链。pbuf_copy系列: 用于当必须进行数据拷贝时的复制操作。
三、驱动零拷贝优化实战
理解PBUF机制后,我们可以在网络驱动适配中实现高效的零拷贝优化。
3.1 接收方向优化
常规驱动接收流程为:DMA将数据收到驱动内部的Rx Buffer -> 申请pbuf -> 将数据从Rx Buffer拷贝到pbuf -> 提交给LwIP协议栈。这个过程存在一次内存拷贝。
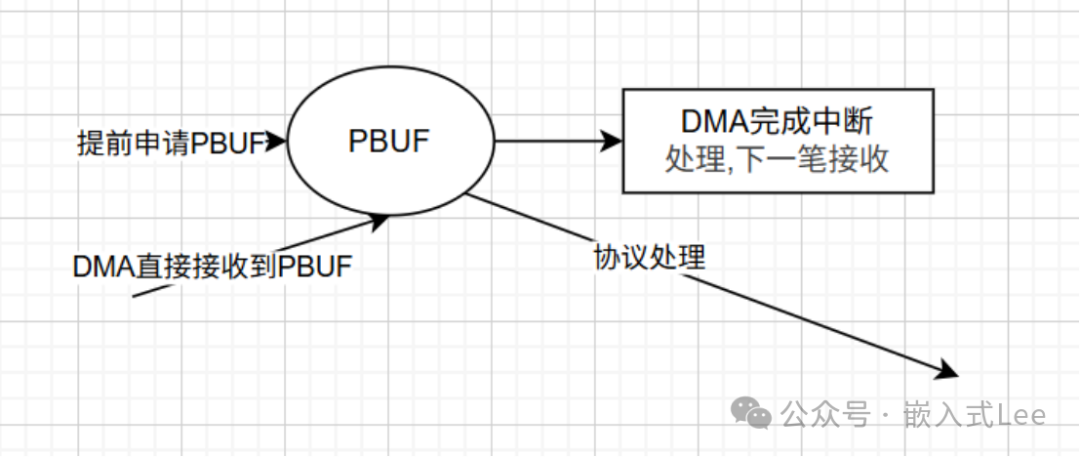
优化方案A(DMA直接到PBUF):
- 在接收描述符初始化时,直接调用
pbuf_alloc(PBUF_RAW, MAX_FRAME_LEN, PBUF_POOL)申请好pbuf。
- 将DMA接收描述符的数据缓冲区地址设置为
pbuf->payload。
- 当DMA接收完成产生中断时,收到的数据已直接位于
pbuf中。
- 直接调用
netif->input(pbuf, netif)将pbuf送入协议栈。
优点:完全消除拷贝。
缺点:需要提前申请并管理一批pbuf,且pbuf的申请失败可能影响驱动正常接收。
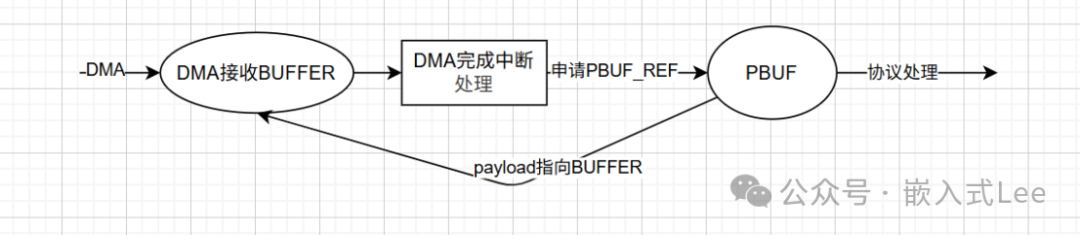
优化方案B(PBUF引用DMA缓冲区):
- DMA将数据收到驱动内部的
Rx Buffer。
- 在接收中断中,申请一个
PBUF_REF类型的pbuf(仅分配结构体)。
- 将该
pbuf的payload指针直接指向Rx Buffer中的数据区。
- 调用
netif->input(pbuf, netif)提交。协议栈处理期间,数据始终位于Rx Buffer。
- 协议栈处理完毕后会调用
pbuf_free,由于PBUF_REF类型,只会释放pbuf结构体。此时驱动可回收Rx Buffer。
优点:无数据拷贝,pbuf申请快。
缺点:Rx Buffer被协议栈占用时间较长,需要更多的Rx Buffer来维持吞吐量,且需确保协议栈处理期间驱动不会覆写该缓冲区。
3.2 发送方向优化
常规发送流程:应用数据填入pbuf -> 协议栈逐层添加头部 -> 调用驱动发送函数,驱动将数据从pbuf拷贝到Tx Buffer -> 启动DMA发送 -> pbuf被释放。
