PikiwiDB(Pika) 自 3.5.X 版本起,正式推出了基于 Codis 的分布式集群解决方案。该方案已在 360 内部搜索团队的生产环境中得到验证,展现出优秀的稳定性和性能。本文将深入解析其分布式架构、部署流程及核心组件的工作机制。
一、 分布式架构解析
PikiwiDB 分布式集群架构基于 Codis 进行改造设计,整体架构如下图所示:
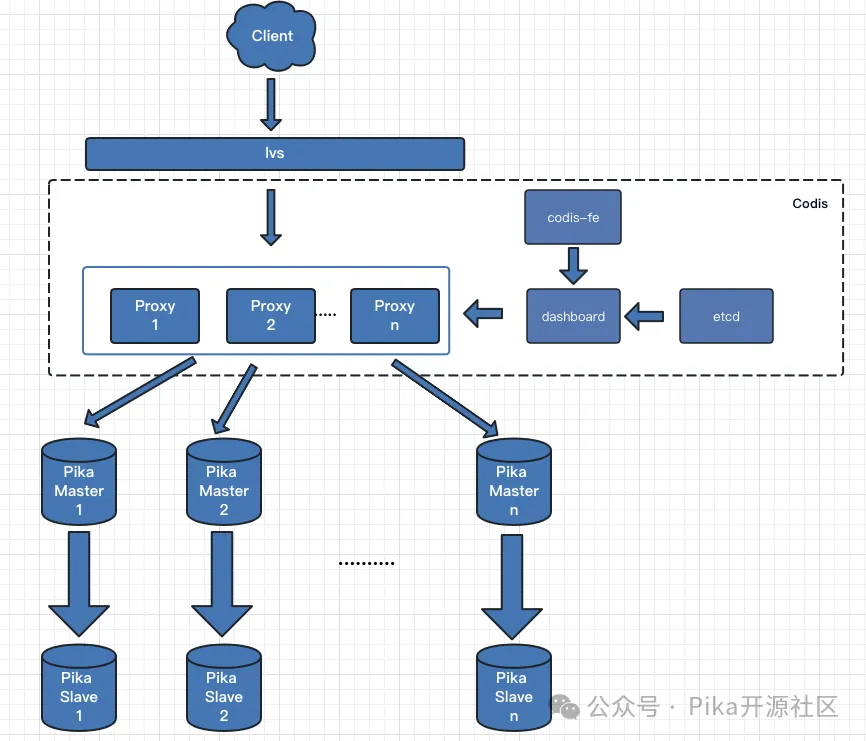
集群主要由以下核心组件构成:
- Pika Server: 数据存储节点,运行 PikiwiDB (Pika) 3.5.X 或 4.0.x 版本,其内部架构与单机版保持一致。
- Codis Proxy: 客户端的统一接入层。代理接收用户请求,通过计算请求 Key 的哈希值,将其转发到正确的 Pika Server 上执行。一个业务集群可以部署多个 Proxy 实例以实现负载均衡和高可用,它们之间的状态由 Codis Dashboard 保持同步。
- Codis Dashboard: 集群管理中枢。负责对 Codis Proxy、Pika Server 进行上下线管理、数据迁移等操作,并维护集群元数据的一致性。同一时间,一个业务集群中只能有一个 Dashboard 处于活跃状态。
- Codis FE: 集群的 Web 管理界面。可以通过配置文件管理多个后端的 Codis Dashboard,并自动更新集群状态视图。
- Codis Etcd: 用于存储集群的元数据信息(如 Slot 与 Group 的映射关系)。为保证高可用,建议部署为 3 节点集群。
二、 Sentinel 主从切换
为提升运维自动化水平,此版本集成了 Sentinel 以实现主从故障自动切换。当主节点发生故障时,Sentinel 能够自动将一个从节点提升为主节点,从而提供故障自愈能力,保障服务高可用。
三、 部署方式与流程
部署时可根据自身业务压力调整资源配置。以下为 360 搜索部门的参考配置:
| 组件 |
节点数量 |
实例规格(参考) |
| Pika Server |
12主 + 12从 |
20核,32G内存,200G磁盘 |
| Codis FE |
1 |
2核,4G内存 |
| Codis Dashboard |
1 |
2核,4G内存 |
| Codis Etcd |
3 |
2核,4G内存 |
| Codis Proxy |
4 |
2核,4G内存 |
集群创建与部署需按以下顺序进行:
- 启动所有 PikiwiDB (Pika) 实例。
- 建立 PikiwiDB 实例间的主从复制关系。
- 启动 Codis Etcd 集群。
- 启动 Codis Dashboard。
- 启动 Codis Proxy。
- 启动 Codis FE。
- 在 Dashboard 中将 PikiwiDB 与 Codis 集群进行绑定。
绑定操作在 Dashboard 的管理界面中完成,主要步骤为:
- 添加 Group: 一个 Group 对应一个 Pika 主从对。
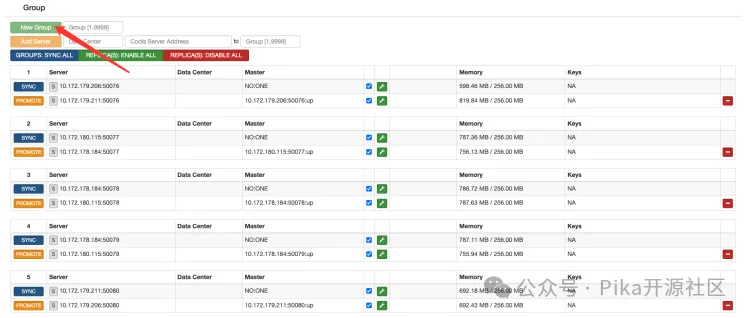
- 添加 Pika Server: 将 Pika 主节点和从节点的地址添加到对应的 Group 中。
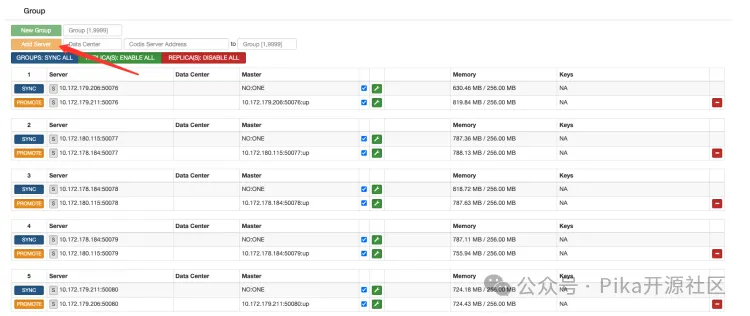
- 分配 Slots: 将 1024 个 Slot 均匀分配给各个 Group。

绑定完成后,客户端即可通过 Codis Proxy 提供的虚拟 IP 和端口访问集群。
四、 快速启动脚本
PikiwiDB-Codis 源码的 admin 目录下提供了一系列运维脚本,可以便捷地启停各个组件。
启动 Codis-dashboard
./admin/codis-dashboard-admin.sh start
tail -100 ./log/codis-dashboard.log.2017-04-08
若启动失败,请检查当前用户对默认元数据存储路径 /tmp/codis 是否拥有读写权限。
启动 Codis-proxy
./admin/codis-proxy-admin.sh start
tail -100 ./log/codis-proxy.log.2017-04-08
启动 Codis-server (Pika)
./admin/codis-server-admin.sh start
tail -100 /tmp/redis_6379.log
需注意 redis.conf 中 pidfile 和 logfile 的路径权限。
启动 Codis-fe
