
我们都知道,DeepSeek-R1 或 OpenAI o1 的成功,很大程度上验证了强化学习在提升模型推理能力上的统治力。但在这些光环之下,有一个尴尬的角落被很多人忽视了:搜索智能体(Search Agents)。
让模型做数学题,答案是对是错,写个 Python 脚本就能验证。但如果你问模型:“2024年诺贝尔物理学奖得主的本科导师是谁?”,模型不仅要会搜索,还要从一大堆网页噪音中提取信息。训练这类智能体,通常需要人类精心编写的“问题-搜索路径-答案”数据。
这就引出了今天的主角——Dr. Zero。这篇论文不仅名字听起来像个反派,它的野心也极大:不给任何一条人类标注数据,让一个大模型通过自我博弈,进化成顶级的搜索专家。

摆脱“平庸之恶”:为什么要设计 Proposer?
在 Dr. Zero 之前,也有人尝试过让模型自己问自己(Self-evolution)。但以前的方法有个致命弱点:模型太“懒”了。
如果没有外界刺激,模型倾向于生成简单的、一步就能搜到答案的“单跳(One-hop)”问题。做这种题,模型很难学到复杂的推理链条。
Dr. Zero 的破局点在于引入了一个Proposer(出题人) 和一个Solver(做题人) 的对抗进化机制:
- Solver:负责用搜索引擎找答案。
- Proposer:负责基于给定的文档片段,构造出需要 N 步搜索才能解出的难题。
这就像一个魔鬼教练和运动员的关系。教练必须不断设计更难的训练项目(从单跳问题进化到多跳问题),否则运动员就会停滞不前。
我们可以从下面这张架构图中清晰地看到这个循环:
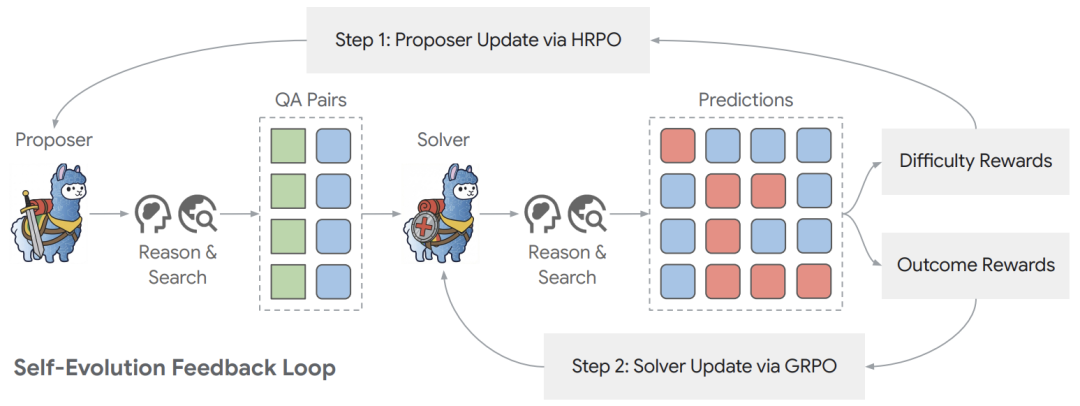
这就形成了一个完美的闭环:Solver 能力越强,简单的题就没有奖励了,逼迫 Proposer 去生成更难的题;Proposer 出的题越难,Solver 就必须学会更复杂的搜索策略(比如追问、多步验证)才能得分。这正是 强化学习 思想在智能体训练中的巧妙应用。
HRPO:打破计算瓶颈的关键一刀
如果仅仅是 Proposer-Solver 的循环,并没有太多新意。这篇论文真正的工程学明珠在于它提出的优化算法——HRPO (Hop-Grouped Relative Policy Optimization)。
要理解 HRPO 的价值,我们得先看它的前身 GRPO(Group Relative Policy Optimization)。在 DeepSeek-R1 等工作中,GRPO 非常流行。它的逻辑是:对于同一个问题 x,让模型生成 m 个不同的回答 y_i,然后算出这组回答的平均奖励作为基线(Baseline),用来减少方差。
