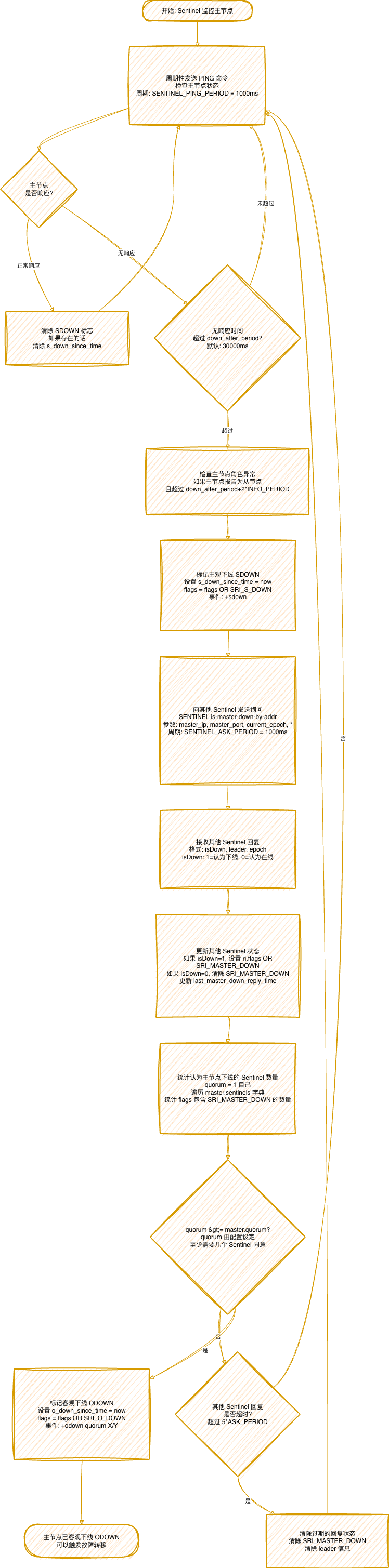
一、Redis master下线判断流程
关键概念说明
主观下线 (SDOWN - Subjectively Down)
定义:单个 Sentinel 认为主节点已下线。
触发条件:
- 主节点在
down_after_period 时间内无响应。
- 或者主节点角色异常(报告为从节点)。
作用范围:仅当前 Sentinel 的观察。
客观下线 (ODOWN - Objectively Down)
定义:多个 Sentinel(达到 quorum)都认为主节点已下线。
触发条件:
- 主节点已被标记为 SDOWN。
- 统计认为主节点下线的 Sentinel 数量
>= master.quorum。
作用范围:所有 Sentinel 达成共识。
关键配置参数
down_after_period: 主观下线判定时间,默认 30000ms。quorum: 客观下线所需的最少 Sentinel 数量(配置设定)。SENTINEL_PING_PERIOD: PING 命令周期,默认 1000ms。SENTINEL_ASK_PERIOD: 询问其他 Sentinel 的周期,默认 1000ms。
通信机制
SENTINEL is-master-down-by-addr: 用于询问其他 Sentinel 对主节点状态的看法。- 回复格式:
[isDown(int), leader(string), epoch(int)]。
- 投票时机: 当 runid 参数为 “*” 时,只询问状态;当 runid 为具体 ID 时,请求投票。
单个 Sentinel 判断主节点下线后,这只是“主观”判断。那么如何从“主观判断”上升到“客观事实”呢?这需要 Sentinel 集群通过投票达成共识,这也是构建可靠高可用系统的关键一步。
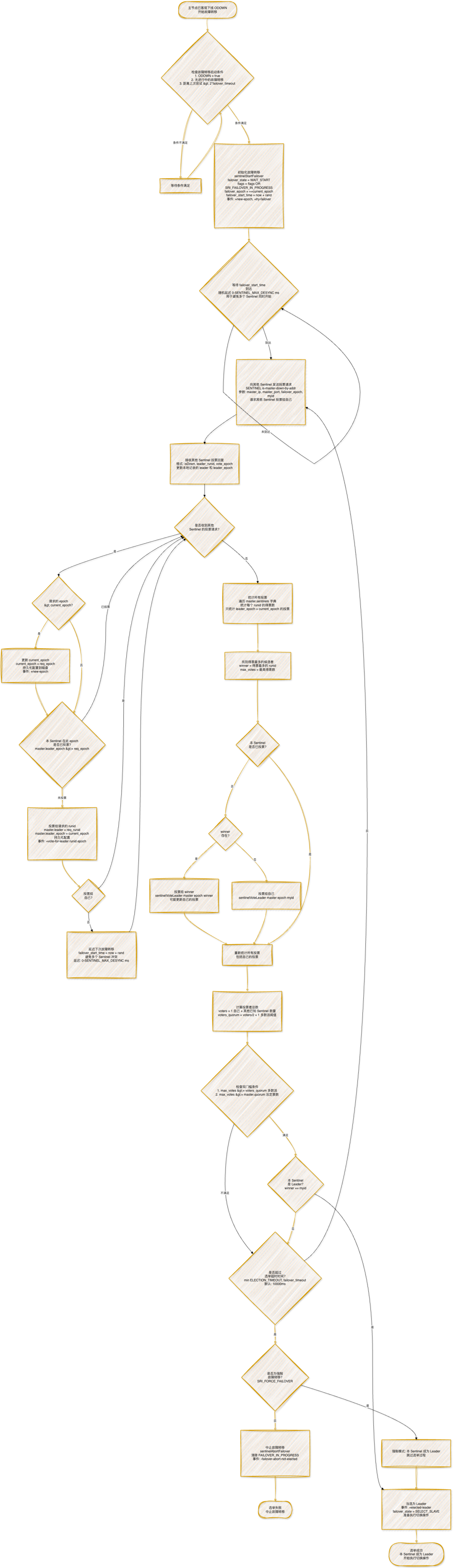
二、Sentinel Leader选举流程
关键机制说明
Epoch(纪元)的作用
current_epoch: 全局纪元,每次发起故障转移时递增,确保选举的唯一性。failover_epoch: 本次故障转移的纪元,等于发起时的 current_epoch。leader_epoch: 投票给领导者的纪元,用于标识投票的轮次。
投票规则
