
Hudi 1.1 正式发布 🎉
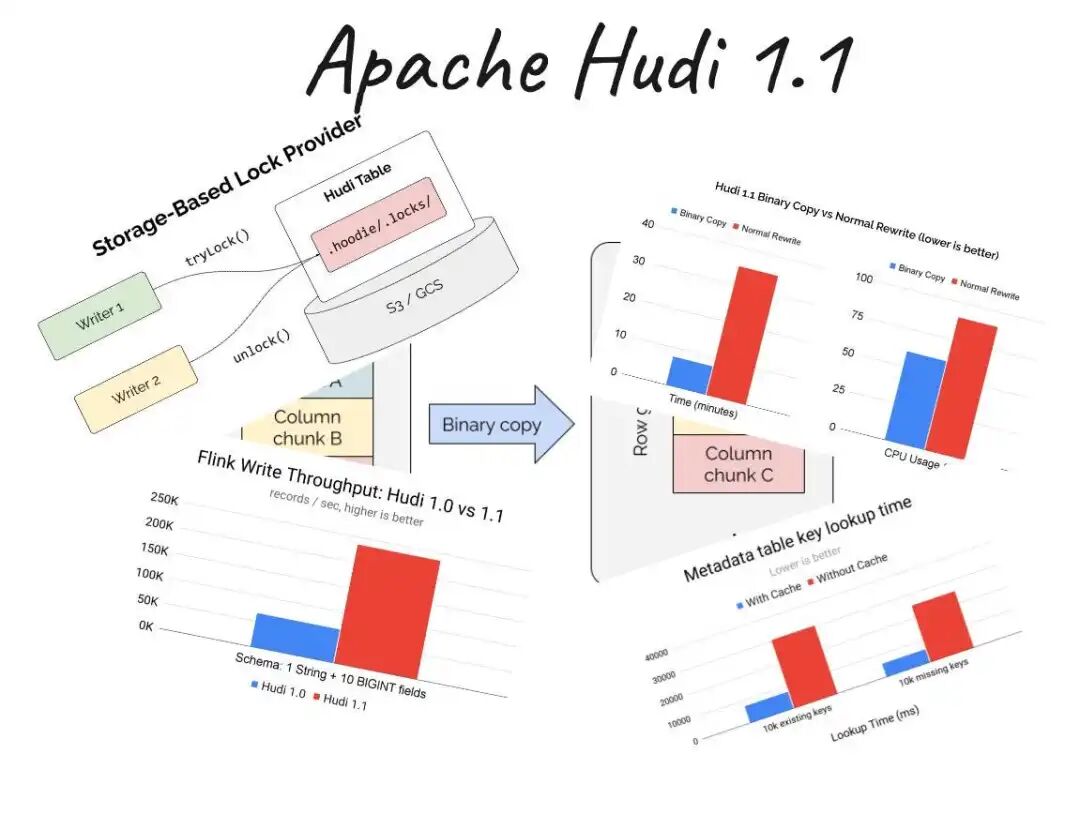
Apache Hudi 1.1 已正式发布!此版本作为重要里程碑,引入了可插拔表格式框架,原生支持 Iceberg 和 Delta Lake 适配器,实现了真正的多格式读写能力。
同时,该版本带来了多项性能与功能提升:
- 高级索引功能:增强了数据定位效率。
- 更快的聚簇操作:通过 Parquet 二进制复制,聚簇速度提升高达 95%。
- 提升并发性能:采用基于存储的锁机制。
- 计算引擎优化:在 Spark 4.0 和 Flink 2.0 中实现了显著的性能提升,其中写入吞吐量最高可提升3倍。
这标志着向开放、无厂商锁定的湖仓一体架构迈出了关键一步,非常适合致力于构建面向未来数据管道的团队。
详细版本说明与解读:https://yunpan.plus/t/1577-1-1
Open Source Data Summit 2025 分享回顾

在 Open Source Data Summit 2025 上,Shiyan Xu 探讨了 Hudi 的流式优先湖仓设计,如何应对高频、可变的工作负载挑战,例如由更新与删除操作引发的小文件问题、延迟峰值及资源冲突。
分享重点介绍了以下经过验证的策略,用以构建稳定、可扩展的流式管道:
- 高效写入的 Merge-on-Read 表类型
- 实现低延迟查找的记录级索引
- 自动文件大小调整与异步压缩
