
文本摘要作为自然语言处理(NLP)的核心任务,对其质量的评估往往需要综合考量多个维度,例如一致性(Consistency)、连贯性(Coherence)、流畅性(Fluency)和相关性(Relevance)。
但在实际优化时,开发者们常常陷入“拆东墙补西墙”的困境:提升了摘要的相关性,却可能导致其内部一致性下降。
那么,模型怎样才能在多个目标间找到那个完美的平衡点,也就是达到“帕累托最优”呢?最近,一项被 ICASSP 2025 会议接收的研究给出了一个新答案——超体积优化。
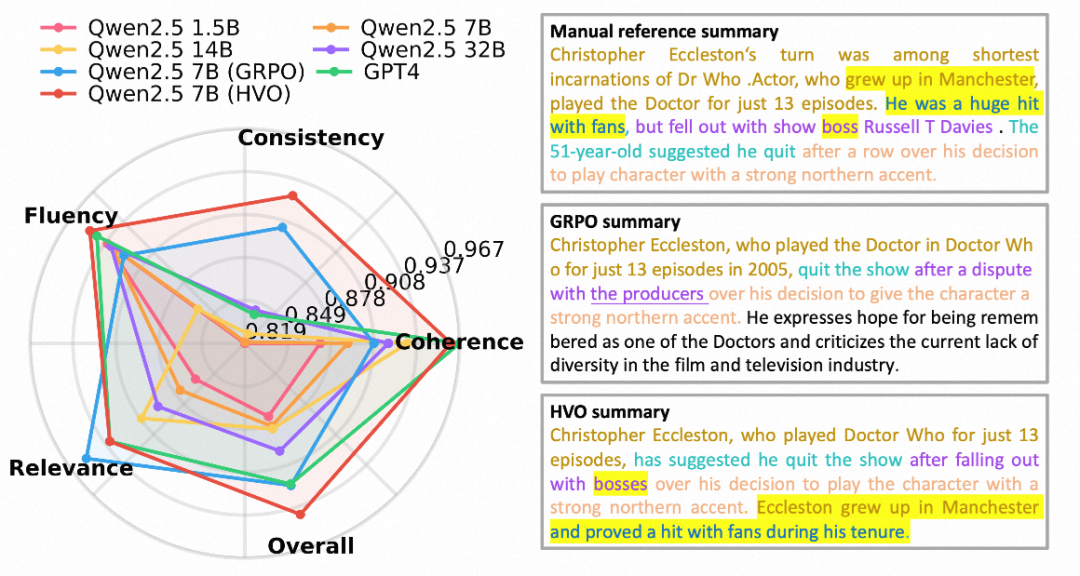
图1. HVO性能对比雷达图
这项由Li Auto团队提出的 HyperVolume Optimization (HVO) 方法,是一种全新的多目标强化学习策略。它基于GRPO框架,无需经过传统的监督微调(SFT)或复杂的冷启动,就能让参数量仅为7B的模型在文本摘要任务上达到媲美GPT-4的综合性能,并且生成的摘要更加简洁。

论文标题:
Balancing Rewards in Text Summarization: Multi-Objective Reinforcement Learning via Hypervolume Optimization
论文链接:
https://arxiv.org/abs/2510.19325
代码链接:
https://github.com/ai4business-LiAuto/HVO

研究背景:多目标优化的“不平衡”难题
文本摘要生成是NLP中一项核心且富有挑战的任务。为了全面评估生成摘要的质量,我们通常会考察连贯性、一致性、流畅性和相关性等多个维度。
然而,同时优化这些相互关联甚至可能冲突的目标非常困难。在一个维度上的改进,往往伴随着其他维度的妥协,最终导致摘要质量“失衡”。
当前的文本摘要研究大多依赖于单一的奖励信号,难以整合多维度的评估指标。即使尝试引入多维度奖励,通常也只是简单地将各项得分进行加权线性组合。
这种传统做法存在明显局限:
- 人工依赖性强:需要繁琐的手动配置和调整各项权重。
- 无法处理目标冲突:加权求和的方式难以有效协调目标间的相互制约关系,容易导致优化结果不完整或严重偏向某个维度。
此前虽有基于多目标梯度下降的方法尝试通过梯度投影来缓解冲突,但因计算成本过高,难以集成到大语言模型的训练中。

