前提
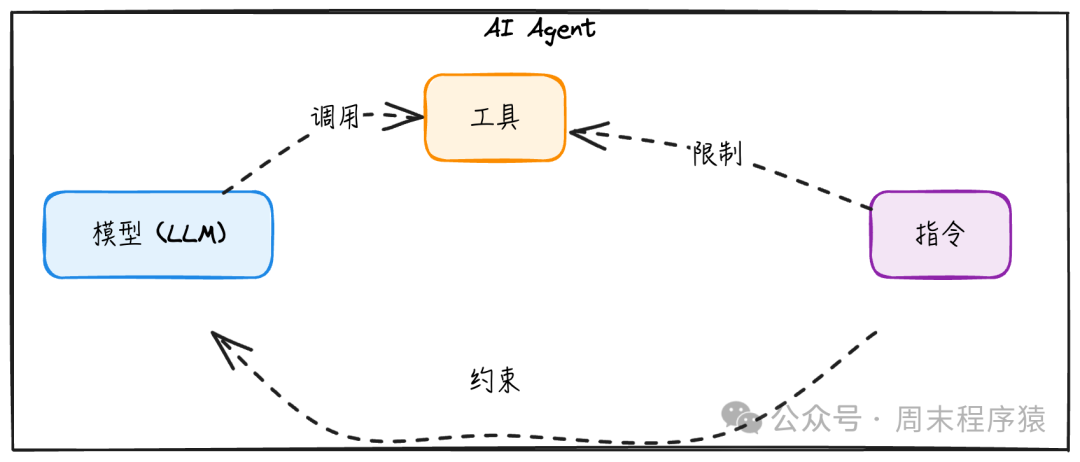
AI Agent 构成
- 模型:为智能体的推理和决策提供动力的LLM,决定了智能体的能力下限。
- 工具:智能体可用于采取行动的外部函数或API。
- 指令:定义智能体行为的明确指导方针和安全策略。
三者共同构成AI Agent的核心能力边界。模型越强,对工具和指令的调度越精准;但从工程角度看,即使使用较弱的模型,通过合理设计工具与指令,也能构建功能强大的Agent。
由于Anthropic的Tool Calling协议已被多数大模型支持且成熟稳定,本文默认通过传入TOOLS参数实现模型调用工具的功能。示例如下:
{
"name": "my_function_name",
"description": "The description of my function",
"input_schema": {
"type": "object",
"properties": {
"query": {
"description": "The search query to perform."
}
},
"required": ["query"]
}
}
给模型传入TOOLS参数后,LLM API 返回如下结构:
{
"type": "tool_use",
"id": "toolu_01A09q90qw90lq917835123",
"name": "my_function_name",
"input": {
"query": "Latest developments in quantum computing"
}
}
简单的 v0:Shell 到复杂 v4:Skills
如前所述,AI Agent由工具和指令组成。我们基于其核心原理——“感知 → 认知 → 执行 → 反馈 → 感知”循环,逐步演进:
- v0: Shell 是基础工具
- v1: 模型即代理
- v2: 结构化规划与 Todo
- v3: 子代理
- v4: Skills
v0: Shell 是基础的工具
Shell 在各类操作系统中广泛存在(如 Bash 脚本),可作为通用工具集的基础。
工具映射表
| 工具 |
对应 Bash 命令示例 |
| 读文件 |
cat file.txt, head -n 20 file.py, grep "TODO" -n -r . |
| 写文件 |
echo '...' > file, cat << 'EOF' > main.py |
| 搜索/导航 |
find . -name "*.py", ls -R, rg "keyword" . |
架构

- 核心逻辑是一个简单循环:模型 → 工具调用 → 工具结果 → 模型
- 不引入额外抽象(如 Task/Plan/Registry),全部由「自然语言 + Bash + 递归」实现
不足之处
- 缺乏工程化安全边界(路径沙盒、命令白名单)
- 可观测性不足(缺少结构化日志、任务树可视化)
- 无语义层面的角色区分(计划者/执行者/审阅者)
该版本仅保留最小闭环所需要素。
一个工具就够了
Bash 本身就是“元工具”:几乎所有其他工具(curl、git、python、docker等)都可通过 Bash 间接调用。
递归 = 层级结构
无需实现复杂的 Task/Plan 抽象;只要允许“调用自己”,层级结构自然涌现。
进程 = 上下文隔离
操作系统的进程模型天然提供上下文隔离,无需额外会话ID或容器管理。
提示词 = 行为约束
系统提示词定义了当前 Agent 的角色与责任边界,决定其如何使用 Bash 能力。
核心循环
while True:
response = model(messages, tools)
if response.stop_reason != "tool_use":
return response.text
results = execute(response.tool_calls)
messages.append(results)
完整代码
import sys
import os
import traceback
from llm_factory import LLMFactory, LLMChatAdapter
from util.mylog import logger
from utils import run_bash, BASH_TOOLS
# 初始化 API 客户端
llm = LLMFactory.create(
model_type="openai",
model_name="deepseek-v3.2",
temperature=0.0,
max_tokens=8192
)
client = LLMChatAdapter(llm)
# 系统提示词
SYSTEM = f"""你是一个位于 {os.getcwd()} 的 CLI 代理,系统为 {sys.platform}。使用 bash 命令解决问题。
## 规则:
- 优先使用工具而不是文字描述。先行动,后简要解释。
- 读取文件:cat, grep, find, rg, ls, head, tail
- 写入文件:echo '...' > file, sed -i, 或 cat << 'EOF' > file
- 避免危险操作,如 rm -rf等删除或者清理文件, 或格式化挂载点,或对系统文件进行写操作
## 要求
- 不使用其他工具,仅使用 bash 命令或者 shell 脚本
- 子代理可以通过生成 shell 代码执行
- 如果当前任务超过 bash 的处理范围,则终止不处理
"""
def extract_bash_commands(text):
"""从 LLM 响应中提取 bash 命令"""
import re
pattern = r'```bash\n(.*?)\n```'
matches = re.findall(pattern, text, re.DOTALL)
return [cmd.strip() for cmd in matches if cmd.strip()]
def chat(prompt, history=None, max_steps=10):
if history is None:
history = []
has_system = any(msg.get("role") == "system" for msg in history)
if not has_system:
history.insert(0, {"role": "system", "content": SYSTEM})
history.append({"role": "user", "content": prompt})
step = 0
while step < max_steps:
step += 1
response = client.chat_with_tools(
prompt=prompt,
messages=history,
tools=BASH_TOOLS
)
assistant_text = []
tool_calls = []
for block in response.content:
if getattr(block, "type", "") == "text":
assistant_text.append(block.text)
elif getattr(block, "type", "") == "tool_use":
tool_calls.append(block)
full_text = "\n".join(assistant_text)
if full_text:
logger.info(f"助手: {full_text}")
history.append({"role": "assistant", "content": full_text})
elif tool_calls:
history.append({"role": "assistant", "content": "(Executing tools...)"})
if not tool_calls:
logger.info(f"第 {step} 步结束,无工具调用")
if response.stop_reason == "end_turn":
return full_text
return full_text or "(No response)"
logger.info(f"第 {step} 步工具调用: {tool_calls}")
all_outputs = []
for tc in tool_calls:
if tc.name == "bash":
cmd = tc.input.get("command")
if cmd:
logger.info(f"[使用工具] {cmd}")
output = run_bash(cmd)
all_outputs.append(f"$ {cmd}\n{output}")
if len(output) > 200:
logger.info(f"输出: {output[:200]}... (已截断)")
else:
logger.info(f"输出: {output}")
else:
logger.warning(f"Unknown tool: {tc.name}")
if all_outputs:
combined_output = "\n".join(all_outputs)
history.append({"role": "user", "content": f"执行结果:\n{combined_output}\n\n请继续处理。"})
else:
history.append({"role": "user", "content": "Error: Tool call failed or produced no output."})
return "达到最大执行步数限制,停止执行。"
if __name__ == "__main__":
if len(sys.argv) > 1:
logger.info(chat(sys.argv[1]))
else:
logger.info("Bash 代理已启动。输入 'exit' 退出。")
history = []
while True:
try:
user_input = input("> ")
if user_input.lower() in ['exit', 'quit']:
break
chat(user_input, history)
except KeyboardInterrupt:
logger.info("\n正在退出...")
break
except Exception as e:
logger.info(f"\n错误: {e}")
traceback.print_exc()
执行完整流程
输入: 统计当前目录下的代码行数,输出到控制台
输出:
(base) linkxzhou@LINKXZHOU-MC1 miniagent % python3.11 v0_bash.py
2026-01-16 21:39:40,009 - INFO - ====== 使用 openai 模型: deepseek-v3.2, 参数:(0.0, None, 8192)
2026-01-16 21:39:40,009 - INFO - OpenAI API 配置已初始化
2026-01-16 21:39:40,037 - INFO - Bash 代理已启动。输入 'exit' 退出。
> 统计当前目录下的代码行数,输出到控制台
2026-01-16 21:39:56,102 - INFO - OpenAI API 响应内容: 我将统计当前目录下的代码行数并输出到控制台...