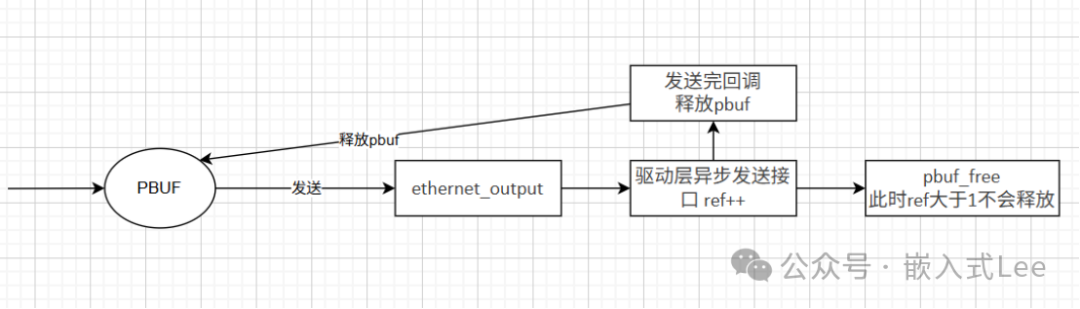
优化方案(异步发送与引用计数):
核心思路是:让驱动直接从pbuf指向的数据区发送,避免拷贝。但必须确保在DMA发送完成前,pbuf不会被释放。
- 当协议栈调用底层输出函数(如
ethernet_output)准备发送一个pbuf时,在将其交给驱动之前,先调用pbuf_ref(p)增加其引用计数。
- 驱动配置DMA描述符的数据地址为
pbuf->payload,并启动异步DMA发送。
ethernet_output函数返回后,协议栈会调用pbuf_free(p)。由于此时ref=2,pbuf_free仅将ref减为1,不会真正释放内存。- DMA发送完成中断中,驱动调用
pbuf_free(p)。此时ref从1减为0,内存被安全释放。
此方案的关键在于理解并利用好引用计数机制。
3.3 其他性能调优要点
- 优先使用
PBUF_POOL:内存池分配速度远快于堆分配(PBUF_RAM)。
- 合理配置
PBUF_POOL_BUFSIZE:使其大于(pbuf结构体 + 最大协议头 + MTU),这样绝大多数数据包都能由单个pbuf承载,避免链式结构带来的处理开销。
- 调整内存池大小:根据实际流量监控调整
PBUF_POOL_SIZE(对应PBUF_POOL)和MEMP_NUM_PBUF(对应PBUF_REF/ROM),确保不会因pbuf耗尽而丢包或性能下降。
- 驱动与调度优化:确保DMA描述符链式传输无缝衔接;为网络处理任务分配合适的优先级;采用高效的中断或信号量通知机制。
四、总结
PBUF是LwIP高效处理网络数据的核心。其通过指针操作避免数据拷贝的设计理念,以及引用计数管理内存的生命周期机制,为底层驱动实现高性能的零拷贝优化提供了坚实基础。在驱动适配中,通过让DMA直接与PBUF管辖的内存交互,并妥善运用pbuf_ref()与pbuf_free(),可以显著减少内存拷贝次数,提升网络吞吐量,降低CPU负载,这对于资源受限的嵌入式系统尤其重要。 |  发表于 2025-12-13 00:55:36
|
查看: 368|
回复: 0
发表于 2025-12-13 00:55:36
|
查看: 368|
回复: 0
