
大型语言模型(LLM)推理的难度正日益凸显。其底层 Transformer模型 的自回归解码阶段,使得 LLM 推理与训练有了本质上的区别。受近期人工智能发展趋势的影响,当前面临的主要挑战已从计算能力转向了内存和互连。
为了应对这些挑战,Google的Xiaoyu Ma和David Patterson重点指出了四个架构研究方向:能提供10倍内存容量且带宽堪比HBM的高带宽闪存;旨在实现高内存带宽的近内存处理与3D内存逻辑堆叠;以及用于加速通信的低延迟互连。尽管研究重心在于数据中心AI,但文中也探讨了这些方案在移动设备上的适用性。
引言
计算机体系结构的研究与实践之间似乎出现了裂痕。有学者指出,业界在顶级体系结构会议上的论文占比已从1976年的约40%降至2025年的不足4%。为了重新弥合这种联系,我们提出了一些研究方向,若能取得进展,将有助于解决AI行业面临的一些最严峻的硬件挑战。
LLM推理正处在一个关键节点。硬件的快速迭代曾是AI进步的驱动力,而未来5-8年,推理芯片的年销售额预计将增长4-6倍。虽然训练展现了AI的能力上限,但推理的成本才真正决定了其经济可行性。随着模型使用量激增,企业维持最先进模型的成本变得异常高昂。
更严峻的是,新的技术趋势正在使推理变得更加困难,对资源提出了更高要求:
- 专家混合模型:MoE使用数十到数百个专家进行选择性调用,这种稀疏性让模型规模大幅增长,同时也对推理时的内存和通信带来了巨大压力。