2026-01-16 21:39:56,105 - INFO - 第 1 步响应: <class 'llm_factory.Response'>
2026-01-16 21:39:56,105 - INFO - 助手: 我将统计当前目录下的代码行数并输出到控制台...
2026-01-16 21:39:56,105 - INFO - 第 1 步工具调用: [<class 'llm_factory.ToolUseBlock'>]
2026-01-16 21:39:56,105 - INFO - [使用工具] pwd
2026-01-16 21:39:56,129 - INFO - 输出: /Volumes/my/github/mylib/llm/llmapi/miniagent
...
2026-01-16 21:40:04,810 - INFO - 助手: 我已经统计了当前目录下的代码行数。结果显示:
...
**总计:1,761 行代码**
2026-01-16 21:40:04,810 - INFO - 第 4 步结束,无工具调用
v1: 模型即代理
Agent 的核心是自主决策:只需人工设定目标+约束规则,让大模型自主决定如何调用工具、遵循规则,从而实现通用性。
传统助手 vs Agent 系统
传统模式:
用户 -> 模型 -> 文本回复
Agent 模式:
用户 -> 模型 -> [工具 -> 结果]* -> 回复
^_________|
模型可以反复调用工具直至任务完成,将“聊天机器人”升级为“自主代理”。
对于本地代码助手,4个工具即可覆盖80–90%场景:
| 工具 |
用途 |
示例能力 |
bash |
运行命令 |
npm install, git status |
read_file |
读取文件内容 |
查看 src/index.ts 实现 |
write_file |
创建/覆盖文件 |
创建 README.md |
edit_file |
精确修改代码片段 |
插入日志、重构方法 |
具备这些工具后,模型可完成以下任务:
- 探索代码库:
bash: find, ls, tree, rg/grep
- 理解代码:
read_file 查看具体文件
- 做出修改:
- 新建/重写:
write_file
- 小范围精修:
edit_file
- 运行验证:
bash: python, npm test, make, pytest...
架构
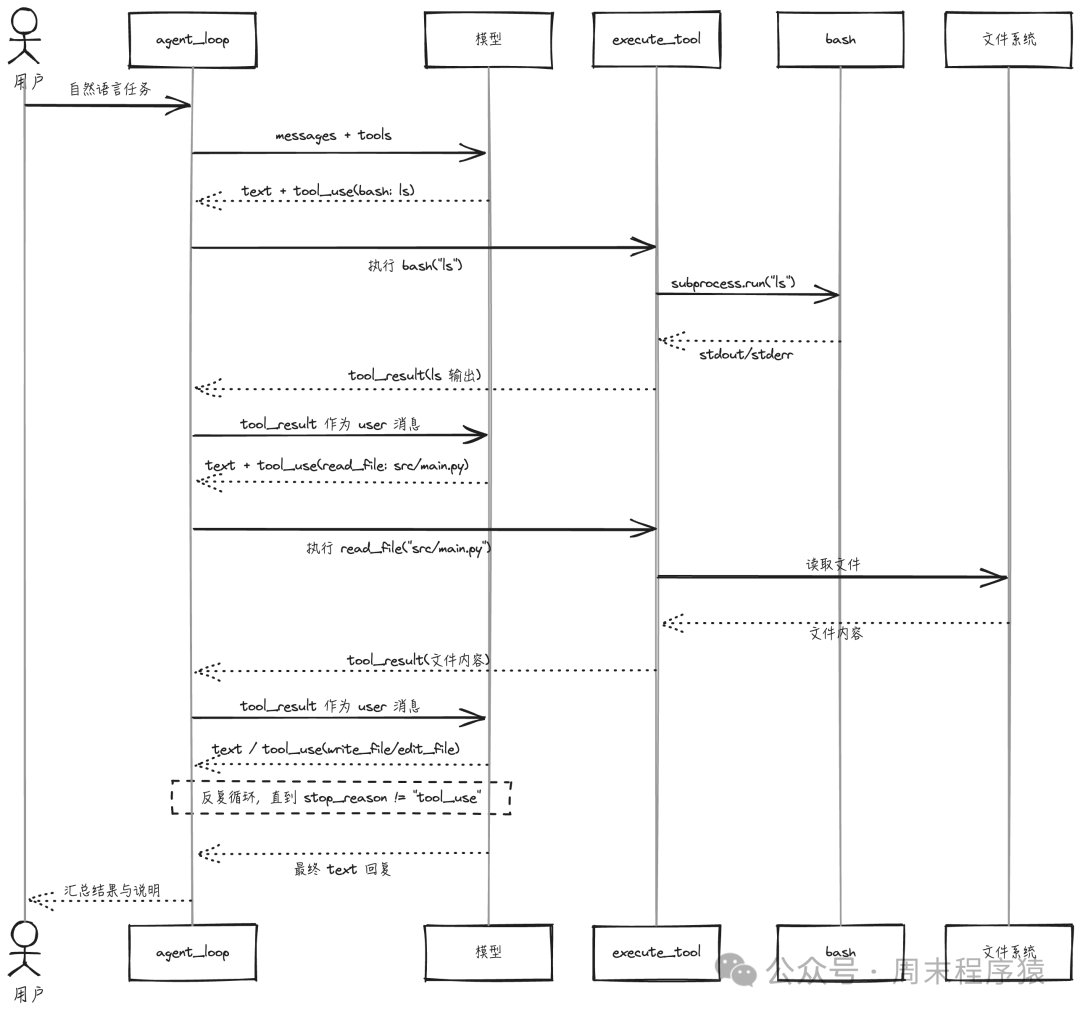
- 模型是决策者:何时调用、调用哪些工具、顺序及停止均由模型决定。
- 代码只做两件事:
- 提供一组带清晰 schema 的工具
- 驱动「模型 → 工具 → 结果 → 模型」循环
agent_loop 是 v1 的核心:
while True:
response = model(messages, tools)
if no tool_use:
return
results = execute(response.tool_calls)
messages.append(response)
messages.append(results)
模型控制循环
只要 stop_reason == "tool_use",说明模型仍在“思考 + 操作”;一旦不再返回此状态,即认为任务完成。
工具结果成为上下文
工具执行结果以 "user" 消息形式追加回对话,使模型能“看到”自身操作结果。
记忆自动累积
所有对话、工具调用、结果均保存在 messages 中,模型拥有完整任务上下文。
代码逻辑极薄
无需复杂状态机、计划器或自定义框架——这些均由模型通过自然语言引导“涌现”。
为什么这样设计?
1. 简洁性
- 无显式状态机
- 无 planner/parser 模块
- 无自定义框架
只有:messages、tools、while True。
2. 模型负责思考
- 哪个工具?
bash / read / write / edit?
- 什么顺序?先看文件?找入口?改代码?跑测试?
- 何时停止?任务是否已完成?