- 1.0 版本中引入的非阻塞并发控制
- 用于元数据优化的 LSM Timeline
观看演讲回放:https://opensourcedatasummit.com/streaming-lakehouse/
Data Streaming Summit:Uber 每日 600TB 的 Flink → Hudi 大规模摄取实践

在 Data Streaming Summit 上,Uber 的工程师 Zhenqiu Huang 详细分享了其超大规模数据管道的实践经验。Uber 运行着超过 5,000 条 Flink 流处理管道,每日向 Hudi 数据湖仓稳定摄取约 600TB 数据,并确保 P90 数据新鲜度低于 15 分钟。
实现这一目标的核心策略包括:
- 针对成本峰值的集群自动扩缩容
- 数据写入的部分排序优化
- 非阻塞并发控制机制
- 安全的偏移量提交策略
- 跨区域灾难恢复方案
观看完整案例分享:https://www.youtube.com/watch?v=FDeP0JKe7RQ
Data Streaming Summit:使用 Hudi 构建高吞吐量流式湖仓
另一场来自 Shiyan Xu 的分享深入探讨了如何利用 Hudi 构建高吞吐量的流式湖仓架构。演讲展示了 Hudi 在大规模数据摄取、高效可变数据处理以及实时管道性能优化方面的设计。
回放内容重点解析了 Hudi 的核心优势,如记录级索引、非阻塞并发控制以及智能文件大小管理技术。这些特性共同作用,能够在实现低延迟数据更新的同时,有效避免因小文件或资源瓶颈导致的管道性能问题。
获取构建稳健、可扩展数据流的关键洞察:https://www.youtube.com/watch?v=GUMiY44iy74
博客解读:深入 Hudi 索引子系统(下篇)
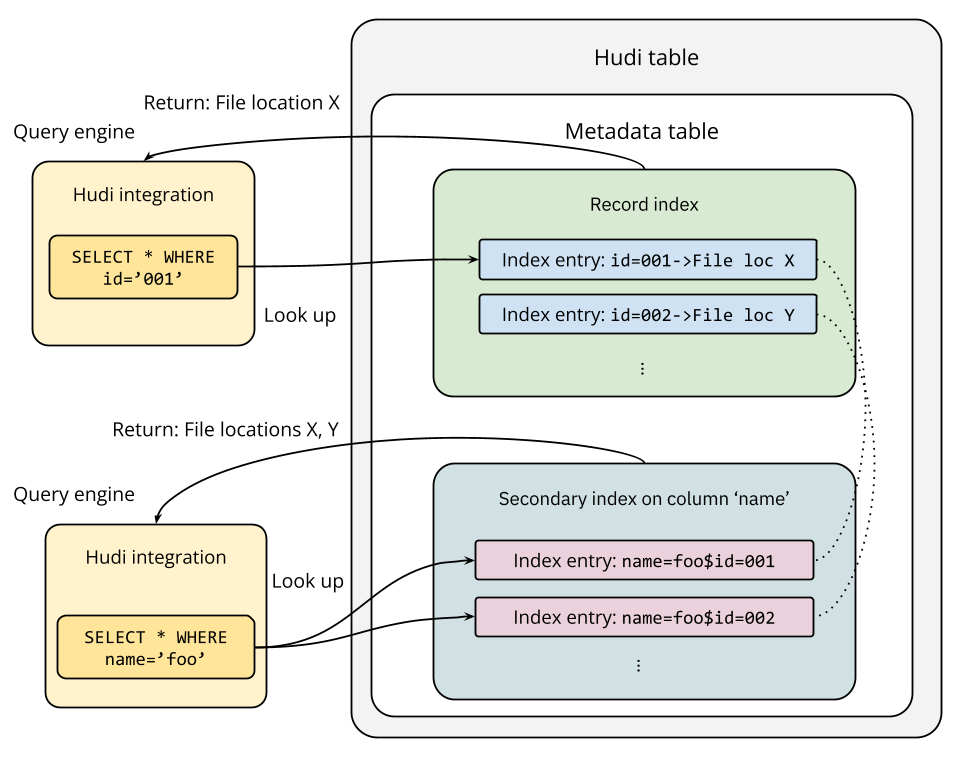
Shiyan Xu 撰写的最新博客深入探讨了 Hudi 的索引子系统,包括记录级索引、二级索引和表达式索引。这些索引机制能够大幅加速基于键值的查找、非主键过滤以及复杂谓词条件的查询。
博客亮点包括:
- 异步索引构建:对数据写入过程实现零影响。
- 事务一致性:通过元数据表保障。
- 智能过滤:结合使用 Bloom Filter 和列统计信息进行高效文件剪枝。
这对于需要在大型、可变数据湖仓中优化查询性能的开发者具有重要参考价值。
阅读完整全文:https://yunpan.plus/t/1578-1-1
博客分享:Hudi 中的动态 Bloom Filter 解析
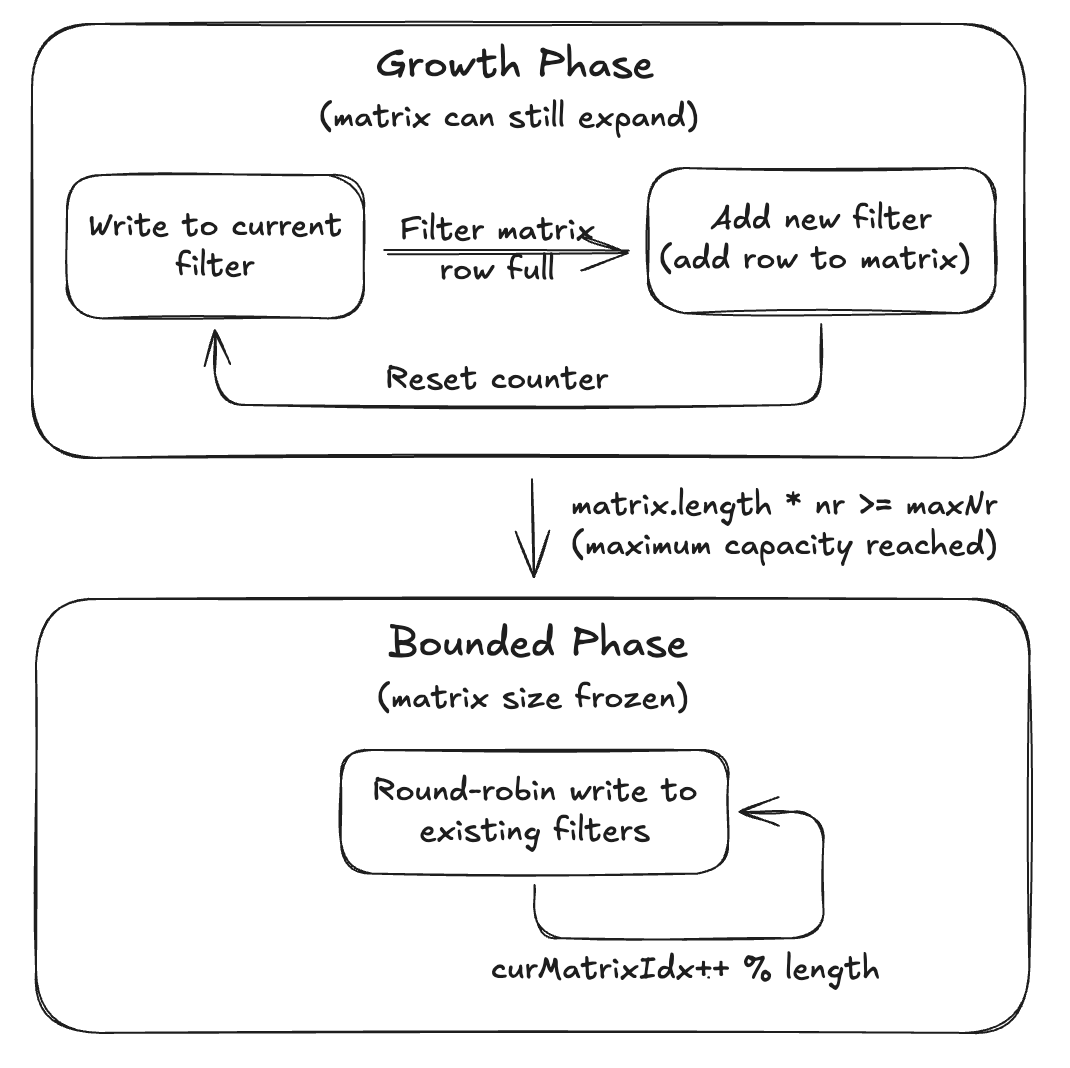
Yongkyun Lee 的新文章详细解释了 Hudi 动态 Bloom Filter 的工作原理。与传统固定大小的布隆过滤器不同(可能导致误报率激增或内存浪费),Hudi 的动态版本能够随着数据量增长而自动调整,即使在 Upsert 操作量不可预测地激增时,也能保持高准确性和效率。
