使用自定义数据集完成YOLOv5模型训练后,所有输出文件均会保存在 runs/train/exp 目录下(多次训练会顺序生成 exp2, exp3 等)。深入理解这些文件的构成与含义,对于评估模型性能、进行后续优化及模型部署至关重要。
weights/ 模型权重文件目录
weights 子目录是训练输出的核心,保存了最终生成的模型权重文件,主要包含 best.pt 和 last.pt。
best.pt:训练过程中在验证集上表现最佳的模型权重。训练时,每个 epoch 结束后都会在验证集上计算 mAP@0.5 指标,若当前 epoch 的指标超过历史最佳值,则会更新此文件。因此,best.pt 代表了训练过程中的最优性能,是后续模型导出(如转换为 ONNX、TensorRT 格式)并进行生产环境部署的首选。last.pt:最后一个 epoch 训练完成后的模型权重。无论验证集性能如何,每个 epoch 结束后都会更新此文件。它的主要作用在于:当训练意外中断时,可以加载 last.pt 从中断处继续训练;同时,也可用于分析模型最终的训练状态和收敛情况。
训练结果指标:results.png 与 results.csv
这两个文件记录了训练过程中每个 epoch 的关键指标。
results.png(指标可视化图表)
下图是一个典型的 results.png 文件示例:
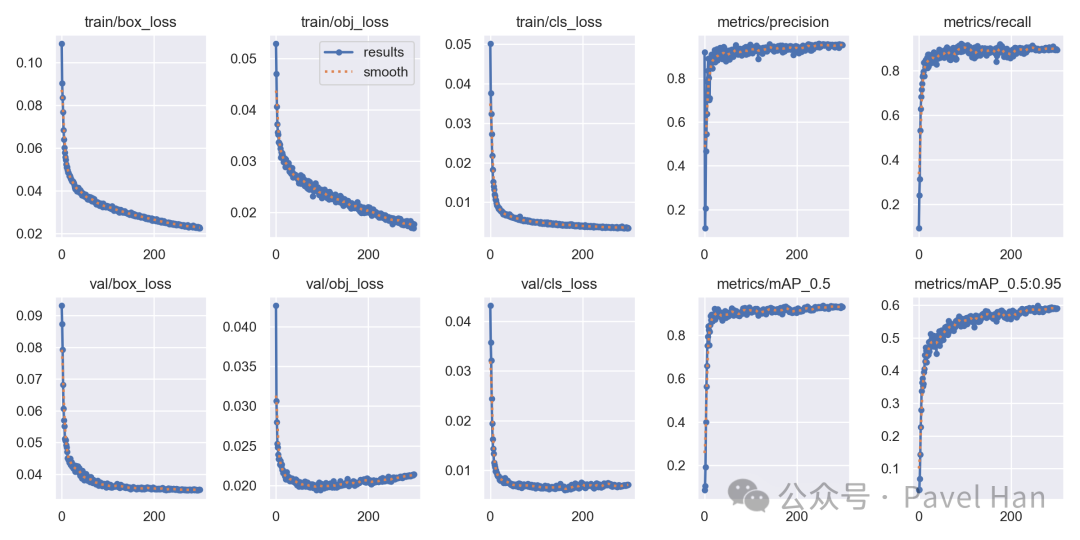
图表主要包含两部分信息:
-
损失曲线 (Loss Curves):
box_loss, obj_loss, cls_loss:分别对应边界框坐标损失、目标置信度损失和分类损失。每条曲线都有训练集(train)和验证集(val)两条线。- 理想情况:所有损失曲线平稳下降并最终维持在较低水平,且训练损失略低于验证损失。
- 过拟合迹象:训练损失持续下降,但验证损失在某个点后开始上升。解决方案包括增加数据量、降低模型复杂度或使用早停(Early Stopping)。
- 欠拟合迹象:训练和验证损失都维持在较高水平且较早进入平台期不再下降。可能需要更复杂的模型、更长的训练轮数或调整超参数。
-
精度指标 (Metrics):
- 精确率 (Precision):模型预测为正的样本中,真正为正的比例。越高越好。
- 召回率 (Recall):所有真实为正的样本中,被模型正确预测出来的比例。越高越好。
- mAP@0.5:IoU(交并比)阈值为 0.5 时的平均精度均值。这是最常用的评估指标,侧重于模型的分类和基础定位能力。
- mAP@0.5:0.95:IoU 阈值从 0.5 到 0.95(步长0.05)计算的平均精度均值。这是一个更严格的指标,要求模型同时具备精确的分类和高精度的定位能力。计算时,会在10个不同 IoU 阈值下分别计算 mAP,然后取平均值。
results.csv(指标详细数据)