全部交由模型决策,而非硬编码流程。
3. 透明可观测
- 每次工具调用都显式出现在
messages 中 (tool_use + tool_result)
- 可持久化
messages,用于恢复过程或调试行为
4. 可扩展性强
添加新工具成本低:
- 实现 Python 函数(如
tool_http_request)
- 在
TOOLS 列表中增加 JSON schema 条目
- 在
execute_tool 中分发到对应函数
无需改动 Agent 循环本身。
完整代码
from pathlib import Path
import sys
import traceback
from llm_factory import LLMFactory, LLMChatAdapter
from util.mylog import logger
from utils import execute_base_tools, BASIC_TOOLS
llm = LLMFactory.create(
model_type="openai",
model_name="deepseek-v3.2",
temperature=0.0,
max_tokens=8192
)
client = LLMChatAdapter(llm)
WORKDIR = Path.cwd()
SYSTEM = f"""你是一个位于 {WORKDIR} 的编码代理,系统为 {sys.platform}。
## 执行流程
简要思考 -> 使用工具(使用 TOOLS) -> 报告结果。
## 规则
- 优先使用工具而不是文字描述。先行动,不要只是解释。
- 永远不要臆造文件路径。如果不确定,先使用 bash ls/find 确认。
- 做最小的修改。不要过度设计。
- 完成后,总结变更内容。
## 要求:
- 循环尽量简单,不要复杂。
"""
def execute_tool(name: str, args: dict) -> str:
result = execute_base_tools(name, args)
if result is not None:
return result
return f"Unknown tool: {name}"
def agent_loop(prompt, history=None, max_steps=10) -> list:
if history is None:
history = []
has_system = any(msg.get("role") == "system" for msg in history)
if not has_system:
history.insert(0, {"role": "system", "content": SYSTEM})
step = 0
while step < max_steps:
step += 1
response = client.chat_with_tools(
prompt=prompt,
messages=history,
tools=BASIC_TOOLS,
)
assistant_text = []
tool_calls = []
for block in response.content:
if getattr(block, "type", "") == "text":
assistant_text.append(block.text)
elif getattr(block, "type", "") == "tool_use":
tool_calls.append(block)
full_text = "\n".join(assistant_text)
if not tool_calls:
history.append({"role": "assistant", "content": full_text})
logger.info(f"第 {step} 步结束,无工具调用")
return history
results = []
for tc in tool_calls:
logger.info(f"\n> [使用工具] {tc.name} 第 {step} 步调用工具: {tc.input}")
output = execute_tool(tc.name, tc.input)
preview = output[:200] + "..." if len(output) > 200 else output
logger.info(f" [使用工具] {tc.name}, 输入: {tc.input}, 返回: {preview}")
results.append(f"工具 {tc.name}, 输入: {tc.input}, 返回: {output}")
history.append({"role": "assistant", "content": full_text})
combined_output = "\n".join(results)
history.append({"role": "user", "content": f"执行结果:\n{combined_output}\n\n请继续处理"})
logger.info(f"第 {step} 步达到最大执行步数限制,停止执行。")
def main():
logger.info(f"Mini Claude Code v1 - {WORKDIR}")
logger.info("Type 'exit' to quit.\n")
history = []
while True:
try:
user_input = input("You: ").strip()
except (EOFError, KeyboardInterrupt):
break
if not user_input or user_input.lower() in ("exit", "quit", "q"):
break
history.append({"role": "user", "content": user_input})
try:
agent_loop('', history, max_steps=10)
except Exception as e:
logger.error(f"Error: {e}")
traceback.print_exc()
if __name__ == "__main__":
main()
执行完整流程
输入: 统计当前目录下的代码行数,输出到 html 中
输出:
(base) linkxzhou@LINKXZHOU-MC1 miniagent % python3.11 v1_basic.py
...
You: 统计当前目录下的代码行数,输出到 html 中
...
> [使用工具] bash 第 5 步调用: {'command': 'wc -l ./v3_subagent.py ...'}
...
> [使用工具] write_file 第 6 步调用: {'path': 'code_stats.html', 'content': '<!DOCTYPE html>...'}, 返回: Wrote 1569 bytes to code_stats.html
...
最终HTML报告展示如下:
v2: 结构化规划与 Todo
v1 已能正常工作,但在复杂任务上易“失去方向”:
- 在不同子任务间来回跳转
- 难记住已做/未做的事
- 难向用户呈现清晰进度
v2 引入 Todo 工具(少量状态管理+提示逻辑),实现 “计划(使用 TodoWrite)→ 行动(使用 TOOLS)”。
在 v1 基础上新增 TodoManager 和 TodoWrite 工具。
TodoManager:带约束的任务列表
class TodoManager:
"""
管理具有强制约束的结构化任务列表。
关键设计决策:
--------------------
1. 最多 20 项:防止模型创建无尽的列表
2. 一个进行中:强制专注 - 一次只能做一件事
3. 必填字段:每个项目需要 content, status 和 activeForm
activeForm 字段值得解释:
- 它是正在发生的事情的现在时形式
- 当 status 为 "in_progress" 时显示
- 示例:content="Add tests", activeForm="Adding unit tests..."
这提供了代理正在做什么的实时可见性。
"""
def __init__(self):
self.items = []
def update(self, items: list) -> str:
"""
验证并更新任务列表。
模型每次发送一个完整的列表。我们验证它,
存储它,并返回一个模型将看到的渲染视图。
验证规则:
- 每个项目必须有:content, status, activeForm
- Status 必须是:pending | in_progress | completed
- 一次只能有 ONE 个项目处于 in_progress 状态
- 最多允许 20 个项目
Returns:
任务列表的渲染文本视图
"""
validated = []
in_progress_count = 0
for i, item in enumerate(items):
content = str(item.get("content", "")).strip()
status = str(item.get("status", "pending")).lower()
active_form = str(item.get("activeForm", "")).strip()
if not content:
raise ValueError(f"Item {i}: content required")
if status not in ("pending", "in_progress", "completed"):
raise ValueError(f"Item {i}: invalid status '{status}'")
if not active_form:
raise ValueError(f"Item {i}: activeForm required")
if status == "in_progress":
in_progress_count += 1
validated.append({
"content": content,
"status": status,
"activeForm": active_form
})
if len(validated) > 20:
raise ValueError("Max 20 todos allowed")
if in_progress_count > 1:
raise ValueError("Only one task can be in_progress at a time")
self.items = validated
return self.render()
def render(self) -> str:
"""
将任务列表渲染为人类可读的文本。
格式:
[x] 已完成任务
[>] 进行中任务 <- 正在做某事...
[ ] 待办任务
(2/3 completed)
这个渲染后的文本是模型作为工具结果看到的内容。
然后它可以根据当前状态更新列表。
"""
if not self.items:
return "No todos."
lines = []
for item in self.items:
if item["status"] == "completed":
lines.append(f"[x] {item['content']}")
elif item["status"] == "in_progress":
lines.append(f"[>] {item['content']} <- {item['activeForm']}")
else:
lines.append(f"[ ] {item['content']}")
completed = sum(1 for t in self.items if t["status"] == "completed")
lines.append(f"\n({completed}/{len(self.items)} completed)")
return "\n".join(lines)
设计约束的意义
| 规则 |
原因 |
| 最多 20 条 |
防止模型把 todo 当成无限备忘录 |
必须有 content |
保证每条任务有明确描述 |
必须有 status |
让任务进度可追踪 |
必须有 activeForm |
描述“当前正在做的具体动作” |
只能一个 in_progress |
强制模型一次只专注一个任务 |
| 内容不能重复 |
防止模型无意义地复制条目 |
这些约束既限制了行为空间,又增强了可控性和可观察性。
Todo 工具的执行与反馈
todo_manager = TodoManager()
def execute_tool(name, args):
if name == "TodoWrite":
try:
todo_manager.update(args["items"])
return todo_manager.render()
except Exception as e:
return f"[TodoWrite error] {e}"
# 其他工具: bash / read_file / write_file / edit_file...
...
