今天,腾讯混元团队在开源实战领域带来了一款面向消费级硬件场景的“极小”模型——HY-1.8B-2Bit。它的等效参数量仅有 0.3B,内存占用低至 600MB,这个体积甚至比一些常见的手机应用还要小。这意味着,开发者可以轻松地将它本地化部署到手机、无线耳机乃至各类智能家居设备中,为端侧AI应用打开了新的想象空间。
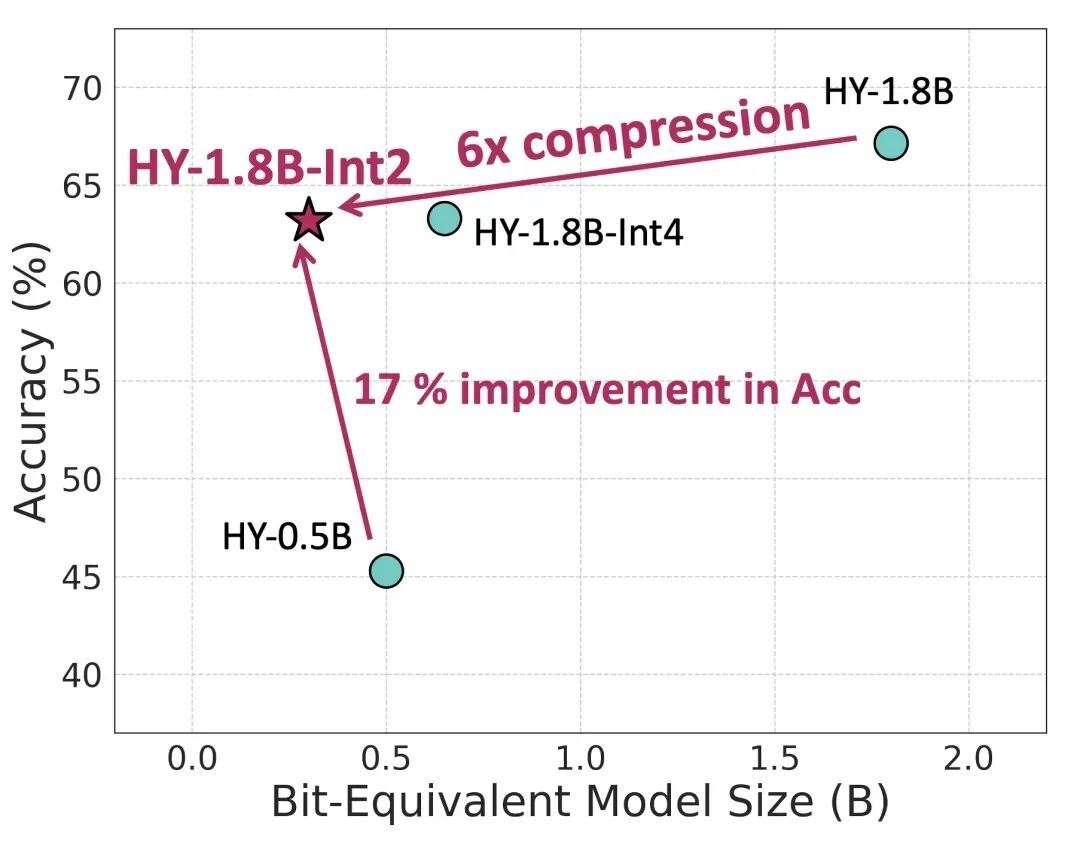
这款模型的核心技术,是基于首个产业级的2比特端侧量化方案。团队通过对先前发布的1.8B小尺寸指令微调模型 HY-1.8B-Instruct 进行 2比特量化感知训练(QAT) ,最终产出了HY-1.8B-2Bit。量化效果显著:对比原始的全精度模型,其等效参数量直接降低了6倍。更关键的是,这种极致的压缩并未牺牲核心能力——模型保留了完整的“思考”能力,能够根据任务复杂度,在长、短两种思维链模式间智能切换。在实际的端侧设备上运行,其文本生成速度更是提升了 2到3倍。
我们来看一下它在终端上的实际运行表现。下图展示了原始精度的HY-1.8B模型在llama.cpp上生成一首新春祝福诗的过程,包含了完整的思考链。
而经过2比特量化后的HY-1.8B-2Bit模型,在完成相似创作任务时,响应速度有着肉眼可见的提升。

这里的“比特”是计算机存储的基本单位。通常,模型精度越高(如32比特、16比特),所占内存就越大,性能也相对更好。2比特量化虽然会带来较大的精度损失,但腾讯团队通过QAT技术和先进的量化策略,成功地将性能损失降到了最低。结果显示,这个2比特模型在数学、代码、科学等多个关键指标上的表现,已经能够与4比特的后训练量化(PTQ)版本相媲美。
为了在仅有1.8B的原始模型上实现高质量的2比特量化,混元团队重点采用了量化感知训练策略。此外,他们还通过数据优化、弹性拉伸量化以及训练策略创新这三板斧,全面提升了HY-1.8B-2Bit的“全科”能力。