results.csv 以表格形式存储了每个 epoch 的详细指标数据,与 results.png 图表内容对应。

此外,文件中还包含 x/lr0, x/lr1, x/lr2 三列,分别记录了 YOLOv5 模型主干网络(Backbone)、颈部网络(Neck)、检测头(Head)三个部分在训练过程中的学习率(Learning Rate)变化。YOLOv5 使用分组学习率策略,并结合学习率调度器(如余弦退火)动态调整各部分的学`习率,以优化模型收敛效果。
混淆矩阵 (confusion_matrix.png)
该文件直观展示了模型在验证集上对各个类别的分类混淆情况。
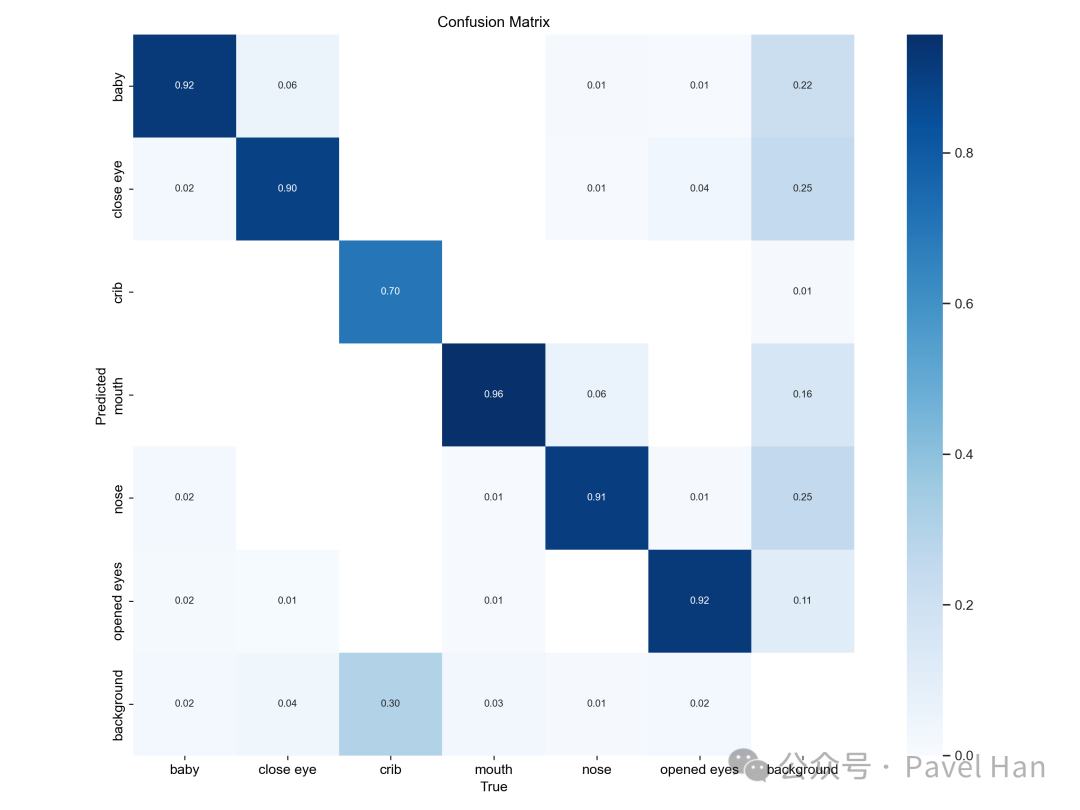
- 对角线(深色方格):表示模型正确预测的比例,数值越高(颜色越深)说明该类别的识别准确率越高。
- 非对角线(浅色方格):表示类别间的误判比例。例如,真实类别为 A 的样本被错误预测为类别 B 的比例。数值越低(颜色越浅)越好。
- 分析价值:通过观察混淆矩阵,可以快速定位模型容易混淆的类别对(如上图中
crib 易与 background 混淆)。针对这些薄弱环节,可以补充更多区分性强的训练数据,或针对性应用数据增强,以提升模型的区分能力。
F1/精确率/召回率/PR 曲线
训练会生成四张评估曲线图:P_curve.png(精确率-置信度阈值曲线)、R_curve.png(召回率-置信度阈值曲线)、PR_curve.png(精确率-召回率曲线)和 F1_curve.png(F1分数-置信度阈值曲线)。这些曲线用于综合评估模型在不同置信度阈值下的性能平衡,是进行模型调优和算法分析的重要参考。
训练与验证批次图像
训练过程还会生成 9 张图像,用于可视化数据及模型预测效果:

-
train_batchX.jpg (共3张):展示了训练时一个批次输入模型的图像。可以观察到 YOLOv5 在训练中应用的数据增强效果,特别是 Mosaic 数据增强——它将四张图片随机缩放、裁剪、拼接成一张新图,再缩放到 640x640 输入网络,极大地增加了数据的多样性和模型鲁棒性。图中显示了增强后图像及其真实标注框(Ground Truth)。
-
val_batchX_labels.jpg (共3张):展示了验证集中一个批次图像的真实标签(Ground Truth),即“标准答案”。
-
val_batchX_pred.jpg (共3张):展示了模型对同一批验证集图像的预测结果。通过对比 val_batchX_labels.jpg 和 val_batchX_pred.jpg,可以直观地分析模型存在的误检、漏检、定位偏差等具体错误模式,为后续模型调试和优化提供直接依据。
|  发表于 2025-12-23 19:00:14
|
查看: 206|
回复: 0
发表于 2025-12-23 19:00:14
|
查看: 206|
回复: 0
