现代高性能分布式文件系统的设计,正面临着底层存储硬件革命的深刻挑战。传统的I/O栈与并发模型已无法充分释放新一代NVMe SSD的全部潜能。本文基于论文《What Modern NVMe Storage Can Do, And How To Exploit It: High-Performance I/O for High-Performance Storage Engines》的核心发现,探讨如何通过用户态驱动、异步并发与精细化的存储引擎设计,弥合硬件与软件之间的性能鸿沟。
论文要解决的六大核心问题
论文旨在回答以下六个决定存储引擎设计的关键问题:
| 问题编号 |
研究问题 |
论文给出的核心解答与发现 |
| Q1 |
NVMe阵列能否达到硬件标称的性能? |
可以,甚至能超越。实验证实,8块NVMe SSD组成的阵列能够实现1250万次/秒的随机读取IOPS,超过了单个硬盘标称性能的简单叠加。 |
| Q2 |
应该使用哪种I/O API?是否需要内核旁路(如SPDK)? |
1. 所有异步接口(libaio, io_uring, SPDK)都能实现高吞吐。
2. 内核旁路(SPDK)在CPU效率上具有绝对优势,但io_uring在轮询模式下也能接近其性能。对于追求极致效率的场景,SPDK是最佳选择。 |
| Q3 |
存储引擎应使用多大的页大小,才能在获得高性能的同时最小化I/O放大? |
4 KB是最佳权衡点。这是NVMe SSD随机读取性能的“甜点”,能同时优化IOPS、带宽和延迟。小于4KB会因硬件限制导致性能下降,大于4KB则会造成严重的I/O放大。 |
| Q4 |
如何管理实现高SSD吞吐所需的高并发度? |
必须采用用户态协作式多任务(轻量级线程)。传统“一个查询一个内核线程”的模型会导致数千线程的过度订阅和巨大开销。论文通过用户态任务调度,使少量工作线程能高效管理海量并发的I/O请求。 |
| Q5 |
