大语言模型的迅猛发展正在深刻改变我们的生活和工作方式。我们可以随时与诸如DeepSeek、ChatGPT或通义千问(Qwen)等AI助手进行对话,获取知识解答和灵感启发。这些模型在知识记忆、信息整合乃至逻辑推理方面展现出强大的能力。
那么,能否亲手打造一个完全离线、可随时携带并进行自然语音对话的AI设备呢?答案是肯定的。本文将详细介绍如何利用树莓派5(Raspberry Pi 5)作为核心硬件,结合 whisplay-ai-chatbot、Ollama、Whisper、Piper等一系列开源软件,从零开始组装并配置一个功能完整的离线语音聊天机器人。
视频展示了最终成品的交互效果。
整个系统的核心是树莓派,它负责运行Linux操作系统并集成AI聊天组件(包括whisplay-ai-chatbox、Ollama、Whisper、Piper),实现与用户的交互。其中,whisplay-ai-chatbox是语音交互软件框架,Ollama用于加载和运行Qwen3大语言模型,Whisper负责语音转文字,Piper则将文字回复转换为语音。所有这些软件均为免费开源。
以下将分步详解硬件组装与软件安装的全过程。
一、硬件组装
所需硬件清单:
- 树莓派5B主板(8GB RAM)
- Micro SD卡(建议32GB以上)
- Whisplay HAT显示屏
- 散热风扇
- 锂电池(PiSugar 3 Plus)
- 40针扩展排针
组装步骤如下:
首先安装散热风扇。


接着焊接并安装40针扩展排针。

然后安装PiSugar 3 Plus锂电池。

最后安装Whisplay HAT显示屏。


完成所有组装后的整体外观如下:

二、安装操作系统
- 将Micro SD卡插入电脑读卡器。

- 访问树莓派官网,下载并运行 Raspberry Pi Imager 软件。
- 在软件界面中:
- 设备(Device):选择 Raspberry Pi 5。
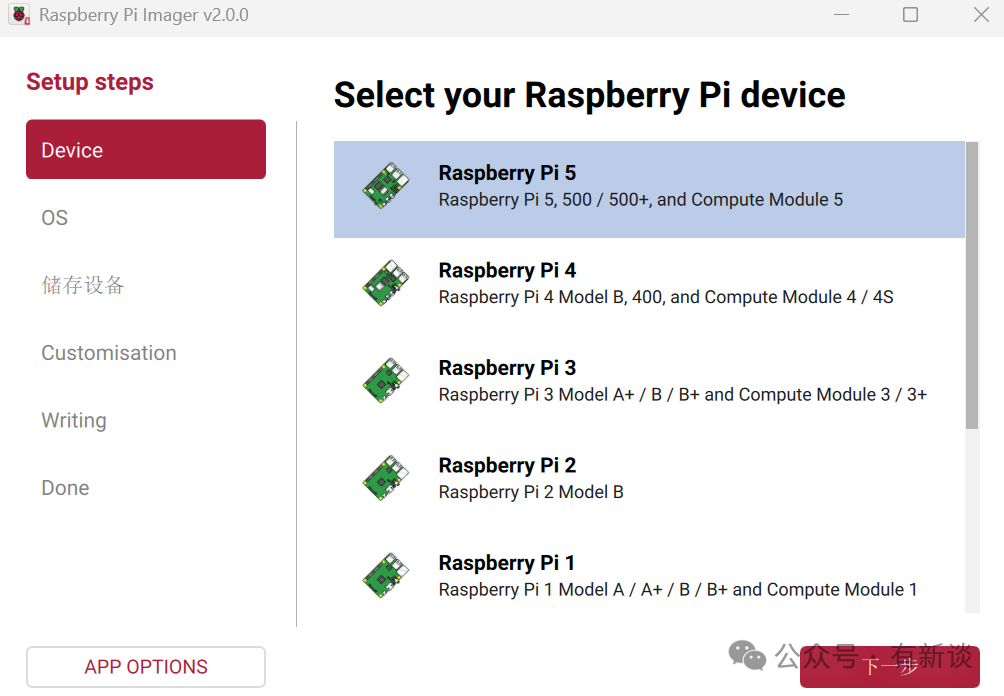
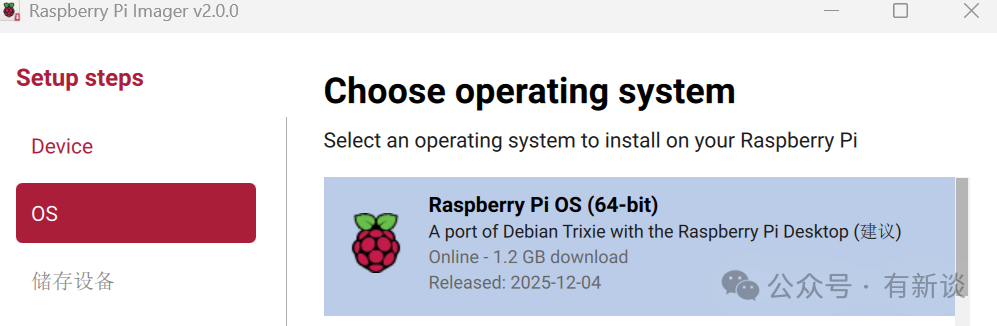
- 操作系统(Operating System):选择 Raspberry Pi OS(其他版本)。
- 存储(Storage):选择你的SD卡。

