索引,几乎在任何数据库中,都处于一个核心的地位,向量数据库亦是如此。Milvus作为当前最为成功的向量数据库产品之一,它所实现的索引类型和算法,是比较丰富的。所以这些内容相对于传统的数据库的索引来说,理解起来,也要稍微麻烦一点。要清晰地理解所有细节的开端,还是先回到最古老的问题?
一、 概念
1、 什么是索引?索引的本质是什么?
索引是额外的数据存储。索引是建立在数据之外的附加结构。索引优化的本质是用存储空间效率换查询过程的时间效率。
索引是实现一些快速查询算法的存储基础。某些特殊的数据存放方法,也对应着查询时的一些算法使用。比如在B树的存储结构上,可以使用二分查找的算法。但是要注意,这个算法和后面Quantization的算法是两个不同的东西。
2、 索引加速查询的逻辑本质是什么?
索引加速查询,在于减少了无关数据(无论是数据行、还是数据列)的访问。
几乎从最古老的数据库/中间件开始,到如今炙手可热的向量数据库,索引的本质依旧如此。各种各样的索引所不同之处,亦在其中。不同索引的差别也在此处。其一,在于附加的存储结构类型,譬如B-TREE、BITMAP。其二,在于运行于数据结构上的算法,譬如位图索引上可以做一些位运算。
3、 向量数据库的索引变了什么?
有不变的、就必有变化了的。
第一,在Milvus中,由开发者指定搜索使用什么索引。不存在传统数据库的优化器计算代价或者选择执行计划的步骤,且它的数据结构和算法是配套的。这表示,开发者在使用某一个向量索引时,其实是没什么灵活性可言的。并且,要求开发者应该了解自己使用的索引、算法。即使不知道这个索引和算法的原理和实现,最最起码,也应该了解不同的索引应该用在什么样的数据类型和场景之下。好处是搜索高度符合开发者预期,不存在什么走错了索引之类的异常情况。
第二,查询加速逻辑有区别,查询瓶颈的主要矛盾似乎有些变化。Milvus强调了,对于大部分的算法,加载集合是在集合中进行相似性搜索和查询的前提。而加载的时候,所有的索引文件和原始数据都被加载到了内存里面。在传统数据库里,索引加速查询的核心逻辑,一直都在于,高效的避免无关行和无关列,被读入到内存之中,从而可以大幅地削减磁盘IO,最终实现查询优化。而向量数据库的索引,它更加侧重于加速内存中的计算。除去一些专门优化磁盘的索引。这种加速可能是避免不必要的实体进行计算。也可以是必要的实体计算算得更快一些。从降低召回率这一点来看,甚至是为了算得更快一些,有的必要的实体,可能也不算了。
第三,索引的选择可能改变查询结果。它并不像传统数据库单纯的加速查询。
二、 索引的构成
官网给出了向量索引的解剖图。
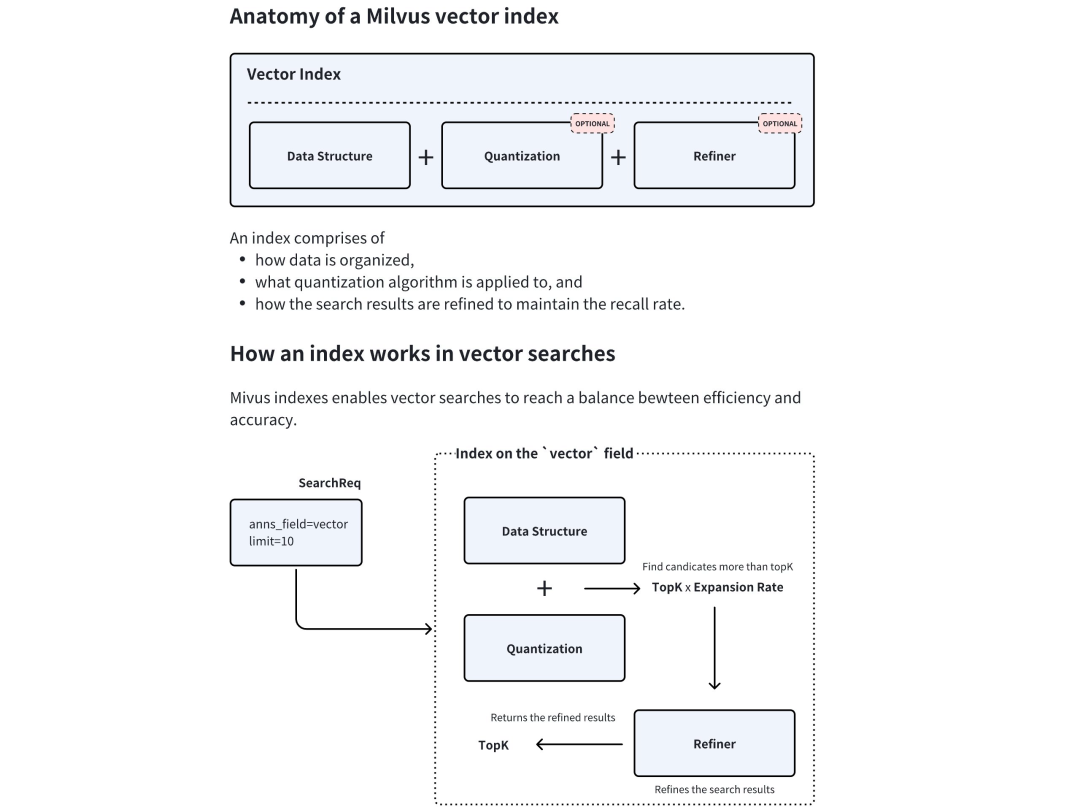
Milvus的索引,有三个核心的部分。分别是:Data Structure, Quantization, Refiner。
- Data Structure: 指数据的存储组织结构。
- Quantization: 指数据量化使用的算法。
- Refiner: 指搜索结果如何精炼并保持召回率。
Quantization这个词有点意思,它翻译成量子化,意为把连续量转化为数字。它原来是个物理名词,由普朗克提出,用来突破经典物理量连续变化的限制。规定物理量只能以量子的最小单位离散变化。比如,光能也不是连续的。对光的量子化就是认为光是以一个一个微小单位的形式存在和传播的。这里先用量化这个翻译。在向量数据库里,Quantization可以先理解为一种编码或者压缩的存储方式。
Data Structure和Quantization作为索引的两个部分,加速查询的根本逻辑不一样。Data Structure缩小需要访问的数据范围。Quantization使计算向量数据需要更少的空间和计算资源。
结合具体的索引,这一段描述才能更加具象化。很多 Milvus的索引命名由两部分构成,比如IVF_FLAT, HNSW_SQ。 前半部分,比如IVF表示内存之中数据结构部分。后半部分,SQ就是Quantization的量化部分,表示向量数据在向量数据库中真实的存储计算结构。