如何让存储引擎足够快,以管理每秒数千万的IOPS? |
内存外(Out-of-Memory)的代码路径必须进行深度优化和并行化。这包括:采用分区锁消除热点、优化淘汰算法(如引入乐观父指针)、移除内存分配、以及微调热代码路径,确保CPU不会成为瓶颈。 |
| Q6 |
I/O应由专用的I/O线程执行,还是由每个工作线程执行? |
应由工作线程直接执行(All-to-All模型)。论文否定了专用I/O线程或SSD绑定的模型,采用对称设计:每个工作线程拥有通往所有SSD的独立I/O通道,无需线程间通信。这简化了设计,并实现了最佳的可扩展性。 |
Part 1:NVMe的优势与基本原理
为什么必须选择NVMe阵列?
在追求极致性能的计算场景(如大型AI超算集群)或企业级核心存储系统中,NVMe阵列已成为必选项。其根本原因在于,传统的SATA/SAS接口和协议栈已构成性能瓶颈,只有NVMe架构才能充分发挥PCIe高速通道的潜力,支撑起庞大的数据吞吐需求。
例如:
- 华为Atlas 950 SuperCluster 50万卡超集群,必须依赖NVMe阵列来支撑其海量计算单元的数据供给。
- 浪潮信息HF5000G5全闪存储系统,也采用了全新的NVMe架构以实现更低时延和更高性能。
NVMe、SATA SSD与HDD的区别
- HDD(机械硬盘):基于旋转磁盘,容量大、成本低,但延迟高。顺序吞吐约150–200 MB/s,随机IOPS为几十到数百。
- SSD(固态硬盘):基于NAND闪存,无机械部件,延迟低、并发高。按接口与协议主要分为:
- SATA SSD:使用SATA协议与AHCI接口,理论带宽上限为600 MB/s。
- SAS SSD:使用SAS协议,带宽更高(12/24 Gb/s),常见于企业级场景。
- NVMe SSD:使用NVMe协议与PCIe通道,专为闪存设计,协议开销极低。