- 点击右下角的齿轮图标进行高级设置:
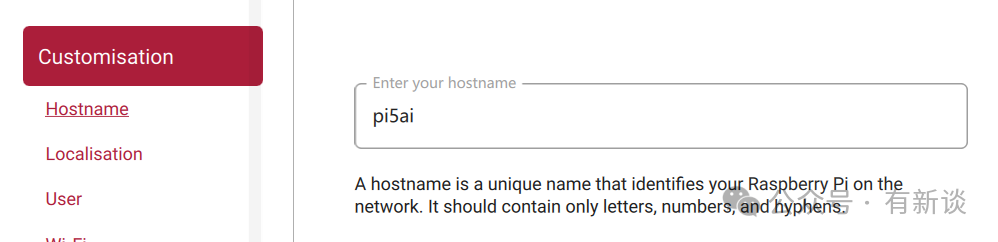
- 设置主机名(例如:
pi5ai)。
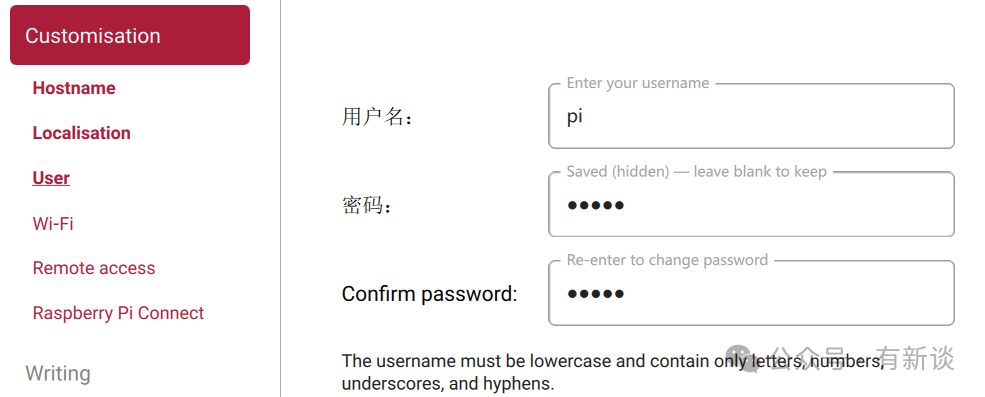
- 设置用户名和密码。
- 配置Wi-Fi网络。

