随着AI大模型对算力需求的爆炸式增长,高性能计算(HPC)的瓶颈已从GPU转移到内存带宽。HBM(高带宽内存)作为AI加速器的核心组件,其技术演进速度直接决定了下一代AI芯片的性能上限。你是否好奇,在物理尺寸的严格限制下,存储巨头们如何将DRAM堆叠层数从8层推向16层甚至更高?SK hynix的MR-MUF和三星/美光的TC-NCF,这两种主流封装技术究竟有何本质差异?更进一步,当HBM不再只是一个被动存储器件,而是集成计算逻辑的“定制化HBM”(cHBM)时,它将如何重塑“存算一体化”的架构,并彻底改变供应链格局?
一、 前端工艺:提升带宽与单Die密度的基石
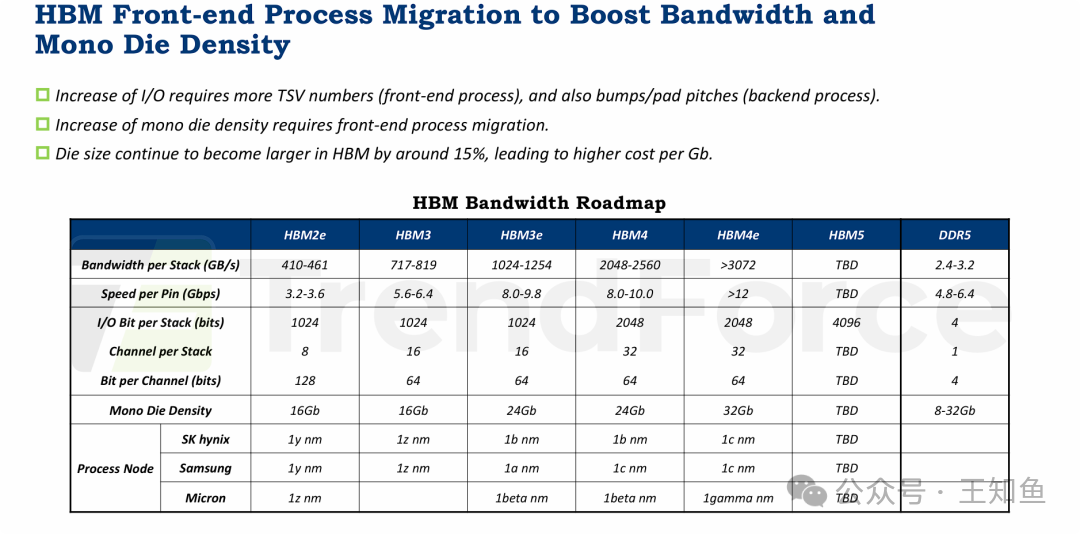
HBM(高带宽内存)前端工艺迁移以提升带宽和单Die(裸晶)密度。表格呈现HBM逐代工艺演进路线及技术参数。
前端工艺的进步是HBM性能飞跃的基础,主要体现在带宽提升和单Die密度增加两方面。
- 增加I/O与TSV数量:为了提升数据传输带宽,必须增加输入/输出通道(I/O)的数量。这直接依赖于增加硅通孔(TSV)的数量,这属于前端工艺。同时,后端工艺需要缩小焊球和焊盘的间距与之配合。
- 迁移制程节点以提升密度:要提升单个存储裸晶的容量(例如从16Gb到24Gb),必须采用更先进的半导体制造节点(如从1z nm迁移到1b nm),这同样是前端工艺的范畴。
- 应对尺寸与成本挑战:值得注意的是,随着HBM迭代,其裸晶物理尺寸在增大,这导致每Gb成本的上升。因此,通过工艺进步来提升密度和性能变得至关重要。
二、 后端工艺:突破堆叠层数的物理极限
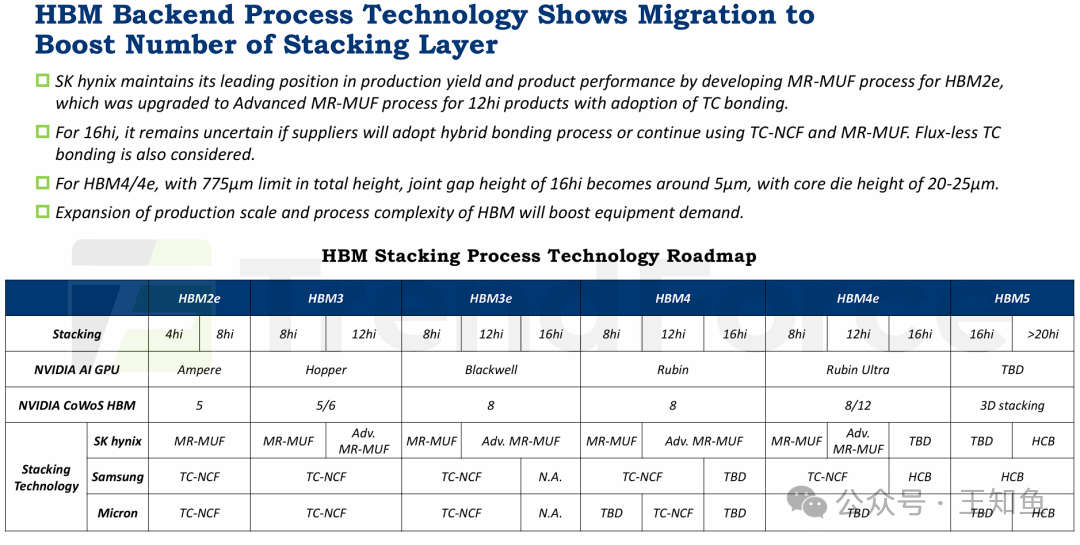
HBM后端工艺技术迁移以增加堆叠层数。
后端封装技术是HBM实现容量跃升的关键战场,其核心是在严苛的物理限制下增加垂直堆叠层数。
