近日,小红书首座自用数据中心获得中国数据中心权威协会CDCC的2025年度十大数据优秀项目及国外数据中心媒体 w.media 的 Northeast Asia Cloud&Datacenter 年度卓悦设计&建设奖 Excellence in Data Centre Design and Build。

图:小红书团队在CDCC 2025十大数据中心优秀项目颁奖现场

图:小红书数据中心项目获得W.Media东北亚云数据中心奖项
这是国内外目前两个影响力最大的数据中心奖项,既是对小红书首次交付自用数据中心的重大肯定,也是小红书基础技术部实用第一、性价比突出、业内领先技术路线理念的体现。

图:小红书数据中心获得的奖杯
本文将梳理小红书数据中心获得两项行业奖项的实践历程,系统剖析其获得行业认可的核心设计方案与标准化运营体系。
文章整体分成六个部分:
- 上云到下云:算力结构变化与基础设施策略调整
- 选址:云上云下协同视角下的数据中心布局
- 服务器与网络:后发优势下的选型与架构实践
- 智算中心设计:集中度、预制化与风/液冷兼容
- 智慧运维体系:自动化分级与能效优化实践
- AI绿色算力:电力、储能与算电协同探索

图:算力结构变化驱动基础设施策略调整
1. 算力架构多元化发展
小红书早期主要是社区和图文内容业务,典型的互联网工作负载,大部分算力需求可以用几个关键词概括:
- CPU为主的通用计算;
- 大量Web/API服务;
- 内容生产、分发、基础推荐与搜索;
- 标准化数据库与缓存集群;
在这个阶段,全面依赖公有云是非常合理的选择:上线快、弹性强,可以支撑业务快速增长和频繁试错。
但是过去五年,情况开始发生了明显变化。随着生成式AI和大模型相关应用的推进,我们的算力需求出现了第二条分支方向:
- 智能计算(GPU):支撑模型训练、在线推理、特征处理等AI工作负载;
智能算力的几个特征值如下:
- 单节点功率密度高,机柜功率密度高;
- 对网络带宽/延迟敏感;
- 训练任务持续时间长,对稳定性要求高;
- 成本压力巨大,对TCO敏感;

图:通算数据中心与智算数据中心特点对比
2. 自建基础设施势在必行
在算力结构变化、电力和GPU等供应链波动,以及数据合规和核心业务可控性要求逐渐提高的背景下,我们做了一个比较明确的判断:
“完全依赖公有云,不再是长期最优解”
对于核心算力,小红书做出了构建“自建基础设施 + 公有云”的混合架构的决定。
随后,小红书开始系统化推进“下云”:
- 自主租用IDC;
- 自主规划采买服务器与网络架构;
- 在云上云下之间构建统一的资源和调度体系;
这不是小红书在“去云”,而是从“全云化”演进到“云上 + 自建算力池”的协同形态。

图:数据中心选址策略的转变
下云的第一步是找到一个合适数据中心站点。很多人提到数据中心选址,第一反应是土地、电价、气候、政策补贴等。这些对我们同样重要,但在做具体规划时,我们把“云上云下协同”和“业务连续性”放在更前面。
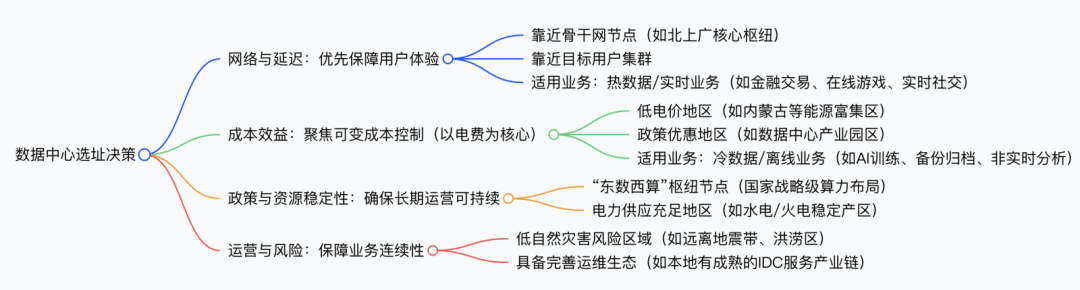
图:数据中心选址决策的四个维度
这里可以简单拆成四个维度:
1. 云上云下协同与容灾
我们不把线下数据中心当成一个独立“孤岛”,而是从一开始就按混合架构来设计:
- 与主流公有云在网络时延上的可接受范围
- 云上云下之间的数据同步方案和带宽预算
- 关键业务在云/线下互为备份、快速切换的可行路径
这会反过来影响我们对机房城市/区域乃至运营商的选择。
2. 用户体验与网络拓扑
我们会结合以下信息:
- 用户主要分布区域
- 三大运营商骨干网与节点布局
- 各区域网络时延与跨域传输能力
目标不是单点极致,而是整体线路可接受、可运维,并能支撑未来跨地域多中心的架构演进。
3. 成本与政策的长期可信度
成本不仅是“今天的电价/地价”,还有:
- 中长期电价政策与能源可获得性
- 地方对数据中心产业的长期态度变化
- 后续扩容(变电、冷源、用地)的空间
我们会刻意规避那些“短期看起来便宜,但未来高度不确定”的选项。
4. 自然灾害与区域冗余
包括:
- 地震带、洪水、极端天气等自然风险;
- 跨地域多数据中心的灾备拓扑和故障域拆分;
总体思路是:先从业务视角出发——云上云下混合、网络拓扑、容灾——然后在这个约束空间里再做成本和政策优化,而不是纯粹成本驱动。