- 推理模型:这种“先思考后回答”的技术会生成大量中间“思考”令牌,显著增加了生成延迟并占用大量内存。
- 多模态:从文本生成扩展到图像、音频和视频,更大的数据类型需要更多资源。
- 长上下文:更长的上下文窗口有助于提升回答质量,但也同步增加了计算和内存需求。
- 检索增强生成:RAG通过访问外部知识库来增强回答,这同样增加了资源消耗。
- 扩散模型:与自回归逐词生成不同,扩散模型一步生成所有标记然后迭代去噪,这会主要增加计算需求。
不断扩张的市场与日益增长的挑战共同表明,在LLM推理硬件领域进行创新,既是巨大的机遇,也是迫切的需求。
当前LLM推理硬件及其效率低下之处
我们首先回顾LLM推理的基础知识及其在主流AI架构中的主要瓶颈,这里主要关注数据中心场景。移动设备上的LLM受到不同限制,需要不同的解决方案。
LLM的核心是Transformer,其推理包含两个特性迥异的阶段:预填充 和 解码。如图1所示,预填充阶段并行处理所有输入令牌,类似于训练,通常受计算限制。解码阶段则是顺序生成输出令牌(自回归),因此受内存限制。连接两者的KV缓存,其大小与输入输出序列长度成正比。尽管图中两者同时出现,但它们在实践中常被解耦,运行在不同服务器上,以便应用批处理等软件优化来降低解码的内存占用。
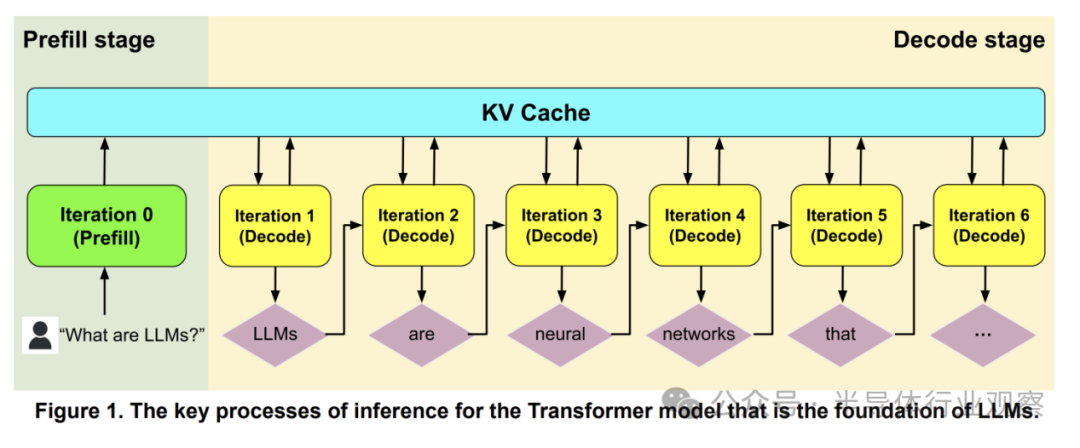
GPU和TPU是数据中心常用的训练与推理加速器。迄今为止,还没有专门为LLM推理设计的GPU/TPU。由于解码阶段与训练差异巨大,当前的通用加速器在解码时面临两大挑战,导致效率低下。