- SK hynix的领先优势:SK hynix凭借其MR-MUF(批量回流模塑底部填充)工艺,在生产良率和产品性能上保持领先。该公司在HBM2e上应用了MR-MUF,并在12层堆叠产品上升级至Advanced MR-MUF。
- 未来路径的抉择:面向16层及以上堆叠,行业面临技术抉择。是继续优化现有的TC-NCF(热压非导电膜)和MR-MUF,还是转向混合键合(Hybrid Bonding)或无助焊剂热压键合,目前尚无定论。
- 直面物理极限:在总高度不超过775微米的封装限制下,要实现16层堆叠,要求裸晶间连接间隙压缩至约5微米,核心裸晶本身也要削薄至20-25微米。这揭示了工艺面临的巨大挑战。
- 驱动设备需求:随着HBM市场规模扩大和制造工艺复杂化,对相关半导体生产设备的需求将显著增长。
核心观点:为了满足AI对内存容量和带宽的爆炸性需求,HBM后端技术正通过革新堆叠与键合工艺,在物理极限的边缘寻求突破,而顶级AI芯片的需求是牵引其发展的核心动力。
三、 工艺流程详解:从TSV到堆叠封装
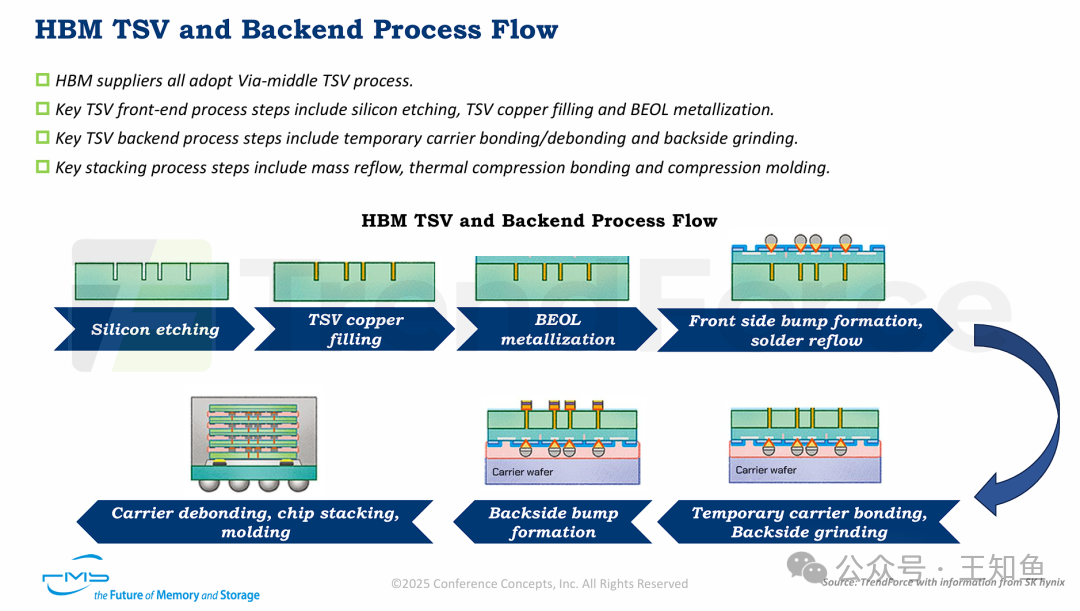
HBM硅通孔(TSV)与后端工艺流程。
HBM制造是一个复杂的系统工程,结合了前端的TSV工艺和后端的堆叠封装技术。
前端TSV工艺:
- 通用方案:行业普遍采用Via-middle TSV工艺,即在晶圆制造中期形成TSV。
- 核心步骤:包括硅刻蚀形成深孔、铜填充形成垂直导电通道,以及后端金属化(BEOL)将TSV连接到芯片互连层。
后端堆叠工艺:
- 准备阶段:包括临时载体键合/解键合以支撑晶圆,以及背面研磨以减薄晶圆。
- 堆叠键合:关键步骤包括回流焊(熔化锡球形成连接)、热压键合(施加热压形成牢固连接)和压缩模塑(封装保护芯片)。
四、 核心对决:MR-MUF vs. TC-NCF
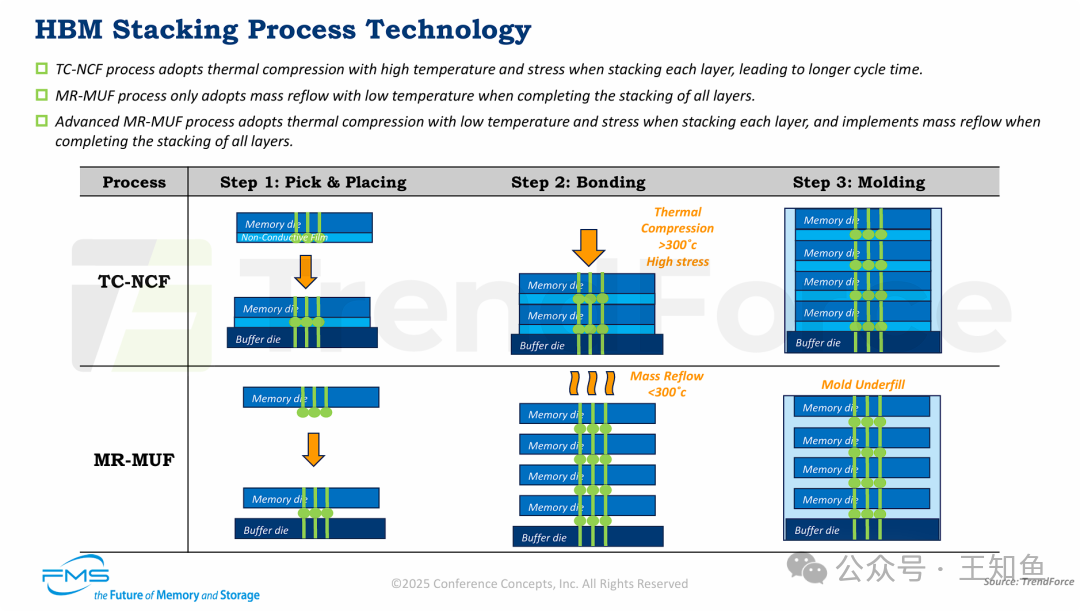
HBM制造中两种主流的后端堆叠技术:TC-NCF (热压非导电膜) 和 MR-MUF (批量回流模塑底部填充)。