- 务必启用SSH,并选择使用密码认证。

- 保存设置后,点击“写入(Write)”按钮。
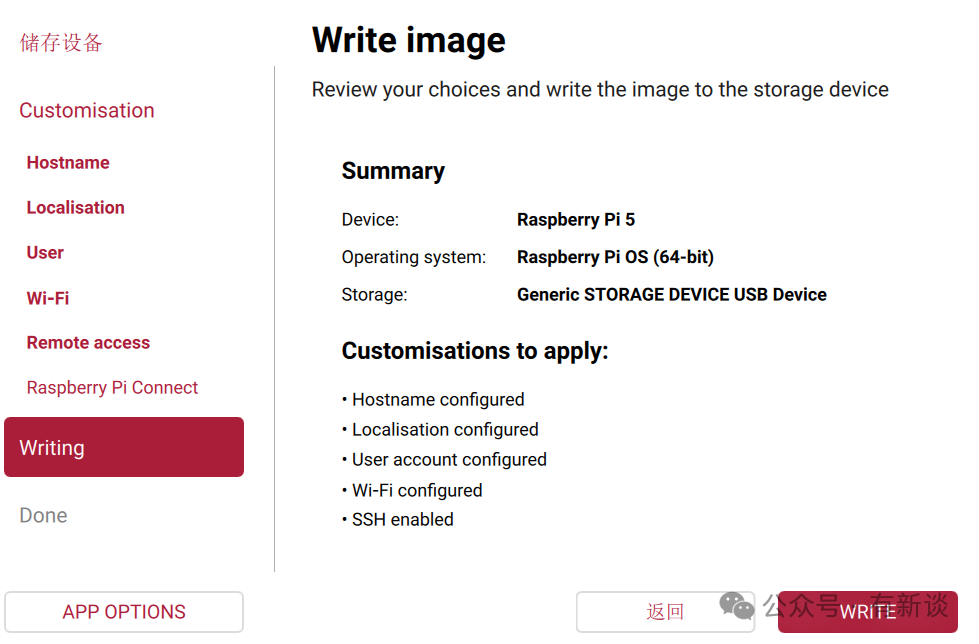
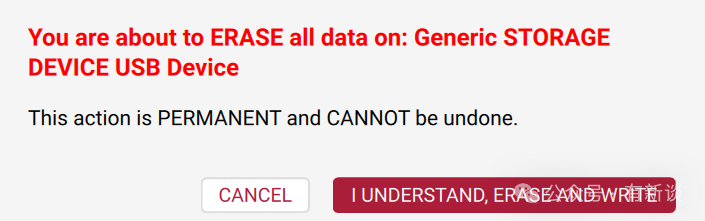
- 确认提示信息,该操作将擦除SD卡所有数据,请提前备份。
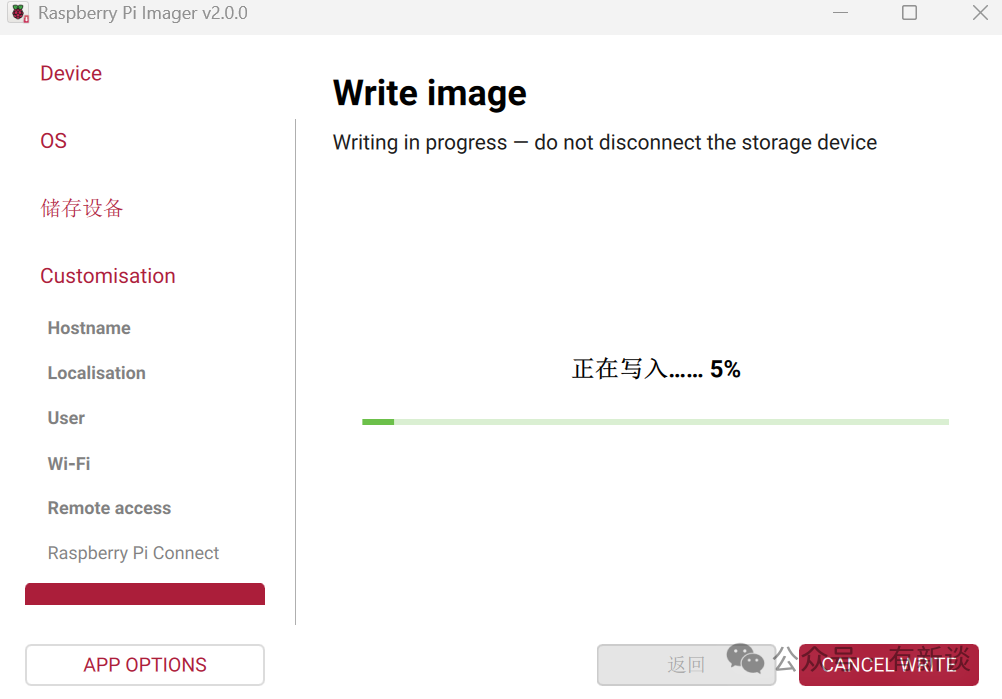
- 等待镜像烧录完成。
- 将SD卡插入树莓派5的卡槽。