所以,后面把索引分成两大部分来理解。
三、 Data Structure索引的数据结构
1、 IVF
Inverted File反转文件,以前也有翻译成倒排文档。这种数据结构要分为两步来理解。为什么要提到以前的翻译,因为直接看官网那个花花绿绿的图,可能并不是那么容易理解。Inverted File并不是在向量数据库中才出现的。以前在一些列存储或者文档型的数据库中,就有这种索引的形态。它的索引项里存着值,后面有指向这个值出现在的文档位置。比如要在下面这个索引里,找到和Gold相关的内容,就可以通过这个索引,迅速定位。
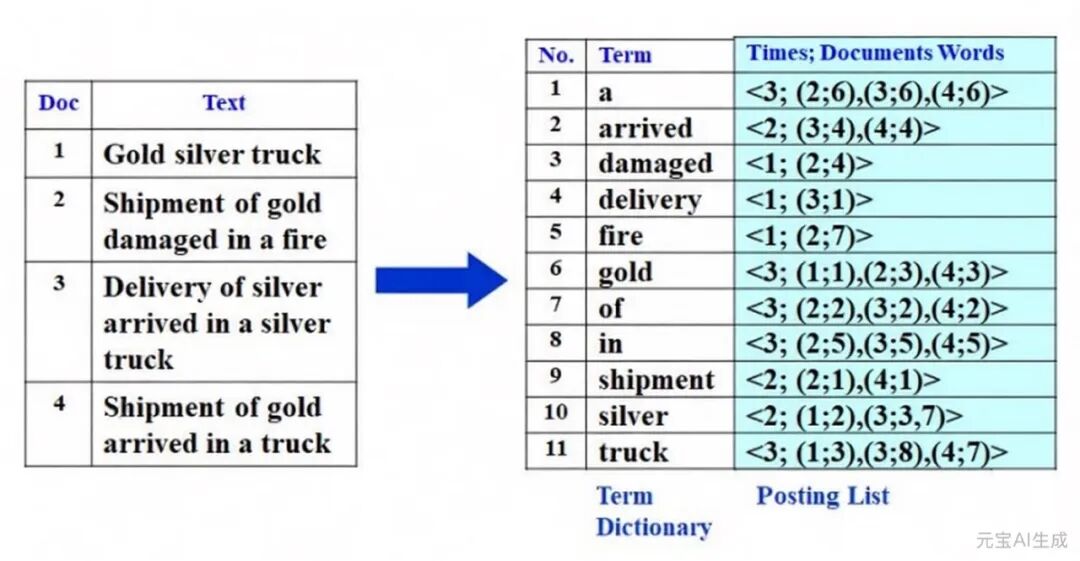
但是,现在这个索引所建立在的数据,并不是文字和文本,而是浮点型的向量。首先要把这些向量,使用K-MEANS 聚类的算法,把向量放到各个可以管理的区域(REGION)里面去,每一个REGION里都有一个中心点,来作为REGION内向量的参考点。
我把这个中心点,理解为上图Term Dictionary里面的词一样的存在。很显然,它的查询优化是通过,直接不计算一些域的实体,来避免没有必要的实体计算。它认为离得比较远的REGION的相似性自然是弱的。相似搜索的时候,把目标向量和备选REGION的中心点进行计算。找到最近的1个或几个中心点,再通过索引中,找到中心点对应的REGION内的向量,完成计算。
这里对于查询结果,影响比较明显的地方,就是REGION是怎么划分的。所以,这里需要先知道,什么是K-MEANS聚类算法。
1) K-means算法
K-means算法是一种基于距离度量的算法,通过迭代,把数据划分为K个簇,使簇内数据相似度最大化,簇间差异最大化。数据不重叠。
K-means基本流程为:
①初始化质心:随机选K个数据点作为初始中心点。
②分配数据点,计算每个数据点与所有质心的距离(比如欧式距离),将其分配到最近的簇。
③更新质心:重新计算每个簇的均值作为新的质心。
2) 重要的参数
IVF这个索引的数据结构,它和字面上的反转文件或者是倒排文档其实关联不大。它主要把所有的向量分成多个聚簇,计算这些聚簇的中心点和向量的距离,完成了聚簇的筛选。从而只需要计算聚簇所包含的向量子集来加速查询。
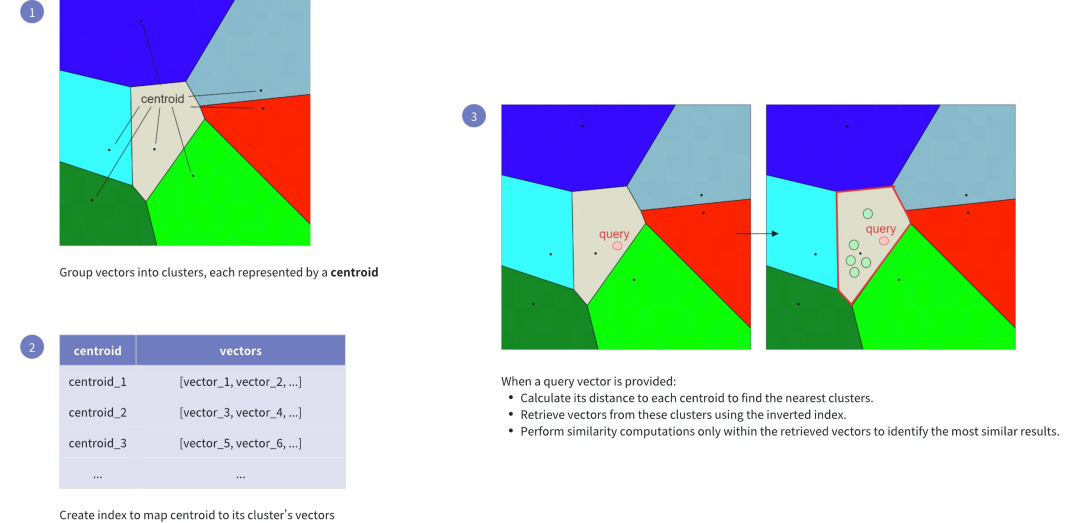
IVF索引的潜在缺点,如这个图上,搜索到的相似点,很有可能不是最接近的。如果搜索的这个点,在这个REGION的边缘,而最近那个点在另一个REGION的边缘。通过中心点检索的向量,就找不到最近的那个向量。所以,就有个参数来用于解决这个缺陷。一个是 nlist,这个用于指定这个K值,也就是REGION的数量。分的范围可以是1-65536个,默认值是128个。
另一个是 nprobe,就是选择候选向量的时候,应该考虑几个分区,这个值要小于nlist的值,默认是8个。这个是决定选最近的几个中心点,对应的向量来检索。显而易见,nprobe会提高召回率,但是查询时的计算量肯定是大幅的增长了。
2、 HNSW分层导航小世界
HNSW是一个基于图的索引算法。HNSW算法构建一个多层图,底层包含所有数据点,而上层则由从底层采样的数据点子集组成。在这个层次结构中,每一层都包含代表数据点的节点,节点之间由表示其接近程度的边连接。上层提供远距离跳转,用来快速接近目标,下层进行细粒度搜索,获取准确的结果。
这个表述还是有点抽象,可以想象我们在一个地图APP中,打算寻找上海中心塔。我们肯定是把地图缩放到很大,然后选中上海。然后把上海地区搓大之后,再点到陆家嘴附近。再搓大,然后精确地找到上海中心。那这个搜索行为,就有点像HNSW的搜索过程。当你找上海中心塔时,你没必要把其他国家的地图搓大(图顶层),也没有必要把其他省的地图搓大(下一层)。而是尽可能到陆家嘴附近(底层),再访问细节数据,从而避免了大量无关数据的访问。
1) HNSW图构建流程
①初始化: 从空图开始,将第一个向量作为图的初始节点。
