从2025年底至2026年初,业界涌现了多篇关于Agentic(智能体)训练的重要研究工作。本文汇总了其中四篇具有代表性的工作,包括阿里的通义DeepResearch、智谱的GLM-5、美团的GEM以及字节的ABE。
通义DeepResearch和GLM-5提供了Agentic训练的整体链路概览,并强调合成数据的质量与训练环境的稳定性是关键。在此基础之上,字节的ABE专门聚焦于自动化训练环境的构建,而美团的GEM则深入解决了Agentic级别数据的自动合成问题。
核心要点(TL;DR):
- Agentic训练的核心在于高质量的合成数据与稳定的训练环境。
- Mid-training(中训练)阶段对于提升模型的Agentic能力至关重要,因为Agentic任务(长视野、多步骤)的数据分布与常见任务差异显著。
- 通过与环境的交互来训练智能体成本高且不稳定,通过构造仿真的Python代码和工具集可以极大缓解这一问题。
- Agentic数据的复杂性是关键,通常在初步合成后,需要进一步精炼以增加轨迹的多样性和难度。
以下是相关论文索引:
- Team, Tongyi DeepResearch, et al. “Tongyi deepresearch technical report.” arXiv preprint arXiv:2510.24701 (2025).
- Zeng, Aohan, et al. “GLM-5: from Vibe Coding to Agentic Engineering.” arXiv preprint arXiv:2602.15763 (2026).
- Xu, Zhihao, et al. “Unlocking Implicit Experience: Synthesizing Tool-Use Trajectories from Text.” arXiv preprint arXiv:2601.10355 (2026).
- Ye, Junjie, et al. “Feedback-Driven Tool-Use Improvements in Large Language Models via Automated Build Environments.” arXiv preprint arXiv:2508.08791 (2025).
一、 基础回顾:ReAct框架
在深入探讨之前,我们先快速回顾Agentic领域的一个重要基础框架:ReAct(Reasoning + Acting)。在每个时间步,智能体包含以下三个核心组件:
- Thought(思考):智能体的内部认知过程。包括分析当前上下文、从记忆中检索信息、规划后续步骤,以及通过自我反思来调整策略。
- Action(行动):智能体为了与环境交互而执行的外部操作。动作空间通常配备一系列多功能工具,使其能够与广泛的信息源交互(例如搜索、访问网页、Python解释器、学术搜索引擎、文件解析器等)。在任务轨迹中,中间Action表现为工具调用,而最终Action则是向用户提供的答复。
- Observation(观察):执行Action后从环境中接收到的反馈。这些信息用于更新智能体的内部状态,并为下一步的Thought提供依据。
二、 通义DeepResearch