示例调用
输入:
{
"items": [
{
"content": "重构认证模块",
"status": "completed",
"activeForm": "重构已完成"
},
{
"content": "添加单元测试",
"status": "in_progress",
"activeForm": "正在为认证模块编写单元测试"
},
{
"content": "更新文档",
"status": "pending",
"activeForm": "准备在完成测试后更新文档"
}
]
}
返回(作为 tool_result):
[x] 重构认证模块 (重构已完成)
[>] 添加单元测试 (正在为认证模块编写单元测试)
[ ] 更新文档 (准备在完成测试后更新文档)
(1/3 已完成)
模型下次调用时即可“看到自己刚刚整理的计划”,并据此决定下一步。
系统提示词:软约束鼓励使用 Todo
INITIAL_REMINDER = "<reminder>对于多步骤任务,请使用 TodoWrite 工具创建和维护一个清晰的 todo 列表。</reminder>"
NAG_REMINDER = "<reminder>已经超过 10 轮未更新 todo,请检查是否需要补充或更新 TodoWrite。</reminder>"
- 在合适位置注入额外文本(通常作为 system 或 user 内容),提醒模型使用 Todo 工具。
- 这些提醒不是独立工具调用,也不需模型回复,仅为“背景提示”。
效果
- 模型被“温柔地提醒”:对于多步骤任务,Todo 是推荐做法。
- 若长期不更新 Todo,会收到 “该更新计划了” 的提示。
架构
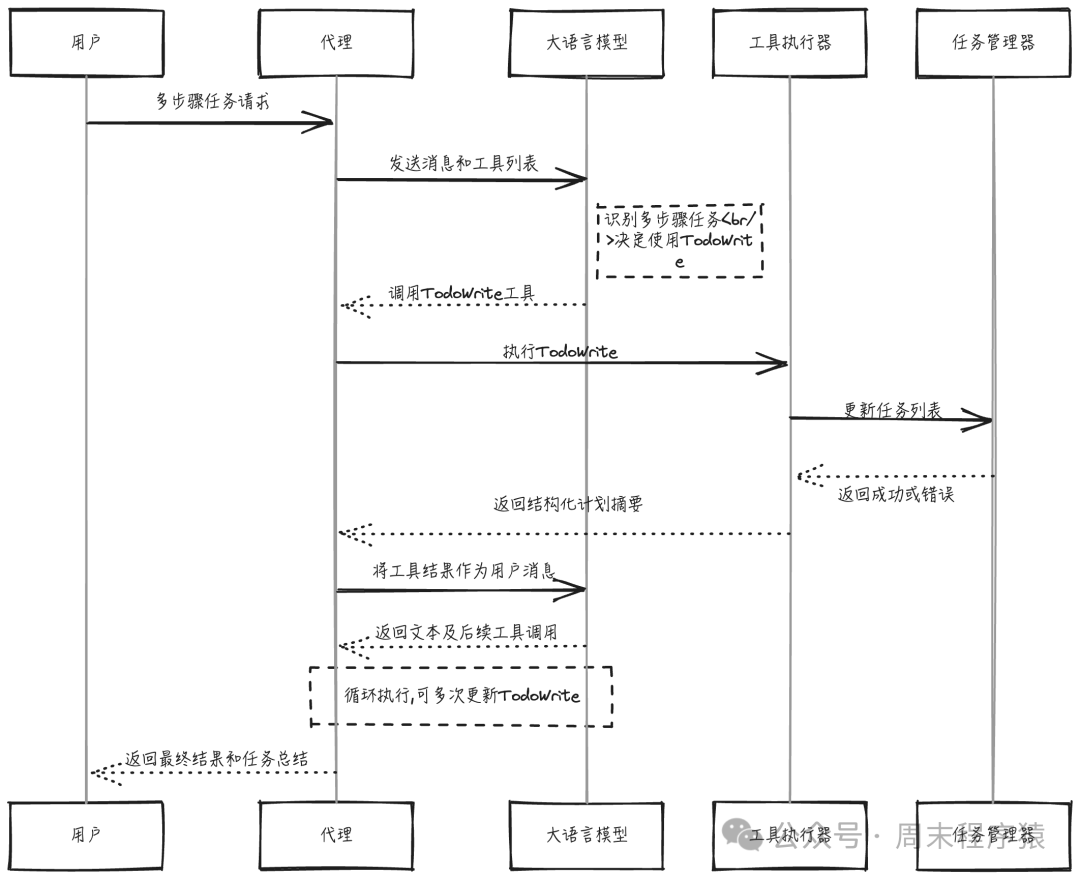
显式规划让 Agent 更可靠,而 Todo 是实现显式规划的最小结构单元。
结构既是约束,也是能力放大的脚手架。
- 约束:
- 限制条目数、状态字段、唯一进行中
- 要求完整列表,而非局部 patch
- 赋能:
- 提供可见的计划(用户、模型都能看到)
- 提供进度追踪和当前焦点的清晰标记
- 为后续总结、回顾提供结构
类似模式普遍存在:
max_tokens 约束 → 赋能响应可控与流式体验- 工具 JSON Schema 约束 → 赋能结构化调用和验证
- Todo 约束 → 赋能复杂任务的可靠完成和可解释性
好的约束不是阻碍,而是让能力更稳定、更可控的支架。
完整代码
v2 是在 v1 基础上的增量扩展,不改变核心 Agent 循环。
import traceback
import sys
from pathlib import Path
from llm_factory import LLMFactory, LLMChatAdapter
from util.mylog import logger
from utils import execute_base_tools, TodoManager, BASE_TOOLS
llm = LLMFactory.create(
model_type="openai",
model_name="deepseek-v3.2",
temperature=0.0,
max_tokens=8192
)
client = LLMChatAdapter(llm)
WORKDIR = Path.cwd()
TODO = TodoManager()
SYSTEM = f"""你是一个位于 {WORKDIR} 的编码代理,系统为 {sys.platform}。
## 执行流程
计划(使用 TodoWrite) -> 使用工具行动(使用 TOOLS) -> 更新任务列表 -> 报告。
## 规则
- 使用 TodoWrite 跟踪多步骤任务
- 开始前将任务标记为 in_progress,完成后标记为 completed
- 优先使用工具而不是文字描述。先行动,不要只是解释。
- 完成后,总结变更内容。"""
INITIAL_REMINDER = "<reminder>使用 TodoWrite 处理多步骤任务。</reminder>"
NAG_REMINDER = "<reminder>超过 10 轮未更新任务列表。请更新任务列表。</reminder>"
max_steps = 20
rounds_without_todo = 0
def run_todo(items: list) -> str:
try:
return TODO.update(items)
except Exception as e:
return f"Error: {e}"
def execute_tool(name: str, args: dict) -> str:
"""Dispatch tool call to implementation."""
result = execute_base_tools(name, args)
if result is not None:
return result
if name == "TodoWrite":
return run_todo(args["items"])
return f"Unknown tool: {name}"
def agent_loop(prompt: str, history: list = [], max_steps: int = max_steps) -> list:
global rounds_without_todo
has_system = any(msg.get("role") == "system" for msg in history)
if not has_system:
history.insert(0, {"role": "system", "content": SYSTEM})
step = 0
while step < max_steps:
step += 1
response = client.chat_with_tools(
prompt=prompt,
messages=history,
tools=BASE_TOOLS,
)
assistant_text = []
tool_calls = []
for block in response.content:
if hasattr(block, "text"):
assistant_text.append(block.text)
logger.info(block.text)
if block.type == "tool_use":
tool_calls.append(block)
full_text = "\n".join(assistant_text)
if not tool_calls:
history.append({"role": "assistant", "content": full_text})
logger.info(f"第 {step} 步结束,无工具调用")
return history
results = []
used_todo = False
for tc in tool_calls:
logger.info(f"\n> [使用工具] {tc.name} 第 {step} 步调用: {tc.input}")
output = execute_tool(tc.name, tc.input)
preview = output[:200] + "..." if len(output) > 200 else output
logger.info(f" [使用工具] {tc.name}, 输入: {tc.input}, 返回: {preview}")
results.append(f"工具 {tc.name}, 输入: {tc.input}, 返回: {output}")
if tc.name == "TodoWrite":
used_todo = True
if used_todo:
rounds_without_todo = 0
else:
rounds_without_todo += 1
history.append({"role": "assistant", "content": full_text})
combined_output = "\n".join(results)
history.append({"role": "user", "content": f"执行结果:\n{combined_output}\n\n请继续处理"})
def main():
global rounds_without_todo
logger.info(f"Mini Claude Code v2 (with Todos) - {WORKDIR}")
logger.info("Type 'exit' to quit.\n")
history = []
first_message = True
while True:
try:
user_input = input("You: ").strip()
except (EOFError, KeyboardInterrupt):
break
if not user_input or user_input.lower() in ("exit", "quit", "q"):
break
content = []
if first_message:
content.append(INITIAL_REMINDER)
first_message = False
elif rounds_without_todo > max_steps:
content.append(NAG_REMINDER)
content.append(f"输入:{user_input}")
history.append({"role": "user", "content": "\n".join(content)})
try:
agent_loop('', history, max_steps=max_steps)
except Exception as e:
logger.error(f"Error: {e}")
traceback.print_exc()
if __name__ == "__main__":
main()
执行完整流程
输入: 统计当前目录下的代码行数和功能,输出到 html 中
输出:
(base) linkxzhou@LINKXZHOU-MC1 miniagent % python3.11 v2_todo.py
...
You: 统计当前目录下的代码行数和功能,输出到 html 中
...
> [使用工具] TodoWrite 第 1 步调用: {'items': [...]}
...
> [使用工具] write_file 第 8 步调用: {'path': 'code_statistics_report.html', 'content': '<!DOCTYPE html>...'}, 返回: Wrote 10388 bytes to code_statistics_report.html
...
通过 TODO 拆分任务,最终任务结果输出展示如下:

v3: 子代理
v2 已有 Todo 规划,但对于更大任务(如:“先探索代码库,再重构认证,然后补测试和文档”),单一 Agent 易出现上下文污染与角色混乱:
- 探索阶段读了 20 个文件,大量细节塞进上下文
- 重构时在同一上下文中继续对话
- 模型难在“海量历史”中保持聚焦和角色清晰
v3 添加新工具:SubTask,可生成带隔离上下文的“子代理”,每个专注完成一个子任务。
问题:单 Agent 的上下文污染
在 v2 中,大型任务的历史会变成:
主 Agent 历史:
[探索中...] cat src/auth/login.py -> 500 行
[探索中...] cat src/auth/session.py -> 300 行
[探索中...] cat src/models/user.py -> 400 行
...