MR-MUF工艺通过“先堆叠后键合”的批量处理方式,相比TC-NCF的“逐层键合”方式,在生产效率、工艺温度和对芯片的物理压力方面具有显著优势。
- 流程本质差异:TC-NCF是串行工艺(三星/美光采用),每层都需独立进行高温高压键合;MR-MUF是并行工艺(SK海力士采用),可一次性完成所有层级的低温键合。
- 效率与成本:MR-MUF避免了逐层热压,生产周期更短,效率更高,这对HBM的产能和制造成本至关重要。
- 工艺条件:MR-MUF键合温度(<300°C)低于TC-NCF(>300°C),且无需对芯片施加高压力。更温和的条件有助于提高良率,减少热应力和机械应力导致的芯片损伤。
- 技术演进:“Advanced MR-MUF”的出现,表明行业正探索结合两者优点的混合方案,以平衡堆叠精度、效率和可靠性。
五、 架构革新:定制化HBM(cHBM)与近存计算

定制化HBM(cHBM)能够实现更优的系统级性能和总拥有成本(TCO)。
cHBM通过将部分计算逻辑下沉到可定制的HBM基底裸晶中,并用高效的D2D接口取代传统的并行HBM PHY接口,实现了“存算一体化”的初步形态,从而在系统层面带来显著的性能提升、成本降低和功耗节省。
- 架构变革:cHBM的本质是从纯粹“内存器件”向集成计算逻辑的“内存子系统”转变。其核心是一个采用先进工艺制造的、可定制的基底裸晶。
- 实践近存计算:将对内存访问要求高的逻辑单元直接内置于内存附近,极大缩短数据路径,减少延迟,提升特定计算任务的效率。可以理解为内存语义在HBM裸晶内部实现,减少了CPU/GPU的内核调度消耗。
- 接口革新降本增效:废除HBM和GPU两侧高功耗、占面积的HBM PHY,代之以轻量化D2D接口。此举直接带来双重的面积节省(释放主处理器芯片面积)和显著的功耗降低,是优化总拥有成本的关键。
- 行业趋势:cHBM代表了通过先进封装和系统级协同设计持续提升计算性能的重要方向,是未来高性能计算架构演进的缩影。
六、 供应链重塑:台积电成为关键玩家