②插入节点: 对于后续的每个向量,将其作为一个新节点插入到图中。
插入过程如下:
a.确定插入层次
通过一个概率函数随机确定新节点所在的层次。较高层次的节点数量较少,代表更全局的连接;较低层次的节点数量较多,代表更局部的连接。
b.搜索插入位置
从图的最高层开始,使用贪心搜索策略找到与新节点在当前层最接近的节点。然后,沿着该节点向下一层继续搜索,直到到达最底层。
c.建立连接
在最底层找到合适的插入位置后,将新节点与周围的一些邻居节点建立连接。同时,根据新节点所在的层次,在更高层也建立相应的连接。
③重复插入: 不断重复上述插入节点的过程,直到所有向量都插入到图中。
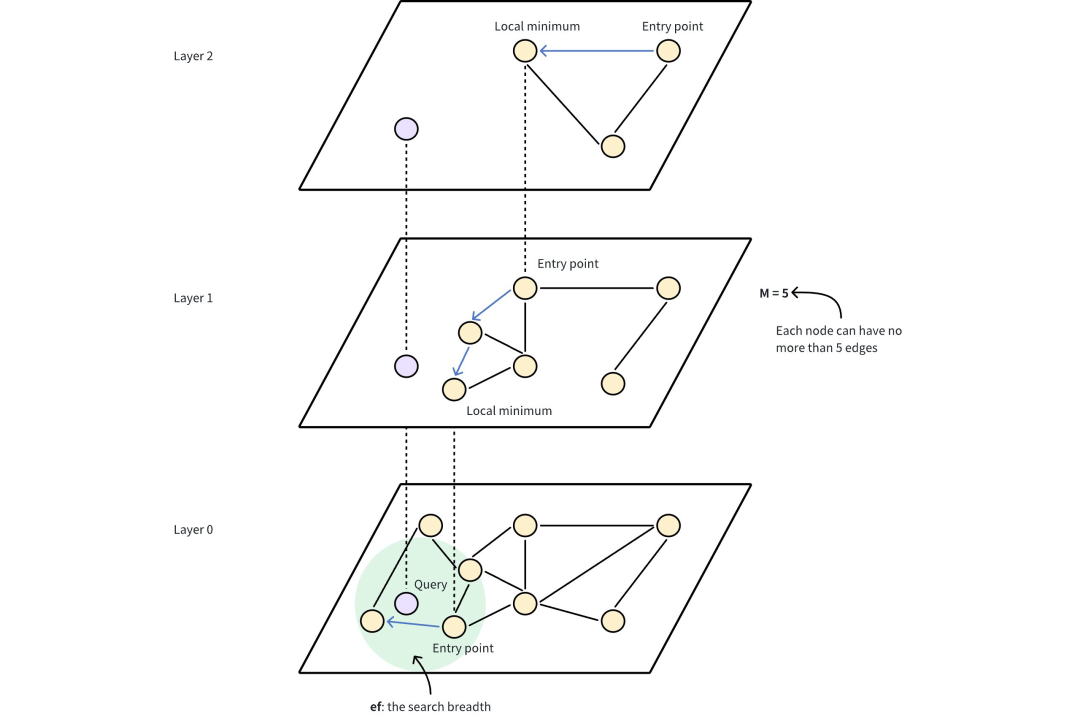
2) HNSW搜索流程
①入口点: 搜索从顶层的一个固定入口点开始,该入口点是图中的一个预定节点。
②贪婪搜索: 算法贪婪地移动到当前层的近邻,直到无法再接近查询向量为止。上层起到导航作用,作为粗过滤器,为下层的精细搜索找到潜在的入口点。
③层层下降: 一旦当前层达到局部最小值,算法就会利用预先遍历的连接跳转到下层,并重复贪婪搜索。
④最后细化: 这一过程一直持续到最底层,再最底层进行最后的细化步骤,找出最近的邻居。
3) 重要的参数
HNSW的性能取决于控制图结构和几个关键参数:
①M: 图中每个节点在层次结构的每个层级所能拥有的最大边数或连接数。M越大,图密度越高,召回率和准确率越高,内存消耗越大。
②efConstruction: 索引构建过程中考虑的候选节点数量,越高则图的质量越好,构建时间越长。
③ef: 搜索过程中评估的邻居数量。增加ef可以提高找到最佳邻居的可能性,但会增加搜索时间。
3、 DISKANN索引的Vamana图
这是一种基于磁盘的图形索引,可将数据点(或向量)连接起来,以便在搜索过程中高效导航。它是DISKANN算法基于磁盘策略的核心的数据结构部分。它可以处理非常大的数据集,因为在构建过程中或之后,它不需要完全驻留在内存中。
1) Vamana图的构建过程
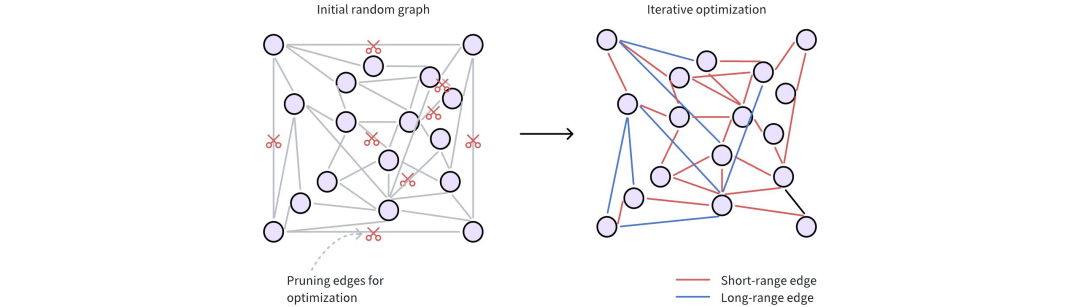
①初始随机连接: 每个数据点(向量)在图中表示为一个节点。这些节点最初时随机连接的,形成一个密集的网络。通常情况下,一个节点开始时会有大约500条边(或连接),以实现广泛的连接。
②细化以提高效率: 初始随机图需要经过优化过程,以提高搜索效率。这包括两个关键步骤:
- 修剪多余的边:算法根据节点之间的距离丢弃不必要的连接。这一步优先处理质量较高的边。
- 添加战略捷径:Vamana引入了长距离边,将向量空间中相距甚远的数据点连接起来。这些捷径允许搜索在图中快速跳转,绕过中间节点,大大加快了导航速度。
2) ANN搜索过程
DISKANN的建立索引后,将执行ANN搜索具体过程如下:
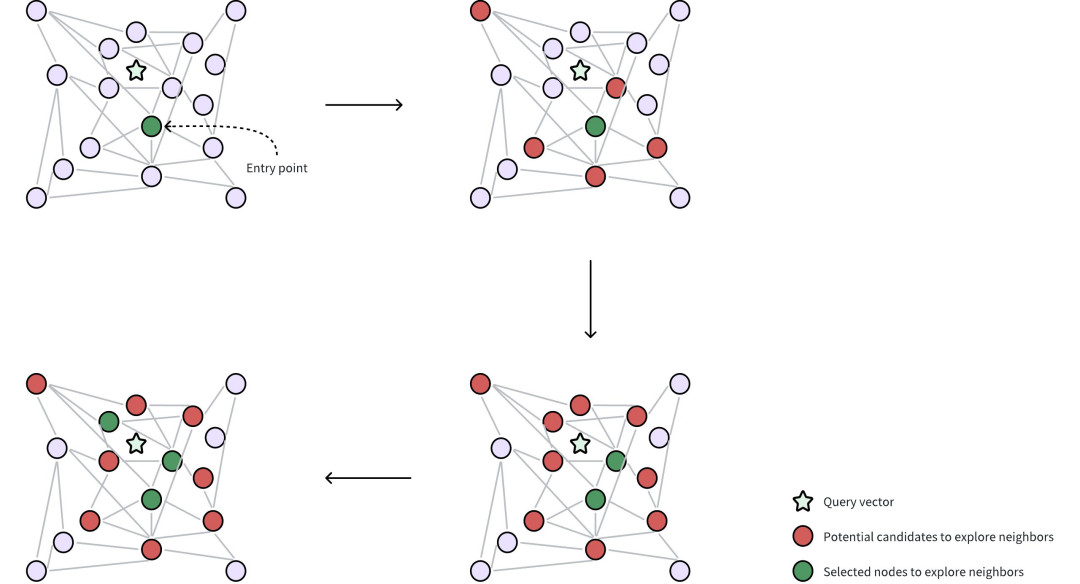
①入口点: 提供一个查询向量以定位其最近的邻居。DISKANN从Vamana图中选定的入口点开始,通常时数据集全局中心点附近的一个节点。全局中心点代表所有向量的平均值,这有助于最小化图中的遍历距离,从而找到所需的邻居。
②邻居搜索: 该算法从当前节点的边缘收集潜在的候选邻居。利用内存中的PQ码来估算这些候选邻节点与查询向量之间的距离。这些潜在的候选邻节点是通过Vamana图中的边直接连接到所选入口点的节点。
③选择节点进行精确距离计算: 在近似结果中,选择最优希望的邻节点子集,使用他们未经压缩的原始向量进行精确的距离评估。这需要从磁盘中读取数据,非常耗时。
3) 重要参数
max_degree 参数限制了每个节点的最大变数。max_degree越高,图的密度越大,有可能找到更多相关的相邻节点(召回率更高),但也会增加内存使用量和搜索时间。
search_list_size 参数决定了图细化过程的广度。较高的search_list_size可以在构建过程中扩展对邻接节点的搜索,从而提高最终准确性,但会增加索引构建时间。