图:聚焦服务器与网络的使用效率
作为数据中心基础设施的“后来者”,我们的优势就是可以直接站在行业已有实践之上做选择,而不是从0开始摸索。
我们的基本原则是:
- 不为了“炫技”而采用复杂方案;
- 不为了“差异化”而走冷门路线;
- 所有选型都要能在业务场景里说清收益;
1. 服务器:三大类型与资源池化
我们团队基于各自的职业经验和行业的快速发展,在服务器规划上做了一个取舍:与其做了非常多的SKU细分或者为了创新而研发不同的机型,不如围绕核心场景收敛几类标准机型,再通过上层的资源池化来吸收差异。
当前推出了三类形态:
- 计算型(单路)
- 面向各类Web服务、API、基础服务组件等;
- 单路配置,追求性能/成本比和部署密度;
- 结合内部调度系统做细粒度分配,提高CPU利用率;
- 推理型(两路 + 4 GPU)
- 面向在线推理 / 实时推荐 / 模型在线服务;
- 强调:PCIe拓扑合理、网络带宽和延迟可控、支持未来更高功率密度的散热方案;
- 这类节点通常需要纳入专门的推理集群调度体系;
- 存储型(高盘位)
- 典型配置:60盘位HDD;
- 服务于日志、内容存储、Warm/Cold Data等;
- 结合分布式存储软件构建统一存储池;
从运维和成本视角看,我们更关心的是集群利用率:
- 在调度和中间件层做资源抽象和池化;
- 减少业务直接和物理机绑定;
- 把“买了多少服务器”转化为“平均利用率是多少”;

