集成学习思想简介
集成学习(Ensemble Learning)是机器学习中一种重要的学习范式。其核心思想是“集思广益”,即通过构建并结合多个性能尚可的个体学习器(或称“基学习器”/“弱学习器”)来创建一个泛化能力更强的强学习器。它相信多个模型的集体智慧往往优于单个模型,从而获得更准确、更稳定的预测结果。
根据基学习器之间的结合方式与训练策略,集成学习的核心思想主要分为两大流派:Bagging与Boosting。
Bagging:并行构建与平权投票
Bagging(Bootstrap Aggregating)的核心在于并行训练多个独立且相似的弱学习器,并通过平权投票或取均值的方式集成结果。这种方法能有效降低模型整体的方差,特别适用于基模型本身方差较大的情况(如深度较大的决策树)。
下图清晰地展示了自助法(Bootstrap Sampling)结合并行训练与投票的流程:
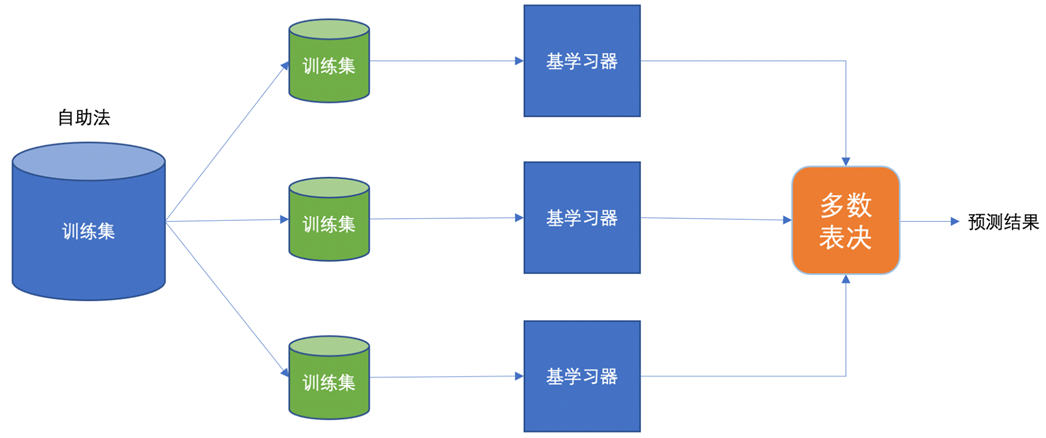
简单来说,Bagging的工作流程是:
- 从原始训练集中使用自助采样法(有放回抽样)生成多个不同的子训练集。
- 每个子训练集独立、并行地训练一个基学习器。
- 对于分类任务,最终的预测结果由所有基学习器投票决定(少数服从多数);对于回归任务,则对所有基学习器的输出取平均。
核心算法:随机森林 (Random Forest)
随机森林是Bagging思想最著名且成功的代表,它通过在Bagging基础上进一步引入特征随机性来增强模型的多样性。
其算法流程如下图所示,直观展示了从数据采样、特征选择到构建决策树森林的完整过程:
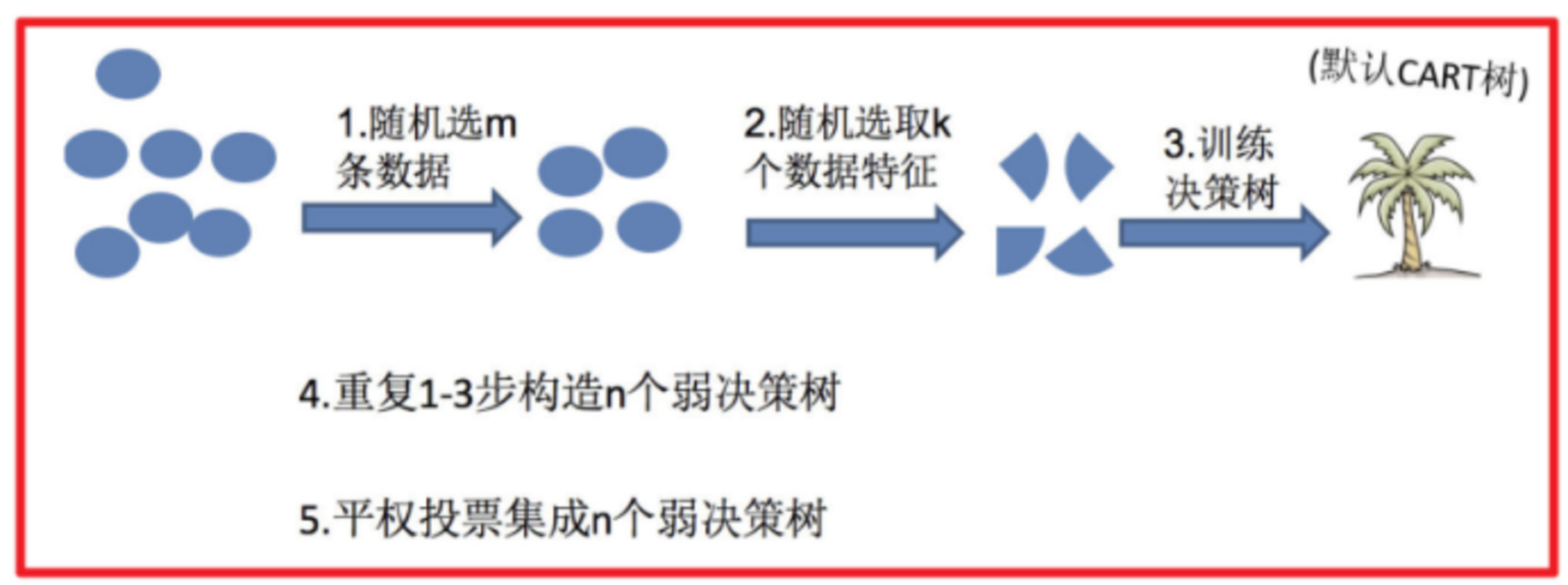
为什么随机森林要同时进行样本和特征的双重随机抽样?
- 样本随机(有放回):确保每棵决策树的训练数据有差异,从而训练出多样化的树。如果所有树训练数据相同,结果会高度一致,失去集成的意义。
- 特征随机:在每棵树进行节点分裂时,只从全部特征的一个随机子集中选择最优分裂特征。这进一步降低了树与树之间的相关性,增强了模型的泛化能力。
在Python的scikit-learn库中,随机森林提供了丰富的参数以供调优,是进行模型优化、应对过拟合的关键。对于希望深入掌握机器学习模型调优的开发者,可以参考我们的人工智能技术专题,了解更多高级技巧。
| RandomForestClassifier 核心参数速查表: |
参数 |
类型 |
默认值 |
描述 |
n_estimators |
int |
100 |
森林中树的数量。树越多通常性能越稳定,但计算开销越大。 |
criterion |
str |
'gini' |
分裂质量的衡量标准,可选 ‘gini’(基尼系数)或 ‘entropy’(信息增益)。 |
max_depth |
int 或 None |
None |
树的最大深度。限制深度是防止过拟合的有效手段。 |
max_features |
int, float, str, None |
'auto' |
寻找最佳分裂时考虑的最大特征数。常用 ‘sqrt’ 或 ‘log2’。 |
bootstrap |
bool |
True |
是否使用自助采样法构建每棵树的训练集。 |
oob_score |
bool |
False |
是否使用袋外样本来评估模型泛化精度。 |
min_samples_split |
int 或 float |
2 |
分裂内部节点所需的最小样本数。 |
min_samples_leaf |
int 或 float |
1 |
叶节点必须具有的最小样本数。 |
Boosting:串行学习与加权投票