DISKANN使用两个参数来控制精度和速度之间的微妙平衡:
① beam_width_ratio: 一个控制搜索广度的比率,它决定了有多少候选邻节点会被冰箱选择以探索其邻节点。beam_width_ratio越大,搜索范围越广,可能带来更高的精度,但也会增加计算成本和磁盘I/O。公式如下:
Beam width = Number of CPU cores * beam_width_ratio
② search_cache_budget_gb_ratio: 为缓存频繁访问的磁盘数据而分配的内存比例。这种缓存有助于最大限度地减少磁盘I/O,使重复搜索更快,因为数据已经在内存中。
迭代探索: 搜索会迭代完善候选集,反复执行近似评估,然后进行精确检查,指导找到足够数量的邻节点。
四、 Quantization
1、 FLAT(扁平索引)
这个是最简单的,可以认为是不做任何存储结构改变,把向量平铺在内存里面。它要把所有的实体都算一遍,所以它慢,但是召回率是100%。我看起来觉得,这个量化就其实就是没有量化编码。官方的介绍说它无需任何高级预处理或者数据结构。硬算两个向量的距离。可以姑且,把它理解为向量查询的一种最原始的基础处理方式。
2、 SQ8 Scalar Quantization
后面这个8,表示8位的整数。这是一个减少高维度向量空间大小的技术,它用更小更紧凑的形态来显示,可以使得计算过程中的内存量大幅的减少。可以理解为某种编码和压缩的算法。SQ8算法,是一个正态化的过程。分为3个步骤:
1)范围识别,找出向量的最小值和最大值。
2)归一化或者翻译为正态化, normalized_value = (value - min) / (max - min)
3)8位压缩,将上面这个值乘以255
这样实现快速搜索和高效的内存使用。
除此之外,SQ8的压缩过程应该还有一个好处,就是使得向量的各个维度都标准化了。可以想象一下,假设向量的某一个维度,它的数值都非常的巨大,另一个维度,它的数值都很小。这样在平铺形态下,这个数值大的维度,明显对距离的影响就会表较大。SQ8之后,明显使得各维度的权重均衡了。
3、 PQ, Product Quantization乘积量化
它是针对高维向量的压缩方法。它的流程如下:
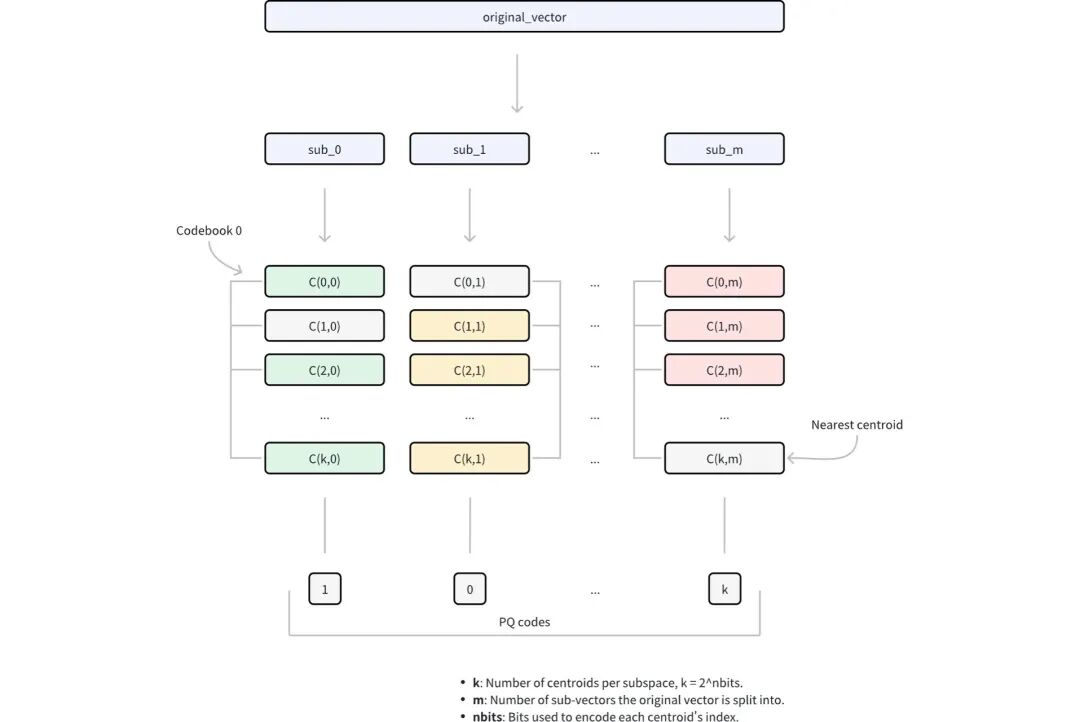
- 维度分解: 先将高维向量分解为m个大小相等的子向量。这种分解将原始的 D 维空间转换为m不相交的子空间,其中每个子空间包含D/m维。
- 子空间编码本生成: 在每个子空间里,用k-means聚类来找到一组代表性向量(中心点)。这个步骤,是PQ算法里面,最难理解部分。所谓编码本,其实是K个向量,也就是这一组子向量的K个中心点。假设这K个中心点的编号,是1,2,3……K。形成了一组参考系。
- 向量量化: 把原始向量中的每个子向量,找到每个子空间里,最邻近的中心点。假设某个向量的第一个子向量距离第3个中心点最近,第二个子向量距离第8个中心点最近。
- 压缩表示: 它就会压缩成(3, 8, ……)这样的形式。由m索引组成,每个子空间一个索引,统称为PQ编码。这种编码方式将存储需求从D × 32位(假设为 32 位浮点数)减少到m×nbits位,在保留近似向量距离能力的同时实现了大幅压缩。
1) 使用 PQ 计算距离
在使用查询向量进行相似性搜索时,PQ 可通过以下步骤实现高效的距离计算:
①查询预处理
将查询向量分解为m个子向量,与原始 PQ 分解结构相匹配。
对于每个查询子向量及其相应的编码本(包含2 nbits 中心点),计算并存储与所有中心点的距离。
这将生成m查找表,其中每个表包含2 nbits 距离。
②距离近似
对于任何由 PQ 代码表示的数据库向量,其与查询向量的近似距离计算如下:
对于m的每个子向量,使用存储的中心点索引从相应的查找表中检索预先计算的距离。将这些m距离相加,得出基于特定度量类型(如欧氏距离)的近似距离。
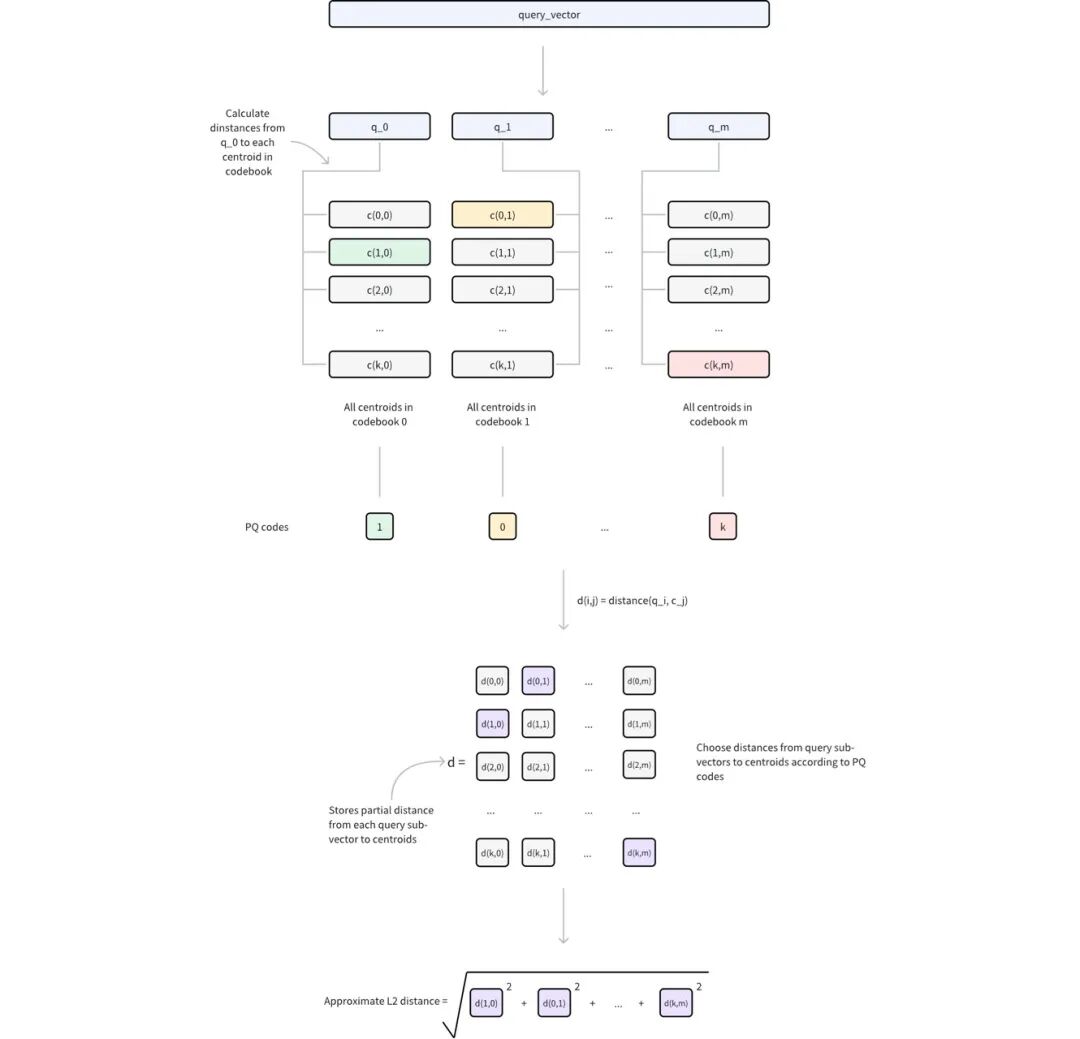