其带来的优势包括:可靠的文件剪枝效果、最小的内存占用,以及在 PB 级数据规模下依然流畅的查询性能。
阅读技术解析:https://yunpan.plus/t/1580-1-1
Hudi 基础教程:使用 Precombine Key 处理乱序数据
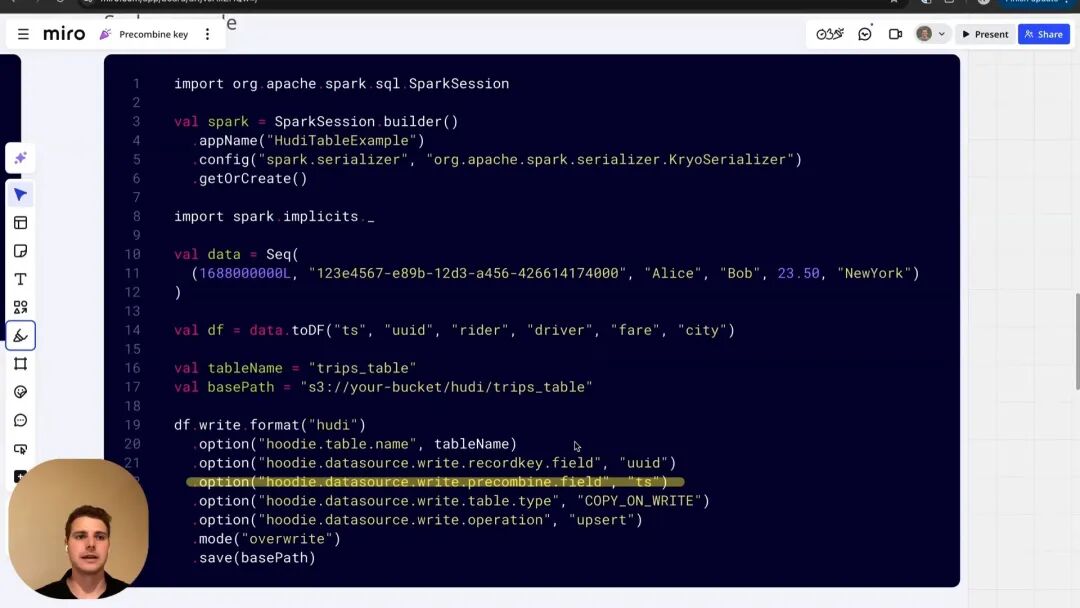
来自 Onehouse 的 Andy 通过视频详细介绍了 Hudi 的 Precombine Key 功能,该功能用于对乱序到达的数据流进行去重和合并,例如处理延迟的 IoT 遥测数据或 CDC 更新,确保保留具有最高优先级值(如最新时间戳)的记录。
教程内容涵盖:
- 通过表属性配置 Precombine Key
- 使用 Payload 类保障跨批次数据的一致性
- 实时演示:将 Kafka 点击流数据摄取到可变的 Hudi 表中
该教程有助于确保实时湖仓摄取的数据准确性,不受延迟到达数据的影响。
观看实战演示:https://www.youtube.com/watch?v=stSliRIMXEg
Hudi 学习与资源
快速开始
官方文档:https://hudi.apache.org/docs/overview
社区交流
社交媒体
贡献指南
 发表于 2025-12-7 00:04:32
|
查看: 207|
回复: 0
发表于 2025-12-7 00:04:32
|
查看: 207|
回复: 0