与Bagging的并行独立训练不同,Boosting采用串行的方式训练一系列弱学习器。每一个新加入的学习器都会更加关注前序学习器预测错误的样本,通过不断修正错误来提升整体性能,最终通过加权投票的方式输出结果。
Boosting方法更适用于降低模型的偏差。下图描绘了其串行、关注前序不足并最终加权集成的核心思想:
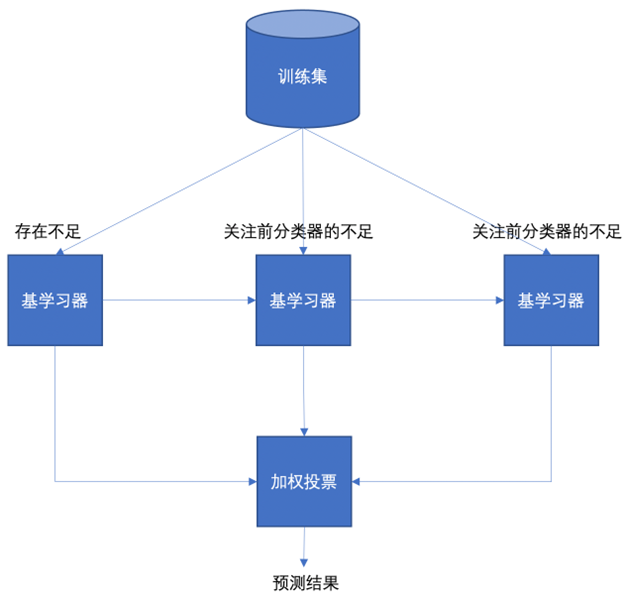
Boosting的几个关键知识点:
- 其基学习器通常是非常简单的模型,如深度为1或2的决策树(称为“决策树桩”)。
- 学习器之间的“经验”传递通过动态调整样本权重实现,错误样本的权重会被提高。
- 最终预测时,每个基学习器的投票权重(α_t)不同,性能越好的学习器权重越高。
Boosting家族的代表算法包括AdaBoost、GBDT以及XGBoost。
AdaBoost:自适应提升算法
AdaBoost的核心思想非常直观:在每一轮训练中,提高那些被前一个学习器分类错误的样本的权重,使得后续的学习器能更专注于这些“难例”。
其算法步骤可以概括为:
- 初始化所有样本的权重为相等值。
- 用当前样本权重训练一个弱学习器(如决策树桩)。
- 计算该学习器的错误率,并据此计算该学习器的投票权重(错误率越低,权重越高)。
- 更新样本权重:增加分类错误样本的权重,减少分类正确样本的权重。
- 重复步骤2-4,直到达到预设的弱学习器数量。
- 将所有弱学习器的结果按各自的权重加权求和,并通过符号函数得到最终预测。
以下是博主总结的AdaBoost算法详细推导与步骤笔记,供大家学习参考:


附:AdaBoost算法的误差上界定理证明,该定理保证了随着迭代增加,训练误差会指数下降。

| AdaBoostClassifier 核心参数: |
参数 |
类型 |
默认值 |
描述 |
base_estimator |
estimator |
DecisionTreeClassifier(max_depth=1) |
基学习器,默认为决策树桩。 |
n_estimators |
int |
50 |
弱学习器的最大数量。 |
learning_rate |
float |
1.0 |
学习率,用于缩减每个弱学习器的贡献权重,起到正则化作用。 |
GBDT:梯度提升决策树
梯度提升决策树(Gradient Boosting Decision Tree)采用了一种更通用的框架。它不再仅仅关注错误样本,而是拟合上一个模型的残差(真实值与预测值之差)。更准确地说,GBDT使用损失函数的负梯度作为残差的近似,在当前轮次构建一个学习器来拟合这个负梯度,从而沿着损失函数下降最快的方向优化模型。
下图以公式形式展示了GBDT如何通过拟合负梯度来迭代优化:

GBDT步骤简述:
- 初始化一个常数值作为初始预测(如目标值的均值)。
- 对于每一轮迭代
m=1 to M:
- 计算当前模型对所有训练样本的负梯度(即伪残差)。
- 用上一步计算的负梯度作为新的目标值,训练一棵新的决策树。
- 通过线性搜索确定这棵树的输出权重(或叶子节点值),使得加入该树后整体损失最小。
- 将所有树的预测结果累加,得到最终模型。
下图直观地展示了GBDT通过迭代拟合残差来逐步逼近真实值的过程:

| GradientBoostingClassifier 核心参数: |
参数 |
类型 |
默认值 |
描述 |
loss |
str |
‘deviance’ |
损失函数,‘deviance’为对数损失,‘exponential’为指数损失(同AdaBoost)。 |
learning_rate |
float |
0.1 |
学习率,控制每棵树的贡献。 |