解码挑战一:内存
自回归解码使推理天生受内存限制,而新的软件趋势加剧了这一挑战。反观硬件发展,却呈现出不同的轨迹。
- AI处理器面临内存墙:当前数据中心GPU/TPU依赖高带宽内存(HBM),将多个HBM堆栈连接到单个加速器ASIC上(图2和表1)。然而,内存带宽的增长速度远低于计算能力(FLOPS)的提升。例如,NVIDIA GPU的FLOPS在十年间增长了80倍,而带宽仅增长17倍,且这一差距还在扩大。
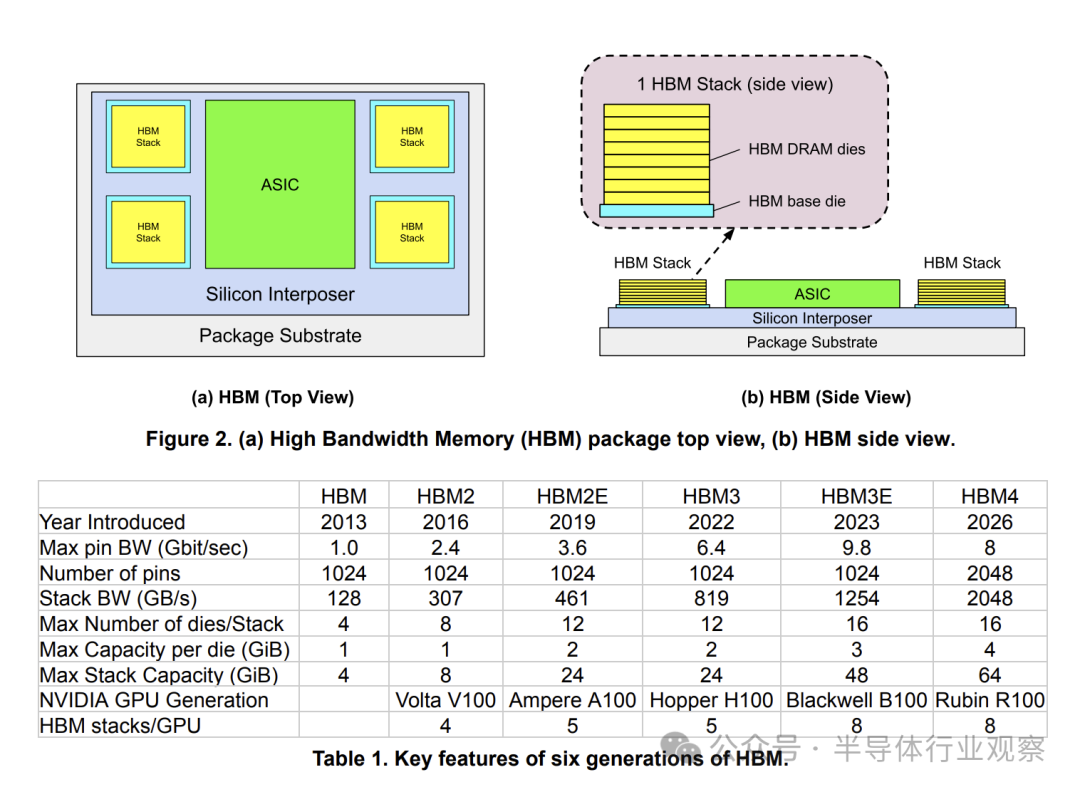
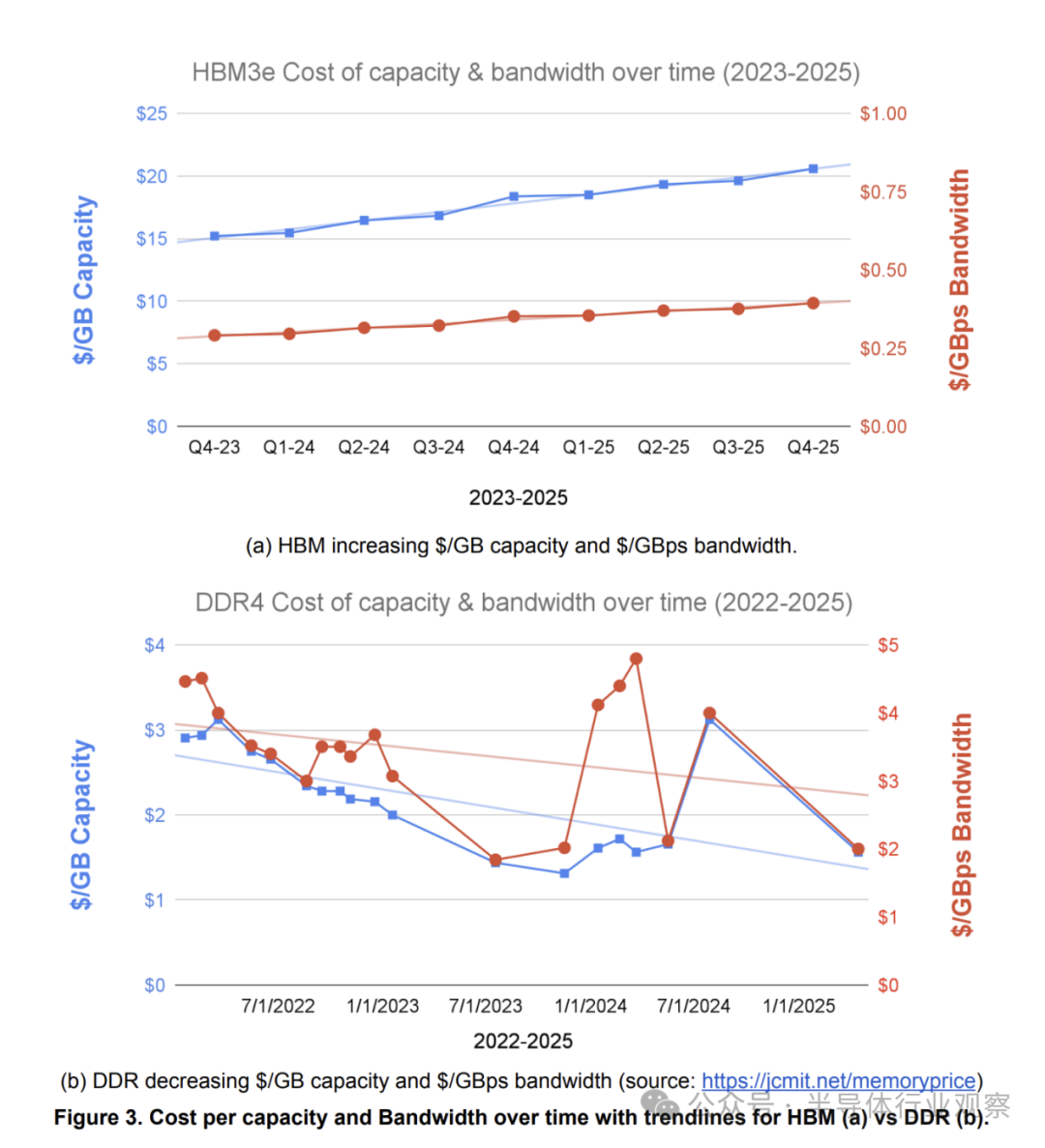
- HBM成本日益高昂:如图3(a)所示,从2023年到2025年,单个HBM堆栈的每GB容量成本和每GBps带宽成本均上涨了约1.35倍。这是由于堆栈芯片数增加和DRAM密度提升导致制造与封装难度加大。相比之下,图3(b)显示标准DDR4 DRAM的等效成本在同一时期是下降的。
- DRAM密度增长放缓:DRAM芯片的扩展性令人担忧。自2014年8Gb芯片后,容量翻两番(达到32Gb)用了超过10年时间,而此前通常只需3-6年。
- 仅靠SRAM的方案已不现实:Cerebras和Groq曾尝试用大容量片上SRAM来规避DRAM问题。但在LLM规模爆炸式增长后,两家公司都不得不为其系统加装外部DRAM。