这样量化之后,计算距离的时候,其实就不是精准计算每个向量,而是计算距离最靠近的子向量中心点的距离,再把子向量距离叠加出一个近似的距离。这个叠加可能是某种特定计算,比如欧式距离。这里的好处是,子向量的中心点到各子向量的距离是可以在索引建立的时候提前算好的。实际的查询过程中,距离的计算量得到了大幅的削减。
2) 重要的参数
显然,子向量的中心点个数K是非常重要的参数,它由参数 nbits 决定,中心点的个数有 2^nbits 个。它意思就是说 ,在存储的时候,用几位存储来表示这个K的编码。8位编码,就自然可以表示256个不同的中心点K。
4、 RABITQ
RABITQ量化算法,发表于2024年的SIGMOD,是一个比较新的技术,相对于前面的算法,也是最难理解的一个。它提出强调了严格的理论误差界限,同时提供了良好的实证准确性。要理解它的实现,需要先铺垫一些高维向量的数学知识。
引用该算法作者博客介绍的例子,任意一个单位向量(长度为1的向量),设为X。假设有一个场景,我们关注它在某一个分向量上的投影,定义为X[0]。但是由于一些原因,我们不能直接计算,只能评估它的大致范围。因为它的长度是1,所以X[0]的取值范围一定分布在[-1,1]。
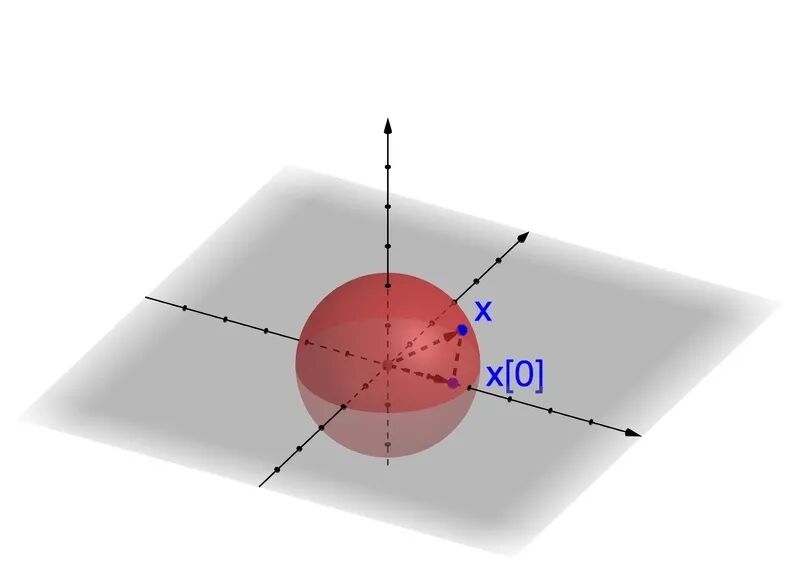
接下来,考虑一个随机的单位向量,均匀分布在一个单位球面上,这以为这球面每一个点的概率都相等。通过深入观察,产生一些随机的向量,然后测量X[0]的值,可以发现,在3维空间里,X[0]可能会取到[-1,1]之间的任意值。而在1000维的向量时,尽管X[0]的可能的范围空间还是[-1,1],但是实际上,x[0],密集的集中在了0的周围。
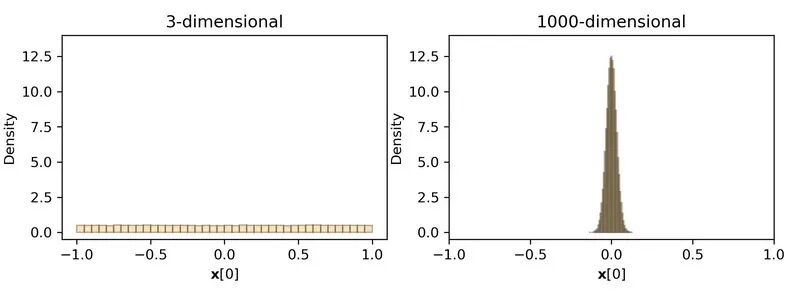
从而得出一个重要的概念:在高维空间中,随机性可以出人意料地提升确定性。这个现象又被称之为测度集中现象,是高维几何和概率的一个基本规则。从数学的角度来理解。一个X的单位向量,它长度为1,根据向量求模公式:
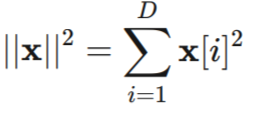
当维度D为3的时候,每一个项贡献的总长度的1/3,其中一项贡献多于50%的概率还是比较大的,当维度D为1000的时候,它的长度就又1000项来组成,每一项占1/1000.如果还有单一项超过50%,这就要求其他项贡献的长度,大幅低于平均,那对于某个场景,就是极其罕见的了。所以,在高维空间,X[0]不太可能偏离0。所以根据约翰逊-林登斯特劳斯引理Johnson-Lindenstrauss(JL) Lemma。X[0]的值偏离0的值不太可能大于 2/√D。
那么这个在高维空间的集中现象,就产生了一些重要的意义。例如,当维度D非常大的时候呢,x[0]就会在很严格的边界范围之中。在高维空间里,X[0]的不确定性大幅的缩减。而且,不需要经过任何计算,它是免费没有代价的。这个现象就提供一个提升算法的机会,并且是没有额外开销的。
RABITQ和它的扩展,基本上可以被当作一个二进制或者标量数据的量化优化方案。RABITQ就是通过刚才的这个免费的信息的有效利用,从而获得了良好的性能表现。
1) RABITQ索引构建流程
第一步:标准化
or和qr分别代表数据向量和查询向量。现在,已估算它们之间的欧几里得距离来作为目标。让c来作为数据向量的中心数据向量。为了简化距离估算问题,我们先把问题简化成单位向量之间的内积估算,考虑以中心为基准,对向量标准化处理。
我们取 o := (or - c) / || or - c ||, q := (qr - c) / || qr - c ||
然后用下面的等式,我们可以把距离估算的问题,简化成一个单位向量的内积估算。
|| or - qr ||^2 = ||( or - c) - ( qr - c) ||^2 = ||( or - c)|| ^2 + ||( qr - c)|| ^2 - 2 * ||( or - c)|| * ||( qr - c)|| * <q, o>