图:服务器选型的理念、架构特征与策略
2. 网络:POD + Super Bank + 超高速端口
网络侧,我们采用的是经过各个大厂验证的多级交换架构(CLOS),并结合AI集群的特点做了一些规划。
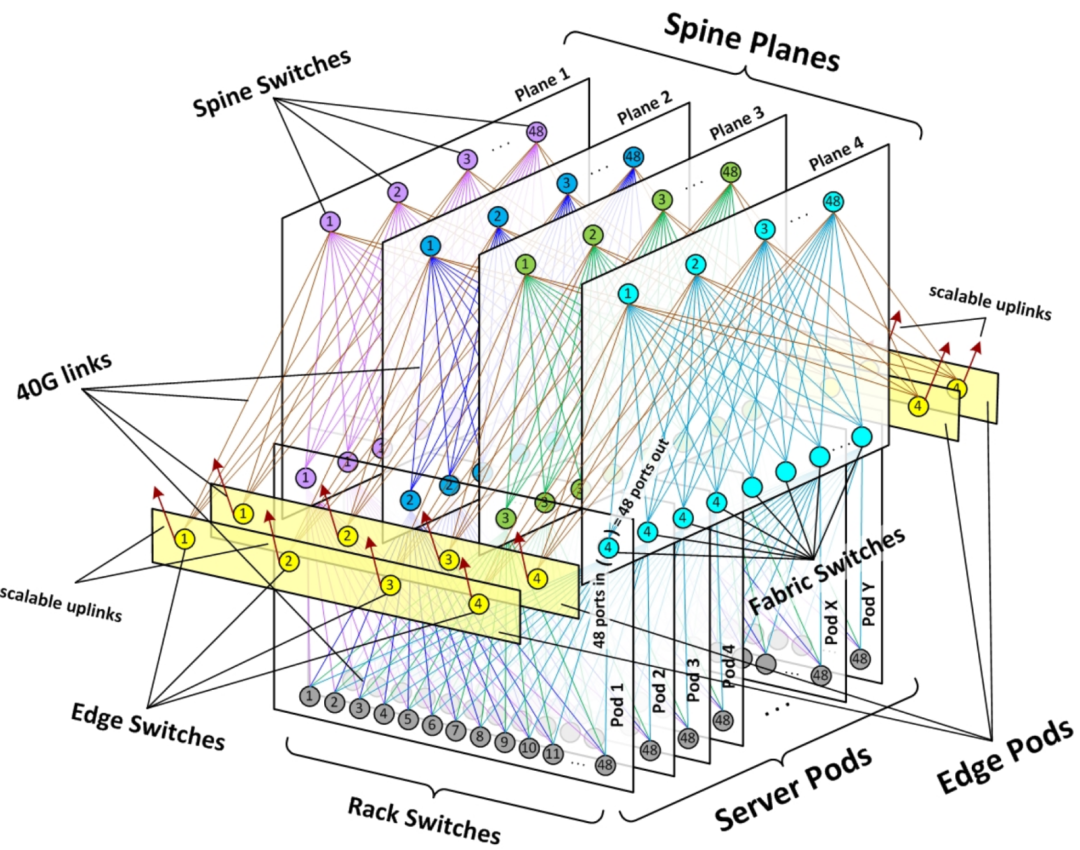
图:数据中心多级网络架构示意图
核心元素包括:
- Spine–Leaf 架构 + POD 化部署
- 每个POD作为基础构建单元,内部使用Spine–Leaf;
- 方便做模块化扩展和分区部署;
- 较好地控制东西向流量和延迟;
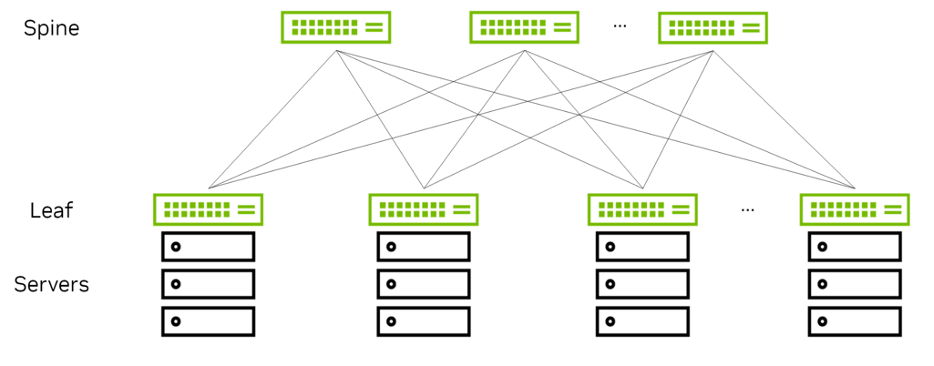
图:Spine-Leaf网络拓扑简图
- 多平面 Super Bank
- 多个POD通过多平面方式组合成更大规模网络;
- 减少单Plane故障的整体影响;
- 支撑从数千到数万级服务器规模的发展;
- 传输速率与介质
- 核心链路采用超300G光模块;
- 局部场景(短距离、对带宽不敏感)配合铜缆,以平衡成本;
- 整体预留向更高速率演进的空间;
整体思路是在性能、可扩展性和成本之间找到一个相对平衡点,而不是追求单点“极致”。