2025年11月,通义团队推出了专为长视野、深度信息检索研究任务设计的Agentic大模型。
主要贡献:
- 强调Mid-training的重要性:提出在Mid-training阶段培养模型内在的Agentic偏好至关重要,随后再通过多轮强化学习(Multi-turn RL)来释放其潜力。
- 设计自动化数据合成流程:设计了覆盖Mid-training和Post-training(后训练)两个阶段的、自动化且可扩展的数据合成管道。
- 构建分阶段定制化环境:将训练环境建模为三种形式,应用于不同阶段:
- Prior World Environment(先验世界环境):提供任务要素、工具和状态定义,允许智能体基于预训练知识自主挖掘交互轨迹,无需实际环境响应。优点:稳定性极佳、零交互成本、无限扩展;缺点:缺乏真实世界反馈。
- Simulated Environment(仿真环境):在本地构建可控、可复现的真实世界交互副本。优点:稳定、响应快、成本低,便于快速迭代和因果分析;缺点:数据覆盖有限,存在“仿真到现实”的差距。
- Real-world Environment(真实世界环境):提供最真实的数据分布和反馈信号。优点:数据保真度绝对;缺点:交互成本昂贵,探索存在风险。
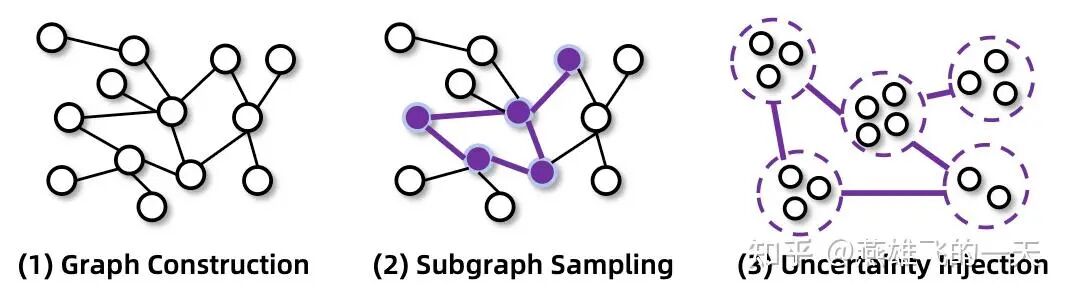
上图展示了其Post-training阶段的Agentic数据合成流程:
- Graph Construction(图构建):通过随机游走获取网络中的真实世界知识,构建高度互联的知识图谱。
- Subgraph Sampling(子图采样):从构建的知识图谱中抽取子图,生成初步的问答对。
- Uncertainty Injection(不确定性注入):引入“原子操作”(如合并相似属性实体),增加问题的模糊性以提高任务难度;并基于集合论对信息搜索问题进行形式化建模,减少推理过程中的捷径和结构性冗余。
三、 GLM-5
2026年2月,智谱AI开源了新一代旗舰模型GLM-5,其Agentic能力提升显著。
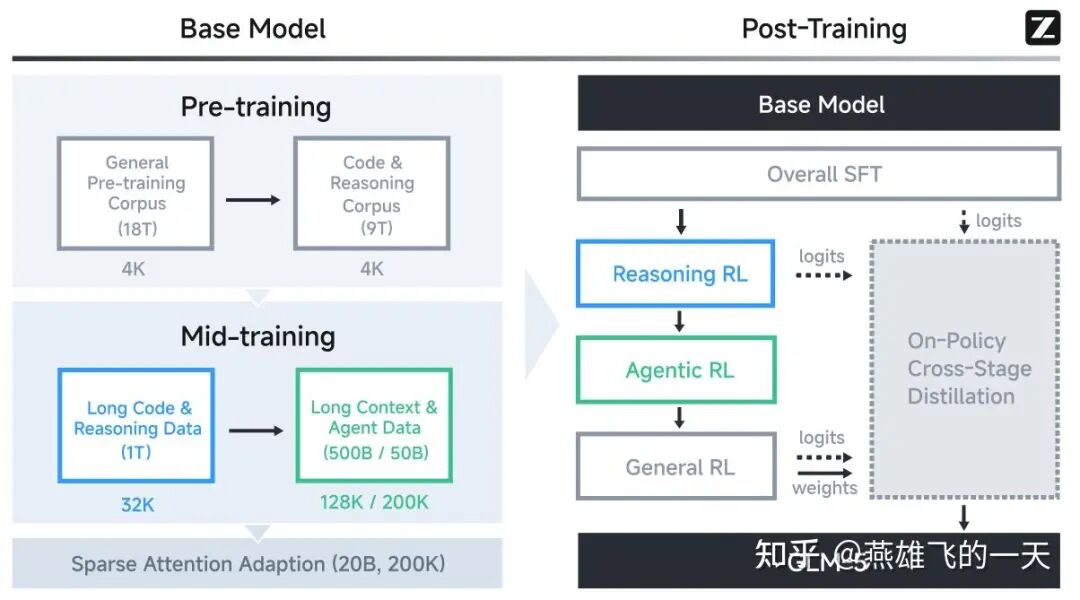
与Agentic相关的核心设计:
- Mid-training:与通义DeepResearch观点一致,同样强调在Mid-training阶段混合
long context & agent data的重要性。
- 多样化的SFT思维格式:支持三种不同的思维格式以适应不同场景:
- Interleaved Thinking(交织思考):模型在每次回复和工具调用前都会进行思考,提升指令遵循和生成质量。
- Preserved Thinking(保留思考):在编程等场景下,模型自动跨多轮对话保留所有思考块,复用现有推理过程,非常适合长视野、复杂任务。
- Turn-level Thinking(轮次级思考):支持在同一会话中逐轮控制推理的启用/禁用,在轻量请求时降低延迟,在复杂任务时提升准确性。
- Agentic RL优化:应用了一系列提升强化学习训练稳定性的技术,如异步RL框架、分词稳定性处理、重要性采样等。
四、 ABE (Automated Build Environments)
2025年9月,复旦和SEED团队提出了自动化构建环境(ABE)的方法,旨在极大降低与环境交互的成本,并提升强化学习的稳定性。