这里 ||( or - c)|| 可在索引构建时计算, ||( qr - c)|| 在查询时要算一次,然后用于所有的数据向量都可以共享。所以,问题就被简化成估算 <q, o>。直觉上看,标准化之后,可以把一组向量集集中在空间中心,并且将他们进一步对齐在一个单位球面上。因此,这个操作把数据向量都均匀地分摊到了单位球面上。
第二步:构建码表
鉴于,原始的数据向量转化成单位向量,会均匀地分布在单位球面上,我们需要也构建一个均匀分布在单位球面上的码表。所以,我们采用一种自然的构造方法,在高维单位球面嵌套一个超立方体。
然后,要利用好高维空间的集中现象,给码表注入一些随机性来旋转,来解决方向的偏好性。
这个随机旋转的地方是非常抽象难以理解的。我不确定理解是否正确,我的大致思路是:因为前文的x[0]其实表示的可能是向量的任意的一个分向量的投影。它的理论值本来应该是[-1,1]。如果向量在x[0]这个方向的分向量很大,那么这个向量就有这个方向的偏好。在高维的空间随机旋转之后,根据前面的引理,x[0]的值就大概率近似为0了。也就是消除了这个方向的偏好。
然后,为每一个向量o,找到一个码表中最接近的向量o’,这个o’肯定是在超立方体上,所以每一个维度可以用1个BIT来存储。
2) Milvus 的RaBitQ的索引构建
①确定编码本codebook。 类似于之前,编码本用一个存储空间较小的内容,用以标识和替代一整个维度的向量。归一化之后,数据点就分布在单位超球面上。所以编码本大约就是一个 C:={(∓1/√D, ∓1/√D, ∓1/√D,……., ∓1/√D)} 这样的东西,最多2D个。
②为了解决某些方向“偏好”,再使用随机正交矩阵P,来对CODEBOOK里所有向量做一次旋转,去除方向偏好的影响。
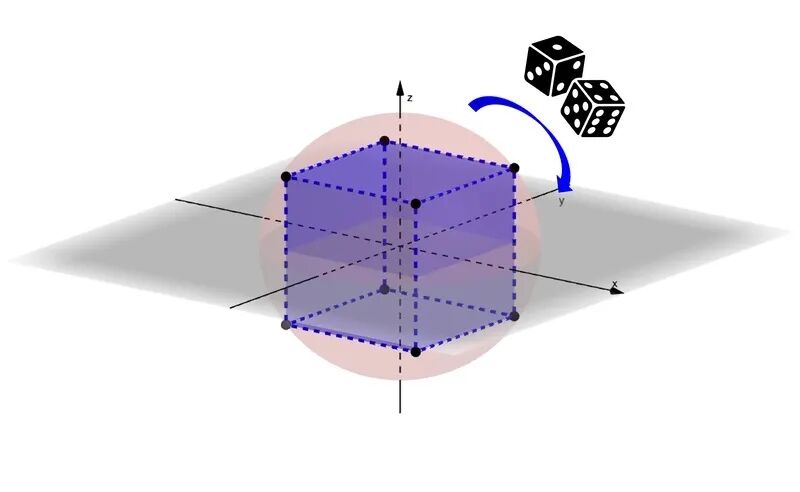
③根据新的CODEBOOK,量化向量,先找到距离向量最近的码表中的中心点向量。也就是找到码表里每一维正负号相同的码表向量就可以了。
3) RaBitQ的查询阶段
这时候,要基于上面量化锅向量,来构建一个估算 <q, o> 内积的方法。为此,我们先分析向量 o, q 和 o’ 的几何学关系。
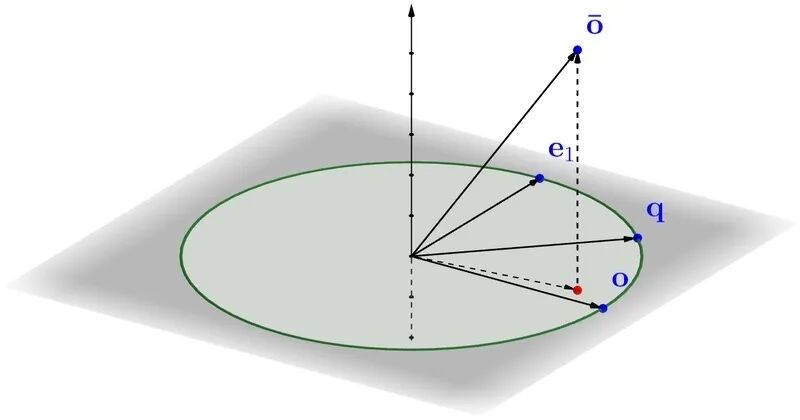
尽管 o, q 和 o’ 是高维向量,要估算 <q, o>,先关注2为平面上。
这里有一个 e1 的单位向量,它和 o 在平面上是垂直的。通过分析向量在平面上的几何关系,我们推导下列等式。
<o’, q> = <o’, o>*<o, q> + <o’, e1>*√(1-<o, q>^2)
这就是说,如果我们知道 <o, q> 以外的所有变量,我们就可以准确地计算出 <o, q>。 <o’, o> 还可以在建索引时算好。 <o’, q> 可以在查询过程中,通过一些巧妙的方法来计算。然后,由于聚集现象的发生, <o’, e1> 大概率集中在了0附近。把它当0来处理,就可以极大地简化计算过程。
所以 <o, q> ≈ <o’, q> / <o’, o>
对任何的向量O的量化步骤如下:
- 保存构建CODEBOOK时用的随机正交矩阵P;
- 计算
P^{-1} * O;
- 取
P^{-1} 每一维的正负号;
- 用P对量化后的向量反变换,得到最终的量化结果。
根据milvus官网,因为 o’ 是存储在索引中,量化的二进制向量。二进制的性质就使得距离计算极快,这受益于现代CPU架构。官网列举了英特尔IceLake+或者AMD Zen 4+两款硬件产品,并且强调了RABITQ索引的性能对硬件严重依赖。
5、 PRQ(残差产品量化)算法
这个量化算法是HNSW索引结构中新出现的。按官网说法,PRQ算法超越了传统的PQ,引入了残差量化来捕捉更多信息。可以实现更高的精度或更紧凑的索引。不过额外的步骤,需要索引构建和搜索过程的计算开销增加。
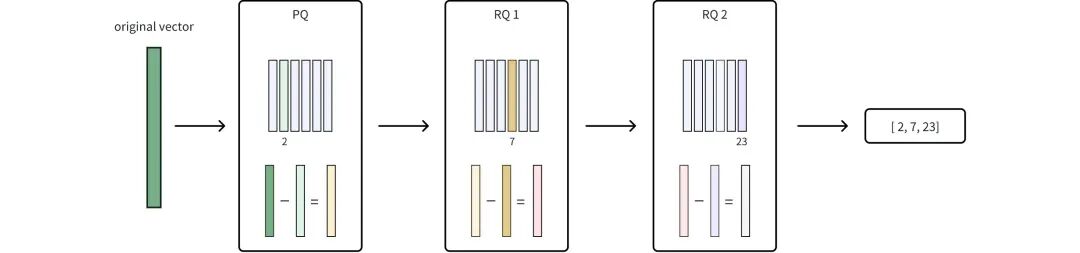