(15+ 个文件内容)
[现在重构...] "等等,login.py 里具体是什么来着?"
模型需在“聊天记录 + N 个文件内容 + Todo 列表”的混合上下文中工作,易:
- 失焦:在旧文件和新任务间跳跃
- 浪费上下文:很多信息是阶段性的
- 难区分角色:探索 vs 规划 vs 实现
解决方案:把不同阶段委托给不同的子代理。
思路:用子代理隔离阶段
将“探索 → 规划 → 实现”拆为三个子代理,各自在干净上下文中工作:
主 Agent 历史:
[Task: explore] 探索代码库
-> 子代理( explore ):读取 20 个文件
-> 返回摘要: "认证在 src/auth/,数据库在 src/models/..."
[Task: plan] 设计 JWT 迁移方案
-> 子代理( plan ):分析结构,输出步骤
-> 返回总结: "1. 添加 jwt 库 2. 创建 token 工具..."
[Task: code] 实现 JWT 重构
-> 子代理( code ):编辑文件、运行测试
-> 返回结果: "创建 jwt_utils.py,修改 login.py ..."
[主 Agent] 汇总更改并向用户汇报
对主 Agent 来说:
- 存的是子代理摘要,而非全部细节
- 每个子代理内部使用和 v1/v2 相同的工具循环,但上下文隔离
代理类型注册表:角色与权限分离
通过注册表定义不同类型代理:
AGENT_TYPES = {
"explore": {
"description": "只读,用于搜索和分析代码结构",
"tools": ["bash", "read_file"],
"prompt": "你是一个探索子代理,只负责搜索和分析项目代码。不要修改任何文件。返回简洁、结构化的摘要。"
},
"code": {
"description": "完整读写能力,用于实现变更",
"tools": "*",
"prompt": "你是一个代码实现子代理,负责根据要求修改代码并跑测试。要高效、谨慎,做完后总结改动。"
},
"plan": {
"description": "规划与分析,不做修改",
"tools": ["bash", "read_file"],
"prompt": "你是一个规划子代理,负责分析现有代码并输出编号计划。不要编辑文件,只提出可执行方案。"
}
}
明确区分:
- explore:只看不写
- plan:只看不写,专注输出计划
- code:可改动代码并跑测试
模型通过 Task 工具选择 agent_type,决定派出何种“角色”的子代理。
Task: 定义 schema + 控制能力边界
定义 schema
TASK_TOOL = {
"name": "Task",
"description": "创建一个聚焦的子任务,并用指定类型的子代理在隔离上下文中执行它。",
"input_schema": {
"type": "object",
"properties": {
"description": {
"type": "string",
"description": "子任务的短名称(3-5 个词),用来在日志/进度条中显示。"
},
"prompt": {
"type": "string",
"description": "详细的自然语言指令,子代理看到的用户任务描述。"
},
"agent_type": {
"type": "string",
"enum": ["explore", "code", "plan"],
"description": "子代理的类型(决定工具与系统提示)。"
}
},
"required": ["description", "prompt", "agent_type"],
},
}
主 Agent 调用 Task 示例:
{
"description": "探索认证代码",
"prompt": "找到所有与用户登录和认证相关的文件,阅读后给出结构化摘要。",
"agent_type": "explore"
}
Task 工具启动子代理,跑完工具循环后返回一段总结文本给主 Agent。
控制每种子代理的能力边界
def get_tools_for_agent(agent_type):
allowed = AGENT_TYPES[agent_type]["tools"]
if allowed == "*":
return [t for t in BASE_TOOLS if t["name"] != "Task"]
else:
return [t for t in BASE_TOOLS if t["name"] in allowed and t["name"] != "Task"]
默认策略:
explore:只读 → bash + read_fileplan:只读 → bash + read_filecode:读写/执行 → bash + read_file + write_file + edit_file + TodoWrite(不含 Task)
对比 v2 与 v3
| 功能 |
v2 |
v3 |
| 上下文形态 |
单一上下文,不断增长 |
主 Agent + 多个子代理,各自隔离 |
| 探索行为 |
直接在主 Agent 中执行 |
通过 explore 子代理执行并总结 |
| 规划行为 |
使用 Todo + 主 Agent 自己规划 |
可选 plan 子代理生成更结构化计划 |
| 代码修改 |
主 Agent 直接改 |
code 子代理在专用上下文中改 |
| 并行潜力 |
理论可以,但逻辑复杂 |
子代理天然支持并行(演示版未实现并发调度) |
核心循环仍是:
while True:
resp = model(messages, tools)
if resp.stop_reason != "tool_use":
return resp
results = execute(resp.tool_calls)
messages.append(resp)
messages.append(results)
v3 只是让这个循环在多个上下文中同时存在(主 Agent + 子代理),并通过 Task 工具协调。
模式:分而治之 + 上下文隔离
复杂任务
└─ 主 Agent(协调者)
├─ 子代理 A (explore) -> 返回「结构摘要」
├─ 子代理 B (plan) -> 返回「任务计划」
└─ 子代理 C (code) -> 返回「实现结果」
所有 Agent(主 + 子)内部结构相同:
- 有工具
- 有系统提示词
- 有
while True 工具循环
只是上下文不同、工具集不同、角色Prompt不同。
详细代码
import sys
import time
import traceback
from pathlib import Path
from llm_factory import LLMFactory, LLMChatAdapter
from util.mylog import logger
from utils import execute_base_tools, TodoManager, get_agent_descriptions, BASE_TOOLS, SUBAGENT_ALL_TOOLS, AGENT_TYPES
llm = LLMFactory.create(
model_type="openai",
model_name="deepseek-v3.2",
temperature=0.0,
max_tokens=8192
)
client = LLMChatAdapter(llm)
WORKDIR = Path.cwd()
TODO = TodoManager()
SYSTEM = f"""你是一个位于 {WORKDIR} 的编码代理,系统为 {sys.platform}。
## 执行流程
计划(使用 TodoWrite)-> 使用工具行动 -> 执行子代理工具 -> 报告。
你可以为复杂的子任务生成子代理:
{get_agent_descriptions()}
## 规则
- 对需要集中探索或实现的子任务使用 Task 工具
- 使用 TodoWrite 跟踪多步骤工作
- 优先使用工具而不是文字描述。先行动,不要只是解释。
- 完成后,总结变更内容。"""
max_steps = 20
def get_tools_for_agent(agent_type: str) -> list:
allowed = AGENT_TYPES.get(agent_type, {}).get("tools", "*")
if allowed == "*":
return BASE_TOOLS
return [t for t in BASE_TOOLS if t["name"] in allowed]
def run_task(description: str, prompt: str, agent_type: str, max_steps: int = max_steps) -> str:
"""
在隔离的上下文中执行子代理任务。
这是子代理机制的核心:
1. 创建隔离的消息历史(关键:没有父级上下文!)