核心方法:
- 自动化环境构建流程:设计了一个确保工具使用训练可扩展、稳定和可验证的自动化流水线。
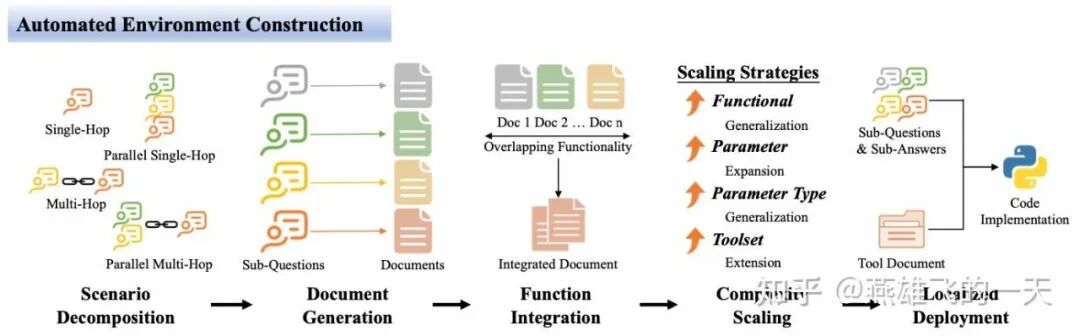
- Scenario Decomposition(场景分解):为保障环境多样性,定义了四种工具使用场景:单跳、并行单跳、多跳、并行多跳,以覆盖子问题间不同的逻辑关系。
- Document Generation(文档生成):为每个子问题生成对应的工具文档,确保任务可解,并建立子问题与工具接口的一一映射。
- Function Integration(功能集成):分析并合并功能重叠的工具文档,减少冗余,形成模块化、高效率的工具集。
- Complexity Scaling(复杂度扩展):通过功能泛化、参数扩展、参数类型泛化、工具集补充四个策略增强工具的复杂性。
- Localized Deployment(本地化部署):将工具文档映射的Python函数部署在本地,利用子问题和答案作为先验条件,确保函数正确响应。
- 可验证的奖励机制:设计了一种能够综合评估生成结构精确性和完整性的奖励机制。
五、 GEM
2026年1月,人大与美团团队提出了一种直接从文本自动合成工具使用轨迹的数据合成方法GEM,旨在极大缓解Agentic数据的构造难度。
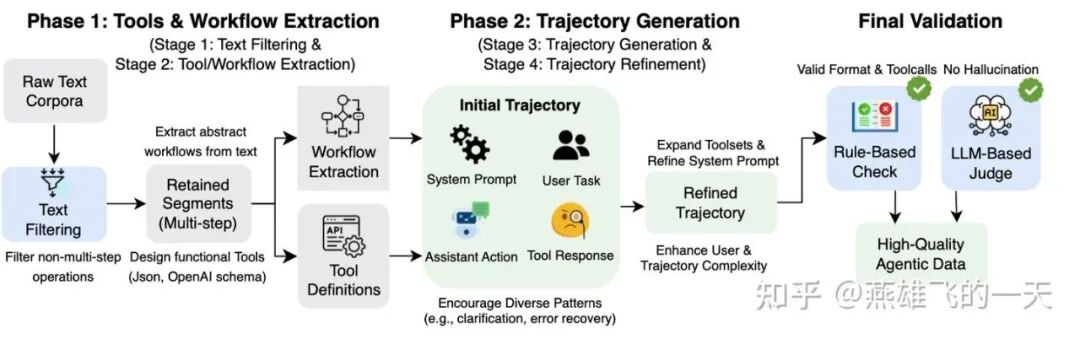
四阶段合成链路:
- Stage 1: Text Filtering(文本过滤):过滤掉不包含多步操作的原始文本,确保生成的轨迹具备高质量和真实性基础。
- Stage 2: Workflow & Tool Extraction(工作流与工具提取):
- 从文本中识别抽象的工作流并列举具体步骤。
- 按照OpenAI Schema标准设计一套对应的工具集合。
- Stage 3: Trajectory Generation(轨迹生成):利用强大的模型,基于上一步得到的文本、工作流和工具定义,单次生成初始轨迹(包含系统提示、用户任务、助手回复、工具响应)。
- Stage 4: Refinement(轨迹精炼):通过增加工具使用的多样性、提升环境响应的真实感、增加用户请求的歧义性和复杂性,来进一步提升轨迹的复杂度和训练价值。
总结与展望
综合来看,当前顶尖的AI代理训练工作呈现出清晰的演进路径:从定义整体训练范式,到专攻其中的核心挑战——高质量数据合成与低成本稳定环境。通义DeepResearch和GLM-5勾勒了包含Mid-training在内的完整训练蓝图,而ABE和GEM则像两把精密的“手术刀”,分别深入解决了环境和数据这两个瓶颈问题。
这些工作共同指向一个未来:通过高度自动化的流程,源源不断地生产复杂、多样的Agentic训练数据,并在稳定、可控的仿真环境中进行高效迭代,从而让大模型真正掌握解决长链条、开放式现实任务的能力。对这类前沿技术进展的持续追踪与解读,正是技术社区价值所在,欢迎在云栈社区交流探讨。
作者:燕雄飞的一天
来源:https://zhuanlan.zhihu.com/p/2010761900250646173
|  发表于 2026-3-2 05:18:00
|
查看: 342|
回复: 0
发表于 2026-3-2 05:18:00
|
查看: 342|
回复: 0