解码挑战二:端到端延迟
- 面向用户的推理要求低延迟:与耗时数周的训练不同,推理需要实时响应,延迟要求通常在秒级甚至更低。延迟可以从两个维度衡量:
- 完成时间:输出序列越长,延迟自然越长。同时,每次解码迭代都伴随着较高的内存访问延迟。
- 首词延迟:更长的输入序列、RAG检索以及推理模型在最终答案前生成的大量“思考”令牌,都会增加生成第一个用户可见令牌所需的时间。
- 互连延迟比带宽更重要:LLM推理改变了数据中心互连的优先级。
- 由于模型权重巨大,LLM推理通常需要多芯片系统并通过软件分片,这意味着频繁的芯片间通信。MoE和长上下文模型进一步扩大了系统规模。
- 与训练不同,推理的批处理大小较小,网络消息也更小。对于频繁发送的小消息而言,延迟比带宽更为关键。
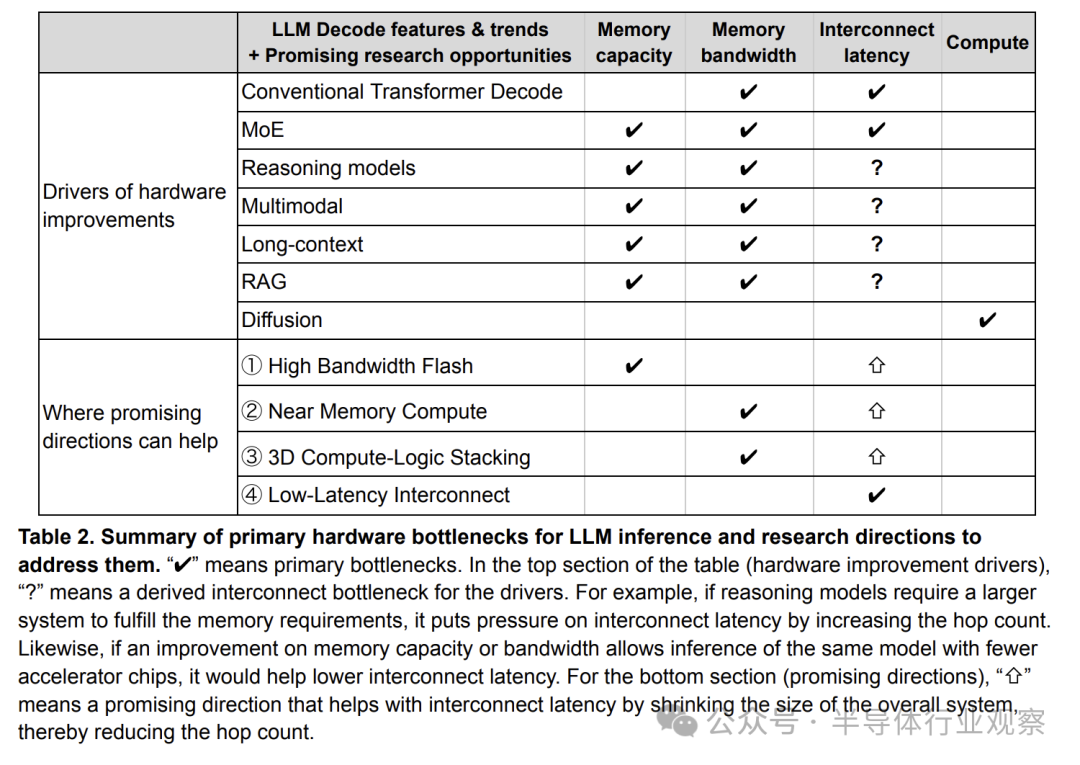
表2总结了解码推理面临的主要挑战。只有扩散模型主要需要提升计算能力——这相对容易实现。因此,我们应聚焦于改善内存和互连延迟的有前景方向,而非单纯追求算力。表格最后四行指出了四个具体的研究机会。
重新思考LLM推理硬件的四个研究机会
评估AI系统效率需要全面的性能/成本指标。现代指标强调实际性能、总拥有成本、平均功耗和二氧化碳当量排放,这为系统设计指明了新方向:
- 性能必须有意义。对LLM解码而言,高FLOPS不等于高性能,我们需要高效扩展内存带宽与容量,并优化互连速度。
- 性能必须在数据中心有限的功耗、空间和碳排放预算内实现。