在部署层面,腾讯提供了HY-1.8B-2Bit的gguf-int2格式模型权重与bf16伪量化权重。与原始模型相比,实际模型大小直降6倍,仅有约300MB,非常适合在资源受限的端侧设备上灵活使用。该模型也已完成在Arm等计算平台上的适配,可充分利用启用Arm SME2技术的移动设备硬件优势。
性能实测数据更有说服力。在苹果MacBook M4芯片上,固定线程数为2进行测试,HY-1.8B-2Bit在不同上下文窗口大小下的首字时延,在1024输入长度内能实现 3~8倍 的加速;在常用的生成窗口下,其生成速度对比原始精度模型也能保持至少 2倍 的稳定加速。
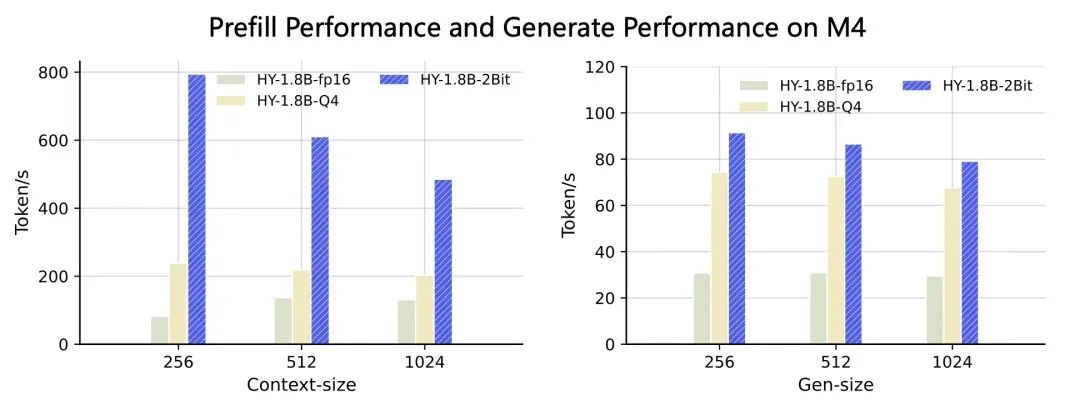
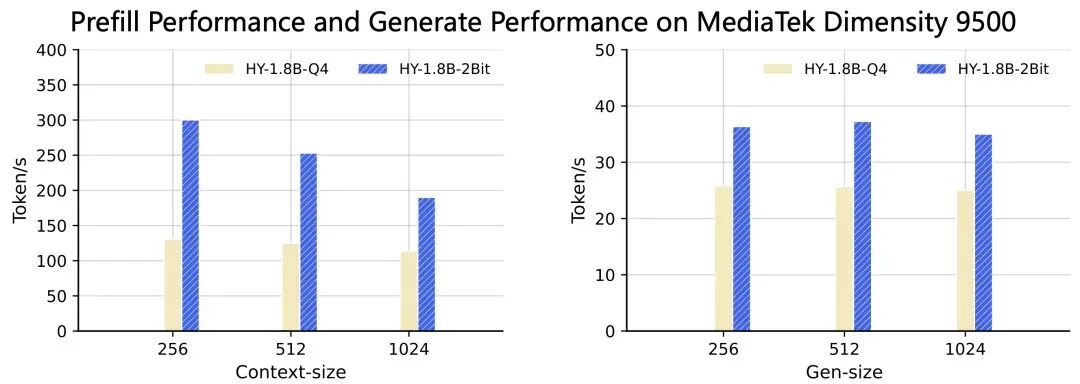
在移动平台联发科天玑9500芯片上的测试同样出色。对比HY-1.8B的Q4量化版本,HY-1.8B-2Bit的首字时延加速了 1.5~2倍,生成速度也提升了约 1.5倍。
项目资源
结语:模型“瘦身”加速端边侧智能发展
HY-1.8B-2Bit的推出,是腾讯在小型化、高效率人工智能模型探索上的一个重要里程碑。它不仅在有限参数量下逼近了更大模型的性能,更在速度、内存占用和隐私安全之间找到了一个精巧的平衡点。
回顾近期趋势,从去年阿里的Qwen-Embedding-0.6B、谷歌的Gemma 3 0.27B,到今年初腾讯这款0.3B的HY-1.8B-2Bit,小尺寸模型正迎来“百花齐放”的局面。这无疑将极大地丰富开发者的工具箱,推动RAG、语义搜索等智能应用不断下沉至每个人的个人设备中。
当然,当前HY-1.8B-2Bit的能力仍受限于监督微调的训练流程以及基础模型自身的上限。针对这些挑战,混元团队透露,未来的技术重点将转向强化学习与模型蒸馏等方向,以期进一步缩小低比特量化模型与全精度模型之间的能力差距,为端侧AI带来更强大的“芯”动力。
|  发表于 2026-2-11 20:09:02
|
查看: 270|
回复: 0
发表于 2026-2-11 20:09:02
|
查看: 270|
回复: 0
