随着人工智能和高性能计算(HPC)席卷全球,数据中心网络在性能、规模和可靠性方面正面临前所未有的挑战。传统的单平面网络架构在处理数万甚至数十万个计算节点(例如GPU)的互连时,可扩展性瓶颈和成本飙升的问题日益凸显。在此背景下,多平面网络架构应运而生,通过构建多个并行、独立的网络平面,为超大规模集群提供了一种全新的解决方案。
本文将深入探讨多平面网络的工作原理、优势和应用场景,并结合具体的架构设计、物理实现和智能调度机制进行阐述。
一、多平面网络的核心原理
多平面网络的核心原理是将单一数据流智能地拆分并进行负载均衡,跨越多个平面。要理解多平面网络,我们首先需要从数据流的微观角度进行分析。
如下图所示,“NVIDIA多级负载均衡与信令”机制阐述了多平面网络的核心思想:在网络入口点(例如网卡)智能地将逻辑上的“单一数据流”拆分。单一数据流被分解为多个子流,并分发到多个独立且物理隔离的“网络平面”进行并行传输。图中显示四个平面:P1、P2、P3和P4,每个平面构成一个完整的交换网络。数据在各自的平面内通过多级交换机进行路由,最终在接收端的网卡上重新聚合,从而重构原始的单一数据流。
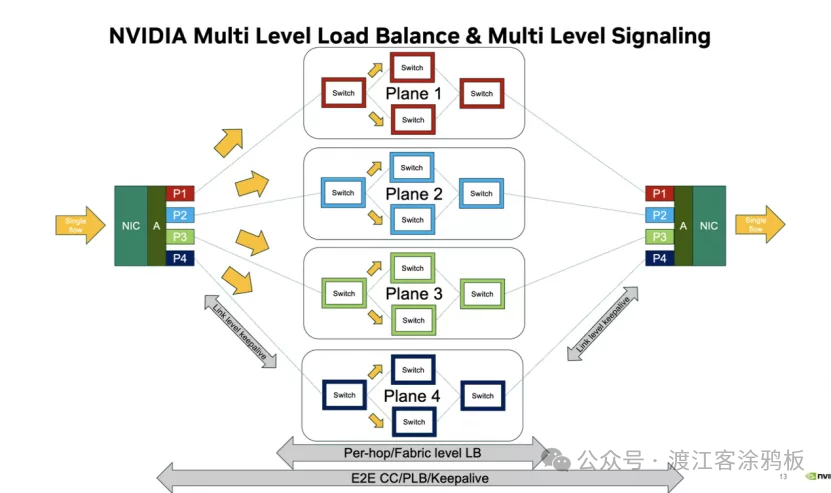
图1:NVIDIA多级负载均衡与信令示意图,展示了数据流在P1-P4四个独立平面上的分发与聚合过程。
这种架构的精妙之处在于多级负载均衡机制。首先,当数据包进入网络时,在网卡(NIC)层进行流量分流——这是第一层负载均衡。接下来,当数据包在其各自平面内的交换矩阵中传输时,每个交换节点都会执行逐跳/结构层级的负载均衡,以确保平面内链路资源的充分利用。更重要的是,整个过程通过端到端拥塞控制(E2E CC)、逐通道负载均衡(PLB)和保活信令进行全局协调。
这意味着系统可以实时感知每个平面的拥塞状态,并动态调整流量分配策略,防止单个热点路径拖累整体通信效率。同时,“链路级保活”信令确保物理连接的稳定性和可靠性。通过这种方式,多平面网络将巨大的通信负载分配到多个“通道”上,显著提升总带宽,并由于平面间的独立性而获得更高的容错能力——即使一个平面发生故障或出现拥塞,其他平面仍能正常运行。
二、多平面网络的物理层布局
虽然理论上理想的平行平面看起来完美无缺,但当扩展到拥有数万个节点的数据中心时,核心挑战在于如何实际实现这些复杂的跨平面连接。
在典型的 Leaf-Spine 网络架构中,服务器/GPU节点首先连接到Leaf交换机,然后Leaf交换机再与所有Spine交换机互连。在多平面网络中,每个GPU节点必须同时连接到不同平面上的叶交换机;同样,Leaf交换机也需要连接到不同平面上的Spine交换机。因此,整体布线复杂度显著增加。

图2:光交换盒(Optical Shuffle Box)物理布局,用于简化多平面网络中的高密度光纤连接。
光交换盒 是一种无源光纤分配设备,旨在解决大规模、高密度光纤连接的问题。它当着精密的“线缆整理器”和“连接转换器”的角色,根据预定义的拓扑结构,将来自不同交换机端口的光纤重新排列,从而在Leaf交换机和Spine交换机之间创建清晰、标准化的跨平面连接。
无源光纤分配设备从多个Leaf交换机端口接收光纤束(例如,每个端口 2 束 100G 光纤),然后在机箱内部,通过预先设计的光路对这些光纤进行“重组”和重新组合,最后将其输出到多个Spine交换机上的相应端口。这使得它可以用结构化的 MPO/MTP 高密度光纤电缆取代大量杂乱的单芯光纤跳线,从而大大简化数据中心内的布线、部署和维护。
三、多平面网络的架构优势