但这个逻辑在搜索场景下是灾难性的。 为什么?因为搜索太慢了!生成数学推理很快,但调用 Google/Bing 搜索接口、读取网页、提取信息,这个过程极其耗时。如果你对每一个问题都采样 m 次搜索路径(Nested Sampling),训练成本会指数级爆炸。
Dr. Zero 的解法非常聪明: 它不再对“同一个问题”采样多次,而是对“同一类难度”的问题进行归一化。
作者发现,Proposer 生成的问题天然带有“难度标签”(比如 1-hop 简单题,3-hop 难题)。HRPO 做的就是:
- 对于每个 Prompt,Proposer 只生成一个问题(而不是 n 个)。
- Solver 也只尝试解答一次。
- 在计算优势函数(Advantage)时,不是跟自己比,而是跟同一个Batch里同样是h-hop难度的其他问题比。
公式如下:
Advantage(x, y) = r(x, y) - mean_{x' in batch_h} r(x', y‘)
这里的 batch_h 代表所有属于 h 跳难度的问题集合。
这就像考试评分。你不能拿做“1+1=2”的学生得分去和做“微积分”的学生比。HRPO 相当于把做简单题的归一组,做难题的归一组,然后在组内进行标准化排名。这样既保证了公平,又彻底省去了对单个问题重复采样的计算浪费,效率提升了约 4 倍。
奖励设计的艺术:寻找“甜蜜点”
Proposer 应该因为什么而获得奖励?如果 Proposer 出的题 Solver 答对了,给奖励吗?不行,那它会一直出送分题。如果 Solver 答错了,给奖励吗?也不行,那它会出无解的乱码题。
Dr. Zero 设计了一个难度导向的奖励(Difficulty-Guided Reward)。它追求的是 Solver 处于“懂与不懂之间”的状态。
具体的奖励函数设计得非常精妙:
r_diff(s, h) = 1 - (2 * c_s / h - 1)^2
其中 c_s 是 Solver 答对的次数。
- 如果
c_s = 0(全错),奖励为 0。
- 如果
c_s = h(全对),奖励也为 0。
- 只有当
c_s ≈ h/2 时,Proposer 才能拿到高分。
这意味着,最好的问题是那些有挑战性、但并非不可解的问题。此外,为了防止模型“玩脱了”生成非法格式,还引入了格式奖励 r_fmt。这种对奖励函数的精妙设计,体现了在 基础与综合 层面优化AI系统行为的深度思考。
实验:零数据 vs. 全监督
这就是最让人兴奋的部分了。作者使用了 Qwen2.5-3B 和 7B 作为基座模型,在完全不使用 NQ、HotpotQA 等数据集进行训练的情况下,直接硬刚监督学习模型(SFT)甚至其他 RL 方法(如 Search-R1)。
