在传统的视觉Transformer(ViT)模型中,输入图像的尺寸和分辨率是预先固定的。这意味着训练好的模型,其推理输入必须被缩放或裁剪到预设的尺寸,导致每张图像的token数量恒定。当实际应用中的图像长宽比或分辨率与模型要求不一致时,强行调整会扭曲原始图像,这在OCR、目标检测等注重细节特征的场景中,可能显著影响模型性能。
为此,研究界提出了能够原生处理任意尺寸图像的方案,允许不同分辨率的图片拥有不同数量的图像块(patch)令牌。Google于2023年发表的论文《Patch n‘ Pack:NaViT, a Vision Transformer for any Aspect Ratio and Resolution》提出的NaViT(Native Resolution Vision Transformer)正是为解决这一问题而生。其核心架构沿用了ViT的设计,但在训练和推理范式上做出了关键革新。官方代码暂未开源,但社区已有相关复现工作可供参考。
核心方法:Patch n‘ Pack
传统批处理需要固定输入尺寸,通常采用Resize或Padding。前者损害性能,后者降低效率。NaViT借鉴了自然语言处理中的“示例打包(Example Packing)”思想,将多张不同分辨率图像的patch序列打包成一个批次进行并行计算,从而在保留原生长宽比的同时,大幅提升训练效率与模型灵活性。
其核心操作流程如下图所示:
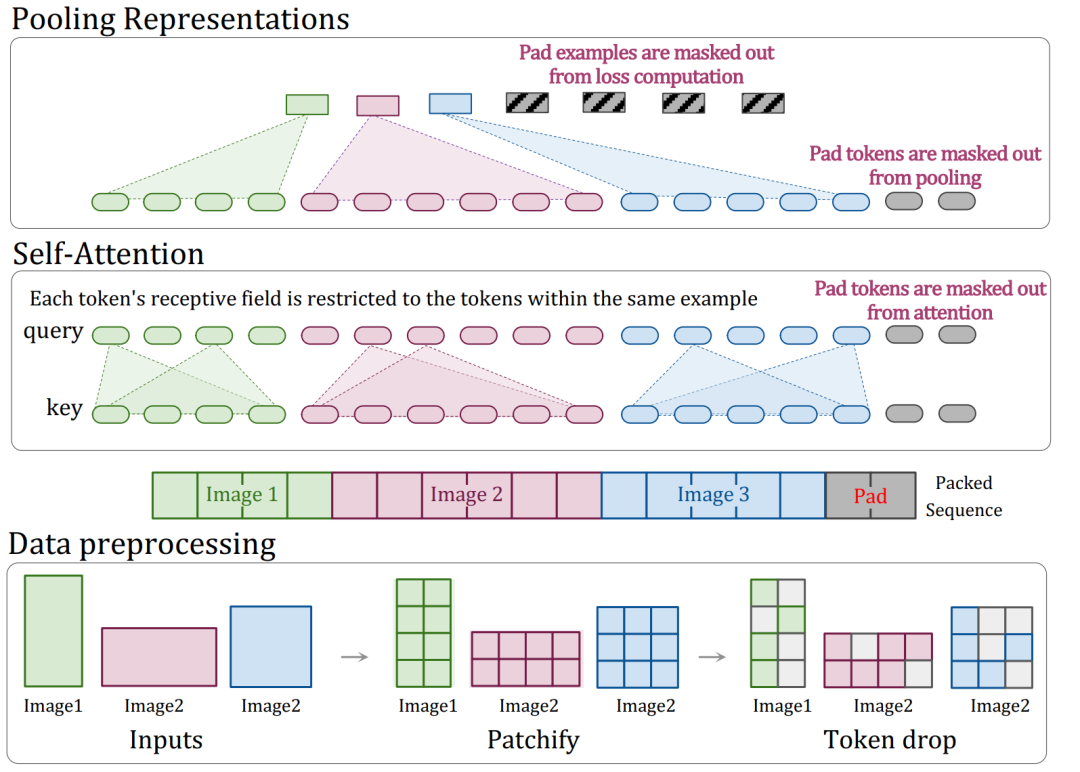
具体而言,NaViT对原生ViT的主要改进体现在以下几个方面:
1. 分解与分数式位置编码
为了适应任意宽高比和分辨率,固定网格式的位置编码不再适用。NaViT采用了分解式位置编码,将二维位置拆分为独立的X轴和Y轴坐标嵌入,再进行相加。
- 绝对嵌入:每个patch的(x, y)坐标对应一个独立的嵌入向量。
- 分数嵌入:将坐标在各自维度上进行归一化处理,使其成为[0,1]区间内的函数。这种方法提供了与图像绝对尺寸无关的位置信息,但隐式地通过patch数量来体现长宽比。
实验表明,这种分解式位置编码显著提升了模型对未见分辨率的泛化能力,使其能够真正实现“原生分辨率”下的训练与推理。
2. 掩码自注意力与掩码池化
在将多张图像的patch打包到同一个序列后,需要防止不同图像之间的信息相互干扰。为此,NaViT引入了掩码自注意力机制,确保注意力计算仅在每张图像自身的patch之间进行。