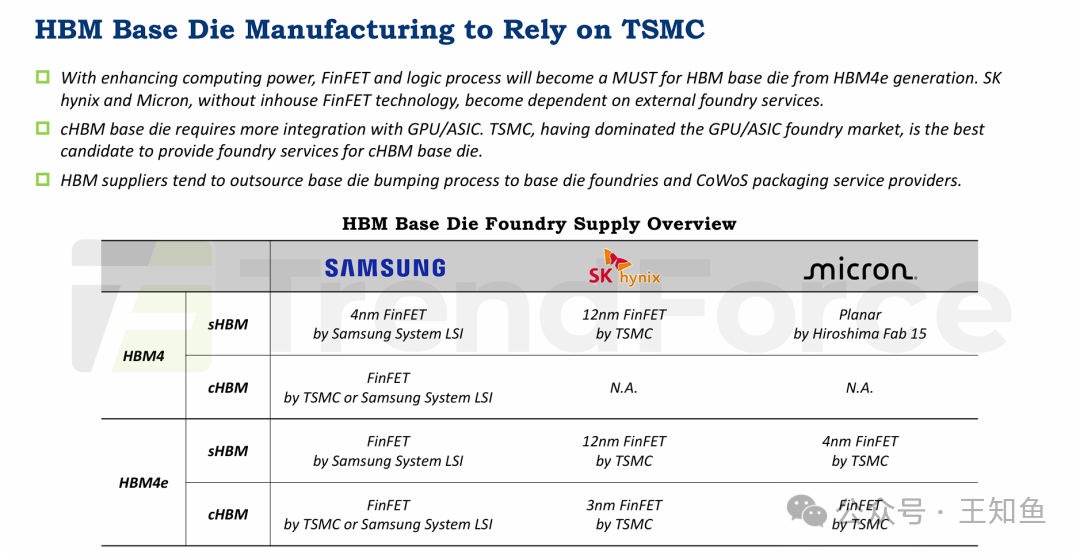
HBM基底裸晶的制造将依赖台积电(TSMC)。
由于HBM基底裸晶的技术复杂性急剧提升,其制造正从存储厂商内部转向专业的逻辑晶圆代工厂,台积电凭借其技术领先和生态系统优势,正在成为这个关键环节的主导者。
- 技术驱动的外包:HBM演进(尤其是cHBM)要求基底裸晶集成复杂逻辑电路,必须依赖FinFET等先进逻辑工艺,这超出了传统存储厂商的能力范围。
- 供应链结构变化:存储厂商(如SK海力士、美光)专注于DRAM裸晶堆叠,而技术含量最高的基底裸晶则外包给逻辑代工厂。三星因其综合业务,保持了较高的垂直整合度。
- 台积电的核心地位:台积电不仅是绝大多数AI处理器(GPU/ASIC)的制造商,也正成为HBM关键组件(基底裸晶)的主要制造商。这种“双重角色”使其能提供从计算芯片到内存接口的“一站式”解决方案,强化了客户粘性。
- 技术代差决定策略:为了追赶最新的HBM4/4e标准,特别是实现cHBM,SK海力士和美光都必须依赖台积电最先进的工艺节点(如3nm/4nm),这凸显了先进制造工艺的决定性作用。
延伸思考
- 在HBM4/4e时代,如果混合键合成为主流,它将如何彻底解决当前TC-NCF和MR-MUF在良率、散热和超高堆叠层数上的固有矛盾?
- cHBM通过将计算逻辑下沉到基底裸晶,实现了初步的近存计算。你认为未来哪些类型的AI工作负载最适合这种架构?
- 随着HBM基底裸晶制造依赖台积电的先进逻辑工艺,这种专业化分工对整个AI芯片的供应链结构和上市时间会产生哪些深远影响?
原文参考:Advancements in HBM Process Technology Boosting Bandwidth and Stacking Layers for the Future |  发表于 2025-12-25 07:59:01
|
查看: 522|
回复: 0
发表于 2025-12-25 07:59:01
|
查看: 522|
回复: 0
