在大语言模型(LLM)推理的实际部署中,显存(VRAM)容量已超越算力(TFLOPS),成为首要的性能与规模瓶颈。面对数百亿参数和百万级上下文长度的常态化需求,显存优化不再是零散的技巧,而是一项涉及算法、系统和硬件的系统性工程。本文旨在提供一个从底层量化原理到顶层集群调度的完整知识框架。
一、量化建模:建立显存占用的精确认知
所有有效的优化都始于精准的测量。首先需要明确区分模型运行中静态加载的权重空间与动态变化的缓存和激活值。
-
KV Cache显存的精确计算公式
针对采用分组查询注意力(GQA)的现代架构(如 Llama 3),资源预估必须引入相应的系数,这是导致显存预算偏差的主要原因之一。
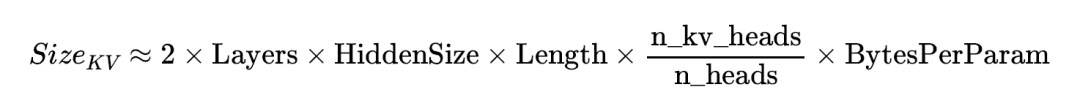
- 线性增长特性:在仅解码器(Decoder-only)架构中,KV Cache 的占用空间随序列长度严格呈 O(n) 线性增长。
- 显存拐点效应:随着上下文长度增加,KV Cache 的占比会迅速超越静态模型权重。通常在 32K-64K 长度附近,KV Cache 将成为显存占用的主要部分,是管理的核心矛盾。
-
预填充与解码阶段的动力学差异
- 预填充阶段(Prefill):注意力计算会产生大量的瞬时激活值,其占用随序列长度呈 O(N^2) 增长,形成显存峰值(Memory Spikes),这是触发显存溢出(OOM)的最常见原因。
- 解码阶段(Decoding):显存占用随着 Token 的生成而线性堆叠。此时的主要瓶颈在于显存带宽,而非容量。因此,采用混合精度策略(如 INT4 权重加载配合 FP16 计算)可以有效缓解带宽压力。
二、存算压缩:以比特宽度换取存储空间
通过降低权重和中间结果的数值精度,可以直接削减其物理存储占用。
-
权重量化方案对比
- 激活感知权重量化(AWQ):当前工业界的共识方案。其通过分析激活值的分布来保护对输出影响更大的关键权重,且其算子实现对现代硬件更友好,准确率通常优于 GPTQ。
- 原生FP4支持:NVIDIA Blackwell 架构引入了对 FP4 数据类型的原生支持,在相同的比特位数下,提供了比 INT4 更优的动态范围。
-
KV Cache的极端压缩
- FP8量化:当前性价比最高的方案,几乎无损精度,并能获得硬件的原生加速支持。
- 2比特压缩(如KIVI/CommVQ):针对百万级长文本场景,仅保留极少数关键的注意力头部信息,而将其余部分压缩至 2-bit,可将 KV Cache 显存占用降低 4-5 倍。
三、系统调度:虚拟化与分层存储
当算法层面的压缩达到极限时,必须借助系统级的工程手段。
-
显存虚拟化:PagedAttention 2.0
- 原理:借鉴操作系统的分页内存管理机制,将连续的 KV Cache 存储在物理上非连续的显存块中,可将显存利用率提升至 95% 以上,从根本上消除内存碎片。
- 前缀缓存(Prefix Caching):在多轮对话中,自动识别并跨请求共享公共系统提示词(System Prompt)的 KV Cache 块,避免重复存储。
-
存算解耦:卸载与交换机制
- 激活值卸载(Activation Offloading):在预填充阶段的峰值时刻,将暂不参与计算的中间激活张量临时卸载至主机内存(RAM)。
- 显存-内存交换(Swapping):通过 PCIe 总线在 GPU 显存和主机内存之间交换冷数据块。主流推理框架通过异步预取(Async Prefetch)技术,有效掩盖了大部分交换延迟。
四、架构演进:从算法底层改变增长曲线
通过优化注意力机制的计算范式,从根本上降低其对显存的需求。
-
访存优化:FlashAttention 3.0 与 TMA
利用 Hopper 架构的张量内存加速器(TMA)单元,结合 SRAM 分块计算技术,彻底避免了在显存中生成和存储庞大的注意力得分矩阵,在长序列场景下可提升高达 1.5 倍的访存效率。
-
空间稀疏化:滑动窗口与动态驱逐
- 注意力锚点(Attention Sink):保留初始 Token 的状态,并结合滑动窗口进行推理,可实现常数级别的 KV Cache 占用。
- KV Cache 驱逐(Eviction):基于实时计算的注意力权重,动态丢弃被判定为不重要的历史 Token。实施时需警惕旋转位置编码缩放(RoPE Scaling)带来的注意力稀释效应,这可能干扰驱逐算法的判断。
五、集群协同:分布式显存治理
当单张 GPU 的显存上限无法满足需求时,需要通过分布式技术进行扩展。
-
空间扩展:上下文并行(Context Parallelism, CP)
当单卡无法承载长文本的全部 KV Cache 时,将序列维度切分到多张 GPU 上,实现显存池的横向扩展。
-
冗余消除:权重绑定与副本共享
- 架构级权重绑定(Weight Tying):在模型定义时,让输入嵌入层和输出层的权重参数共享,直接减少模型权重总量。
- 部署级副本共享:在分布式推理集群中,让多个计算副本共享同一份只读的模型权重,确保宝贵的显存空间尽可能用于存储动态生成的 KV Cache。
总结:显存优化技术路径与选型建议
以下为不同优化目标的策略组合建议,供架构师根据实际模型规模、上下文长度及业务需求进行选择和组合。
| 优化层级 |
推荐技术组合 |
核心收益 |
实施复杂度 |
| 基础层 |
PagedAttention + AWQ 权重量化 |
解决显存碎片,降低基础存储占用 |
中 |
| 加速层 |
FlashAttention 3.0 + FP8 KV Cache |
显著提升推理吞吐量与计算效率 |
高 |
| 长文本层 |
2-bit KV Cache 量化 + Prefix Caching |
支持 100K - 1M+ 超长上下文 |
高 |
| 系统层 |
激活值卸载 + 上下文并行(CP) |
突破单卡物理显存容量上限 |
极高 |
结语:时至今日,高效的显存管理能力已成为 LLM 推理服务实现业务闭环与成本控制的核心竞争力。建议技术决策者根据模型规模、上下文长度的实时配比,动态组合与实施上述策略,构建弹性的推理基础设施。在具体实现时,深入掌握如 PyTorch 等深度学习框架的显存管理机制是进行底层优化的基础。 |  发表于 2025-12-24 08:14:30
|
查看: 380|
回复: 0
发表于 2025-12-24 08:14:30
|
查看: 380|
回复: 0