多平面网络架构最显著的优势在于其在超大规模部署场景下的成本优势。下图“单平面与多平面(成本)”通过详细的数据对比直观地展示了这一点。图中比较了传统“单平面三层”架构和“双平面两层”架构在不同GPU规模下的设备需求。单平面架构通常采用“Leaf-Spine-Core”三层结构,层数较深;而多平面架构可以通过增加平面进行水平扩展,从而将网络层压缩为“Leaf-Spine”两层结构,形成更扁平的结构。
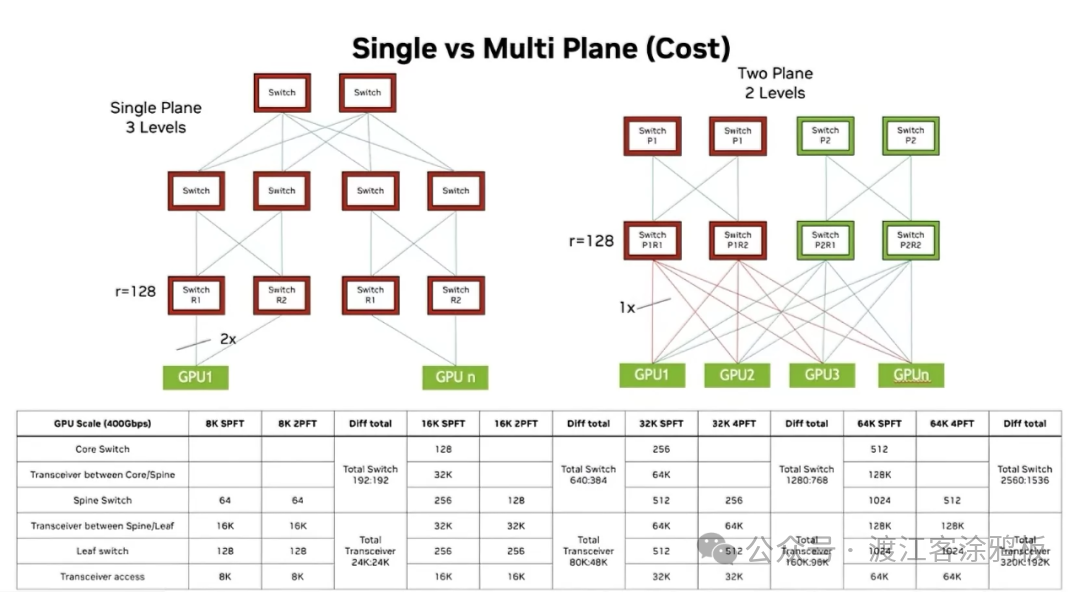
图3:单平面三层与多平面两层架构的成本对比,展示了在32K GPU规模下交换机与光模块的用量差异。
我们以一个拥有32K个GPU的集群为例进行分析。根据图中的数据表,单平面(SPFT)架构需要512台Leaf交换机、256台Spine交换机和最多256台Core交换机。Spine节点和Leaf节点之间需要64K个光模块,Core心节点和Spine节点之间需要32K个光模块。
相比之下,四平面(4PFT,一种多平面架构的例子)设计虽然需要部署更多的Leaf交换机和Spine交换机(分别大约1024个和512个),但避免了使用昂贵的核心层交换机。
更重要的是,其Leaf-Spine层之间的光模块总需求量(表中为96K)等于甚至优于单平面架构Spine-Core层和Leaf-Spine层需求量之和(32K + 64K = 96K),但由于省去了核心层,整体网络部署成本、功耗和管理复杂度都显著降低。从“总差异”列可以看出,随着规模从 8K GPU 扩展到 64K GPU,多平面架构节省的交换机和光模块数量变得越来越显著,凸显成本优势。
这种“水平扩展”方法通过增加平面数量而非网络层数来提升总带宽和连接性,从而显著降低对昂贵核心交换机和相应长距离光模块的依赖。虽然双平面架构可能需要在接入层为每个节点提供双连接,但其在骨干层的成本节约非常显著,最终带来更高的整体成本效益。多层网络架构转变本质上是用更多的水平链路和更扁平的拓扑结构取代了昂贵的垂直堆叠,为构建更大规模的 人工智能 集群铺平了道路。
四、多平面网络应用场景分析
多平面网络架构的价值已在当今大规模人工智能模型训练场景中得到充分体现。训练一个拥有万亿参数的LLM模型需要在数万个GPU之间频繁进行“all-to-all”和“all-reduce”集合通信操作。这些操作对网络的“总互连带宽”和“延迟”提出极高的要求。在传统的单平面胖树网络中,所有GPU的通信流量都汇聚在同一网络结构中。一旦发生拥塞,很容易导致全局性能抖动,造成大量GPU处于“等待”状态,严重影响训练效率和模型浮点运算利用率(MFU)。
多平面网络完美地满足了这一需求。当AI训练任务执行All-Reduce操作时,数据可以在多个平面上同时进行归约和分发,互不干扰,从而大幅提升聚合通信的有效带宽。如果某个平面上的路径出现瞬时拥塞,负载均衡机制可以快速将流量切换到其他更优的平面路径,从而确保整体通信的低延迟和高稳定性。这就像将拥堵的单车道高速公路改造成四车道并行、交通感知的多车道高速公路系统。正是由于多平面网络提供的高带宽、高容错性和无阻塞通信能力,才使得构建由数万个GPU组成的 超大规模集群 成为可能,从而将顶级AI模型的训练周期从数月大幅缩短至数周。
五、结束语
多平面网络通过逻辑优化数据流分布、利用混流盒等关键设备实现高效互连以及采用扁平化架构降低成本,为大规模人工智能和高性能计算应用提供了卓越的网络性能和可扩展性。这不仅是一项技术创新,也为未来超大规模计算系统实现更高效率和更优成本效益奠定了重要基础。
 发表于 2025-12-31 03:17:06
|
查看: 342|
回复: 0
发表于 2025-12-31 03:17:06
|
查看: 342|
回复: 0