- 功耗和碳排放应成为首要优化目标,它们直接影响TCO和运营碳足迹。
接下来,我们介绍四个能协同提升性能/TCO、性能/碳排放和性能/功耗的研究方向。
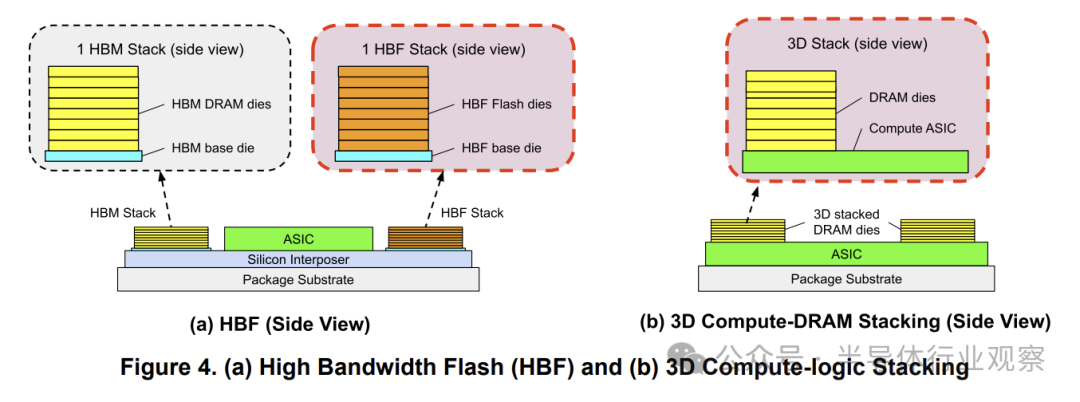
1. 高带宽闪存:容量提升10倍
高带宽闪存通过堆叠闪存芯片,将HBM级带宽与闪存级容量相结合(图4(a))。HBF可使每个节点的内存容量提升10倍,从而缩小系统规模,降低功耗、TCO、碳排放和网络开销。表3对比了HBF、HBM和DDR。HBF的短板在于有限的写入耐久性和较高的读取延迟(基于页访问,延迟在微秒级)。这意味着HBF无法完全取代HBM,系统仍需DRAM来存储频繁更新的数据。
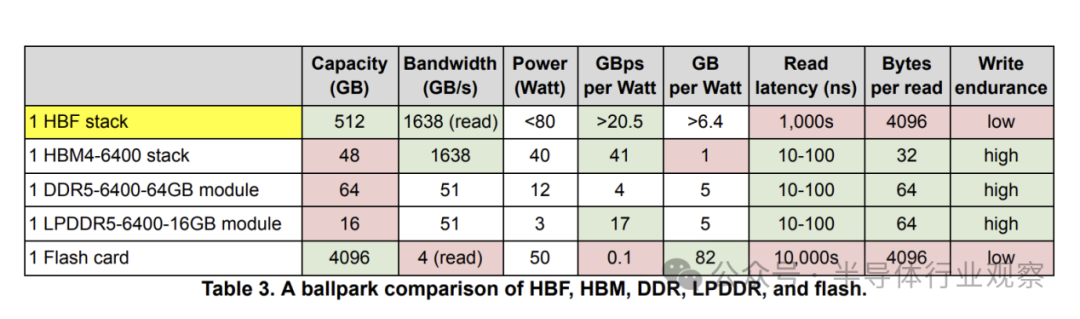
HBF为LLM推理带来了新可能:
- 10倍权重内存:推理时权重是冻结的,适合存储在HBF中,从而支持更庞大的模型(如巨型MoE)。
- 10倍上下文内存:适合存储变化缓慢的上下文,如网络搜索的语料库、代码数据库或学术论文库。
- 更小的推理系统:更大的单节点容量可以缩小系统规模,提升通信和资源分配效率。
- 更大的资源池:降低对单一HBM架构的依赖,缓解高端内存的供应压力。
这也引出了新的研究问题:软件如何适配HBF的特性?系统中HBF与传统内存的理想比例是多少?能否从技术上降低HBF自身的限制?移动端与数据中心的HBF配置应有何不同?