核心区别:NVMe是一种专为PCIe SSD设计的轻量级高效协议,它彻底摆脱了为机械硬盘设计的AHCI/SCSI协议栈的束缚,实现了从单队列竞争模型到大规模并行无锁模型的飞跃。
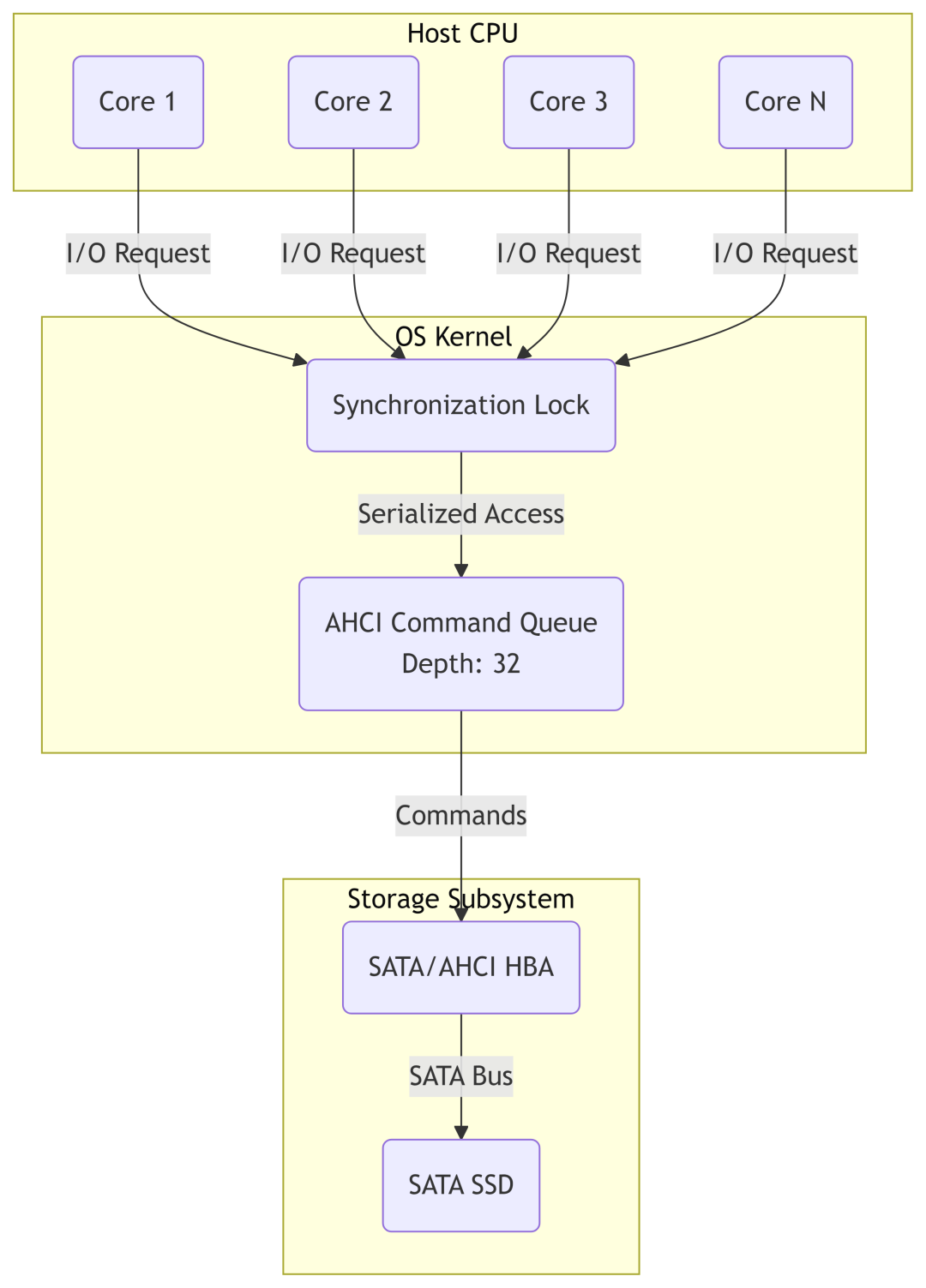
AHCI的单队列模型,难以应对多核并发
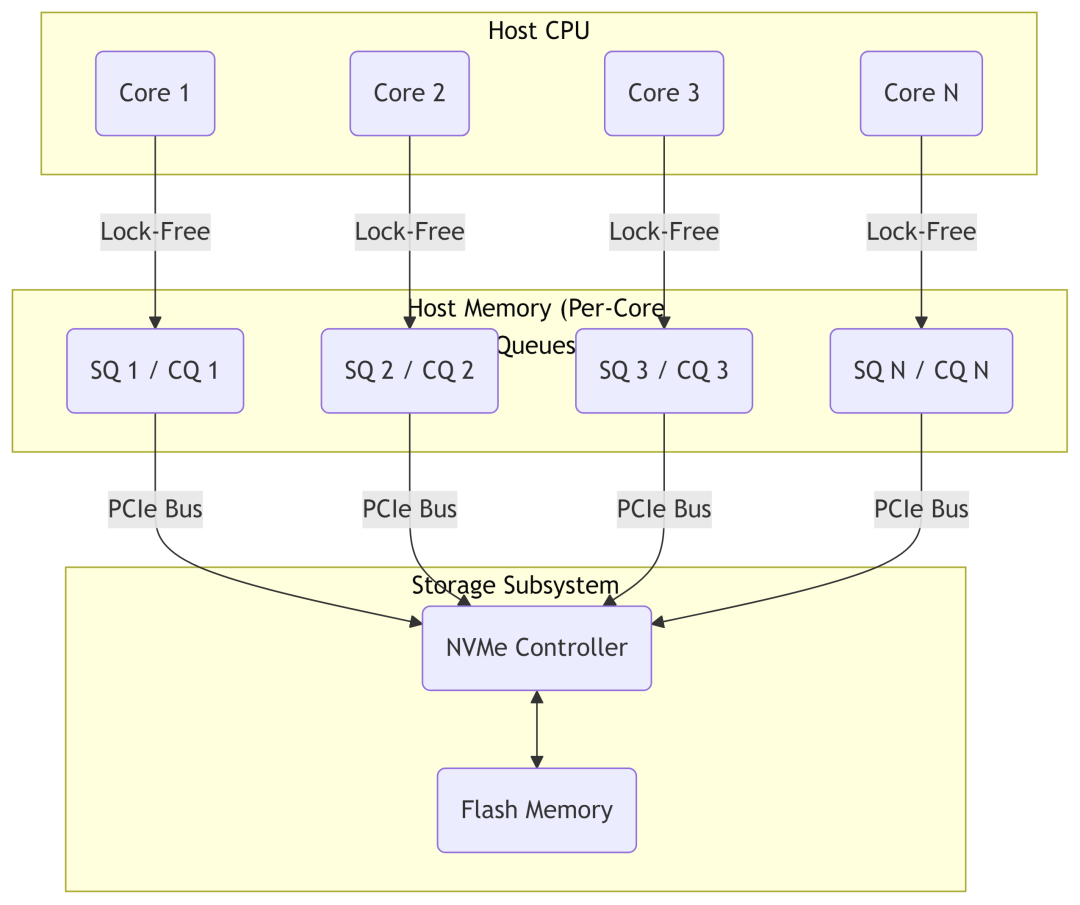
NVMe支持高达64K个队列,每个队列深度64K,完美匹配多核CPU
NVMe带来的性能飞跃:
- 极致低延迟:协议栈精简,访问延迟从毫秒级降至微秒级。
- 超高吞吐量:PCIe 4.0 x4理论带宽近8 GB/s,远超SATA III的600 MB/s。
- 海量并发IOPS:支持数十万级队列深度,轻松实现百万甚至千万级IOPS。
Part 2:现代NVMe存储的能力与软件挑战
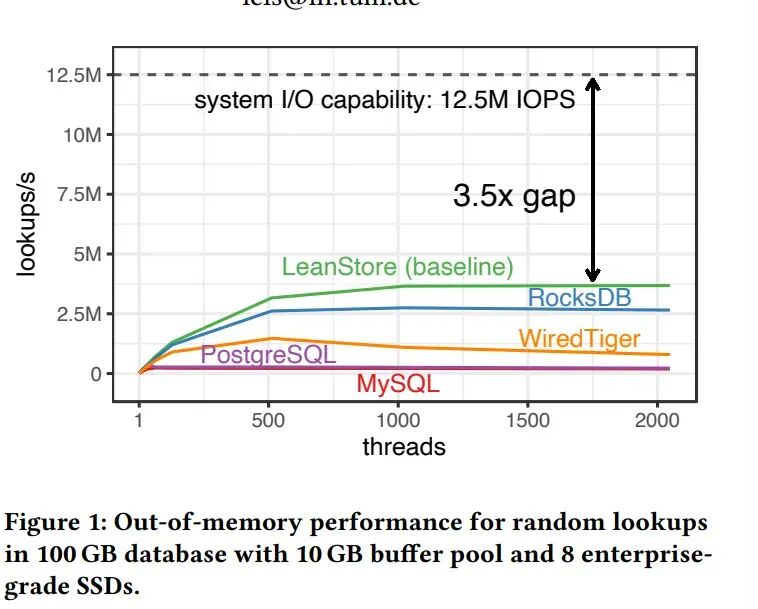
论文实验配置与性能对比
硬件潜力:NVMe阵列正逼近内存带宽
在过去的十年中,闪存固态硬盘已取代磁盘成为操作型数据库系统的默认持久存储介质。随着PCIe 5.0/6.0的到来,单设备带宽已达12 GB/s甚至更高。这意味着NVMe SSD阵列的聚合带宽正在接近DRAM的带宽水平。
实验配置示例:
- RAM:2.5 TB,带宽约150 GB/s。
- NVMe SSD阵列:8 × 4 TB = 32 TB,聚合带宽约56 GB/s。
软件瓶颈:陈旧的I/O与并发模型
图1清晰地揭示了巨大的性能鸿沟:尽管硬件(8块NVMe SSD阵列)能提供高达1250万IOPS的能力,但现有的主流数据库/中间件存储引擎仅能利用其一小部分,且需要启动上千个线程才能达到其软件峰值。
| 系统/指标 |
最高性能 (IOPS) |
达到峰值所需线程数 |
与硬件极限的差距 |
| 硬件极限 |
12.5 M |
不适用 (参考线) |
0 (基准) |
| LeanStore (基准) |
~3.6 M |
