当技术焦点仍集中在云端大模型的参数竞赛时,一个名为 Nexa SDK 的 GitHub 项目正将 AI 的推理能力下沉至终端设备。它致力于将“全能大脑”装入手机、电脑及边缘设备,实现免费用、免联网、高隐私的本地化人工智能体验。
通过一套统一的 SDK,该项目打通了从端侧推理引擎到软硬件协同优化的全链路,旨在消除手机、PC、汽车及 IoT 设备间的算力壁垒,让“随时随地用 AI”从概念变为触手可及的现实。

Nexa SDK 是由 Nexa AI 推出的端侧 AI 开发工具包。其核心是自研的 NexaML 推理引擎,能够跨平台深度适配 NPU、GPU 和 CPU,支持多模态模型的快速(Day-0)部署。凭借低代码特性与 OpenAI API 兼容设计,它助力开发者快速在移动设备、汽车座舱等场景构建高效的本地 AI 应用。
一、AI 落地的“最后一公里”:为何需要端侧推理?
当前,大模型的主要能力依然依赖于云端服务。尽管云端能提供强大的生成与推理能力,但其存在几个固有瓶颈:
- 网络依赖:必须保持稳定的网络连接,离线场景下功能完全失效。
- 隐私风险:用户数据需上传至第三方服务器,这对于金融、医疗等敏感行业是难以接受的风险。
- 延迟问题:网络传输带来的延迟,严重影响了如车载语音、实时翻译等需要即时交互场景的用户体验。
随着芯片技术的飞速发展,端侧部署的条件日趋成熟。手机中的 NPU(神经网络处理单元)、PC 的独立显卡/NPU 以及嵌入式设备的专用 AI 芯片,其算力已足以支撑一定规模的模型本地运行。用户的期待也从“云端调用”转向“设备内置”,追求 数据不出设备、响应实时触达、使用无需付费 的终极体验。
在此背景下诞生的 Nexa SDK,其定位并非单一工具,而是一套 一站式端侧 AI 推理与部署解决方案,覆盖从模型压缩、跨平台适配到快速部署的全流程,旨在攻克端侧 AI 开发中的兼容性、性能优化与易用性三大核心挑战。它的核心价值在于:支持 Hugging Face、魔搭社区等主流模型格式,兼容从高端手机到低功耗 IoT 设备的全硬件谱系,让开发者通过简单命令即可完成复杂模型的端侧部署,实现真正的“一次开发,多端运行”。
以下视频展示了 Nexa SDK 在安卓高通骁龙平台上的多模态能力,包括图片理解与语音识别。
[视频:高通骁龙平台演示]
2025年12月发布的 NexaSDK for Android (Beta) 版,由 Nexa AI 与高通联合打造,专为骁龙手机简化端侧AI部署。它能够调用 Hexagon NPU、Oryon CPU 和 Adreno GPU,例如使 Granite 4.0-h-350M 模型在 NPU 上达到 92 token/s 的推理速度,能效是 CPU 的 9 倍。该 SDK 支持多种模型,甚至包括高达 200 亿参数的 GPT-OSS-20B 模型(可在 RAM ≥16GB 的骁龙手机上运行),并承诺新模型可实现发布即(Day-0)可用。

(详见高通开发者博客:https://www.qualcomm.com/developer/blog/2025/11/nexa-ai-for-android-simple-way-to-bring-on-device-ai-to-smartphones-with-snapdragon)
二、技术解析:异构计算与全格式兼容如何实现?