让我们看看数据:
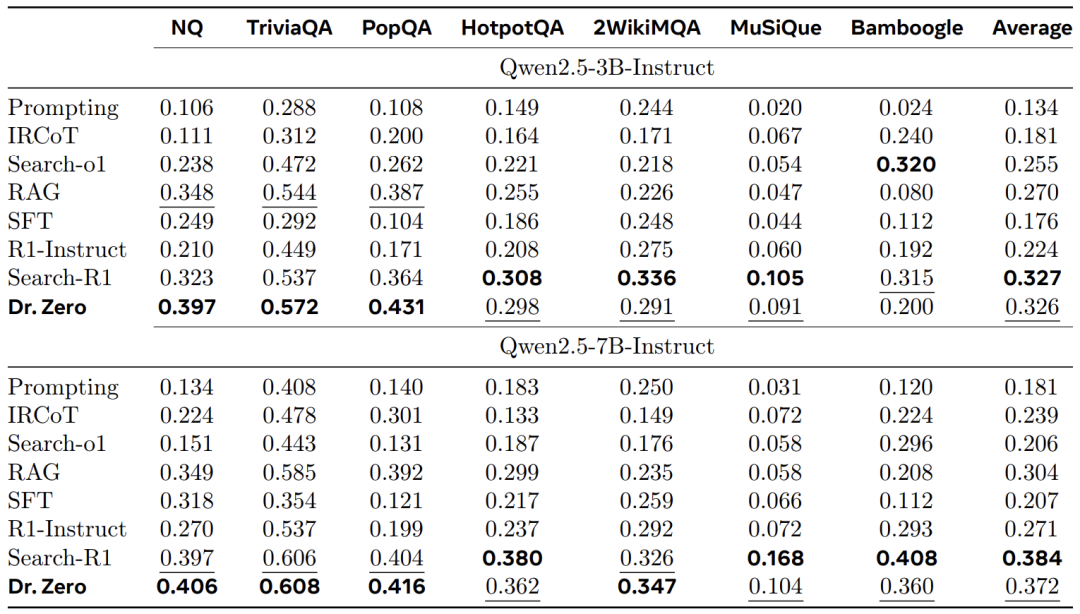
- 碾压少样本(Few-shot):在 Natural Questions (NQ) 数据集上,Dr. Zero (3B) 拿到了 39.7 的分数,几乎是传统 Prompting (10.6) 的 4 倍,也远超 RAG 基线。
- 挑战全监督(Supervised):最离谱的是,即使对比使用了大量人工标注数据的 Search-R1,Dr. Zero 在 3B 参数量下,单跳任务(Single-hop)竟然反超了 22.9%。在 7B 参数量下,它在复杂的 2WikiMQA 数据集上也击败了 Search-R1。
为什么 3B 模型反而比 7B 在某些任务上提升更明显?
论文中的消融实验给出了一个有趣的观察:对于小模型(3B),强化基础的搜索能力(哪怕是单跳查询)带来的收益巨大;而对于大模型(7B),由于其本身基础能力较强,它更受益于多跳的复杂数据训练。
局限与思考
当然,Dr. Zero 并不是完美的。作者坦诚地列出了几个值得深思的问题:
- Token ID 不一致的崩溃:在多轮交互中,Token ID 的微小变动有时会导致模型训练不稳定,这种现象在 7B 模型上反而比 3B 更严重。这意味着模型越大,虽然越聪明,但也可能越“敏感”。
- 长文本生成的瓶颈:随着 Hop 数增加(比如 4-hop),模型容易触碰到上下文长度的限制,或者在复杂的格式约束下动作变形(见 Qualitative Examples 中的失败案例)。
- 自进化的天花板:虽然无需数据,但从图表看,训练 3 轮之后性能提升就开始边际递减了。这暗示了仅仅靠“内部互搏”,可能最终还是会受限于基座模型本身的知识边界。
总结
Dr. Zero 的核心价值不在于它刷新了多少 SOTA,而在于它证明了一条路径:复杂的工具使用和搜索能力,是可以“无中生有”的。
通过 HRPO 解决效率问题,配合巧妙的奖励函数设计,我们完全可以不再依赖昂贵的人工标注,让 AI 自己在信息的海洋里学会捕鱼。这对于那些垂直领域(如金融、法律搜索)的开发者来说,是一个巨大的利好消息。你可能不再需要雇佣昂贵的专家来写 Prompt 了,让模型自己去“左右互搏”吧。这项研究也为 人工智能 社区探索更高效、更通用的智能体训练范式提供了新思路。更多关于AI前沿技术的探讨,欢迎访问 云栈社区 进行交流。
 发表于 2026-1-17 03:50:25
|
查看: 276|
回复: 0
发表于 2026-1-17 03:50:25
|
查看: 276|
回复: 0