工作原理:
1)乘积量化(PQ), 和之前一样,把原始向量划分为子向量,用码本上子向量替换。
2)残差量化(RQ), 在PQ阶段之后,RQ使用额外的编码本量化残差,也就是原始向量与其基础PQ的近似值之间的差值。因为残差通常要小很多,因此可以在不增加大量存储空间的情况下,对其进行更精确的编码。参数 nrq 决定了残差被迭代量化的次数,让你可以微调压缩效率和精确度之间的平衡。这里我理解就是残差再残差,不断循环。
3)最终压缩表示。 RQ完成对残差的量化后,PQ和RQ的整数代码将合并为一个压缩索引。通过捕捉PQ可能忽略的精细细节,RQ在不显著增加存储空间的情况下提高了精确度。PQ和RQ协作定义为PRQ。
6、 SCANN索引的anisotropic vector quantization算法
这个基于GOOGLE的SCANN库。SCANN在分区后采用一种称为 anisotropic vector quantization 的方法。这个 anisotropic 是一个物理学术语,描述物质在不同测量方向呈现差异化物理特性的特性。传统的量化侧重于最小化原始向量和压缩向量之间的距离。这对某一些 Maximum Inner Product Search (MIPS) 任务来说是不理想的。因为在这类任务中,相似性是由向量的内积而不是距离决定的。
什么是相似性由内积决定,而不是距离?我是这么理解,向量的内积公式是:
a·b = |a||b|cos(a, b)
cos(a, b) 表示向量 a和 b之间的夹角,当两个向量垂直时, a·b 为0。说明这里的相似性,更加强调的是方向的相似性。而不强调某一个方向的大小差异。比如,我要寻找一本向量数据库的书籍。可能更关心,书里的内容是否出现过“向量”或“数据库”或其他关键字。而不是特别关系“向量”这个词或者其他无关方向的词出现了100次,还是10000次。
anisotropic vector quantization 优先保留向量之间的平行分量,或对计算精确内积最重要的部分。通过这种方法,SCANN可以仔细地将压缩向量与查询对齐,从而保持较高的MIPS精度,实现更快、更精确的相似性搜索。
五、 其他
以上数据结构和量化算法相互结合,也就对应了Milvus的某种索引。此外还有几个专门场景的。
1、 AISAQ索引
这是一种基于磁盘的向量索引,是DISKANN进行了扩展,AISAQ将所有数据保存在磁盘上。提供两种模式平衡性能和成本。AISAQ索引推荐使用于向量数据集过大,内存放不下,需要降低内存需求的时候。AISAQ提供两种基于磁盘的存储策略。主要区别在于如何存储PQ压缩数据。
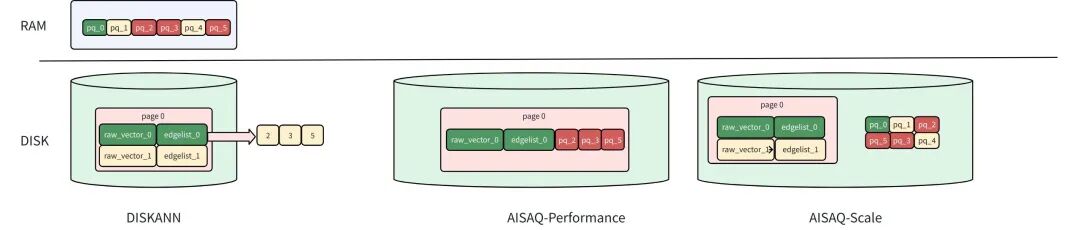
1) AISAQ-performance
通过将PQ数据从内存移至磁盘,实现完全基于磁盘的存储,通过数据主机托管和冗余保持低IOPS。在这种模式下
- 每个节点的原始向量、边缘列表及其邻居的PQ数据都一起存储在磁盘上。
- 这种布局可确保访问一个节点仍然只需要一次磁盘I/O。
- 由于PQ数据被冗余存储在多个节点附近,索引文件大小会显著增加,消耗更多磁盘空间。
2) AISAQ-scale
专注于减少磁盘空间的使用,同时将所有数据保留在磁盘上。
在这种模式下
①PQ数据单独存储在磁盘上,没有冗余。
②这种设计最大限度地减小索引大小,但在图形遍历过程中会导致更多的I/O操作。
③为了减少IOPS开销,AISAQ引入了两种优化方法:
- 重新排列策略,按优先级对PQ向量进行排序,以提高数据的位置性。
- DRAM中的PQ缓存(
pq_cache_size ),用于缓存频繁访问的PQ数据。
AISAQ-scale比DISKANN存储效率更高,性能更低。
2、 二进制向量索引 MINHASH_LSH
MINHASH_LSH算法关注的是大规模机器学习数据集中的高效去重和相似性搜索。特别是像为大语言模型(LLM)清理训练语料库这样的任务。实现快速、可扩展和精确的近似数据去重。