2. 使用特定于代理的系统提示词
3. 根据代理类型过滤可用工具
4. 运行与主代理相同的查询循环
5. 仅返回最终文本(不是中间细节)
父代理只看到总结,保持其上下文干净。
进度显示:
----------------
运行时,我们会显示:
[explore] find auth files ... 5 tools, 3.2s
这在不污染主对话的情况下提供了可见性。
"""
if agent_type not in AGENT_TYPES:
return f"Error: Unknown agent type '{agent_type}'"
config = AGENT_TYPES[agent_type]
sub_system = f"""你是一个位于 {WORKDIR} 的 {agent_type} 子代理,系统为 {sys.platform}。
{config["prompt"]}
完成任务并返回清晰、简洁的总结。"""
sub_tools = get_tools_for_agent(agent_type)
sub_messages = [{"role": "system", "content": sub_system}, {"role": "user", "content": prompt}]
logger.info(f" [子代理][{agent_type}] {description}")
start = time.time()
tool_count = 0
step = 0
while step < max_steps:
step += 1
response = client.chat_with_tools(
prompt='',
messages=sub_messages,
tools=sub_tools,
)
assistant_text = []
tool_calls = []
for block in response.content:
if hasattr(block, "text"):
assistant_text.append(block.text)
logger.info(f" [子代理][{agent_type}] {block.text}")
if block.type == "tool_use":
tool_calls.append(block)
full_text = "\n".join(assistant_text)
if not tool_calls:
logger.info(f" [子代理][{agent_type}] 第 {step} 步结束,无工具调用")
break
results = []
for tc in tool_calls:
tool_count += 1
output = execute_tool(tc.name, tc.input)
results.append(f" [子代理][{agent_type}] 工具 {tc.name}, 输入: {tc.input}, 返回: {output}")
elapsed = time.time() - start
sys.stdout.write(
f"\r [子代理][{agent_type}] {description} ... {tool_count} tools, {elapsed:.1f}s\n"
)
sys.stdout.flush()
sub_messages.append({"role": "assistant", "content": full_text})
combined_output = "\n".join(results)
sub_messages.append({"role": "user", "content": f"子代理执行结果:\n{combined_output}\n\n请继续处理"})
elapsed = time.time() - start
sys.stdout.write(
f"\r [子代理][{agent_type}] {description} - done ({tool_count} tools, {elapsed:.1f}s)\n"
)
for block in response.content:
if hasattr(block, "text"):
return full_text
return "(subagent returned no text)"
def execute_tool(name: str, args: dict) -> str:
result = execute_base_tools(name, args)
if result is not None:
return result
if name == "TodoWrite":
try:
return TODO.update(args["items"])
except Exception as e:
return f"Error: {e}"
if name == "Task":
return run_task(args["description"], args["prompt"], args["agent_type"])
return f"Unknown tool: {name}"
def agent_loop(prompt: str, history: list, max_steps: int = max_steps) -> list:
has_system = any(msg.get("role") == "system" for msg in history)
if not has_system:
history.insert(0, {"role": "system", "content": SYSTEM})
step = 0
while step < max_steps:
step += 1
response = client.chat_with_tools(
prompt=prompt,
messages=history,
tools=SUBAGENT_ALL_TOOLS,
)
assistant_text = []
tool_calls = []
for block in response.content:
if hasattr(block, "text"):
assistant_text.append(block.text)
logger.info(block.text)
if block.type == "tool_use":
tool_calls.append(block)
full_text = "\n".join(assistant_text)
if not tool_calls:
history.append({"role": "assistant", "content": full_text})
logger.info(f"第 {step} 步结束,无工具调用")
return history
results = []
for tc in tool_calls:
if tc.name == "Task":
logger.info(f"\n> [使用工具] Task 第 {step} 步调用: {tc.input.get('description', 'subtask')}")
else:
logger.info(f"\n> [使用工具] {tc.name} 第 {step} 步调用: {tc.input}")
logger.info(f" 输入: {tc.input}")
output = execute_tool(tc.name, tc.input)
if tc.name != "Task":
preview = output[:200] + "..." if len(output) > 200 else output
logger.info(f" [使用工具] {tc.name}, 返回: {preview}")
results.append(f"工具 {tc.name}, 输入: {tc.input}, 返回: {output}")
history.append({"role": "assistant", "content": full_text})
combined_output = "\n".join(results)
history.append({"role": "user", "content": f"执行结果:\n{combined_output}\n\n请继续处理"})
def main():
logger.info(f"Mini Claude Code v3 (with Subagents) - {WORKDIR}")
logger.info(f"Agent types: {', '.join(AGENT_TYPES.keys())}")
logger.info("Type 'exit' to quit.\n")
history = []
while True:
try:
user_input = input("You: ").strip()
except (EOFError, KeyboardInterrupt):
break
if not user_input or user_input.lower() in ("exit", "quit", "q"):
break
history.append({"role": "user", "content": user_input})
try:
agent_loop('', history, max_steps=max_steps)
except Exception as e:
logger.error(f"Error: {e}")
traceback.print_exc()
if __name__ == "__main__":
main()
执行完整流程
输入: 统计当前目录下的代码行数和功能,详细分析每个文件的执行流程,包括调用的函数和类,输出到 html 中
输出:
(base) linkxzhou@LINKXZHOU-MC1 miniagent % python3.11 v3_subagent.py
...
You: 统计当前目录下的代码行数和功能,详细分析每个文件的执行流程...
...
> [使用工具] Task 第 3 步调用: {'description': '探索认证代码', 'prompt': '...', 'agent_type': 'explore'}
...
> [使用工具] write_file 第 10 步调用: {'path': './code_analysis_report.html', 'content': '<!DOCTYPE html>...'}, 返回: Wrote 16588 bytes to ./code_analysis_report.html
...
每个子代理只执行自己的任务,最终将结果汇总展示如下:
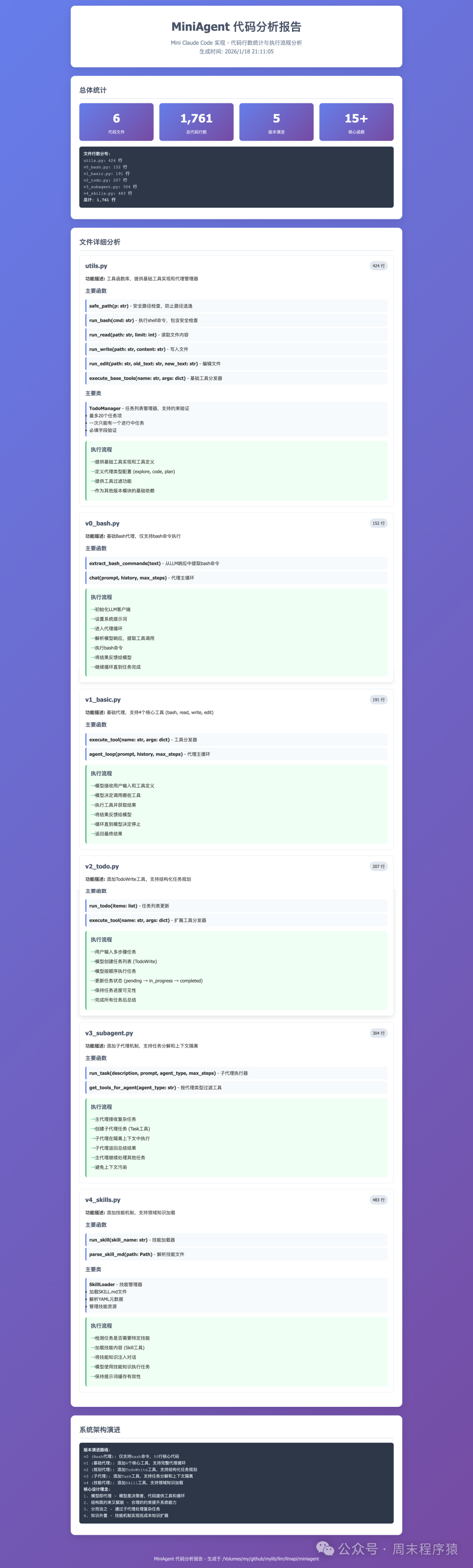
v4: Skills
Skills 是知识包,不是工具本身,体现深刻范式转变:知识外化 (Knowledge Externalization)。
传统方式:知识内化于参数
传统 AI 系统中,知识封装在模型参数里:
让模型学会新技能需:
- 收集训练数据
- 租用集群
- 运行微调流程(LoRA / 全量微调)
- 部署新模型版本
知识锁死在权重矩阵中,对用户不可见、不可编辑、不可复用。
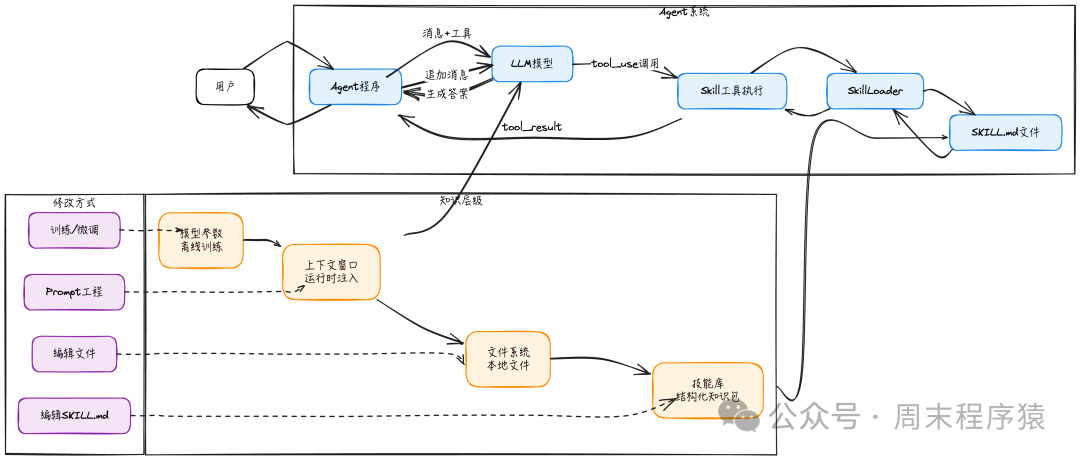
新范式:知识外化为文档
有了“代码执行 + 文件系统”范式后,知识可逐层外化:
┌─────────────────────────────────────────────────────────────────┐
│ 知识存储层级 │
│ │
│ Model Parameters → Context Window → File System → Skill Library│
│ (内化) (运行时) (持久化) (结构化) │
│ │
│ ←───────── 训练修改 ──────────→ ←──── 自然语言/文本编辑 ────→ │
│ 需要集群、数据、专业知识 任何人都能参与 │
└─────────────────────────────────────────────────────────────────┘
关键变化:
- 过去:修改行为 = 修改参数 → 需训练 → 需 GPU 集群 + 数据 + ML 技能
- 现在:修改行为 = 修改 SKILL.md → 就像写文档 → 任何人都可以做
这类似于给 base model 外挂“可热插拔的知识模块”,无需改动模型参数。
为什么 Skills 工程范式重要
- 民主化:无需 ML 专业知识,“定制模型行为”只需写 Markdown 文档。
- 透明性:知识存在于人类可读的 SKILL.md 中,可审计、可理解、可讨论。
- 复用性:一个 Skill 编写一次,可在任何兼容 Agent 框架中加载使用。
- 版本控制:用 Git 管理 Skill 变更:支持协作、Code Review 和回滚。
- 在线学习:模型在更大上下文窗口中即时「学习」技能内容,无需离线训练。
Skills 正处在一个“可工程化的范式”中:
- 持久化存储(文件系统)
- 按需加载(只在需要时注入)
- 人类可编辑(Markdown 文档)
v3 解决结构与上下文,v4 解决“知识从哪来”
v3 引入子代理机制,让 Agent 可:
- 分阶段处理任务(explore / plan / code)
- 每个阶段在各自上下文中运行
但更深的问题是:模型怎么知道「做这件事的正确方法」?