2. 近内存处理技术实现高带宽
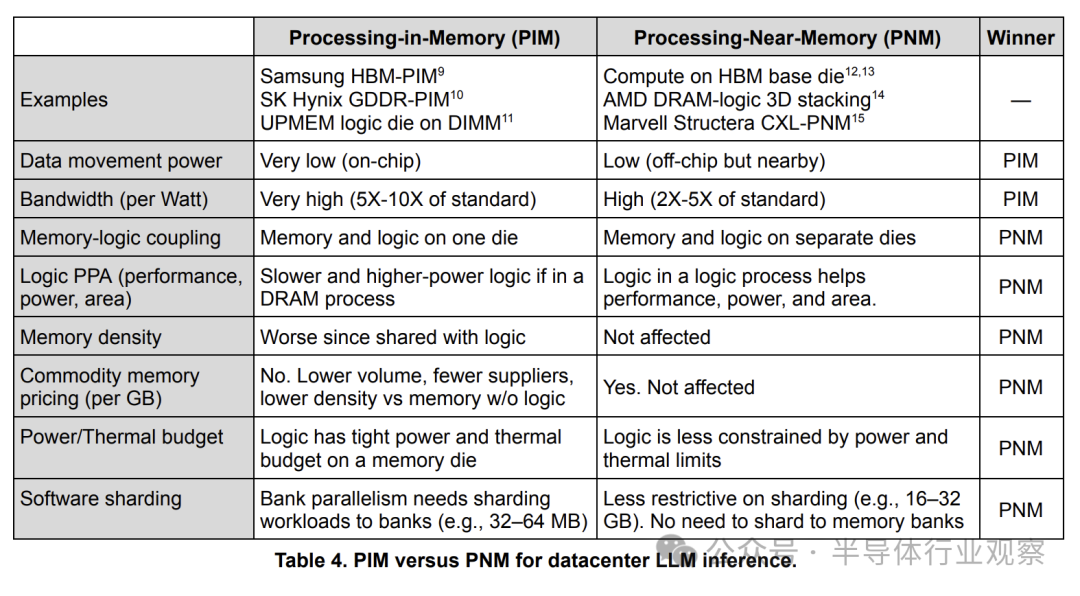
内存内处理技术将小处理器嵌入内存芯片以获得高带宽,但面临软件分片复杂和内存逻辑耦合(导致逻辑能效低)的挑战。近内存处理技术则将内存与逻辑芯片放置于临近位置但保持独立。PNM的一种形式就是下文将介绍的3D计算逻辑堆叠。
近期一些研究模糊了PIM和PNM的界限。我们在此明确区分:PIM是处理器与内存在同一芯片内;PNM是处理器与内存在相邻但独立的芯片上。
如果软件难以利用,硬件优势将毫无意义。表4列出了PNM在数据中心LLM推理中优于PIM的原因。尽管PNM的绝对带宽和功耗优势不及PIM,但其软件分片更简单(分片粒度大1000倍),且计算逻辑不受DRAM工艺的功耗散热限制。
对于移动设备,情况则不同。移动设备运行的是更小规模的LLM(权重少、上下文短),且为单用户运行,这简化了分片并降低了计算需求,使得PIM的弱点不那么突出,因此在移动端PIM可能更具可行性。
3. 用于高带宽的3D内存逻辑堆叠
与2D封装不同,3D堆叠(图4(b))通过垂直硅通孔实现更宽更密的内存接口,从而在低功耗下获得高带宽。主要有两种形式:一是复用HBM设计,在HBM基础芯片中插入计算逻辑;二是定制化的3D解决方案,有望实现比HBM更高的带宽和能效。
尽管优势明显,3D堆叠也面临挑战:
- 散热:较小的表面积使得散热更难。一个解决方案是降低逻辑芯片的频率和电压,因为LLM解码本身计算强度就不高。
- 内存逻辑耦合:可能需要行业标准来定义3D堆叠的内存接口。
这带来了新的研究问题:软件如何适应这种带宽/容量/算力比值迥异的新系统?在包含多种内存类型的异构系统中如何高效映射LLM?3D堆叠之间以及与主处理器之间如何通信?不同的3D设计选择(如逻辑芯片位置、堆叠层数)在带宽、功耗、散热和可靠性上有何权衡?移动端与数据中心的3D方案有何不同?