- MinHash: 快速地产生压缩签名(或指纹)来估算文档的相似性。
- Locality-Sensitive Hashing (LSH): 根据MinHash签名快速查找相似文档组。
以上的表述还是稍微抽象了一点。从字面意思来理解,MinHash通过压缩,来产生一个较小的用于计算的签名集合,以达到索引减少无关数据读入的一个目标。而后者就是在压缩后的数据上快速计算的过程。
1) Jaccard相似性
集合A和集合B的相似程度,定义如下:
J(A, B) = |A∩B| / |A∪B|
其中,其值范围从0(完全不相交)到1(完全相同)。
然而,在大规模数据集中精确计算所有文档之间的Jaccard相似性,当n较大时,时间和内存方面的计算成本很高 O(N^2)。这使得它在如LLM训练语料清理等用例中不可行。
MinHash签名近似Jaccard相似性。它是一种概率技术,它提供了一种估算Jaccard相似性的有效方法。它的工作原理是把每个集合转换为一个紧凑的签名向量,保留足够的信息来有效近似集合相似性。
也就是,两个集合越相似,他们的MinHash签名越可能匹配到相同位置。
2) MinHash处理过程包括:
①Shingling
将文档转换为一个overlapping token sequences (shingles)。这个指在序列处理中,不同位置的token存在部分重叠的现象,常见于自然语言处理(NLP)等领域。shingle这个词有建筑中木瓦,或者地理中碎石滩的意思。
②HASH
对每个shingle使用多个独立的HASH函数。
③Min Selection
对于每个HASH函数,记录所有shingles的最小HASH值。
流程图如下:
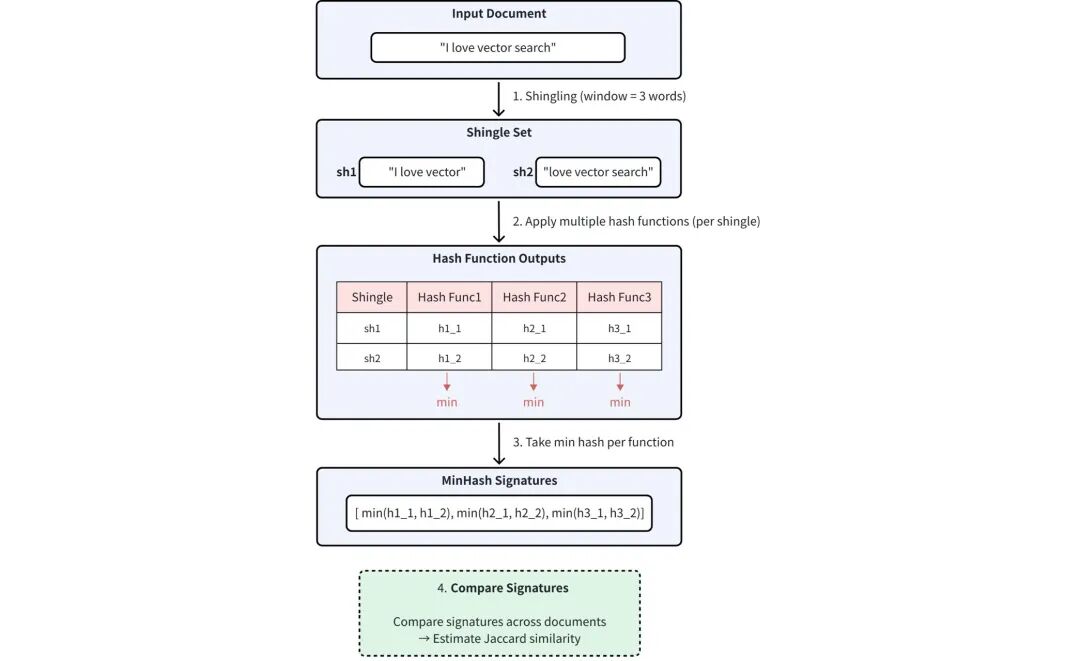
使用的HASH函数数量决定了MinHash签名的维度。维度越高,近似精度越高,但存储和计算量越大。
3) 用于MinHash的LSH
虽然签名大大降低了计算文档间精确Jaccard相似性的成本,但是穷举比较低效。使用LSH。LSH通过确保相似项目以高概率散列到同一个桶中,从而快速近似搜索。这个过程包括:
①签名分割
一个N维MinHash签名被分为b个BAND。每个包括r个连续的哈希值,总签名长度 n = b * r
② BAND散列
在分段之后,使用标准HASH函数对每个BAND都独立处理,把它分到一个桶中。如果两个签名在一个BAND里,产生了相同的HASH值,那么它们就被认为是潜在的匹配对象。
③候选者选择
在至少一个频段内发生碰撞的配对会被选为相似性候选。
有3个128维签名分为32个BAND。

用Hash函数散列到不同桶中,相同散列的就是相似性候选。文档AB相似,因为band0碰撞了。
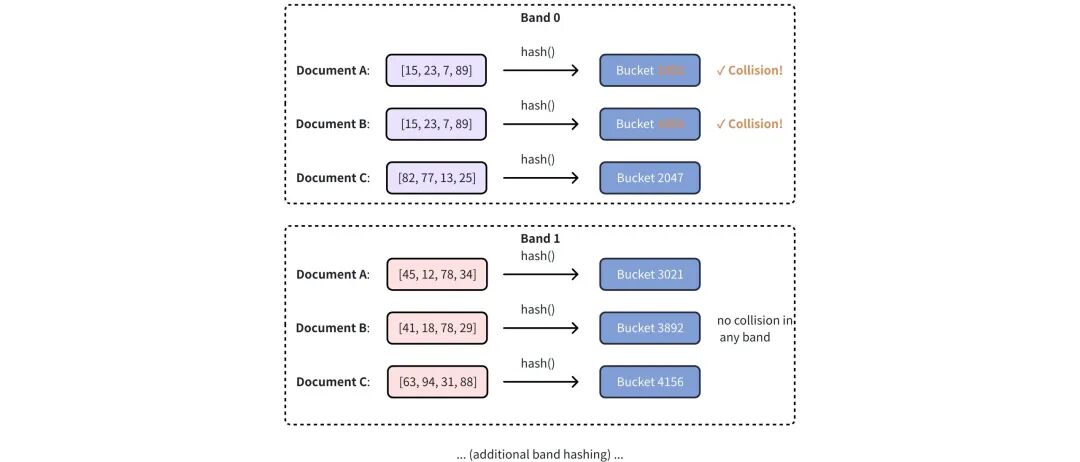
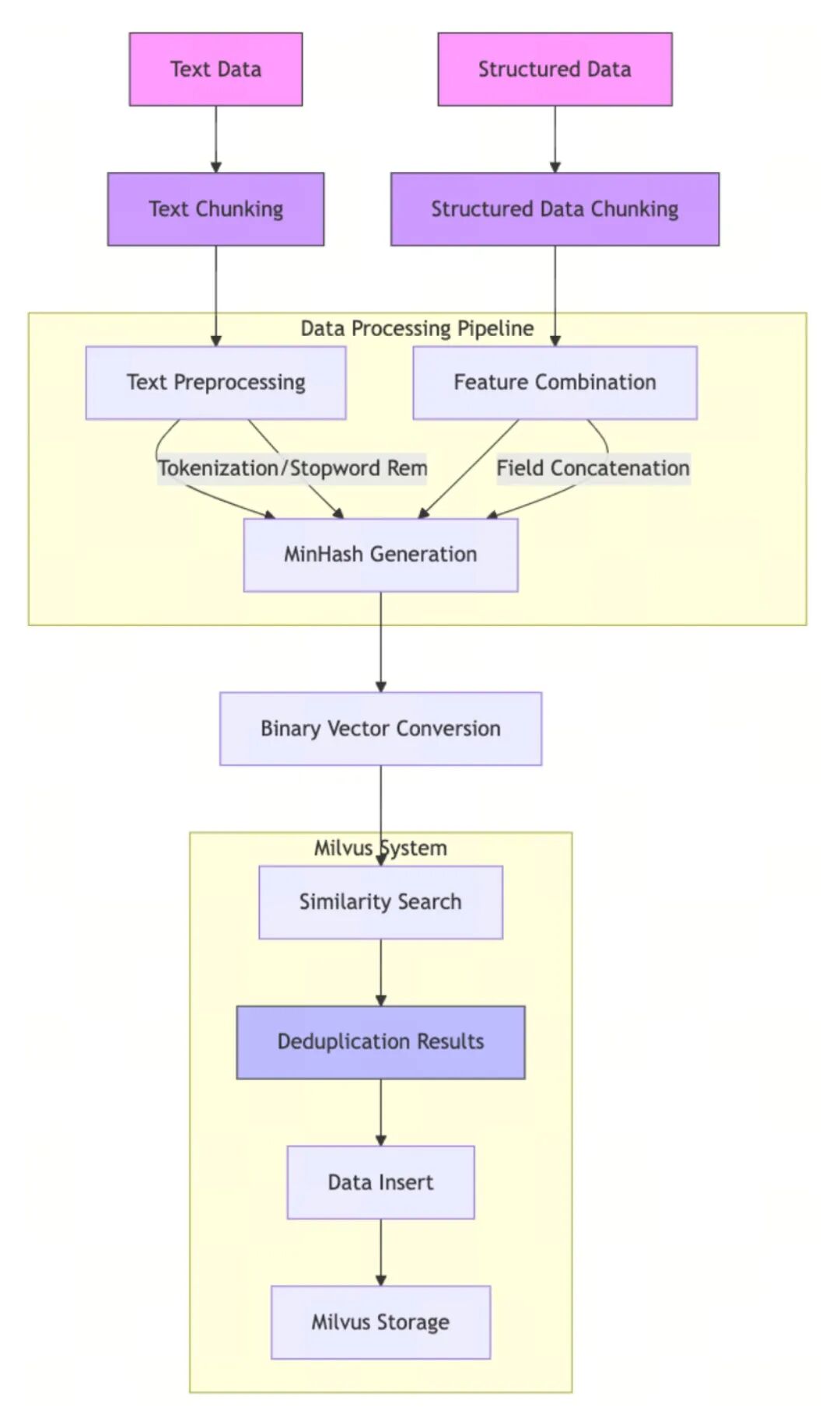
由 MinHash LSH支持的重复数据删除流程允许 Milvus 在将近乎重复的文本或结构化记录插入 Collections 之前,高效地识别并过滤掉它们。流程如下:
六、 未来的一些猜想
回忆了一下,上一次学习种类繁多的,五花八门的数据库索引,已经是很多很多年前的事情了。这大约是因为,越是成熟的数据库产品,越是朝着低使用门槛的路线发展,索引的类型越来越简明,开发者越来越不需要理解索引实现的细节。最新的一些产品,都已经可以支持数据库自我学习,自己选择和建立索引。
作为一个学习AI的新人和古老DBA,我猜未来的向量数据库索引或者是量化算法,也大约会从百花齐放,走向极少的几种,最终出现一两种力压群雄的通用算法,或者是数据库产品自己根据场景和查询来选索引和算法。对于一个希望深入理解并在Python等语言中实现相关算法的开发者而言,掌握这些底层原理至关重要。
 发表于 2025-12-17 02:53:24
|
查看: 192|
回复: 0
发表于 2025-12-17 02:53:24
|
查看: 192|
回复: 0