图:智算数据中心设计理念
在数据中心的风火水电层面的设计上,我们尽量避免“设施定死、未来被动适配”,而是从一开始就按AI高功率密度和散热路线的不确定性来预留空间。
1. 高集中度:IT核心区 + 环绕式基础设施
传统数据中心往往是IT设备与基础设施相对分散分区,我们采用的是相对集中化的方式:
- IT包间(机柜、AI集群等)集中布局在中央核心区;
- 配电、制冷、水系统环绕核心区布置;
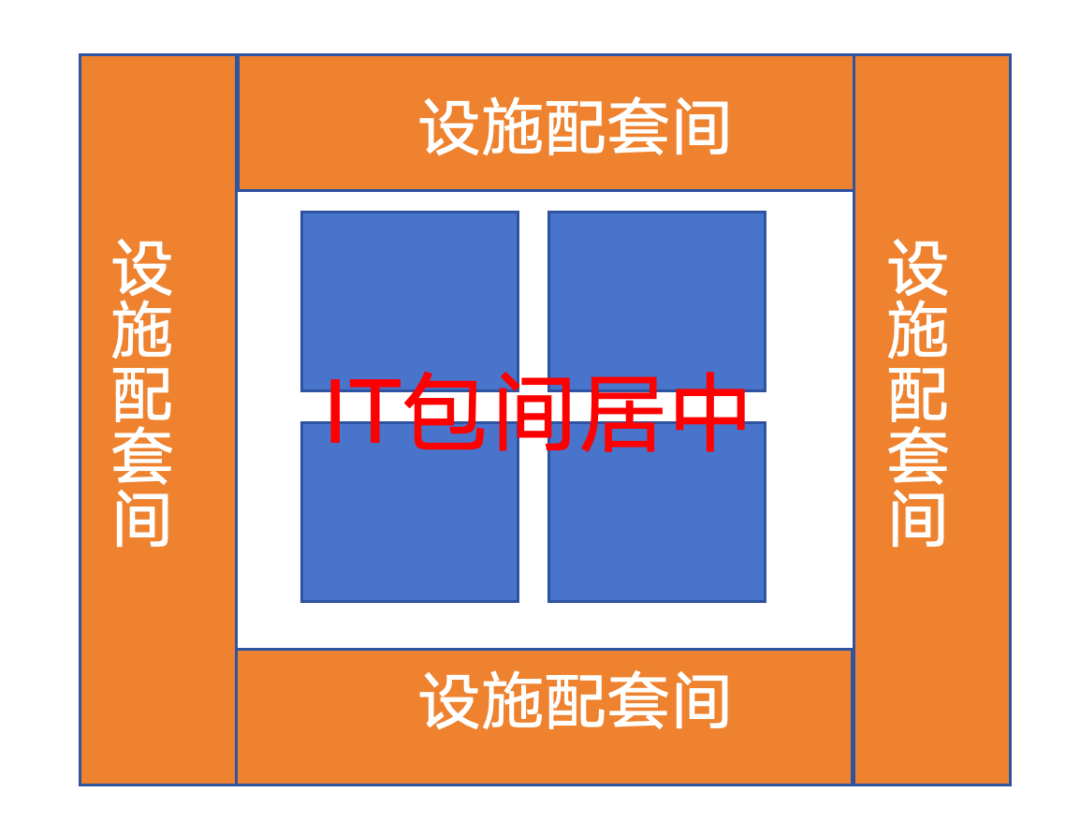
图:IT包间居中,设施配套环绕的平面布局
这样带来的好处:
- 冷量和电力分配更集中,能效更好优化
- 水、电、冷的管线更短,降低损耗与复杂度
- 运维路径更清晰,巡检和应急响应更高效
- 对高功率密度区域可以集中“重点照顾”
2. 预制化:缩短交付周期,提升一致性
在新建和扩建项目中,我们尽量引入预制化模块,包括:
- 预制化电力模块(含变配电、UPS等);
- 预制化制冷模块(冷机、冷却塔、分配单元);
- 微模块数据中心单元;
预制化的价值主要体现在三点:
- 大部分复杂工作在工厂完成,质量更可控;
- 现场只做组装和调试,交付周期显著缩短;
- 模块统一标准,后期扩容和维护更可预测;
对于希望快速上线AI集群或补充算力的场景,这种方式非常实用。
3. 风冷 + 液冷:不押单一路线,提升基础设施的“可变性”
AI集群带来的机柜功率密度,已经在逼近传统风冷机房的上限,但液冷技术路线还在演进中(弥漫式风墙+冷板混合方案并存)。

图:弥漫送风与热通道密闭回风吊顶设计
我们的应对策略是:
- 从设计阶段就支持风冷 + 液冷混用;
- 可在较大比例区间内调整风冷/液冷(比如 5:5 → 1:9);
- 在建筑、管道、配电上为液冷留出足够接口和冗余;
- 在末端空调上兼容不同形态(大风墙、小风墙等),适配高低功率密度混合部署;
这个思路的本质是:不赌哪一种散热方案会“胜出”,而是让基础设施具备根据业务发展和行业技术演进做调整的能力。