这些不是“工具”,而是领域知识 / 专业技能。Tools 决定模型“能做什么”,Skills 决定模型“知道怎么做”。
工具 vs 技能
| 概念 |
定义 |
例子 |
| Tool |
模型能做什么 |
bash, read_file, http 等 |
| Skill |
模型知道怎么做 |
PDF 处理、MCP 构建、代码审查 |
- Tool 是动作层面的能力(能执行什么操作)
- Skill 是策略/知识层面的积累(做这件事的正确方法、最佳实践)
控制上下文
为控制开销,Skill 分三层:
Layer 1: 元数据 (始终加载) ~100 tokens/skill
└─ name + description
Layer 2: SKILL.md 正文 (触发时) ~2k tokens
└─ 详细指南、分步骤说明、示例等
Layer 3: 资源文件 (必要时再查) 无硬限制
└─ scripts/, references/, assets/
做到:
- 平时只加载轻量“技能列表/描述”
- 当模型决定使用某个 Skill 时,再加载 SKILL.md 正文
- 若正文引用脚本/示例,可按需再读取
Skill 目录结构与 SKILL.md 标准
Skill 目录结构
skills/
├── pdf/
│ └── SKILL.md # 必需
├── mcp-builder/
│ ├── SKILL.md
│ └── references/ # 可选
└── code-review/
├── SKILL.md
└── scripts/ # 可选
SKILL.md 采用“YAML 前置 + Markdown 正文”格式:
---
name: pdf
description: 处理 PDF 文件。用于读取、创建或合并 PDF。
---
**Skill 工具定义**
```python
SKILL_TOOL = {
"name": "Skill",
"description": "加载一个技能的文档,以获得领域知识和最佳实践。",
"input_schema": {
"type": "object",
"properties": {
"skill": {
"type": "string",
"description": "要加载的 skill 名称,例如 'pdf'、'mcp-builder'。"
}
},
"required": ["skill"],
},
}
### Skill 工具执行逻辑:缓存友好式注入
关键点:**Skill 内容作为 tool_result 追加到 messages 末尾**,而非修改 system prompt 或历史前缀。
```python
def run_skill(skill_name: str) -> str:
try:
content = skill_loader.get_skill_content(skill_name)
except KeyError:
return f"[Skill error] Skill '{skill_name}' not found."
return f"""<skill-loaded name="{skill_name}">
{content}
</skill-loaded>
Now follow the instructions and best practices described in this skill."""
在统一的 execute_tool 中:
def execute_tool(name, args):
if name == "Skill":
return run_skill(args["skill"])
# 其他工具...
在 agent_loop 中无需结构性变化,像处理其他工具一样处理 Skill 即可。
这样:
- Skill 内容出现在对话末尾的
tool_result 文本里
- 前缀(system + 之前 history)完全不变 → prompt cache 可以完全复用
- 下次请求时,只需对新增的 Skill 内容和新问题部分做计算
设计哲学:从「训练 AI」到「教育 AI」
知识被提升为一等公民资源。
传统观点把 Agent 看作“调用工具的模型”——模型负责决策,工具负责执行,但这隐含前提:模型已知“如何使用这些工具解决问题”。
Skills 机制把领域知识从模型参数中剥离:
- 过去:教模型新技能 → 收集数据 + 训练
- 现在:教模型新技能 → 写/编辑 SKILL.md 文档
这是从“训练 AI”到“教育 AI”的转变:
- 技术上:从参数微调 → 上下文注入
- 组织上:从 ML 团队独占 → 任何工程师/领域专家都能参与
- 工程上:从黑盒权重 → 白盒文档(可审计、可 review)
架构图
详细代码
import re
import sys
import time
import traceback
from pathlib import Path
from llm_factory import LLMFactory, LLMChatAdapter
from util.mylog import logger
from utils import execute_base_tools, TodoManager, AGENT_TYPES, get_agent_descriptions, SUBAGENT_ALL_TOOLS, BASE_TOOLS
llm = LLMFactory.create(
model_type="openai",
model_name="deepseek-v3.2",
temperature=0.0,
max_tokens=8192
)
client = LLMChatAdapter(llm)
WORKDIR = Path.cwd()
SKILLS_DIR = WORKDIR / "skills"
class SkillLoader:
"""
从 SKILL.md 文件加载和管理技能。
技能是一个包含以下内容的文件夹:
- SKILL.md (必须): YAML frontmatter + markdown 说明
- scripts/ (可选): 模型可以运行的辅助脚本
- references/ (可选): 额外的文档
- assets/ (可选): 模板,输出文件
"""
def __init__(self, skills_dir: Path):
self.skills_dir = skills_dir
self.skills = {}
self.load_skills()
def parse_skill_md(self, path: Path) -> dict:
content = path.read_text()
match = re.match(r"^---\s*\n(.*?)\n---\s*\n(.*)$", content, re.DOTALL)
if not match:
return None
frontmatter, body = match.groups()
metadata = {}
for line in frontmatter.strip().split("\n"):
if ":" in line:
key, value = line.split(":", 1)
metadata[key.strip()] = value.strip().strip("\"'")
if "name" not in metadata or "description" not in metadata:
return None
return {
"name": metadata["name"],
"description": metadata["description"],
"body": body.strip(),
"path": path,
"dir": path.parent,
}
def load_skills(self):
if not self.skills_dir.exists():
return
for skill_dir in self.skills_dir.iterdir():
if not skill_dir.is_dir():
continue
skill_md = skill_dir / "SKILL.md"
if not skill_md.exists():
continue
skill = self.parse_skill_md(skill_md)
if skill:
self.skills[skill["name"]] = skill
def get_descriptions(self) -> str:
if not self.skills:
return "(no skills available)"
return "\n".join(
f"- {name}: {skill['description']}"
for name, skill in self.skills.items()
)
def get_skill_content(self, name: str) -> str:
if name not in self.skills:
return None
skill = self.skills[name]
content = f"# Skill: {skill['name']}\n\n{skill['body']}"
resources = []
for folder, label in [
("scripts", "Scripts"),
("references", "References"),
("assets", "Assets")
]:
folder_path = skill["dir"] / folder
if folder_path.exists():
files = list(folder_path.glob("*"))
if files:
resources.append(f"{label}: {', '.join(f.name for f in files)}")
if resources:
content += f"\n\n**Available resources in {skill['dir']}:**\n"
content += "\n".join(f"- {r}" for r in resources)
return content
def list_skills(self) -> list:
return list(self.skills.keys())
SKILLS = SkillLoader(SKILLS_DIR)
TODO = TodoManager()
SYSTEM = f"""你是一个位于 {WORKDIR} 的编码代理,系统为 {sys.platform}。
## 执行流程
计划(使用 TodoWrite) -> 使用工具行动 -> 报告。
**可用技能**(当任务匹配时使用 Skill 工具调用):
{SKILLS.get_descriptions()}
**可用子代理**(对于需要集中注意力的子任务,使用 Task 工具调用):
{get_agent_descriptions()}
规则:
- 当任务匹配技能描述时,**立即**使用 Skill 工具
- 对需要集中探索或实现的子任务使用 Task 工具
- 使用 TodoWrite 跟踪多步骤工作
- 优先使用工具而不是文字描述。先行动,不要只是解释。
- 完成后,总结变更内容。"""
SKILL_TOOL = {
"name": "Skill",
"description": f"""Load a skill to gain specialized knowledge for a task.
