这篇文章,我们来测试一个有意思的特性——Flink 程序中的 全局变量 ,即在类中定义、所有函数皆可见的成员变量。
起因是一位学员根据自己的业务需求,编写了一个 Flink CDC 读取 MySQL 的程序,对自己的编码水平不太自信,便发给我点评。
撇开其他部分不谈,他在代码中使用 全局变量 的方式,一下子引起了我的注意。因为类似的玩法,我曾在 Spark 框架中尝试过。
不知道你是否还记得下面这篇历史文章?
为什么不能在 Spark 中定义全局变量?
当时的结局是:尝试失败了——不能在 Spark 程序里,使用全局变量做任何与业务数据相关的统计。
那么,类似的需求,在 Flink 中也会这样吗?我们这次一起来验证看看。
0. 需求
先来看看这个同学的需求。他使用 Flink CDC 读取上游 MySQL 的多张表后,为了判断读取数据的准确性(主要用于每次任务中断后的带状态重启),希望把每张表读到的数据 打印 出来进行观察。
因为只是想验证 Flink CDC 程序每次重启后,读到的数据是否能 接着上一次 ,所以只需要打印每次读取的前几行数据就足够了。
对于这部分逻辑,来看看他是怎么写的。
首先,在程序中定义一个全局变量:
// 记录每个表已打印的行数
private val printedCount = mutable.Map[String, Int]().withDefaultValue(1)
这里使用一个可变的 Map,用来记录 不同表名 与 每张表对应的已打印数据行数 。由于是用 Scala 编写,类的选择比较灵活,这里采用了比较简洁的写法。
接着,在 数据处理逻辑 中,应用这个变量:
rawDS.map(jsonLine => {
val json = JSON.parseObject(jsonLine)
val sourceJson = json.getJSONObject("source")
val table = sourceJson.getString("table")
// 打印前10行
synchronized {
if (printedCount(table) <= 10) {
println(s"[表: $table] 第${printedCount(table)}行: $jsonLine")
printedCount(table) = printedCount(table) + 1
}
}
})
用3秒钟猜一下,这么写,能实现预期效果吗?
1. 运行情况
答案是:能跑通。而且是 本地多线程模式 和 服务器分布式模式 都可以。
这多少有点让我意外,因为在测试 Spark 时,如果采用 服务器分布式模式 ,这个 全局变量 无论在程序中如何操作,其内容始终是空的。
这证明了 Flink 与 Spark 在对待 全局变量 这件事上,采用了不同的策略。
对于 Spark 来说, 全局变量 跨进程后 不可见 ;
而对于 Flink 来说, 全局变量 跨进程后 依然可见 。
不过,这次的实测光证明这一点还不够。我注意到代码中的 synchronized 关键字非常显眼。
稍有 Java 基础的开发者都知道,这个关键字并非随意添加,它的存在理论上一定会让程序的运行效率打折扣(具体原因此处省略一千余字)。
2. 做个优化
在优化之前,我们先做个实验。
在这个变量打印的逻辑里,加上 线程ID :
synchronized {
if (printedCount(table) <= 10) {
val currentThreadID = Thread.currentThread().getId
println(s"当前线程为 $currentThreadID, [表: $table] 第${printedCount(table)}行: $jsonLine")
printedCount(table) = printedCount(table) + 1
}
}
运行后,得到下面的结果:
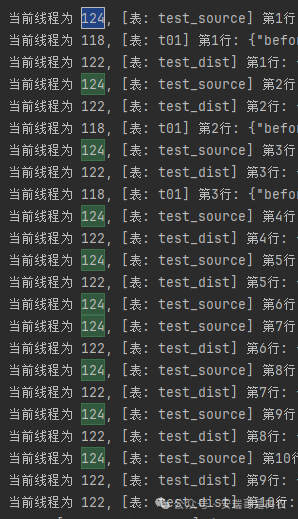
我相信你一眼就能看明白—— 每个线程,都只会负责处理同一张表的数据 。
既然 线程间不存在交替读取同一张表的情况 ,那对于这个 全局变量 ,还要 synchronized 关键字有什么用呢?
因此,我们可以放心大胆地去掉它。
if (printedCount(table) <= 10) {
val currentThreadID = Thread.currentThread().getId
println(s"当前线程为 $currentThreadID, [表: $table] 第${printedCount(table)}行: $jsonLine")
printedCount(table) = printedCount(table) + 1
}
去掉后再次运行,查看结果:
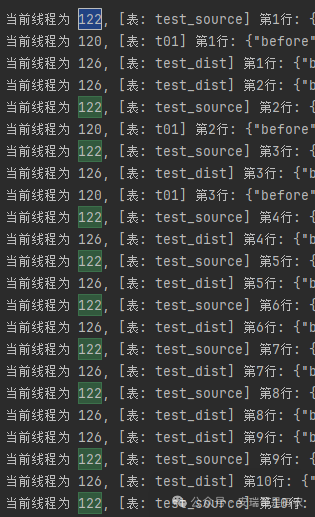
结果丝毫没有影响(当然,在分布式环境下也是一样的,这里就不重复截图了)。这进一步验证了在处理 大数据 流时,Flink 对任务划分的线程隔离性。
最后
虽然这只是一次小小的 全局变量应用 测试,但揭示的却是 Spark 与 Flink 在解决相同问题时,底层设计的较大差异。
同时,这次实测也说明,对于 Flink CDC 读取的数据源, 一张数据源表,严格对应一个处理线程 ,开发者在设计状态逻辑时无需担心线程交叉访问带来的数据一致性问题。
 发表于 2026-1-3 09:31:47
|
查看: 278|
回复: 0
发表于 2026-1-3 09:31:47
|
查看: 278|
回复: 0