图:智慧运维的演进路径
数据中心真正的大头在运维周期。我们在这块的目标可以概括为三层:
- 把所有基础设施状态“看见”
- 把重复的动作“自动化”
- 在能效和安全约束内“自动调优”
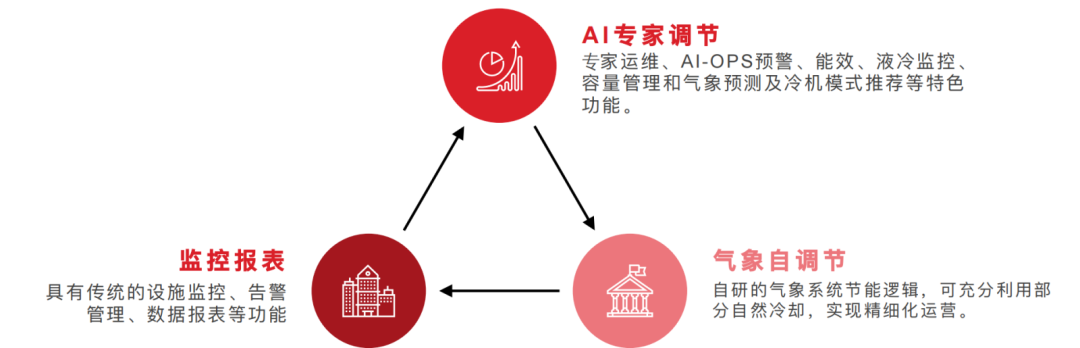
图:智慧运维的三层功能模块
1. 自动化分级:当前能力在 L2+,部分场景向 L3 演进
我们借用自动驾驶的分级方法来理解运维智能化水平:
当前整体能力:L2+(部分自动化)
- 大量标准事件可以自动识别与处置
- 运维人力集中在复杂故障与策略优化上
部分场景开始尝试:L3(高自动化)
- 基于负载预测和气象数据,预先调节冷源与机房参数;
- IT包间内机柜电力等能耗数据的实时监控&分析 ;
这里对机柜电力等能耗数据的监控分析展开讲一下,特别是在机柜超出额定功耗(超电)的场景下我们的自动化分析策略。
结合柜内服务器、网络设备当前的实际使用情况,对用电负载进行梳理与评估。包括:
- 统计各服务器的数量、型号和功耗参数;
- 分析CPU、内存、存储等资源的占用率;
- 评估高负载应用或高并发业务对功率的影响;
- 初步判断是否存在持续超负载运行导致用电偏高的情况。
对柜内整体配电能力和运行状态进行核查。包括:
- 检查配电设计是否满足现有服务器规模和冗余要求,核对电表与监控数据是否存在偏差;
- 对可能存在的线路老化、接触不良、局部过热等隐患进行排查,评估是否存在因电气损耗或异常导致的额外功耗。
通过以上分析,向相关人员和群组推送超电的主要成因,并提供后续的整改措施(如设备优化、负载调整、配电改造等),并提供数据支撑和决策依据。