端侧 AI 开发面临的核心痛点在于设备生态的碎片化。手机端的 Apple A 系列芯片与安卓骁龙芯片架构各异,PC 端的 CUDA 与 Metal 平台互不兼容,IoT 设备的低算力环境更是对模型效率提出了苛刻要求。以往,开发者需为不同平台编写专用代码,适配成本极高。
Nexa SDK 的解决方案立足于 “异构计算统一调度” 与 “全链路格式兼容”,而其底层基石则是先进的模型压缩技术 —— NexaQuant。
以 NexaSDK for iOS & macOS 为例,它使 iOS 设备和 Mac 电脑能够本地运行最新 AI 模型,在实现 2 倍性能提升与 9 倍能耗节省的同时,仅需三行代码即可启动。它支持 Embedding、语音识别(ASR)、光学字符识别(OCR)等功能,并兼容 EmbeddingNeural、Gemma 3 等框架。从架构上看,应用通过 Swift API 或 C 接口连接 Nexa SDK Core,再由 NexaML Runtime 的组件调度 NPU、CPU、GPU 等硬件资源,实现高效低耗的本地推理。
2.1 NexaQuant:实现模型“瘦身”而不损性能
模型体积与推理性能的平衡是端侧部署的首道关卡。即便是参数仅 3B 的“小模型”,原始格式也可能占用数 GB 存储,运行时内存消耗更是巨大。NexaQuant 作为硬件感知型多模态模型压缩工具,通过创新的混合精度量化技术,达成了 “速度提升 3 倍、存储与能耗节省 4 倍,且精度完全恢复甚至部分超越” 的效果。
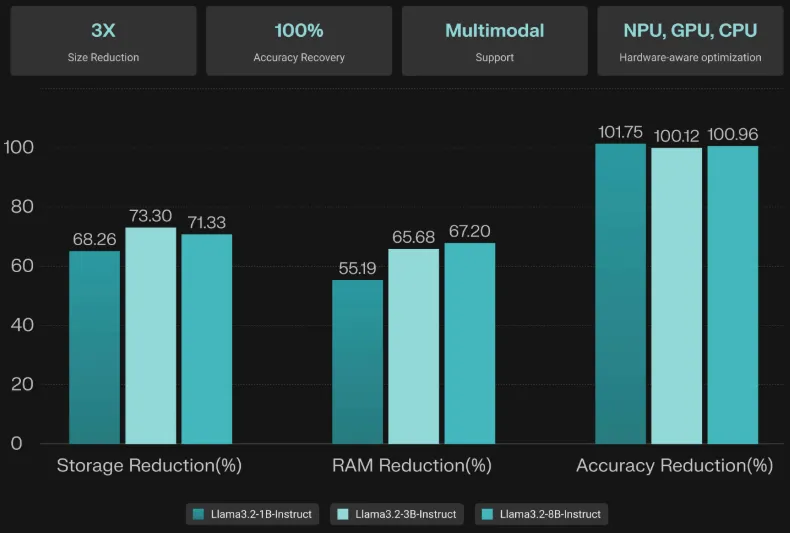
在 Llama 3.1/3.2 系列模型(1B、3B、8B)上应用时,压缩后的模型在各项基准测试中均达到了原始 BF16 模型 100% 以上的性能。例如,Llama3.2-3B-Instruct 经 Nexa Q4_0 量化后,IFEVAL 分数从 60.82 提升至 62.77,GSM8K 数学推理得分从 63.92 提升至 64.75。该技术不仅支持基于 Transformer 的文本模型,还能高效压缩视觉、音频乃至图像生成类多模态模型。
其核心优势包括:
- 精度无损压缩:对特定模型系列可实现精度无损甚至提升。
- 多模态兼容:支持视觉、音频等模型压缩。如 Qwen-VL-2B 压缩后,存储体积从 4.42GB 降至 2.27GB,运行时内存从 4.40GB 降至 2.94GB,同时在复杂文档 QA 任务中保持高准确率。
- 全硬件适配:压缩后的模型可无缝运行于 NPU、GPU、CPU,覆盖 PC、移动端、IoT 等全场景设备。

在图像生成模型上,NexaQuant 同样表现出色。例如,将 FLUX.1-dev 模型压缩后,文件大小降至原始的 27.9%(23.8GB → 6.64 GB),所需运行时内存降至 36%(34.66GB → 12.61 GB),同时推理速度可比标准 Q4_0 量化快 9.6 倍。
2.2 异构后端支持:打破设备壁垒,智能调度算力
Nexa SDK 的核心能力体现在其对全平台硬件的深度适配与智能调度上:
- 跨平台全覆盖:支持 iOS/Android 手机、Windows/macOS/Linux PC、IoT/XR 嵌入式设备及汽车座舱等全场景,无需为不同系统重写业务逻辑。例如,Parakeet v3 语音识别模型可通过同一套 Nexa SDK,分别在 Apple ANE 和高通 Hexagon NPU 上高效运行。
[视频:PC平台骁龙X Elite NPU演示]
- 硬件智能调度:运行时自动识别并优化利用设备算力资源(CPU/GPU/NPU)。在配备 NPU 的设备(如高通 SA8295、Apple M 系列芯片)上,优先调用 NPU 以实现低功耗高性能推理;在无专用 AI 芯片的设备上,则通过深度优化的 CPU/GPU 后端保证基础体验。
- 全格式兼容:原生支持 GGUF、MLX 等主流模型格式,可直接加载 Hugging Face 等社区的海量模型资源,无需繁琐的格式转换。
- 全模态支持:集成大型语言模型(LLM)、视觉语言模型(VLM)、纯视觉模型、音频模型及图像生成模型的全模态能力,提供一站式调用接口。
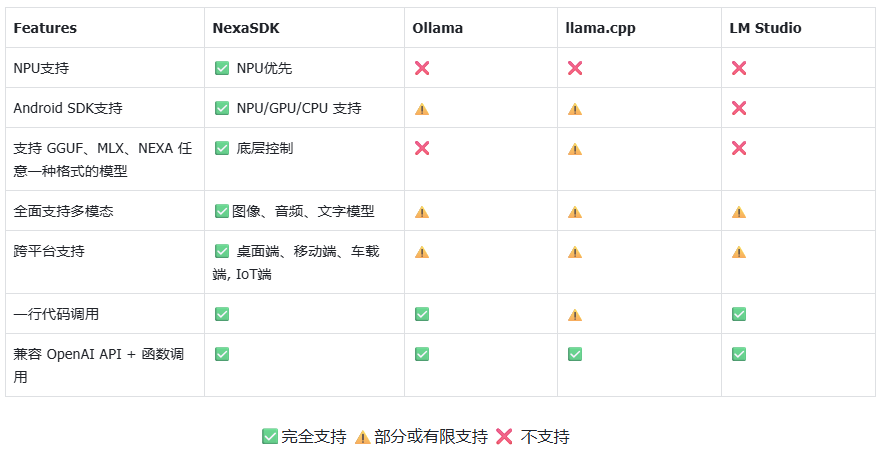
以下特性对比表清晰地展示了 Nexa SDK 在不同设备与框架间的支持情况:
三、应用场景:超越聊天机器人的多模态助手
技术的价值最终由落地体验定义。基于 Nexa SDK 构建的端侧 AI 生态,已延伸至多模态交互、本地知识库、实时环境感知等丰富场景。
3.1 移动端:隐私优先的“视觉搜索引擎” — EmbedNeural
EmbedNeural 是全球首个为 Apple 和高通 NPU 专项优化的多模态嵌入模型。它能让手机在完全离线的状态下,通过自然语言瞬间搜索本地相册中的目标图片。
[视频:EmbedNeural 相册搜索演示]
部署仅需两步:
- 根据模型卡片说明下载 SDK 并激活令牌:
https://sdk.nexa.ai/model/EmbedNeural
- 参考 GitHub 示例运行 Gradio 界面。
nexa pull NexaAI/EmbedNeural
nexa serve
pip install -r requirements.txt
python gradio_ui.py
核心亮点:
- 毫秒级响应:在 5000+ 图片库中搜索“穿西装的猫”,仅需 0.03 秒。
- 100% 隐私保护:所有图片特征提取与比对均在设备本地完成,数据永不离开手机。
- 超高能效:利用 NPU 加速,持续索引与搜索的功耗仅为传统 CPU/GPU 方案的 1/10。
3.2 PC 端:本地化的“超级知识大脑” — Hyperlink
对于处理敏感文档的从业者,Hyperlink 是一款基于 Nexa SDK 构建的本地 AI 助手,堪称 “私有化部署的 Perplexity”。它将个人电脑变为能理解、分析和溯源各类文件内容的智能伙伴。
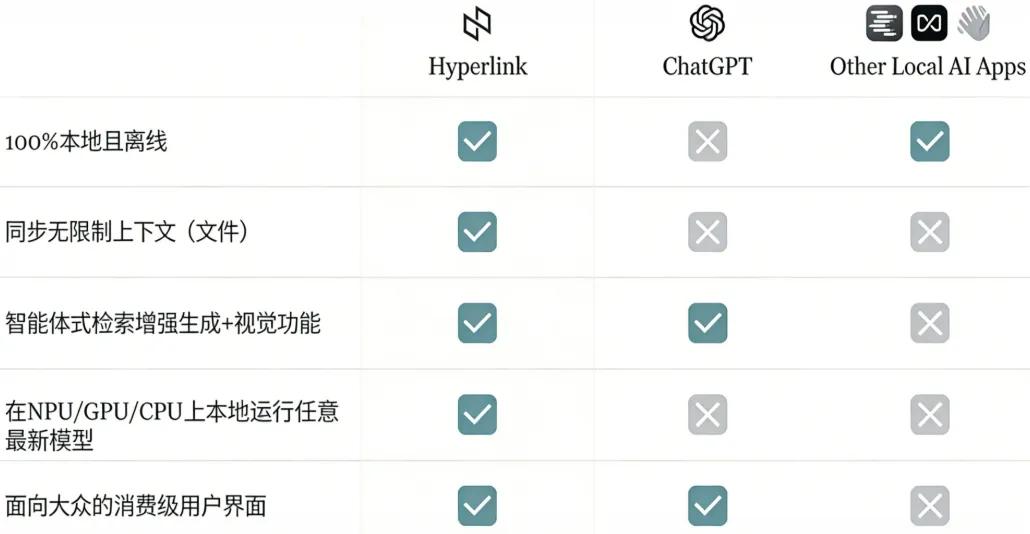
核心能力包括:
- 无限制本地知识库:支持索引 PDF、Word、图片等格式,文档数量无上限,远超云端产品的限制。
- 自然语言问答与溯源:回答复杂查询并提供原文引用,确保信息准确可验证。
- 智能关联推理:具备 Agentic RAG 能力,可跨文档关联信息、发现隐藏规律。
- 完全离线运行:所有数据处理均在本地完成,兼顾安全性与稳定性。