三、开机登录系统
接通树莓派电源,观察电源指示灯闪烁。

登录路由器管理界面,查找主机名为 pi5ai 的设备并记下其IP地址。然后使用SSH终端工具(如Termius、WindTerm或系统自带的终端)进行连接,这是进行后续运维操作的起点。输入之前设置的用户名和密码。
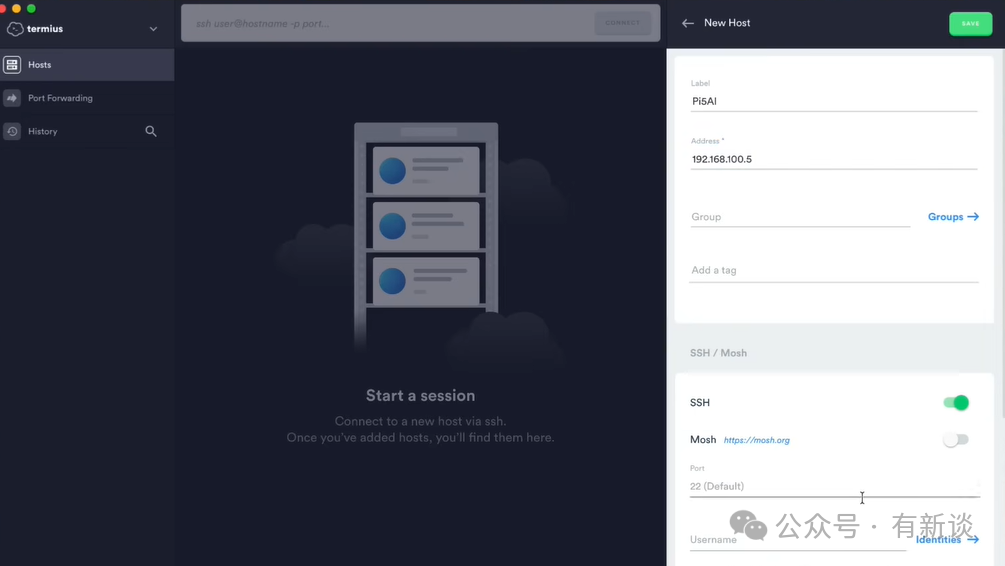
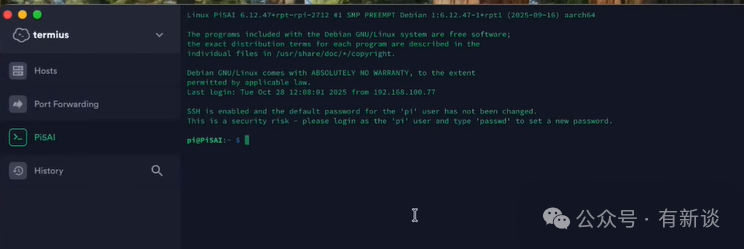
成功登录后,你将看到命令行操作界面。
四、应用软件安装
(一)安装PiSugar Whisplay HAT驱动程序
在用户主目录下,执行以下命令:
git clone https://github.com/PiSugar/Whisplay.git --depth 1
cd Whisplay/Driver
sudo bash install_wm8960_drive.sh
sudo reboot
重启后,进入示例目录测试驱动是否安装成功:
cd Whisplay/example
sudo python test.py