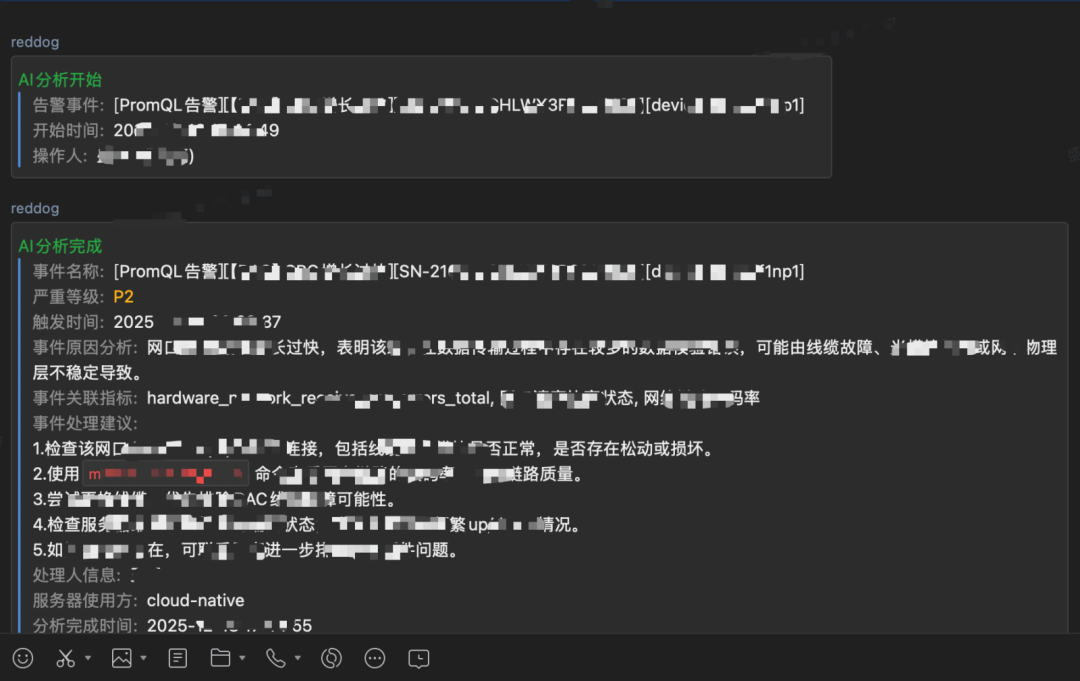
图:AI分析告警事件界面,展示原因分析与处理建议
目标是逐步用系统取代高频重复劳动,把人释放出来做更有价值的事情。
2. DCIM:打通“风、火、水、电”的统一监控和分析
在基础设施监控系统(DCIM)上,我们选择与专业伙伴联合开发,而不是完全从头自研或直接照搬标准产品:
- 利用成熟产品能力,快速打通风、火、水、电等各系统数据接入;
- 再根据小红书的运维流程和组织结构做定制化;
- 建立统一模型和告警体系;
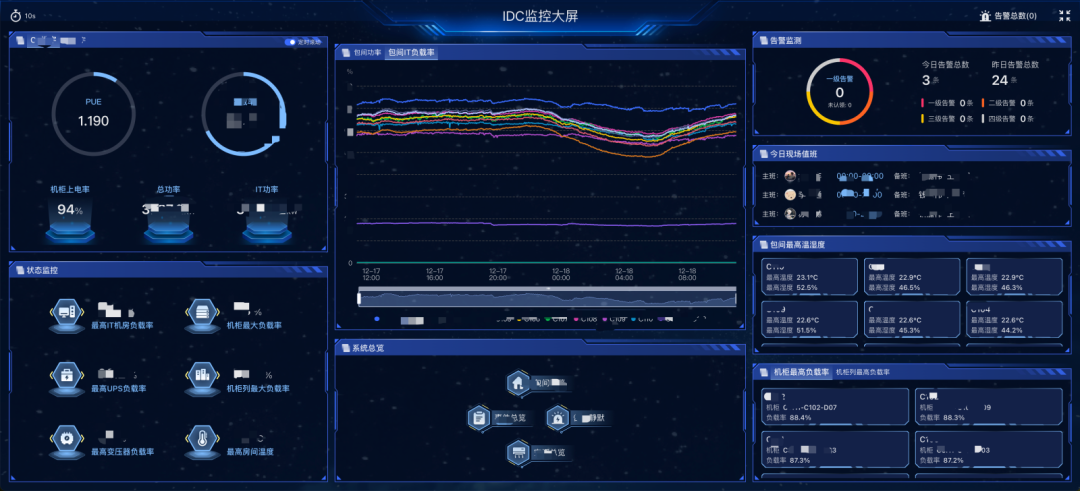
图:IDC监控大屏,显示PUE、功率、告警等关键指标
最终目标是形成数据中心的“中枢神经系统”:
- 所有关键基础设施都有采集、看板、告警;
- 事件可以串起来,做关联分析和根因推断;
- 为后续自动化与智能调优提供数据基础;
3. 能效与PUE优化:用AI和实时数据“持续调参”
能效方面,我们不是简单地做一次性改造,而是做一个“不断调参数”的过程:
- 接入实时气象数据(温度、湿度、风速等);
- 利用自研算法和AI模型,动态调整;
- 自然冷与机械冷的切换策略
- 冷水机组、水泵、冷却塔、末端风机的运行参数;
- 在保障业务连续性的前提下,压低能耗和PUE;
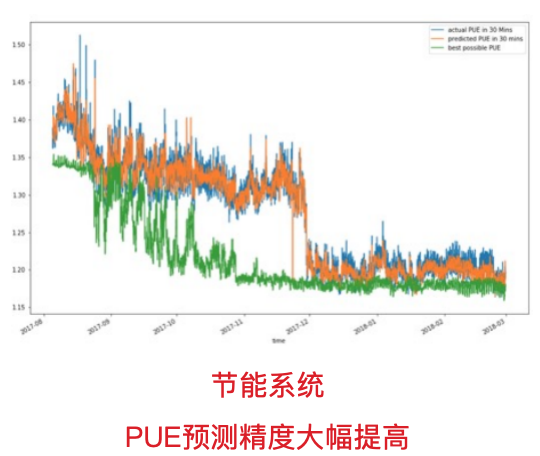
图:PUE预测精度对比,实际值与预测值趋势
我们也在尝试把“业务负载曲线”和“能耗曲线”结合起来,看有哪些任务可以在能效更高的时间窗口执行,为后续算电协同做准备。