方法介绍:引入超体积指标HVO
为了解决上述问题,研究者创新地将多目标优化领域的超体积(Hypervolume) 概念引入了强化学习的奖励结构设计中。
基于GRPO框架
借鉴了类似DeepSeek-R1-Zero的训练范式,HVO直接在预训练好的基础模型上应用组相对策略优化(GRPO),跳过了监督微调阶段。其优化目标函数如下:
$J(θ) = E_{(q,a)~D,\{o_i\}^G_{i=1}~π_{old}(·|q)} [\frac{1}{G} ∑_{i=1}^G \frac{1}{|o_i|} ∑_{t=1}^{|o_i|} (min(f_{i,t}(θ)Â_{i,t}, clip(f_{i,t}(θ),1−ε,1+ε)Â_{i,t}) − βD_{KL}(π_θ||π_{ref}))]$
其中:
$f_{i,t}(θ) = \frac{π_θ(o_{i,t}|q, o_{i,<t})}{π_{θ_{old}}(o_{i,t}|q, o_{i,<t})}, Â_{i,t} = \frac{r_i - mean(\{r_i\}^G_{i=1})}{std(\{r_i\}^G_{i=1})}$
动态调整得分的核心
HVO的核心创新在于,它利用超体积计算方法,在强化学习过程中动态地评估和调整不同候选输出在各个目标维度上的综合表现,而不再是简单的加权求和。这使得模型能够被引导着逐步逼近帕累托前沿的最优解集。
具体来说,对于一组包含$G$个候选输出、$M$个优化目标的情况,HVO通过以下方式计算每个候选的综合奖励$r_i$:
$r_i = ∏_{k=1}^{M} [min(ε, r_i^k - min(\{r_i^k\}_{i=1}^G) + δ)]^{-w_k}$
引入长度约束机制
为了解决GRPO训练中常见的稳定性不足和“长度坍缩”(生成内容过短)问题,HVO额外提出了一种新的长度约束奖励,通过控制文本的压缩比来确保模型在追求简洁性的同时,能够稳定地收敛。
$R_{conciseness}(o_i) = \frac{1}{1 + (x_i / ρ)^λ}$
整体流程示意图
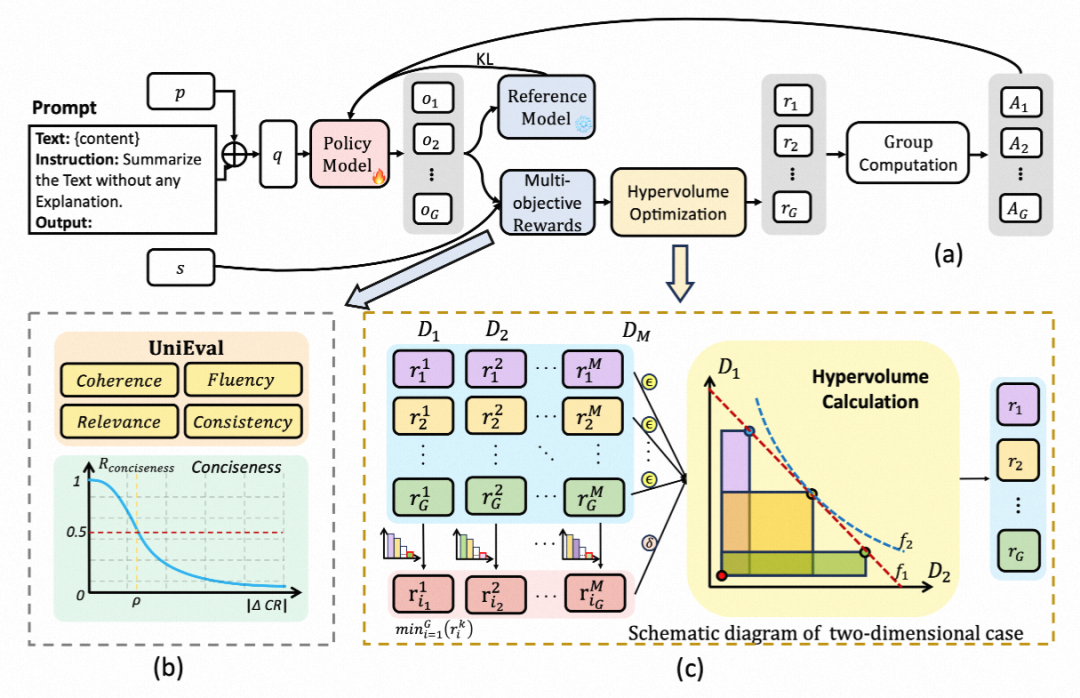
图2. HVO整体流程示意图。通过超体积计算替代简单的加权求和,使模型倾向于选择各维度表现更均衡的解。