n_estimators |
int |
100 |
提升阶段(树)的数量。 |
max_depth |
int |
3 |
每棵独立树的最大深度。 |
subsample |
float |
1.0 |
用于拟合每棵树的样本比例,小于1.0可引入随机性。 |
XGBoost:极端梯度提升
XGBoost(eXtreme Gradient Boosting)是GBDT算法工程实现上的巅峰之作,它在GBDT的损失函数基础上,显式地加入了正则化项来控制模型的复杂度,从而更有效地防止过拟合。
其目标函数由两部分构成:损失函数(衡量预测值与真实值的差异)和正则化项(控制模型复杂度)。正则化项公式如下,它惩罚了叶子节点数量(T)和叶子节点权重(w)的平方和:
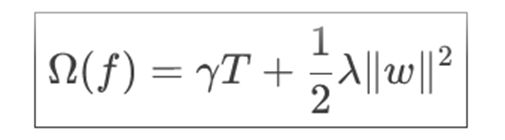
完整的可微目标函数为:
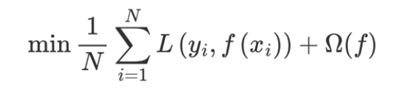
XGBoost通过二阶泰勒展开近似目标函数,并推导出用于评估树结构好坏的分裂收益(Gain)公式。增益(Gain) 的计算方式是分裂前的分数减去分裂后左右子树的分数之和。只有当Gain大于0时,分裂才被认为是有益的。
下图展示了XGBoost目标函数的推导化简过程:



XGBoost核心特性:
- 正则化:显式的L1/L2正则化。
- 处理缺失值:自动学习缺失值的最佳分裂方向。
- 并行与缓存优化:在特征粒度上进行并行计算,对数据访问进行优化。
- 剪枝策略:采用先生长到指定深度,再基于增益进行后剪枝的策略。
如果你想在实际项目中高效应用XGBoost这类复杂模型,扎实的Python编程和数据科学库功底是基础。
| XGBClassifier 部分核心参数: |
参数 |
类型 |
默认值 |
描述 |
n_estimators |
int |
100 |
弱学习器的数量。 |
max_depth |
int |
6 |
树的最大深度。 |
learning_rate |
float |
0.3 |
学习率,又称为收缩步长。 |
objective |
str |
‘binary:logistic’ |
学习任务目标,如二分类、多分类、回归。 |
subsample |
float |
1.0 |
训练每棵树时使用的样本比例。 |
colsample_bytree |
float |
1.0 |
训练每棵树时使用的特征比例。 |
reg_alpha |
float |
0 |
L1正则化权重。 |
reg_lambda |
float |
1 |
L2正则化权重。 |
gamma |
float |
0 |
进行分裂所需的最小损失下降值,越大模型越保守。 |
Bagging vs Boosting 思想对比
下表从多个维度系统对比了Bagging与Boosting这两种集成思想的核心差异:

代码应用实例
以下是使用Python和scikit-learn/XGBoost库,对不同集成算法进行建模的简要示例。
随机森林示例(基于泰坦尼克数据集)
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.metrics import accuracy_score
# 数据加载与预处理
df = pd.read_csv('train.csv')
x = df[["Pclass","Age","Sex"]].copy()
y = df["Survived"]
x["Age"].fillna(x['Age'].mean(), inplace=True)
x = pd.get_dummies(x, drop_first=True)