./admin/codis-fe-admin.sh start
tail -100 ./log/codis-fe.log.2017-04-08
五、 核心代码机制解析
1. Pika Server 的 Slot 数据管理
在 Codis 架构中,数据按 Slot 分片存储。Pika 引擎内部的数据本身不携带 Slot 信息。为实现 Slot 粒度的高效迁移,Pika 内部为每个 Slot 维护了一个 Set 类型的 Key,用于记录该 Slot 中存储的所有用户 Key。此功能由配置参数 slotmigrate 控制是否开启。
当该功能开启时,Pika 在处理写命令后,会调用 AddSlotKey 函数,将 Key 及其数据类型追加记录到对应 Slot ID 的 Set 中。这为后续的批量迁移提供了便利。以下以 MSET 命令为例:
void MsetCmd::Do(std::shared_ptr<Slot> slot) {
storage::Status s = slot->db()->MSet(kvs_);
if (s.ok()) {
res_.SetRes(CmdRes::kOk);
std::vector<storage::KeyValue>::const_iterator it;
for (it = kvs_.begin(); it != kvs_.end(); it++) {
AddSlotKey("k", it->key, slot); // 记录Key到对应Slot的Set中
}
} else {
res_.SetRes(CmdRes::kErrOther, s.ToString());
}
}
AddSlotKey 函数的核心逻辑是计算 Key 的 Slot ID,并将其存入对应的 Set。这本质上是一种利用 数据库/中间件 自身能力实现的元数据索引机制。
2. Slot 迁移机制
Pika 的 Slot 迁移由 PikaMigrateThread 和 PikaParseSendThread 两个核心类协作完成。
- PikaMigrateThread: 作为管理线程,负责调度迁移任务。它从两个来源收集待迁移的 Key:一是来自 Codis Proxy 的异步单 Key 迁移命令;二是通过遍历 Slot 对应的 Set 来获取批量 Key。然后,它将 Key 放入待处理队列,并唤醒工作线程进行实际的数据迁移。
- PikaParseSendThread: 作为工作线程,负责具体的数据迁移逻辑。它从队列中消费 Key,根据 Key 的类型(String, Hash, List, Set, Zset)从底层的 RocksDB 存储引擎中读取完整数据,并打包发送到目标 Pika 节点。
PikaMigrateThread 的主循环会按批次执行迁移,每完成一批次后挂起,等待被下一次迁移任务唤醒。这种设计有利于控制迁移对正常服务请求的影响。
3. Codis Dashboard 的关键逻辑
Dashboard (Topom 结构体) 是集群的“大脑”,它通过多个后台 Goroutine 持续维护集群状态:
- CheckMastersAndSlavesState: 周期性检测所有 Pika 节点的状态和主从关系。当发现 Master 节点连续异常达到阈值时,将其标记为客观下线,并触发自动故障转移(Failover),从该 Group 的可用 Slave 中选举新的 Master。
- ProcessSlotAction: 执行 Slot 迁移任务。Dashboard 发起迁移计划后,会按顺序将 Slot 状态置为
Migrating,并通知相关 Pika Server 开始数据迁移,同时更新所有 Proxy 的 Slot 映射表。
- ProcessSyncAction: 处理 Group 内主从同步任务。例如,当新增一个 Slave 节点时,Dashboard 会向其发送
SLAVEOF 命令,使其从 Master 同步数据。
Slot Rebalance 流程: 这是实现集群数据均衡的核心功能。Dashboard 会计算当前各 Group 持有的 Slot 数量与平均值的差值,生成一个将 Slot 从“富余” Group 迁移到“不足” Group 的计划。这个集群管理过程考虑了离线 Slot 的分配和节点间负载的均衡,最终通过更新 Slot 的 Action.State 来触发 ProcessSlotAction 执行具体的迁移。
 发表于 2025-12-18 00:43:51
|
查看: 243|
回复: 0
发表于 2025-12-18 00:43:51
|
查看: 243|
回复: 0