如果驱动正常,显示屏将开始显示测试图案。

(二)安装聊天机器人核心组件 (whisplay-ai-chatbot)
-
下载软件:
git clone https://github.com/PiSugar/whisplay-ai-chatbot.git
cd whisplay-ai-chatbot

-
安装依赖:
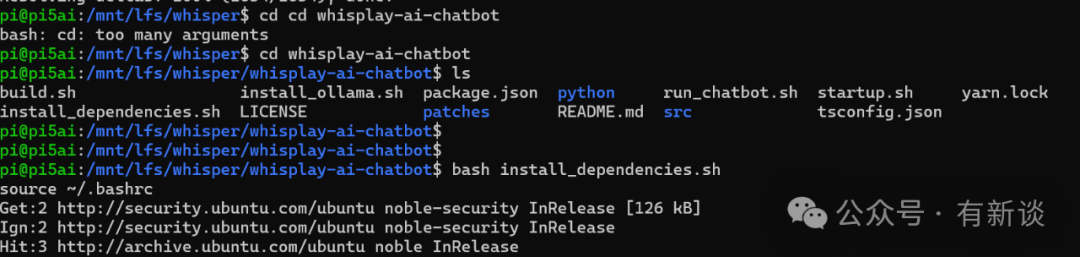
在 chatbot 目录下运行:
bash install_dependencies.sh
source ~/.bashrc

-
配置环境变量:
复制环境变量模板并编辑:
cp env.template .env
nano .env

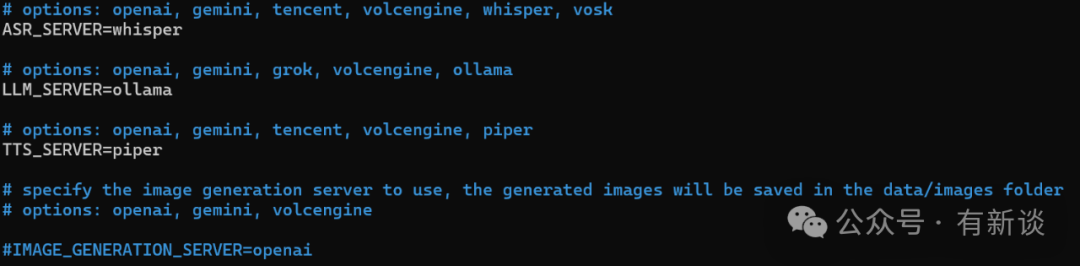
关键配置如下:
ASR_SERVER=whisper (语音识别使用Whisper)LLM_SERVER=ollama (大语言模型使用Ollama)TTS_SERVER=piper (语音合成使用Piper)- 注释掉
IMAGE_GENERATION_SERVER (禁用绘图功能以节省资源)
- 注释掉
THINKING_MODE=true (对于小模型,思考模式可能导致响应变慢)
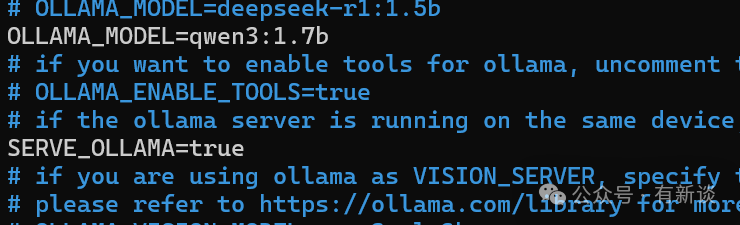
- 在
[ollama] 部分,设置 MODEL=qwen3:1.7b
- 设置
SERVE_OLLAMA=true (允许聊天机器人脚本自动启动Ollama服务)