- 一纪元一票: 每个 Sentinel 在每个 epoch 只能投票一次。
- 纪元更新: 收到更大的 epoch 请求时,先更新自己的
current_epoch。
- 自动跟投: 如果本 Sentinel 未投票,会跟投当前得票最多的候选者。
- 投票持久化: 投票结果会持久化到配置文件,确保重启后不丢失。
双门槛条件
选举成功的候选者必须同时满足两个条件:
- 多数派条件:得票数
>= voters/2 + 1
- 确保有超过半数的 Sentinel 支持。
- 防止脑裂(split-brain)。
- 法定票数条件: 得票数
>= master.quorum
quorum 是配置设定的最小投票数。- 确保有足够的 Sentinel 参与投票。
随机延迟机制
- 目的: 避免多个 Sentinel 同时发起故障转移。
- 实现:
failover_start_time = now + rand() % SENTINEL_MAX_DESYNC。
- 效果: 给最早检测到问题的 Sentinel 更多机会成为 Leader。
强制故障转移
- 触发: 执行
SENTINEL FAILOVER 命令。
- 特点: 可以绕过选举过程,直接执行切换操作。
- 使用场景: 手动运维、测试、特殊故障处理。
超时控制
- 选举超时:
SENTINEL_ELECTION_TIMEOUT = 10000ms (10秒)。
- 故障转移超时:
SENTINEL_DEFAULT_FAILOVER_TIMEOUT = 180000ms (3分钟)。
- 实际超时:
min(ELECTION_TIMEOUT, failover_timeout)。
选举出 Leader 只是开始,真正的挑战在于如何安全、平滑地将一个从节点提升为新主节点,并让整个数据库/中间件集群快速恢复服务。
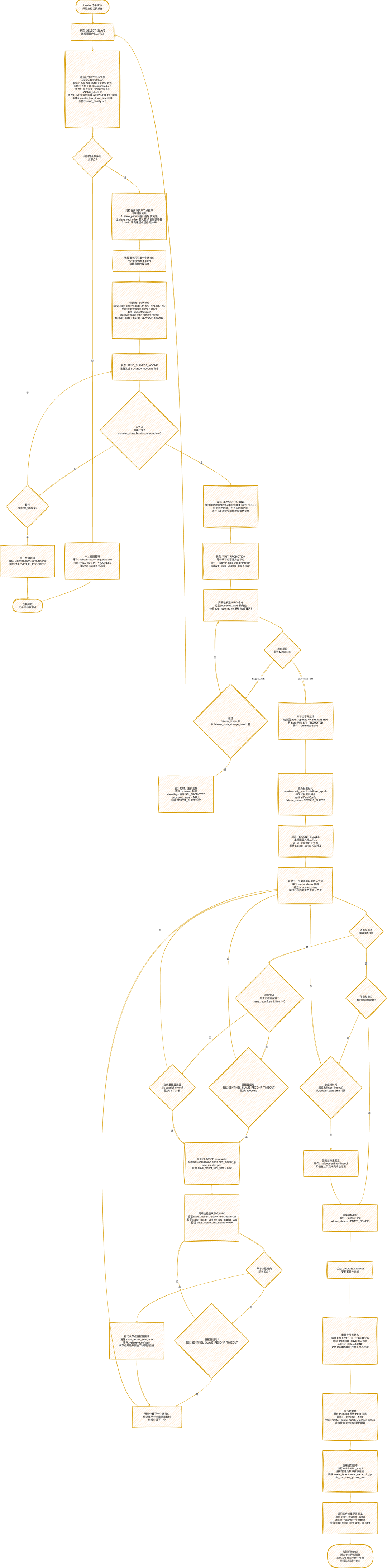
三、Redis主从切换流程
关键状态说明
故障转移状态机 (failover_state)
SELECT_SLAVE (2): 选择要晋升的从节点。SEND_SLAVEOF_NOONE (3): 发送 SLAVEOF NO ONE 命令。WAIT_PROMOTION (4): 等待从节点晋升为主节点。RECONF_SLAVES (5): 重新配置其他从节点。UPDATE_CONFIG (6): 更新配置并完成。