此外,在编码器之后,通过掩码池化操作,对每个示例(即每张图像)内的所有token表示进行聚合,为后续如图像分类等任务生成一个统一的图像级表示向量。
3. 序列打包与填充策略
打包序列的总长度是固定的,因此可能需要对短序列进行填充(Padding)。论文采用了一种贪心算法进行打包,并指出在其实验设置下,填充令牌仅占总令牌数的约2%,已是一个高效且实用的方案。更极致的方案可动态选择分辨率并结合token丢弃,以实现完美的序列打包。
创新的训练策略
除了模型结构,NaViT还引入了独特的训练技术以进一步提升效能:
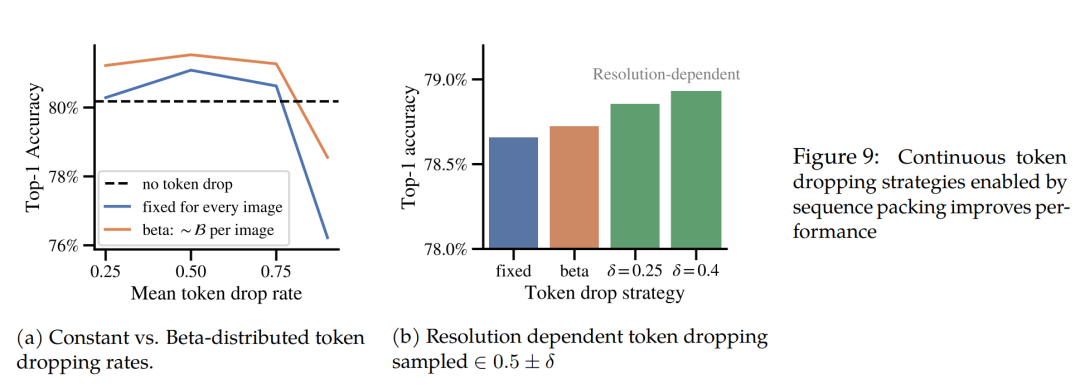
连续令牌丢弃
在训练过程中,随机丢弃一部分图像patch(token)可以加速训练。NaViT的“连续令牌丢弃”策略首先为每张图像采样一个丢弃率,然后按此比率随机丢弃其token,再进行打包。这样,同一个批次中同时包含完整图像和部分信息被“挖空”的图像。研究表明,从Beta分布中采样丢弃率优于固定比率,且根据图像分辨率动态调整丢弃率(高分辨率图像丢弃率更高)能带来进一步的性能提升。
分辨率采样
NaViT支持使用图像原始分辨率训练,也支持从预设的图像大小分布中采样分辨率进行混合分辨率训练,同时保持每张图像的原生长宽比。这种方法不仅提高了训练吞吐量,也让模型更多地接触到大尺寸图像,相比传统的高低分辨率分开训练方法更为高效。
总结与展望
NaViT通过Patch n‘ Pack、分解位置编码等核心设计,有效突破了ViT对固定输入尺寸的依赖,为视觉Transformer处理任意分辨率图像提供了优雅的解决方案。论文中包含大量详实的对比实验,值得深入研读。
该技术的变体已在众多先进的多模态大模型中得到应用,成为其视觉编码器的重要组成部分,例如阿里的Qwen2-VL、百度的PaddleOCR-VL等。这充分证明了其在人工智能特别是多模态领域的实用价值与发展潜力。未来,随着多模态模型的发展,NaViT及其衍生技术的优化与应用值得持续关注。
参考资料
- 多模态大模型的基石-ViT速览: https://mp.weixin.qq.com/s/bXZJ4Z5T0K-qb_pE2Fd6BQ
- NaViT社区复现代码: https://github.com/kyegomez/NaViT
|  发表于 2025-12-15 12:49:23
|
查看: 261|
回复: 0
发表于 2025-12-15 12:49:23
|
查看: 261|
回复: 0