图:AI绿色算力探索方向
最后一部分,谈一下与AI算力紧密相关的“电力侧”探索,这块可能是未来几年变化最大的领域。
1. 绿电与自有电源能力
未来对于大型AI算力集群,电力已经不只是“成本项”,而是约束整个体系上限的关键变量。我们的思路可以概括为三点:
- 提高绿电占比(通过绿电交易、长期合同等路径);
- 关注源网荷储一体化的可能性;
- 不只是“买电”,也要考虑未来一定程度的“自发自用”
- 从发电、输电、用电、储能一体规划,提高自洽能力
- 目标不是短期成本最小,而是长期电力供给的稳定性和可控性;
国际上,头部互联网大厂等已经在探索自建发电站(含核能/火电等),我们跟业内同仁认同一个判断:未来AI竞争的一条底层分界线,在于谁能更高效地获得大规模电力。
2. 储能:把“电”的时间维度拉长
储能技术是电力与算力之间的关键缓冲层,也是我们重点关注的方向之一:
- 化学储能(锂电、钠电等);
- 机械储能(飞轮等);
- 势能储能(抽水蓄能等);
我们不会自己做底层技术研发,而是重点跟踪行业成熟方案,把它们:
- 与数据中心负载特性结合;
- 与电价峰谷、用电政策结合;
- 用来平滑电力波峰/波谷,支撑高功率AI任务执行;
储能对数据中心的意义不是简单“备用电源”,而是可以将算力消耗从电力高峰“平移”出来,为后面的算电协同打基础。
3. 算电协同:让算力任务和电价/电网状况“对齐”
最后一块是算力和电力的联动调度问题。我们正在探索这样一些方向:
- 把算力任务按“实时性/可延期性/优先级”做分级;
- 利用电价信号、电网负荷信息,把可延迟任务下沉到低电价/低负荷时段;
- 对跨地域的算力集群,考虑不同区域电价差异和用电政策差异,做整体调度;
简单说,就是:
- 即时业务(如在线推理)优先保障体验和稳定;
- 可延迟的大模型训练等任务尽量“追着低价电、低压电网”跑;
长期看,这块会是AI基础设施的重要优化空间。

小红书的数据中心和AI基础设施建设还在快速演进中,从全云到混合架构,从单一风冷到风/液冷兼容,从传统机房运维到更高水平的自动化,从强调单站点的能效PUE优化到数据中心间的算电协同,这中间有很多工程上的权衡和取舍。
我们没有把自己当成“行业范本”,更多是希望把一些真实的实践过程和决策逻辑分享出来,供大家参考:
- 在选址、机电设计、AI集群网络等方面的经验和坑
- 在DCIM、运维自动化、能效优化上的工具和方法
- 在绿电、储能、算电协同上的探索与试错
也期待后续有更多机会和同行深入沟通,互相借鉴,共同推动数据中心和AI基础设施的整体发展。

如果你对小红书在云原生与高可用基础设施方面的更多实践感兴趣,欢迎持续关注 云栈社区,我们将分享更多一线技术团队的深度思考与实战总结。
 发表于 2025-12-31 03:14:37
|
查看: 405|
回复: 0
发表于 2025-12-31 03:14:37
|
查看: 405|
回复: 0