保存并退出编辑器。
-
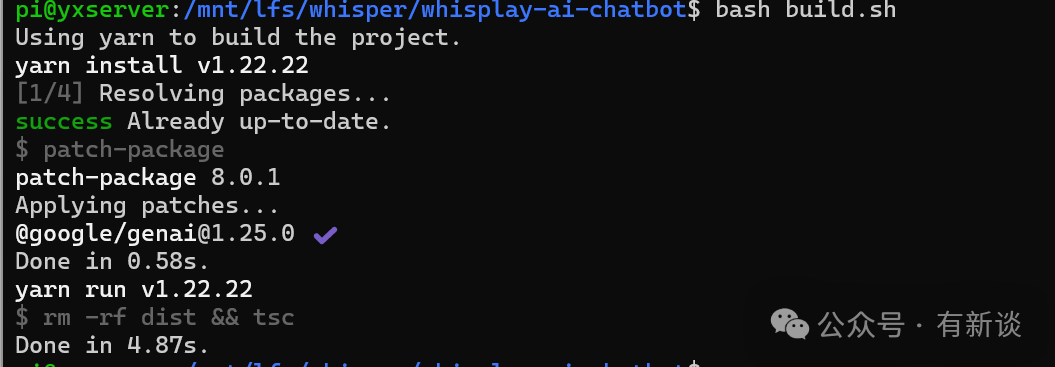
构建应用:
在 chatbot 目录下执行构建脚本:
bash build.sh
(三)安装与配置Ollama服务
-
安装Ollama:
可以通过官网脚本安装(较慢):
curl -fsSL https://ollama.com/install.sh | sh
或者在Windows电脑下载ARM64版本的压缩包 (ollama-linux-arm64.tgz),上传到树莓派的 chatbot 目录后,运行本地安装脚本:
bash install_ollama.sh

-
启动Ollama服务并下载模型:
在一个终端中启动Ollama服务:
ollama serve

打开另一个SSH终端,运行以下命令拉取Qwen3 1.7B模型(首次运行会自动下载):
ollama run qwen3:1.7b

下载完成后,即可在该终端内与模型进行文本对话测试。

(四)安装电池管理软件
安装PiSugar电源管理软件,用于显示电池状态:
wget https://cdn.pisugar.com/release/pisugar-power-manager.sh
bash pisugar-power-manager.sh -c release
(五)安装Whisper(语音转文字)
Whisper是OpenAI开源的语音识别引擎,可完全离线工作。使用Python的pip命令安装:
pip install -U openai-whisper --break-system-packages

安装后,可以使用以下命令测试是否安装成功(此命令仅为测试,无需等待执行完成):
whisper audio.flac audio.mp3 audio.wav --model tiny

(六)安装Piper(文本转语音)
Piper是一个高效的本地文本转语音引擎,针对树莓派做了优化。
-
安装Piper:
使用pip直接安装:
pip install piper-tts --break-system-packages
或者,更推荐使用虚拟环境安装:
# 1. 创建虚拟环境
python3 -m venv piper-env
# 2. 激活虚拟环境
source piper-env/bin/activate
# 3. 在虚拟环境中安装(无需--break-system-packages)
pip install piper-tts
使用 which piper 命令可以查看其安装路径。

-
下载语音模型:
访问Piper的GitHub页面或社区提供的模型库,选择并下载中文语音模型(例如 zh_CN-huayan-medium.onnx 及其对应的 .onnx.json 配置文件)。
将下载的模型文件(例如 zh_CN-huayan-medium.onnx)放置于用户目录下,如 /home/pi/piper/。

-
更新环境变量:
再次编辑 chatbot 目录下的 .env 文件,设置Piper的路径:
PIPER_BINARY_PATH=/usr/local/bin/piper # 或你的虚拟环境中的路径,如 /home/pi/piper-env/bin/piper
PIPER_MODEL_PATH=/home/pi/piper/zh_CN-huayan-medium.onnx

五、运行与对话
所有组件安装配置完成后,在 whisplay-ai-chatbot 项目目录下,运行启动脚本即可开始与你的离线AI机器人进行语音对话:
bash run_chatbot.sh
启动后,设备会进入语音唤醒状态,你可以通过语音与其自然交互。

相关资源链接
|  发表于 2025-12-19 03:26:51
|
查看: 389|
回复: 0
发表于 2025-12-19 03:26:51
|
查看: 389|
回复: 0