# 划分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=6, stratify=y)
# 特征标准化
ssm = StandardScaler()
x_train = ssm.fit_transform(x_train)
x_test = ssm.transform(x_test)
# 训练随机森林模型
rf = RandomForestClassifier(n_estimators=100, criterion='gini', bootstrap=True, random_state=6)
rf.fit(x_train, y_train)
# 预测与评估
y_pred = rf.predict(x_test)
print(f"模型准确率:{accuracy_score(y_test, y_pred):.4f}")
GBDT示例
from sklearn.ensemble import GradientBoostingClassifier
# 使用相同预处理后的数据 (x_train, x_test, y_train, y_test)
gbdt = GradientBoostingClassifier(loss='log_loss', n_estimators=100, learning_rate=0.1, random_state=6)
gbdt.fit(x_train, y_train)
y_pred_gbdt = gbdt.predict(x_test)
print(f"GBDT准确率:{accuracy_score(y_test, y_pred_gbdt):.4f}")
XGBoost示例(基于红酒品质多分类数据集)
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from xgboost import XGBClassifier
from sklearn.metrics import accuracy_score
# 数据加载
df = pd.read_csv('红酒品质分类.csv')
x = df.iloc[:, :-1]
y = df.iloc[:, -1] - 3 # 将类别标签调整为从0开始
# 划分与标准化
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=6, stratify=y)
ss = StandardScaler()
x_train_scaled = ss.fit_transform(x_train)
x_test_scaled = ss.transform(x_test)
# 训练XGBoost多分类模型
model = XGBClassifier(objective="multi:softmax",
eval_metric='mlogloss',
num_class=len(y.unique()),
n_estimators=150,
learning_rate=0.05,
random_state=6)
model.fit(x_train_scaled, y_train)
# 预测与评估
y_pred_xgb = model.predict(x_test_scaled)
print(f"XGBoost准确率:{accuracy_score(y_test, y_pred_xgb):.4f}")
 发表于 2025-12-29 01:27:51
|
查看: 323|
回复: 0
发表于 2025-12-29 01:27:51
|
查看: 323|
回复: 0