Available skills:
{SKILLS.get_descriptions()}
When to use:
- IMMEDIATELY when user task matches a skill description
- Before attempting domain-specific work (PDF, MCP, etc.)
The skill content will be injected into the conversation, giving you
detailed instructions and access to resources.""",
"input_schema": {
"type": "object",
"properties": {
"skill": {
"type": "string",
"description": "Name of the skill to load"
}
},
"required": ["skill"],
},
}
ALL_TOOLS = SUBAGENT_ALL_TOOLS + [SKILL_TOOL]
max_steps = 50
def get_tools_for_agent(agent_type: str) -> list:
allowed = AGENT_TYPES.get(agent_type, {}).get("tools", "*")
if allowed == "*":
return BASE_TOOLS
return [t for t in BASE_TOOLS if t["name"] in allowed]
def run_subagent_task(description: str, prompt: str, agent_type: str, max_steps: int = max_steps) -> str:
if agent_type not in AGENT_TYPES:
return f"Error: Unknown agent type '{agent_type}'"
config = AGENT_TYPES[agent_type]
sub_system = f"""你是一个位于 {WORKDIR} 的 {agent_type} 子代理,系统为 {sys.platform}。
{config["prompt"]}
完成任务并返回清晰、简洁的总结。"""
sub_tools = get_tools_for_agent(agent_type)
sub_messages = [{"role": "system", "content": sub_system}, {"role": "user", "content": prompt}]
logger.info(f" [子代理][{agent_type}] {description}")
start = time.time()
tool_count = 0
step = 0
while step < max_steps:
step += 1
response = client.chat_with_tools(
prompt='',
messages=sub_messages,
tools=sub_tools,
)
assistant_text = []
tool_calls = []
for block in response.content:
if hasattr(block, "text"):
assistant_text.append(block.text)
logger.info(f" [子代理][{agent_type}] {block.text}")
if block.type == "tool_use":
tool_calls.append(block)
full_text = "\n".join(assistant_text)
if not tool_calls:
logger.info(f" [子代理][{agent_type}] 第 {step} 步结束,无工具调用")
break
results = []
for tc in tool_calls:
tool_count += 1
output = execute_tool(tc.name, tc.input)
results.append(f" [子代理][{agent_type}] 工具 {tc.name}, 输入: {tc.input}, 返回: {output}")
elapsed = time.time() - start
sys.stdout.write(
f"\r [子代理][{agent_type}] {description} ... {tool_count} tools, {elapsed:.1f}s\n"
)
sys.stdout.flush()
sub_messages.append({"role": "assistant", "content": full_text})
combined_output = "\n".join(results)
sub_messages.append({"role": "user", "content": f"子代理执行结果:\n{combined_output}\n\n请继续处理"})
elapsed = time.time() - start
sys.stdout.write(
f"\r [子代理][{agent_type}] {description} - done ({tool_count} tools, {elapsed:.1f}s)\n"
)
for block in response.content:
if hasattr(block, "text"):
return full_text
return "(subagent returned no text)"
def run_skill(skill_name: str) -> str:
"""
加载一项技能并将其注入到对话中。
这是关键机制:
1. 获取技能内容(SKILL.md 正文 + 资源提示)
2. 将其包装在 <skill-loaded> 标签中返回
3. 模型作为 tool_result(用户消息)接收此内容
4. 模型现在"知道"如何执行任务
为什么使用 tool_result 而不是系统提示词?
- 系统提示词更改会使缓存失效(成本增加 20-50 倍)
- 工具结果追加到末尾(前缀不变,缓存命中)
这就是生产系统保持成本效益的方式。
"""
content = SKILLS.get_skill_content(skill_name)
if content is None:
available = ", ".join(SKILLS.list_skills()) or "none"
return f"Error: Unknown skill '{skill_name}'. Available: {available}"
return f"""<skill-loaded name="{skill_name}">
{content}
</skill-loaded>
Follow the instructions in the skill above to complete the user's task."""
def execute_tool(name: str, args: dict) -> str:
result = execute_base_tools(name, args)
if result is not None:
return result
if name == "TodoWrite":
try:
return TODO.update(args["items"])
except Exception as e:
return f"Error: {e}"
if name == "Task":
try:
return run_subagent_task(args["description"], args["prompt"], args["agent_type"])
except Exception as e:
return f"Error: {e}"
if name == "Skill":
try:
return run_skill(args["skill"])
except Exception as e:
return f"Error: {e}"
return f"Unknown tool: {name}"
def agent_loop(prompt: str, history: list, max_steps: int = max_steps) -> list:
has_system = any(msg.get("role") == "system" for msg in history)
if not has_system:
history.insert(0, {"role": "system", "content": SYSTEM})
step = 0
while step < max_steps:
step += 1
response = client.chat_with_tools(
prompt=prompt,
messages=history,
tools=ALL_TOOLS,
)
assistant_text = []
tool_calls = []
for block in response.content:
if hasattr(block, "text"):
assistant_text.append(block.text)
logger.info(block.text)
if block.type == "tool_use":
tool_calls.append(block)
full_text = "\n".join(assistant_text)
if not tool_calls:
history.append({"role": "assistant", "content": full_text})
logger.info(f"第 {step} 步结束,无工具调用")
return history
results = []
for tc in tool_calls:
if tc.name == "Task":
logger.info(f"\n> [使用工具] Task 第 {step} 步调用: {tc.input.get('description', 'subtask')}")
elif tc.name == "Skill":
logger.info(f"\n> [使用工具] 第 {step} 步调用 Loading skill: {tc.input.get('skill', '?')}")
else:
logger.info(f"\n> [使用工具] {tc.name} 第 {step} 步调用: {tc.input}")
logger.info(f" 输入: {tc.input}")
output = execute_tool(tc.name, tc.input)
if tc.name == "Skill":
logger.info(f" Skill loaded ({len(output)} chars)")
elif tc.name != "Task":
preview = output[:200] + "..." if len(output) > 200 else output
logger.info(f" [使用工具] {tc.name}, 返回: {preview}")
results.append(f"工具 {tc.name}, 输入: {tc.input}, 返回: {output}")
history.append({"role": "assistant", "content": full_text})
combined_output = "\n".join(results)
history.append({"role": "user", "content": f"执行结果:\n{combined_output}\n\n请继续处理"})
def main():
logger.info(f"Mini Claude Code v4 (with Skills) - {WORKDIR}")
logger.info(f"Skills: {', '.join(SKILLS.list_skills()) or 'none'}")
logger.info(f"Agent types: {', '.join(AGENT_TYPES.keys())}")
logger.info("Type 'exit' to quit.\n")
history = []
while True:
try:
user_input = input("You: ").strip()
except (EOFError, KeyboardInterrupt):
break
if not user_input or user_input.lower() in ("exit", "quit", "q"):
break
history.append({"role": "user", "content": user_input})
try:
agent_loop('', history, max_steps=max_steps)
except Exception as e:
logger.error(f"Error: {e}")
traceback.print_exc()
if __name__ == "__main__":
main()
执行完整流程
输入: 统计当前目录下的代码行数和功能,并且做 code-review,将结论输出到 html 中
输出:
(base) linkxzhou@LINKXZHOU-MC1 miniagent % python3.11 v4_skills.py
...
You: 统计当前目录下的代码行数和功能,并且做 code-review,将结论输出到 html 中
...
> [使用工具] TodoWrite 第 1 步调用: {'items': [...]}
...
> [使用工具] 第 18 步调用 Loading skill: code-review
...
> [使用工具] write_file 第 29 步调用: {'path': 'code_review_report.html', 'content': '<!DOCTYPE html>...'}, 返回: Wrote 21KB to code_review_report.html
...
总结
本文通过使用 deepseek-v3.2 模型,结合规则与工具,实现了从最简 Bash 代理到高级 Skills 机制的完整 Agent 构建流程。该项目代码开源地址:
https://github.com/linkxzhou/mylib/tree/master/llm/llmapi/miniagent
参考
- https://github.com/shareAI-lab/learn-claude-code
- https://github.com/linkxzhou/SimpleExcalidraw
 发表于 2026-1-20 09:42:32
|
查看: 219|
回复: 0
发表于 2026-1-20 09:42:32
|
查看: 219|
回复: 0