[视频:Hyperlink 本地 RAG 演示]
(Hyperlink 体验链接:https://hyperlink.nexa.ai)
3.3 全场景延伸:从智能汽车到工业 IoT
Nexa SDK 在垂直领域的应用潜力巨大:
- 车载场景:专为高通 SA8295 NPU 优化的 AutoNeural-VL-1.5B 模型,可实现座舱内监控、车外环境感知、多模态交互等功能,端到端延迟较传统方案降低 14 倍。
- IoT 场景:通过 NexaML 引擎,LFM2-1.2B 等轻量模型可在高通 IQ-9075 等 IoT 芯片上高效运行,用于工业异常检测、设备远程指导等,满足边缘计算的实时性要求。

此外,基于 Nexa SDK 的本地 RAG 系统,在 2021 款 MacBook Pro (M1 Pro) 上运行 Llama3.2-3B 模型处理复杂文档时,加载时间不足 2 秒,简单检索速度甚至优于某些云端大模型。通过 LoRA 等微调技术,还能为小模型增添图表生成等专项技能。
四、开发者视角:低门槛与高效率
对于开发者,Nexa SDK 的核心吸引力在于其显著降低了端侧 AI 的应用开发门槛。
4.1 零成本迁移:OpenAI API 兼容
这是其“杀手锏”特性。开发者只需将现有应用中指向 OpenAI 的 API 端点改为本地 Nexa Server 地址,即可几乎零成本地将云端 AI 功能迁移至端侧,无需改变任何业务代码。
4.2 极致易用:一行命令启动模型
Nexa SDK 将复杂的部署流程封装为简洁的命令行操作:
- 在高通 NPU 上运行 Qwen3-VL:
nexa infer NexaAI/qwen3-4B-npu
- 在 Apple Silicon 上运行模型:
nexa infer NexaAI/Qwen3-VL-4B-MLX-4bit
这种“开箱即用”的设计极大提升了开发效率。
[视频:NexaCLI 极速部署演示]
4.3 强大的合作生态
Nexa SDK 已建立起广泛的生态合作网络:
- 模型支持:深度适配通义千问(Qwen)、Llama 3、GPT-OSS 等主流模型系列。
- 硬件合作:与高通、Apple、AMD、Intel、NVIDIA 等芯片厂商深度合作,进行针对性优化。
- 社区支持:活跃的 GitHub 仓库(NexaAI/nexa-sdk)提供了完整的文档、示例和社区交流渠道。
结语:端侧 AI 的未来已来
当云端竞赛趋于白热化,Nexa SDK 选择了一条更贴近用户的路径:不盲目追求参数规模,而是专注于让 AI 真正融入设备、场景,并切实保障隐私与体验。随着压缩技术的进步与硬件算力的普及,未来 AI 将如今天的手机应用一样,成为设备原生、随时可用的能力。
作为这场变革的核心推动者之一,Nexa SDK 为开发者提供了强大的工具。感兴趣的朋友可以前往其 GitHub 主页了解详情,甚至用一行命令开启你的第一个本地大模型体验。该项目目前还设有有奖征集活动,鼓励开发者基于其 SDK 创作应用。

 发表于 2025-12-20 09:09:09
|
查看: 393|
回复: 0
发表于 2025-12-20 09:09:09
|
查看: 393|
回复: 0