实验结果:7B模型的“降维打击”
研究团队在CNN/DailyMail(新闻摘要)和BillSum(法律文书摘要)两大经典数据集上对HVO进行了全面验证。实验采用的基座模型是Qwen 2.5-7B-Instruct。
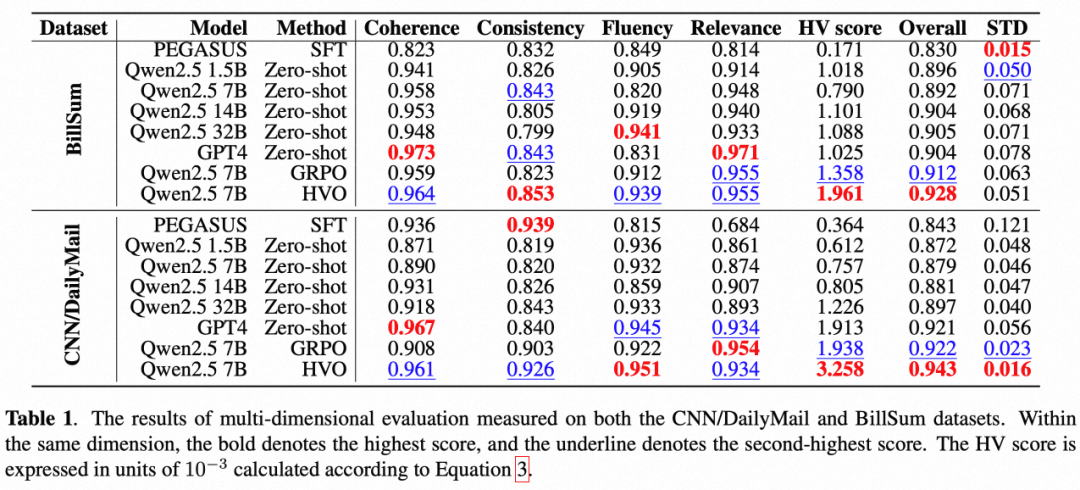
综合素质超越GPT-4
在使用多维度自动评估工具UniEval的测试中,经过HVO方法增强后的7B模型展现出了令人印象深刻的表现:
- 在两个数据集上的HV得分(超体积分数)和总分均优于所有参与对比的基线方法。
- 对比GPT-4:虽然GPT-4在连贯性(Coherence)和相关性(Relevance)两个维度上仍有微弱优势,但Qwen 2.5-7B (HVO)在整体性能(Overall)和各维度平衡性上已经与GPT-4旗鼓相当。
更均衡的雷达图表现
对比标准的GRPO方法可以发现,GRPO在训练早期会过度追求流畅性(Fluency)和相关性,从而限制了一致性(Consistency)的提升空间。而HVO能够更均匀、同步地优化各项指标,在雷达图上呈现出更饱满、更稳定的多边形覆盖区域,这意味着其生成的摘要质量更加均衡全面。
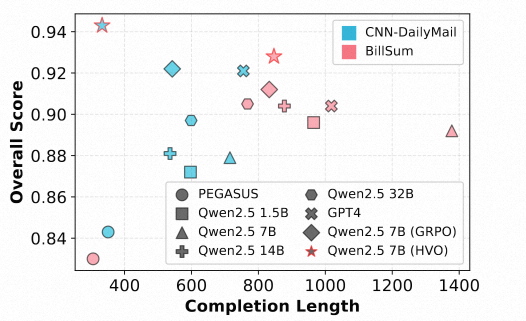
拒绝“废话”,输出更简洁
进一步的散点图分析显示,HVO在保持最高总分的同时,其生成的摘要长度普遍更短,展现了极佳的简洁性(Conciseness)。这说明HVO不仅能平衡质量维度,还能有效控制输出长度,避免模型产生冗余信息。

结语
本文介绍的超体积优化强化学习方法,为文本摘要任务提供了一个高效的多目标优化框架。它通过在高维目标空间中直接优化超体积指标,巧妙地平衡了多个评估维度,实现了更稳定、更高效地向帕累托前沿逼近的优化轨迹。
在CNN/DailyMail和BillSum数据集上的实验表明,HVO取得了当前最先进的超体积分数和整体评分,性能优于现有方法,并且无需监督微调或冷启动初始化,就能让7B参数量的开源模型在综合摘要质量上媲美GPT-4。
这些结果证实了HVO在处理复杂目标权衡和生成高质量、均衡摘要方面的有效性。它也为业界提供了一个明确的信号:通过更科学、更精巧的优化策略,较小规模的开源模型完全有潜力在特定任务场景下,对标甚至超越顶尖的闭源大模型。
研究团队表示,未来工作将探索将HVO框架扩展到更多NLP任务中,研究更复杂的奖励结构,并验证其在更大规模模型上的应用潜力。对于如何在云栈社区讨论和实践这类前沿的AI优化技术,这无疑提供了一个充满想象力的起点。
 发表于 2026-3-3 05:13:17
|
查看: 119|
回复: 0
发表于 2026-3-3 05:13:17
|
查看: 119|
回复: 0