约 1500 线程 |
3.5倍 |
| RocksDB |
~2.8 M |
约 1000 线程 |
4.5倍 |
| WiredTiger |
~1.8 M |
约 500 线程 |
约7倍 |
| PostgreSQL |
~1.3 M |
约 1500 线程 |
约9.6倍 |
| MySQL |
~0.8 M |
约 1000 线程 |
约15.6倍 |
性能差距根源分析:
- 数据结构与写入放大:如InnoDB的B+Tree就地更新与WAL日志导致写入放大;RocksDB的LSM-Tree虽优化写入但可能增加读放大。
- 读取路径与缓冲管理:这是核心瓶颈。当数据量远大于内存缓冲池时(如100GB数据对10GB缓冲池),激烈的页面淘汰会带来巨大开销。传统数据库严重依赖全局锁保护的缓冲池,而像RocksDB这样的设计虽然避免了全局页缓存,但其多层SSTable的查找路径也可能成为瓶颈。
关键结论:简单地开启上千个内核线程无法解决根本问题,反而会引入巨大的调度开销和网络/系统并发控制复杂度。必须从I/O栈、任务调度模型和存储引擎内部架构进行系统性重构。
总结与展望
本文基于论文前半部分,揭示了NVMe硬件的巨大潜力与现有软件架构的不足。要构建能匹配千万级IOPS的分布式文件系统或存储引擎,必须采纳论文指出的方向:
- 采用4KB页作为存储单元的最佳权衡。
- 在SPDK(极致CPU效率) 与 io_uring(良好平衡性) 间做出明智选择。
- 引入用户态协作式任务调度来管理海量I/O并发。
- 采用全对全(All-to-All)的I/O模型,让工作线程直接处理I/O,避免额外通信开销。
这些原则为设计下一代高性能分布式文件系统的存储引擎提供了坚实的理论基础。
 |  发表于 2025-12-16 19:12:50
|
查看: 245|
回复: 0
发表于 2025-12-16 19:12:50
|
查看: 245|
回复: 0