从节点选择标准
- 健康检查: 不在 SDOWN/ODOWN 状态,连接正常。
- 信息新鲜度: 最近回复 PING 和 INFO 的时间在合理范围内。
- 复制状态:
master_link_down_time 在合理范围内。
- 优先级:
slave_priority != 0(0 表示不参与选举)。
从节点排序规则
选择最优从节点的优先级(从高到低):
slave_priority 越小越好: 配置的从节点优先级。slave_repl_offset 越大越好: 复制偏移量越大,数据越新。runid 字典序越小越好: 作为最后的排序依据。
并发控制
parallel_syncs: 控制同时重配置的从节点数量,默认 1。- 目的: 避免新主节点同时为多个从节点提供全量同步,造成性能问题。
- 实现: 只有当正在重配置的从节点数
< parallel_syncs 时,才发送 SLAVEOF 命令。
超时控制
SENTINEL_SLAVE_RECONF_TIMEOUT: 单个从节点重配置超时,默认 10000ms。failover_timeout: 整个故障转移的总超时,默认 180000ms (3分钟)。- 处理策略: 超时后强制进入下一阶段,确保故障转移能够完成。
配置传播
- Hello 消息: 通过 Pub/Sub 发布到
__sentinel__:hello 频道。
- 包含信息: Sentinel 地址、主节点地址、配置纪元等。
- 更新机制: 其他 Sentinel 收到更大的
config_epoch 时,自动更新本地配置。
通知脚本
notification_script: 通知管理员脚本,在故障转移完成时调用。client_reconfig_script: 客户端重配置脚本,通知应用更新主节点地址。- 异步执行: 脚本在后台执行,不阻塞故障转移过程。
整个流程从节点健康监控、集群共识选举到最终的主从切换,体现了 Redis Sentinel 为实现高可用所做的精细设计。理解这些内部机制,有助于我们在生产环境中更好地配置、监控和排查 Sentinel 相关问题。如果你想深入了解其他分布式系统原理或数据库运维实践,欢迎到云栈社区与更多开发者交流讨论。 |  发表于 2026-1-17 00:00:45
|
查看: 178|
回复: 0
发表于 2026-1-17 00:00:45
|
查看: 178|
回复: 0