4. 低延迟互连
前述三种技术有助于降低延迟和提升吞吐量。除此之外,数据中心另一个有前景的方向是重新权衡网络延迟与带宽,因为推理对延迟更为敏感。例如:
- 高连通性拓扑:采用树形、蜻蜓形等拓扑,可以减少通信跳数以降低延迟,即使这可能牺牲一些带宽。
- 网络内计算:LLM常用的通信模式(如广播、全归约)非常适合在网络交换机内进行加速,能同时改善延迟和带宽。
- AI芯片优化:针对小数据包优化,如将到达的数据包直接存入片上SRAM而非DRAM;将计算引擎靠近网络接口。
- 可靠性协同设计:例如,本地备用节点可以降低故障恢复的延迟;在允许不完美通信的场景下,超时后使用替代数据而非无限等待,可以保证响应速度。
相关工作
- 高带宽闪存:SanDisk和SK海力士曾提出类似概念。微软研究人员提出了一种专注于读取性能和高密度的人工智能内存,HBF可视为其具体实例。另有研究探讨了将闪存集成到移动处理器用于设备端LLM推理。
- 近内存处理:基于HBM的计算方案和AMD的概念展示了3D堆叠的潜力。非3D领域也有三星AXDIMM和Marvell Structera等方案,后者利用CXL接口提升了灵活性。
- 低延迟互连:已有大量关于低跳数拓扑的研究。商业产品中,NVIDIA NVLink和Infiniband交换机已支持网络内归约,以太网交换机也在增加类似功能。
- 软件创新:除硬件外,算法与软件的协同创新空间巨大。例如,若能像扩散模型替代自回归生成那样,找到新的非自回归生成算法,将从根本上简化推理硬件。
结论
LLM推理的重要性与日俱增,其难度和成本压力也催生了一个极具吸引力的研究领域。自回归解码本身对内存和延迟构成根本挑战,而MoE、推理模型、多模态等新趋势更是雪上加霜。
计算机体系结构 社区曾借助精准的模拟器在分支预测、缓存设计等领域做出巨大贡献。面对LLM推理这一以内存和延迟为瓶颈的新问题,基于“屋顶线”模型的性能模拟器同样能提供有效的早期评估。此类框架还需关注内存容量、关键的分片策略,并采用现代的绩效/成本指标。我们呼吁学术研究者抓住这一机遇,推动AI研究加速发展。
当前以高FLOPS大芯片、多HBM堆栈和高带宽互连为核心的AI硬件设计理念,与LLM解码推理的需求并不完全匹配。我们建议从四个方向重点改进内存和网络:高带宽闪存、近内存处理、3D堆叠和低延迟互连。同时,关注数据中心容量、系统功耗和碳足迹的新绩效指标,相比传统指标揭示了新的优化机会。HBF、PNM/PIM和3D堆叠的简化版本也有望应用于移动设备LLM。
这些方向的进展需要业界与学界的通力合作,共同推动这一世界亟需的关键创新,以实现经济实惠的AI推理。关于更多人工智能与智能计算的前沿讨论,欢迎访问云栈社区进行深入交流。
 发表于 2026-1-21 02:50:36
|
查看: 182|
回复: 0
发表于 2026-1-21 02:50:36
|
查看: 182|
回复: 0
